




 广告
广告





















































采用仿真技术生成数据改进自动驾驶的感知机制

arXiv论文“Data generation using simulation technology to improve perception mechanism of autonomous vehicles“上传于2022年7月1日,作者来自UCLA。

计算机图形技术的最新进展使汽车驾驶环境渲染工作更加逼真。DeepGTA-V和CARLA等自动驾驶汽车模拟器能够生成大量合成数据,可以补充现有的真实数据集,用于训练自主汽车感知。此外,由于自动驾驶汽车模拟器允许完全控制环境,因此它们可以生成真实数据集所缺乏的危险驾驶场景,例如恶劣天气和事故场景。
本文从真实世界收集的数据与在模拟世界中生成的数据相结合来训练感知系统进行目标检测和定位任务。提出一个多层深度学习感知框架,旨在模拟人类的学习体验,在特定领域学习一系列从简单到更困难的任务。自动汽车感知可以通过仿真软件,从易于驾驶的场景到定制的更具挑战性的场景学习驾驶。
利用CARLA的虚拟世界——一个为城市驾驶场景开发的开源模拟器——来重建汽车遇到的驾驶环境。通过模拟器提供的一组传感器套件捕捉环境细节:激光雷达、RGB图像、深度和分割摄像机。传感器可以安装在任何位置和朝向的车辆上。模拟器允许测量不同的传感器配置。
在Carla提供的传感器套件中,分割摄像机是模拟训练数据集与真实数据集相比的主要优势。该传感器根据目标的类型(汽车、行人、红绿灯等)对其进行颜色编码,生成摄像机图像。本质上,这是一种工具,可以保证“在像素级快速生成准确的真值”,这是许多用分割掩码进行训练的流行感知算法所需要的。
由于底层游戏引擎对模拟世界中的所有目标都有很好的了解,因此也可以快速生成其他类型传感器的真值标签(例如,生成摄像机图像中所有目标边框,以及被激光雷达射线击中的所有目标位置和方向)。
目前,Carla仿真器不提供自动生成定位信息去标记训练数据的工具。因此,一个初步工具,自动生成摄像头捕获的目标标签,与KITTI数据集格式相同集。以下步骤可生成标签:
-
1、请求附近感兴趣物体的信息。建议在120米半径范围内为汽车和行人贴上标签。请记住,尽管激光雷达的覆盖范围为200米,但120米的覆盖范围足以捕捉所有图像,不会因为太远导致分割不相关的图像。
-
2.为每个目标生成边框顶点。
-
3.将每个目标的顶点从世界视图投影到摄像头视图,然后投影到像素视图。
-
4、确定投影像素周围的像素是否被遮挡。将像素的深度与深度图中的相应深度进行比较来实现的。
-
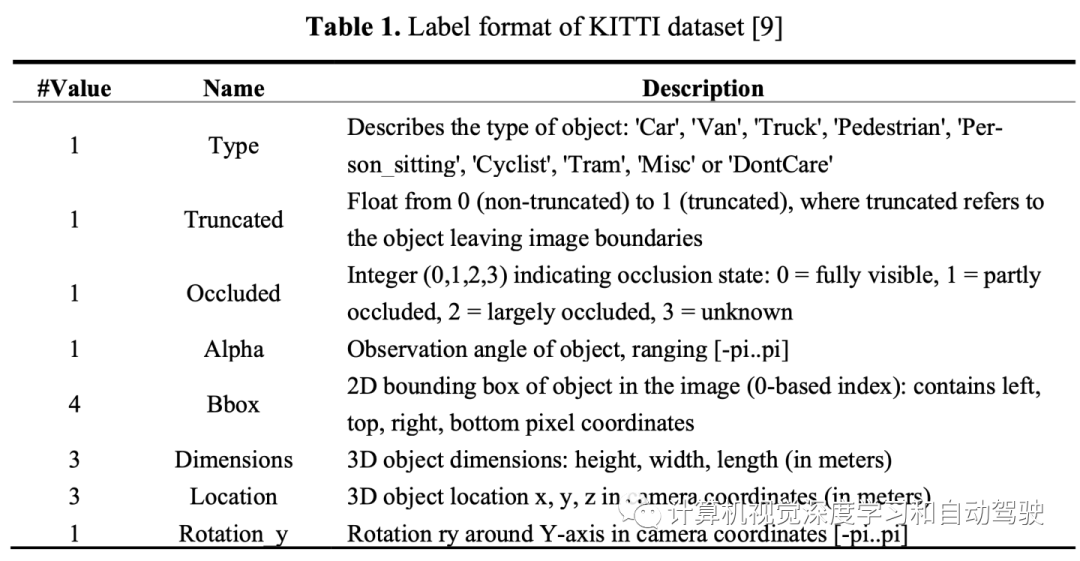
5.如果目标的两个以上顶点未被遮挡,并且目标像素高度大于25,则根据下表所示的KITTI格式生成目标标签。
将Carla模拟器与GTA-V游戏引擎区别开来的主要特点是能够控制虚拟世界的方方面面和复杂性,最重要的是目标和天气。天气控制的一个应用是通过模拟各种天气条件下的道路来提高自主车辆感知能力。天气条件对摄像机和激光雷达传感器的感知都有显著影响。最显著的是光源(太阳和汽车前照灯的角度等)和降水(雨雪)。
太阳的角度将决定阴影在环境中的投射方式,以及镜头光斑在摄像头图像上的形成,这两者都会阻碍基于摄像头的检测算法;从以前的状态下降到阴影中的目标的对比度降低会导致不需要的图像伪影。在夜间,由于建筑物、道路反射器和其他汽车头灯发出人造光,镜头光斑的效果更为显著。
虽然光源仅影响基于摄像头的检测,但降水同时影响摄像头和激光雷达。雨水坑的反射光会混淆基于摄像机的目标识别算法,并可能加剧镜头光斑效应。在激光雷达传感器中记录的雨滴和雪花可以降低3D云点图中真实目标的分辨率,也可以生成更多的污染目标。尽管很容易包括撞车事件,但在此类天气条件下可用的带标注的训练数据集很少。暴风雪或暴雨等天气条件在现实生活中很少发生,因此不存在,更不用说收集这些条件会使测试车进入危险。因此,理想的做法是用合成的数据集来补充收集的传统数据集。
Carla模拟器目前能够改变太阳的位置、云量、降水量以及街道上形成水坑的方式。由这些条件引起的伪影,如反射、阴影和镜头光斑,在很大程度上可以在摄像机传感器上模拟。
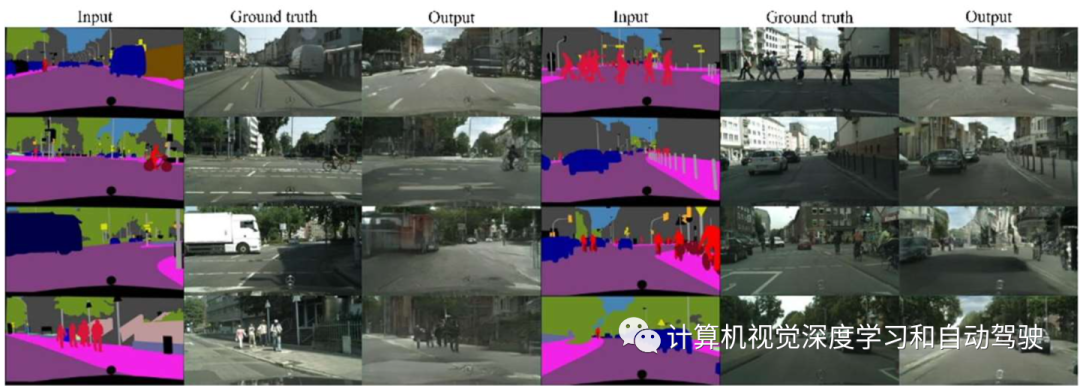
如图描述用CARLA在各种天气条件下生成的各种场景:

为了证明模拟生成的训练数据与传统数据集具有可比性,将训练数据输入到其他研究预训练目标定位算法(Yolo和MobileNet v2),并评估性能。使用风格迁移条件生成对抗网络(cGAN),可以进一步提高Carla模拟器生成的图像质量,使其更逼真。在正常的生成对抗网络(GAN)中,模型提供了所需产品的样本,例如来自汽车前摄像头的图像。从这些样本中,经过训练的模型将学习如何在给定随机输入的情况下生成类似的结果。
此外,cGAN在随机输入的基础上引入了期望输出的额外条件,以生成更直接的结果。这里的条件通常是想要的类标签。在用例中,为模型提供与合成图像一起生成的语义标记图像,以便构建该图像的真值。在Cityscape数据集上训练cGAN模型,以摄像机图像为真值,以语义分割图像为条件。然后,将训练后的模型从Carla模拟器生成的语义分割图像中生成真实图像。这些增强图像将用于补充目标检测模型。
如图所示:
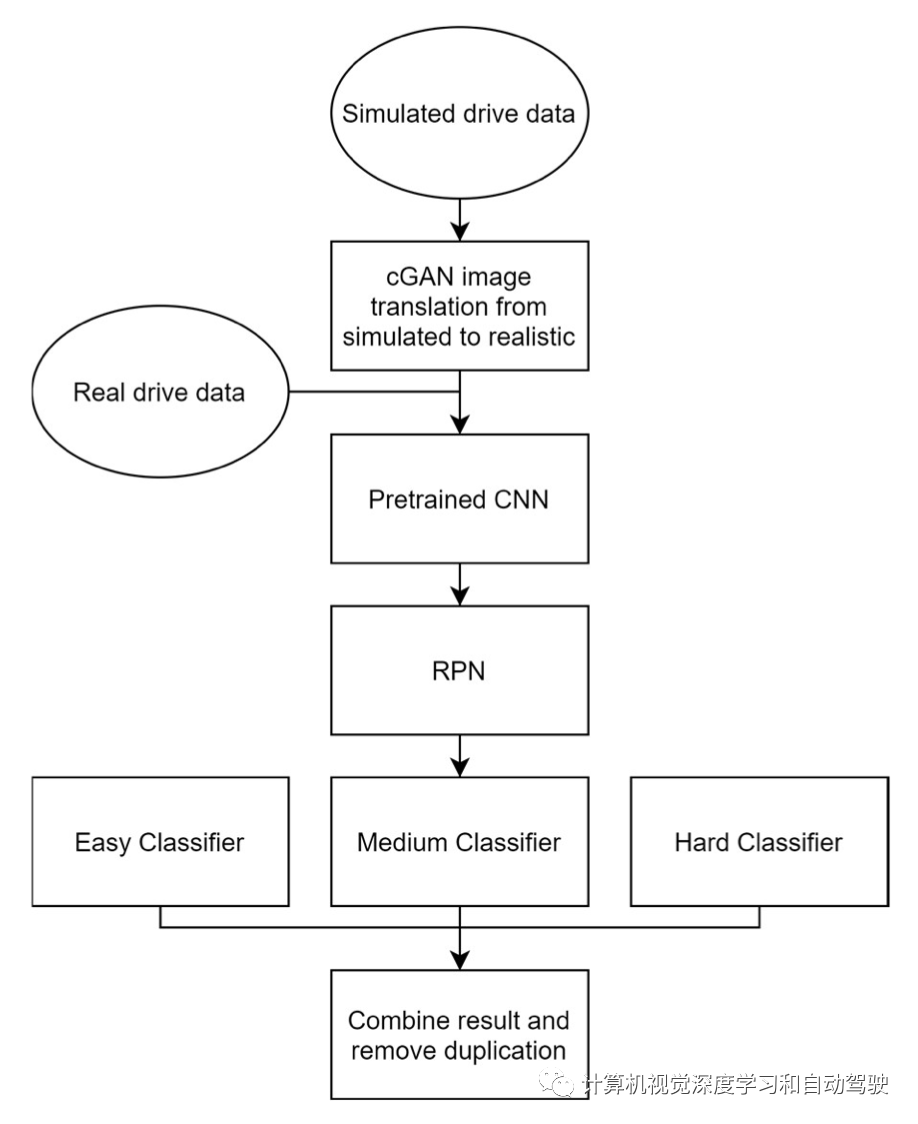
为了进一步改进现有的模型,提出一个用于自主车辆目标识别和定位的多级深度学习框架。该模型利用模拟和真实数据的组合。希望通过该框架实现两个主要目标:1)学习模拟世界和真实世界之间常见目标的特征;2)模拟人类学习过程,学习一系列任务,从特定领域中易于解决的任务到更具挑战性的任务。
如图所示:1.在常用数据集ImageNet和Coco上使用预训练卷积神经网络(CNN),从输入图像生成特征;生成的特征将反馈给区域提议网络(RPN),该网络随后将生成包含感兴趣目标的候选边框。2.使用STRV安排训练RPN。这使RPN专注于提取真实世界和模拟数据之间共享特征。3、分类器层;三个不同分类器代表三个不同的学习阶段:简单、中等和困难;每个分类器都用对应于其困难阶段的数据集进行训练。例如,简单分类器将在具有少量完全可见目标的数据集上训练,而困难分类器将在由大量被遮挡的目标组成的数据集上训练。
目标(goal)是集中在以下特征的图像,其中目标(object)难以正确分类:遮挡,目标数量,边框像素区域。根据这些特征对模拟数据和真实数据进行分类,以形成具有不同难度的数据集。
这种分类过程可以在模拟部分快速完成,因为可以访问图像渲染引擎以及图像中所有目标的状态,以推断样本的所有必要特征。对于真实世界部分,尽管每个数据集的标签中都有目标数和边框区域,但遮挡级别的标签将需要手动操作。实验要确定在STVR数据集排列下模拟真实世界数据的最佳比例。该比例越高,标记真实数据所需的手动工作就越少。
附加学习的训练过程如下:
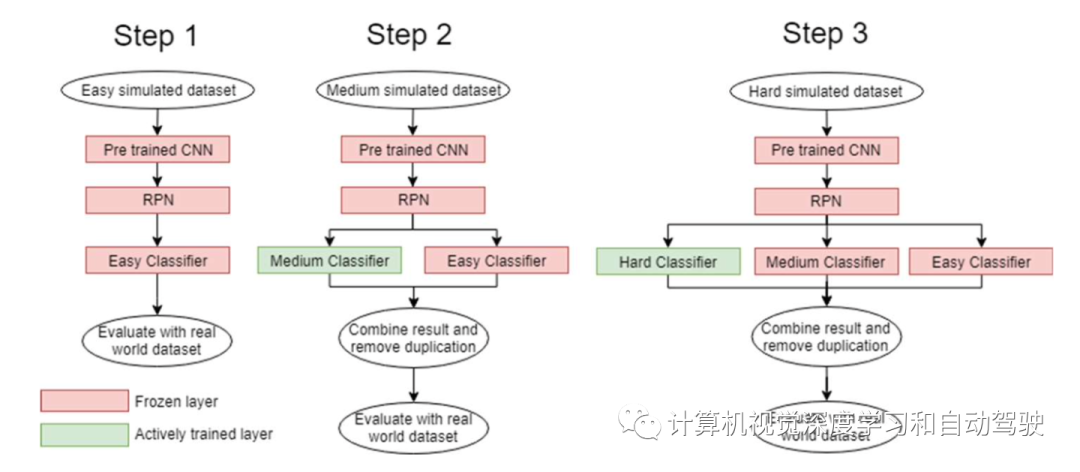
-
1、通用架构用上述容易数据集进行训练。这一步中只有一个容易分类器。CNN和RPN层的权值将被冻结。只修改分类器的权重,因为兴趣在于训练分类器从RPN层识别包含在提议边框中的目标。分类器将来自其他基于摄像机目标检测工作的所选样本。这一步的目标是让分类器在不受遮挡、小尺寸和拥挤影响的情况下学习目标分类的核心基本概念。
-
2.在中等数据集上重复与步骤1相同的过程。这一次,将添加额外的分类器(中等)。这个额外的分类器将是唯一修改权重的分类器。将两种分类器的检测结果结合起来。丢弃具有相同类且与容易分类器的结果非常接近的中等分类器的检测结果。由于这种安排,从简易分类器学习的目标分类的基本概念得以保留并具有更高的优先级。这将迫使中等分类器提出新技术来检测由于遮挡、小尺寸和拥挤的适度影响而被简单分类器遗漏的目标。
-
3.在困难数据集上重复与步骤2相同的过程,使用另一个额外的分类(困难)。训练逻辑同上。这一次,困难分类器被迫提出新技术来检测由于遮挡、小尺寸和拥挤的严重影响而被简单和中等分类器遗漏的目标。
提出的框架不仅限于3个分类器。它可以概括为具有任意数量的分类器,对应于难度级别。该框架的灵活性提供了一个平台,使用户可以选择广泛的功能;最终决定目标检测难度的特征。如图所示:



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
