




 广告
广告





















































自动驾驶下游任务的数据需求估计

arXiv论文“How Much More Data Do I Need? Estimating Requirements for Downstream Tasks“,上传于2022年7月4日,作者来自Nvidia,多伦多大学和Vector。

给定一个小训练数据集和学习算法,需要多少数据才能达到目标(target)验证或测试性能?这个问题在自动驾驶应用中至关重要,因为收集数据既昂贵又耗时。高估或低估数据需求会产生大量成本,本来在预算中是可以避免的。之前关于神经规模化定律(neural scaling laws)的工作表明,幂-定律(power-law)函数可以拟合验证性能曲线,并将其外推到更大的数据集。
不过,这并不能立即转化为在下游模块估计所需数据集大小以满足目标性能这一更困难的任务。这项工作考虑一大类计算机视觉任务,并系统地研究一系列泛化幂-定律函数的函数,为更好地估计数据需求。最后,结合调整的校正因子和多轮的数据收集,显著提高了数据估计器的性能。这样可以准确估计机器学习系统的数据需求,以节省开发时间和数据采集成本。
在部署深度学习模型之前,设计者可能会要求模型满足基线性能,例如像在延迟验证或测试集的指标。一个例子:在部署到安全-紧要应用之前,目标检测器可能需要最小的平均精度。达到目标(target)性能的最有效方法之一是为给定模型收集更多的训练数据。然而,到底还需要多少数据?
高估数据需求可能会因不必要的收集、清理和标注而产生成本。例如,标注分割数据集可能每个目标需要时间15到40秒,这意味着标注一个包含10万个图像的驾驶数据集,每个图像平均有10辆车,可能需要170到460天的时间。
另一方面,低估意味着必须在后期收集更多数据,从而导致未来成本和工作流延迟。例如,在自动驾驶汽车应用程序中,每个数据收集阶段都需要管理一组驾驶员来记录驾驶视频。因此,准确估计给定任务需要多少数据可以减少深度学习工作流中的成本和延迟。
关于估计机器学习模型的样本复杂度,最近提出的神经规模化定律表明,根据幂律泛化随数据集大小规模化。Rosenfield等人建议使用小数据集性能统计数据拟合幂律函数,推断大数据集的性能。然而,幂律函数不是唯一可能的选择。
如图用幂律函数估计ImageNet数据集以及几个有效的替代方案,说明了图像分类中的数据收集过程。
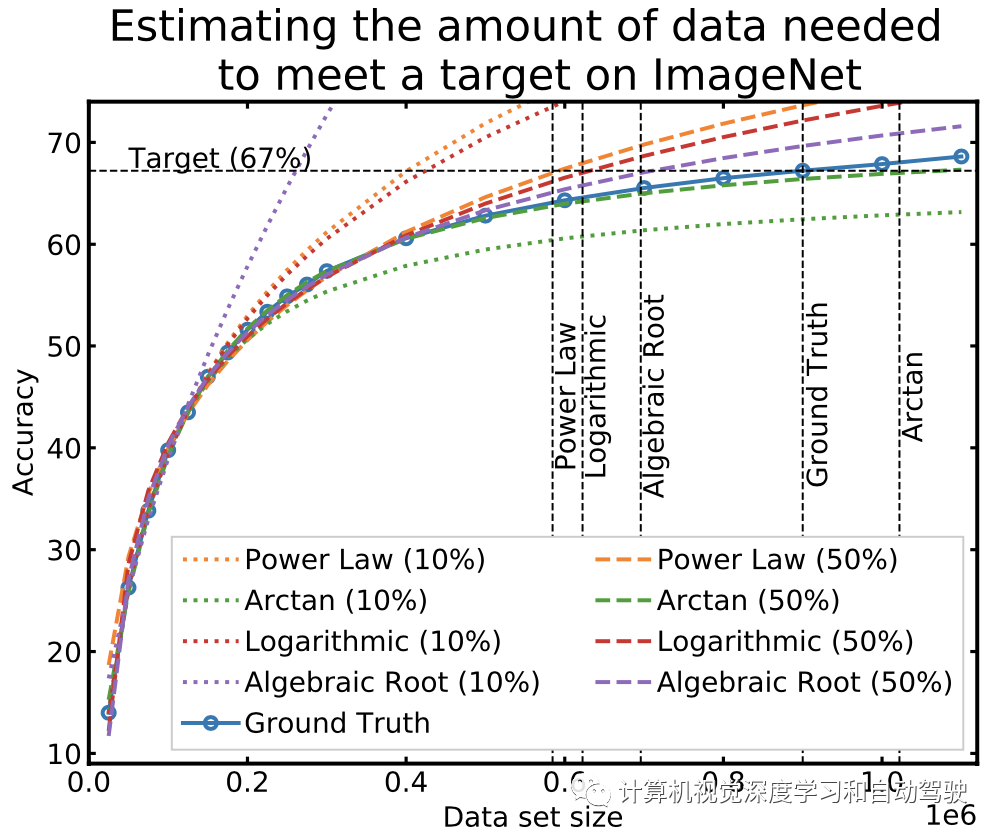
当使用小数据集进行外推时,拟合函数可能以不同方式偏离真值性能曲线。更重要的是,即使是外推精度的一个小错误也可能导致高估或低估数据需求上的大错误,带来巨大的运营成本。
如图所示是数据收集的流水线:
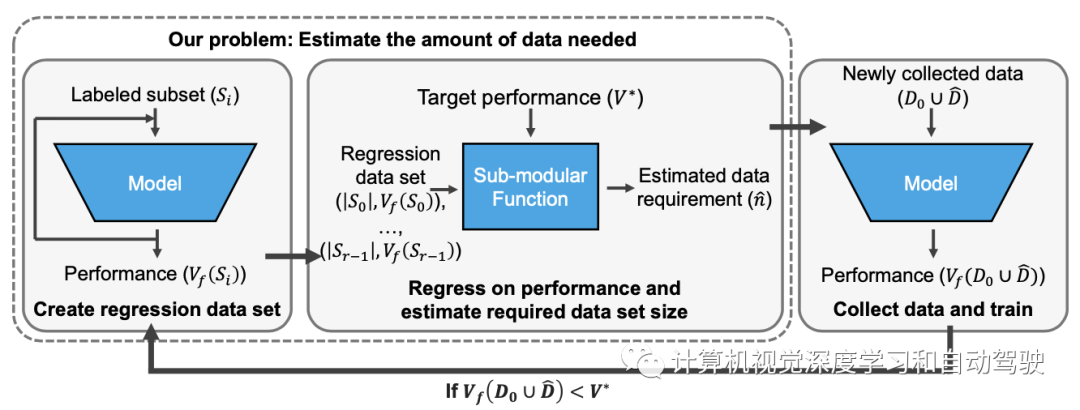
其主要基于以下经验观察事实:
【观察】:直观地说,随着收集更多数据,每个附加数据点的边际值应该降低。
用凹单调递增函数通过回归建立训练数据集大小的模型得分函数 v(n)。在数据收集循环中,首先用可用初始训练数据D0和当前训练数据(加附加数据)Dˆ估计附加数据nˆ,并通过拟合得分函数v(n)的回归模型vˆ(n;θ)来估计相应分数,其中θ是回归参数集。
在学习曲线文献中考虑满足观察(见下表)的四个回归函数。

虽然可以用更复杂的模型,但这些具有少量参数的简单结构化函数更容易适应较小的学习统计数据集。使用拟合回归函数,我们求解最小nˆ。如下算法1总结了主要步骤:重建回归数据,在循环中拟合参数,最后加点

现有文献表明,幂律可以使用数据集大小估计模型精度,但估计所需数据集大小以满足目标分数的实际应用面临三大挑战:
-
上面表中的所有函数都符合模型分数。有了足够的数据,表中的所有回归函数都可以精确拟合v(n)。当|D0| = 600000 图像进行拟合时,每个连接函数(虚线)与真值精度的误差最大为6%。虽然幂律在理论上是有来源的,但在其他函数中使用是否有经验上的正当性?
-
用小数据集外推精度是困难的。在数据有限的情况下,所有回归函数都很差。当|D0| = 125000个图像进行拟合时,每条曲线(虚线)显著偏离真值(≈ 数据集的10%)。此外,一些曲线提供了比幂律更好的拟合。有论文提出数据集和模型大小的联合回归;虽然这提高了外推性能,但也需要通过采样子集和修改不同模型获得2倍多的数据-得分对集合R。这可能会增加计算成本和耗时;因此,重点关注用少量训练统计数据的简单估计器,即r≤ 10、
-
精度误差小,数据误差大。假如在ImageNet建立一个满足67%测试精度的模型,需要90万个数据点。即使60万张图像进行函数拟合,但误差仍达到1%到6%之间。错误估计12万到31万张图像之间的数据需求,收集的数据比实际需要少34%。由于外推误差的容忍度较低,必须确定估计数据需求的最佳做法。
数据和方法
评估下表中总结的图像分类、目标检测和语义分割任务的数据收集问题。
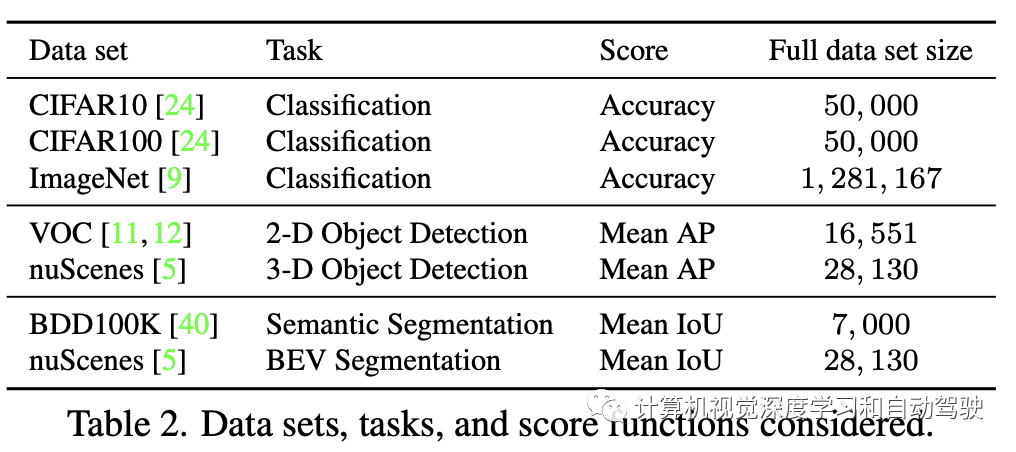
分类中,在CIFAR10、CIFAR100和ImageNet数据集上训练ResNet,确定满足目标验证集精度所需的数据量。用Pascal VOC数据集训练SSD300进行2D目标检测,其中确定满足目标平均精度(AP)所需的数据量。
对于3D目标检测,在nuScenes训练集的不同子集训练FCOS3D网络架构,遵循nuScenes 3D检测评估协议的平均精度(mAP)。样本是在不同场景中随机获得的。用BDD100K探索语义分割,作为一个大规模驱动数据集,收集了50K个驾驶数据,具有各种地理、环境和天气条件。对于多视图BEV分割,在nuScenes数据集上训练“Lift-Splat-Shot(LSS)”架构。在这里,报告mIoU结果。对每个任务,确定模型的体系结构和学习算法,包括数据采样。
对每个数据集和任务,有一个初始数据集D0(例如,n0=训练数据集的10%)。在分析中,根据D0 相对于完整训练数据集的相对大小报告n0。首先根据算法1构建大小呈线性增长的r 个子集创建回归数据集R∈ {0,…,r− 1})。为了确保这个回归过程不昂贵,用了一个小r ≤ 10。
然后,为评估外推性能和估计数据需求的回归函数,抽样较大的子集D1⊂D2⊂···,以此增大(例如,整个训练数据集的10%、20%、30%、…、100%)。对每个子集,训练模型并评估分数Vf(Di)。利用这些集合,构造分段线性得分函数v(n),并将其用作真值。
进行两种类型的实验。在第一个初步分析中,用R拟合每个回归函数,然后对所有| Di |>|D0 |评估相对预测Vf(Di)的误差。该分析揭示每个回归函数在更大数据集上推断模型分数的能力。第二个主要分析是模拟算法1中的数据收集问题,其中用n0=10%的完整训练数据集进行初始化(对于VOC,n0=20%),并估计需要多少数据才能获得不同的目标值。在这里,重复在算法1中数据收集阶段描述的相同步骤,除了一个不同之处。在模拟中,不是每一轮采样更多数据并评估Vf(D0 ∪ Dˆ),而是评估v(n0+nˆ)获得模型分数。该模拟近似于真实的数据收集问题,同时简化了实验,因为不必重复地重训练模型。
分析
下表总结了在外推较大数据集的分数时每个回归函数的均方根误差(RMSE)。
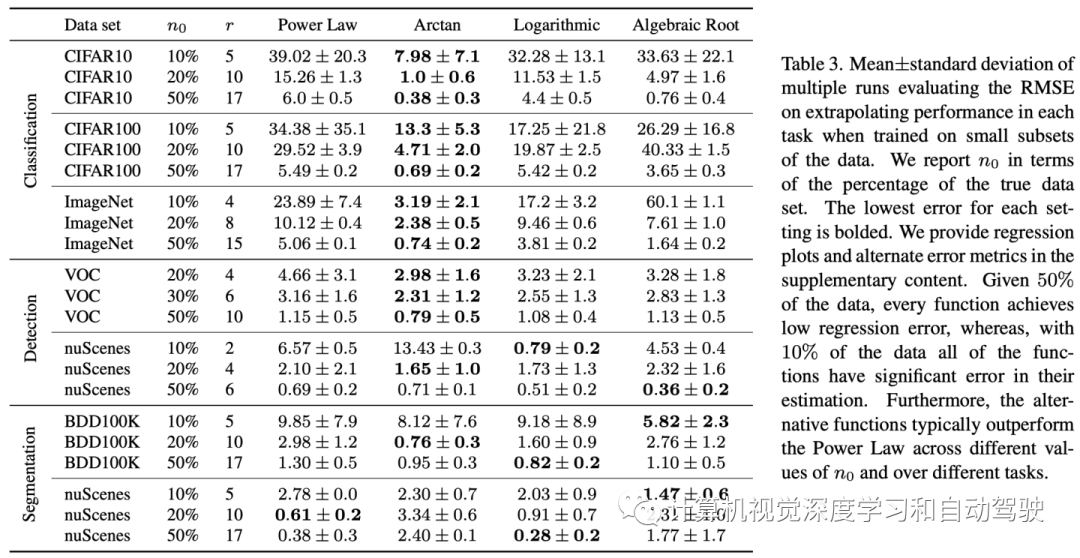
在每个数据集和任务中,用不同的随机种子做三次运行,展示了可以用小、中、大数据子集进行外推。
对考虑的每个任务,验证前两个挑战。给定足够数量的初始数据D0来拟合回归模型(即当n0等于完整数据集大小的50%时),每个链接函数都实现了较低的均方根误差(其范围为区间[0,100])。此外,始终存在至少一个回归函数,其均方根误差小于1。
当n0等于完整数据集大小的10%时,大多数链接函数产生较高的均方根误差,这表明当拟合在小数据集上时,这些函数容易偏离真实v(n)。最后,对于大多数数据集,替代回归函数始终产生较低的均方根误差。特别是,Arctan函数对于所有分类数据集都是最好的,并且通常幂律均方根误差减半。这些结果表明,从小数据集外推模型性能是困难的,此外,其他回归函数代替幂律可以获得更准确的分数回归。
给定n0和T,通过扫描一系列目标来模拟每个不同回归函数的数据收集 。如图所示报告每个函数收集的最终数据与根据真值分数所需最小数据的比率,即(n0+nˆ)/(n0+n∗) ,其中n∗ 满足v(n0+n)= V的最小值。n的值很容易找到,因为v(n)是一个分段线性单调递增函数。
在评估每个回归函数如何收集数据时,需要考虑两种情况。如果比率小于1,该函数被描述为分数的乐观预测因子,即低估数据的需要。比率小于1意味着,用该回归函数,在T轮内将无法收集足够的数据来满足V∗ ,因此无法解决问题。另一方面,如果比率大于1,则该函数是一个悲观预测因子,即高估数据的需要。理想的数据收集策略将实现大于1的最小比率。实验表明,通常情况下,Arctan函数是最悲观的,并且通常达到最大的比率。
验证第三个挑战,指出低回归误差不一定转化为更好的数据收集。在CIFAR100、ImageNet和VOC上,使用Arctan可能会收集到比实际需要多5倍的数据;在nuScenes上进行BEV分割可能会导致10倍以上的结果。回想一下,在ImageNet上,需要大约90万张图像才能达到目标V∗ = 67%。以n0=10%的数据初始化时,Arctan将导致仅在第一轮中就收集约450万张图像,而所有其他回归函数的比率约等于1。
虽然上表表明回归中Arctan实现了所有函数中最低的RMSE(3.19),但以此估计数据需求将导致不必要的昂贵数据收集。这表明,在确定良好的数据收集策略时,简单分析回归误差是不够的,需要模拟方法。
对于大多数回归函数,收集足够的数据需要多轮外推。当T=1时,幂律、对数和代数根函数低估了除VOC之外数据集和任务的数据需求。然而,当T=5时,对除CIFAR10之外的数据集,所有函数在整个V*范围内的比率都大于0.9。也就是说,始终可以使用任何回归函数获得至少90%的所需数据。
最终,即使T=5,当V∗ 较大(例如,在ImageNet上,当V* ≥ 62%时幂律、对数和代数根函数的比值小于1)。从操作角度来看,虽然这些方法不会造成巨大的成本,但也无法解决问题。
有助于达到目标的修正系数
从算法1中,在每一轮数据收集中,根据vˆ(n0+nˆ;θ)最小化 nˆ∗) ≥ V∗。理想情况下,希望最小化真实数据需求,即求解n∗ 满足v(n0+n)∗) = V∗。然而,模拟表明,大多数回归函数都是最优的,并且低估数据需要。
实际上,一种纠正少于满足V∗ 收集数据的简单方法,是施加校正因子τ≥ 0,估计满足“修正”更高目标V∗ + τ所需的数据。因此,固定一个常数τ并修改算法1,以便在每一轮满足vˆ(n0 +nˆ;θ∗)≥V∗ +τ的最小化nˆ。
为了确定该校正因子应该有多大,可视为一个超参进行拟合。例如,假设有完整的CIFAR10数据集,并且想要为未来的数据集构建一个T-轮收集策略。首先,用每个回归函数模拟τ=0的CIFAR10数据收集,获得如图所示的结果。
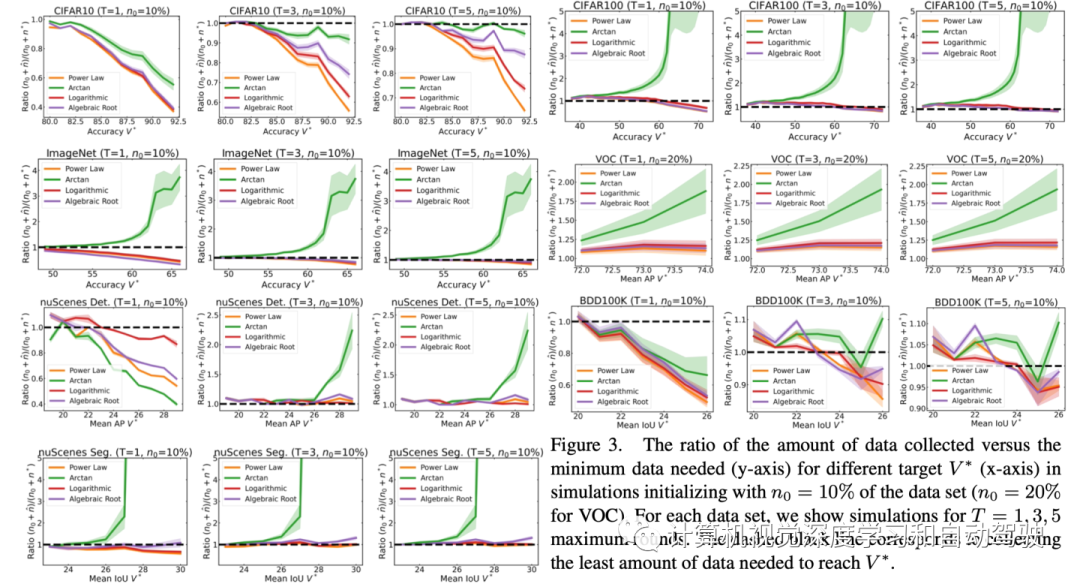
然后增加τ,直到该函数的整个比率曲线大于1。换句话说,求解最小τ,对于CIFAR10(对于给定的固定T和函数),这样数据收集策略将收集刚好足够的数据,满足所有目标值V∗ 。然后,用该拟合τ作为未来数据集的校正因子。
将校正因子与多轮数据收集相结合,可以持续收集略高于最低数据要求的数据。如表所示比较了对每个数据集在所有V∗ 取最小比率的每个回归函数采用τ的效果。用CIFAR10数据集对T和回归函数的每个设置拟合τ。
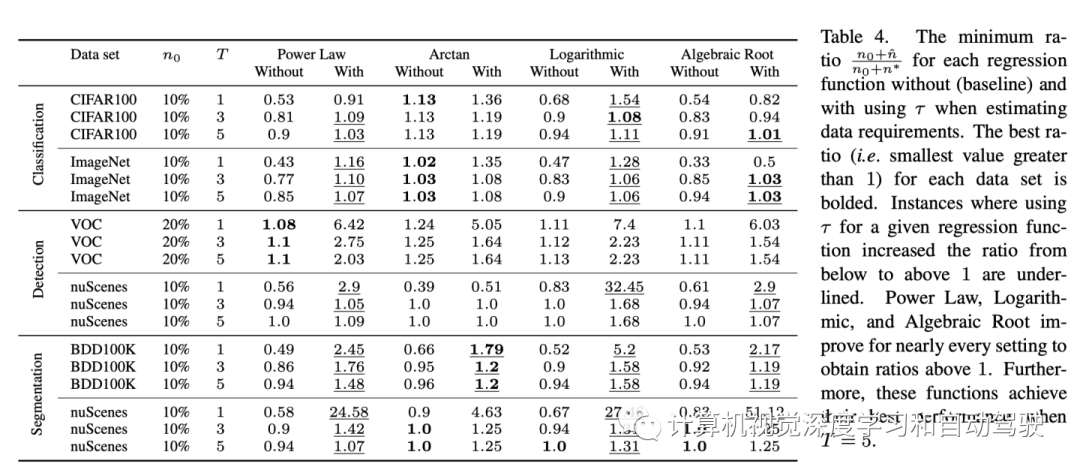
在不进行校正的情况下,幂律、对数和代数根函数对于除VOC之外的每个数据集都实现了小于1的比率。采用τ这些函数几乎总是能实现1到2之间的比率。此外,对于每个数据集,当T=5时,这3个回归函数达到各自的最低比率(高于1)。如图用τ在所有V*上对于T=5的每个数据集进一步给出模拟结果。
每个数据集的所有V*,幂律、对数和代数根函数的比率在1.03到2.5之间。此外,对于所有数据集,没有一致最佳的回归函数。例如,代数根函数在VOC中占主导地位,但当V∗ 很大幂律对 inuScenes BEV segmentation 特别有效。然而,回想一下,Arctan自然高估了数据需求,因此不会从校正中受益。
结论是,纠正三种乐观估计量(幂律、对数或代数根)中的任何一种,并五轮收集数据,就足以在满足预期目标的情况下近似地最小化收集总数据量。
数据要求的经验界
如果校正因子拟合不佳或收集轮数限制比较小,可能仍然会低估或高估数据要求。从上表中可以看出,在T=1的nuScenes分割中,不带τ的幂律可以估计出58%的所需数据,而使用τ可以估计出比所需数据多28倍的数据。
在某些应用程序中,建模可能还需要根据经验估计应该马上收集的数据量。现在考虑这样一个问题,n0个数据点还剩下T=1轮;在单轮或多轮的最后一轮中,我们必须达到数据收集目标。因此,试图获得关于需要多少数据的最坏和最佳情况估计(即上限和下限)。所有不同的回归函数都会产生一系列预测。然后,最大预测是最坏情况估计,最小预测是最佳情况估计。
对于每个数据集,设置T=1,并扫描n0和V∗,用8个回归函数估计数据需求。如图所示:顶行显示,对于每个n0和V*的实例频率,其中最乐观和最悲观的回归函数约束真实数据需求。底行进一步显示,这些上下限的均值。
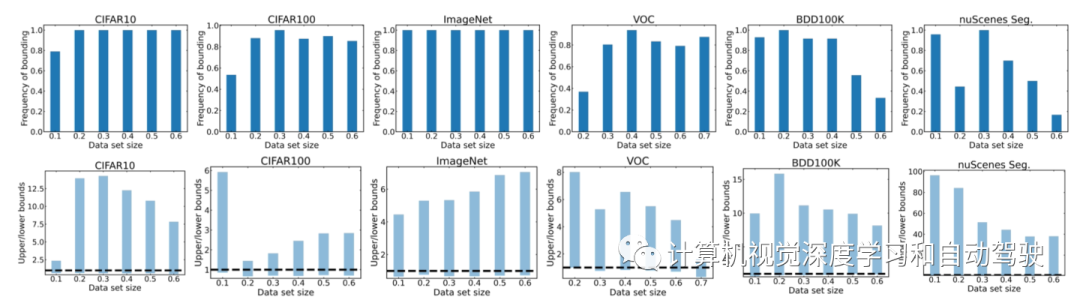
对于图像分类,在80%以上时间估计器限制真实要求。这一趋势也适用于VOC,对于n0≥ 数据集的30%,在80%以上时间内限制需求。由于BDD100K和nuScenes BEV分割是更具挑战性的数据集,限制数据需求的概率有时会降低。
由于在nuScenes上训练3-D目标检测器比其他任务在计算上要昂贵得多,这里只报告n0=10%、20%、50%的值。在这里,估计器的范围用区间[0.56, 31.1]、[0.76, 40.8]、[0.56, 26.9]中的比率分别限制了88%、91%和83%的真实数据需求。
尽管如此,结果表明,如果给一个具有大型初始数据集的单轮,能够准确估计数据需求的上下限。此外,即使有多轮收集数据,在最后一轮中,应该能够获得需求的上下界限。在实际应用中,这些界限可以引导建模得到乐观或悲观的选择,例如,如果实际训练和部署模型的deadline很严格不能错过。
-
不同技术估计的数据,要么远远多于所需数据,要么远远少于所需数据。使用多轮数据收集和低估的技术可以收集高达90%的真实所需数据量。
-
通过之前任务的模拟,可以确定哪些方法低估数据要求,并学习修正系数来解决这一不足。使用校正因子并收集多达五轮数据,最多可以收集达到任何期望性能所需最小数据量的1-2倍。
-
只剩下一轮数据收集,可以用所有回归函数来获得通常真实数据需求的限制区间。这些界限可以指导建模根据实际需求或多或少地收集数据。
- 下一篇:轴电流的产生机理及解决方案
- 上一篇:基于振动的疲劳失效分析



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
