




 广告
广告





















































GitNet: 基于几何先验的转换用于BEV分割

arXiv论文“GitNet: Geometric Prior-based Transformation for Birds-Eye-View Segmentation“,上传于22年4月第一版/7月第二版,报道华中理工和百度的工作。

BEV具有强大的空间表示能力,语义分割对于自主驾驶至关重要。由于空间差距,从单目图像估计BEV语义图是一个挑战,因为隐含地需要实现从透视图到BEV的转换和分割。
提出一种两阶段基于几何先验的变换框架GitNet,由(i)几何引导的预对齐(GPA)和(ii)基于光线的transformer(RT)组成。在第一阶段,将BEV分割解耦为透视图像分割和基于几何先验的映射,并将BEV语义标签投影到图像平面,去学习可见度-觉察的特征和可学习的几何,从而转换为BEV空间,以此做显式监督。其次,通过基于光线的transformer进一步变形预对齐的粗BEV特征,把可见性知识予以考虑。
网络的目标是从单目透视图像预测BEV空间中场景语义图。预测BEV语义图的挑战在于,输入和输出表示存在于不同的空间中,因此网络要学习从透视图像视图到正交BEV空间的转换。如图所示:
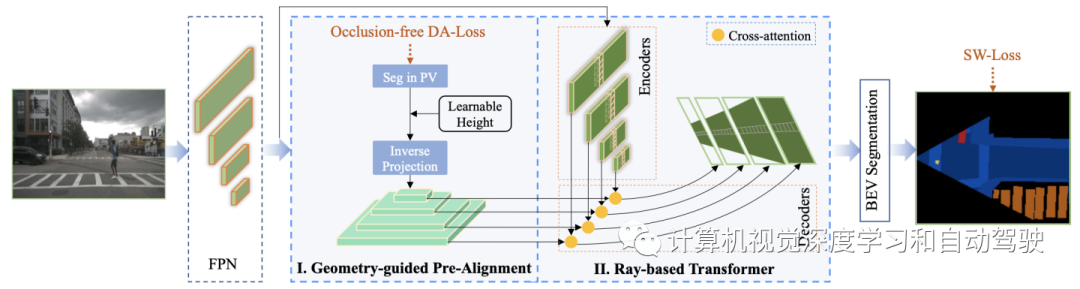
这个框架是一个两步流水线,将透视图(PV)转换为鸟瞰图。它主要由四个模块组成,(i)用于多尺度透视特征表示的特征金字塔网络(FPN),(ii)基于可学习的摄像机高度,将特征转移到BEV空间的几何引导预对齐(GPA),(iii)BEV分割前基于注意的特征增强,构成基于光线的Transformer(RT)模块,以及(iv)用于重加权不同像素专门设计的损失函数。
首先,几何引导为初始化变换的BEV特征提供外观和可见性。为了解决摄像机安装高度引起的模糊性,特别学习了高度,以便更好地对齐透视空间和BEV空间。
在获得预对齐的BEV特征后,进一步采用基于光线的transformer模块,增强BEV空间的特征变形(feature deformation),从而进行语义分割。在可学习摄像机高度的引导下,对GPA阶段进行明确监督,学习可见度-觉察特征,然后将其转换为预对齐的BEV特征。
此外,为了缓解成像引起的透视效应,以深度-觉察的方式组织投影监督损失,进一步提出self weighted DICE(SW Dice)损失来重新加权“易-难”样本。
GPA模块的架构如图所示:
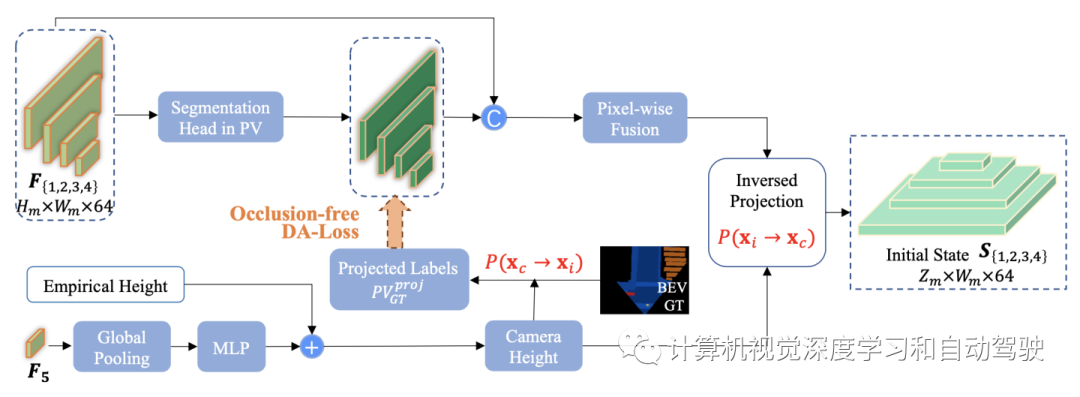
首先将金字塔图像特征输入分割头,预测由无遮挡DA丢失和投影标签强制的BEV一致概率图。通过像素级融合对BEV一致性概率图和透视特征进行进一步编码,以提取可见度感知特征。在另一个分支中,最小尺度特征F 5用于预测到经验预定义高度的偏移w.r.t。然后应用学习到的摄像机高度,将可见度感知的透视特征反向投影到BEV特征,作为后续变换阶段的初始查询。
如图是RT的架构示意图:在第二步,将常见的多头注意扩展到基于光线的Transformer(RT)。多头注意需要三个输入:查询(Q)、键(K)和值(V),表示为多头(Q,K,V);由于BEV语义分割任务需要高分辨率的特征图,计算完整图像的注意将带来高计算复杂度和GPU内存;位于同一列的透视图像素,对应于BEV的同一光线;这促使单个列或光线计算注意,这大大降低了注意的复杂性。
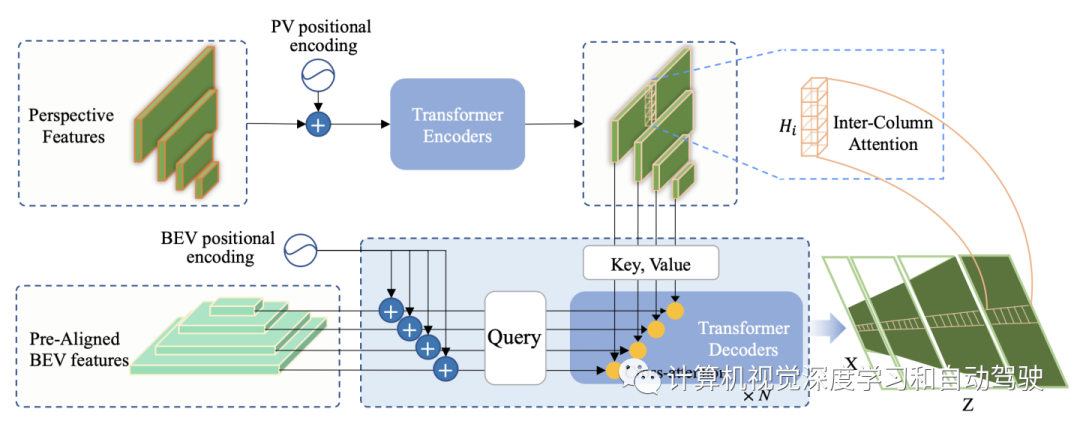
编码器的列上下文增强(CCA)技术介绍如下:如图所示,Transformer编码器的输入是从FPN中提取的透视特征{F1,F2,F3,F4},其中Fm的空间分辨率为Hm×Wm。在CCA中,每个像素通过使用多头自注意自适应地集成来自同一列的其他像素信息。进一步将空间位置编码Pm引入输入Fm,区分输入特征的位置。用正弦函数来生成空间位置编码。
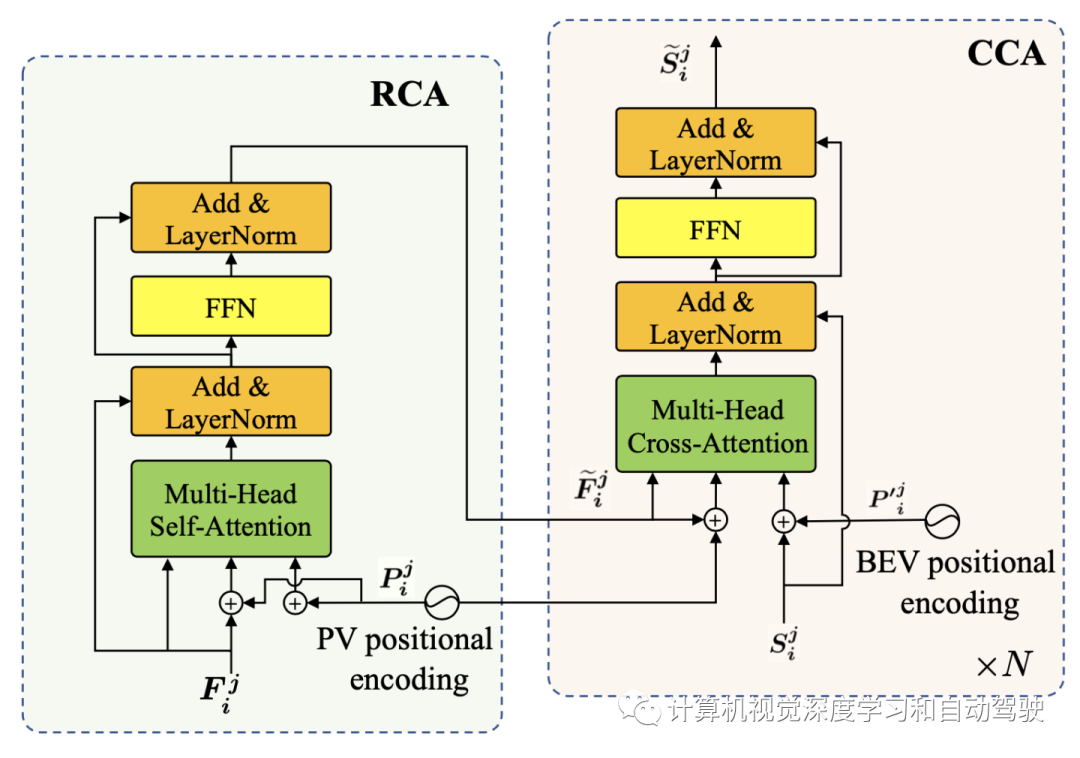
解码器基于光线的交叉注意(RCA)是这样的:transformer解码器的RCA旨在基于增强图像特征{F1,F2,F3,F4},细化预对齐块{S1,S2,S3,S4}输出。如图所示,RCA接收预对齐的BEV特征作为Query,从编码器构建的增强特征作为Key 和 Value。与CCA类似,RCA也采用空间位置编码Pm′。不同之处在于,Pm′表示BEV的位置,而Pm位于图像平面。
如图是RCA和CCA的架构图:
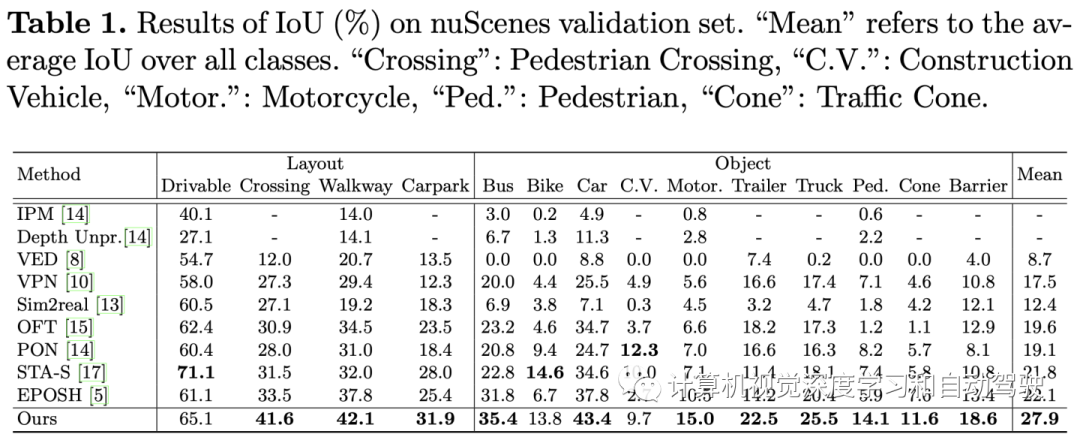
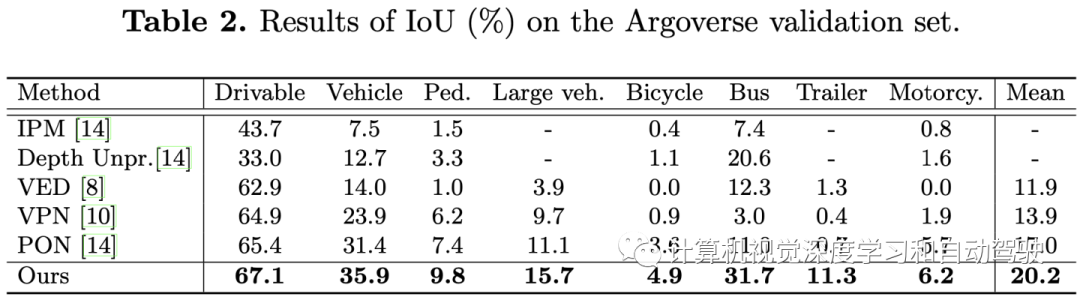
实验结果如下:




编辑推荐




最新资讯
-
风噪测试在电动汽车时代的关键作用
2025-04-29 11:34
-
汉航车辆性能测试系列之操纵稳定性测试--汉
2025-04-29 11:09
-
新能源汽车热管理系统验证体系PITMS正式发
2025-04-29 11:09
-
试验载荷谱采集
2025-04-29 11:07
-
APx500 软件演示模式 (Demo Mode) 竟有这些
2025-04-29 08:37
