




 广告
广告





















































采用可解释传感器融合Transformer的安全增强自动驾驶

arXiv论文“Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer“,2022年7月,商汤科技、多伦多大学和香港中文大学的工作。

出于安全考虑,自动驾驶汽车的大规模部署不断推迟。一方面,缺乏全面的场景理解会导致对罕见但复杂的交通情况的处理脆弱性,例如未知目标的突然出现。然而,从全局上下文推理需要访问多种类型的传感器,并充分融合多模态传感器信号,这很难实现。另一方面,学习模型中缺乏可解释性也阻碍安全性,故障原因无法验证。
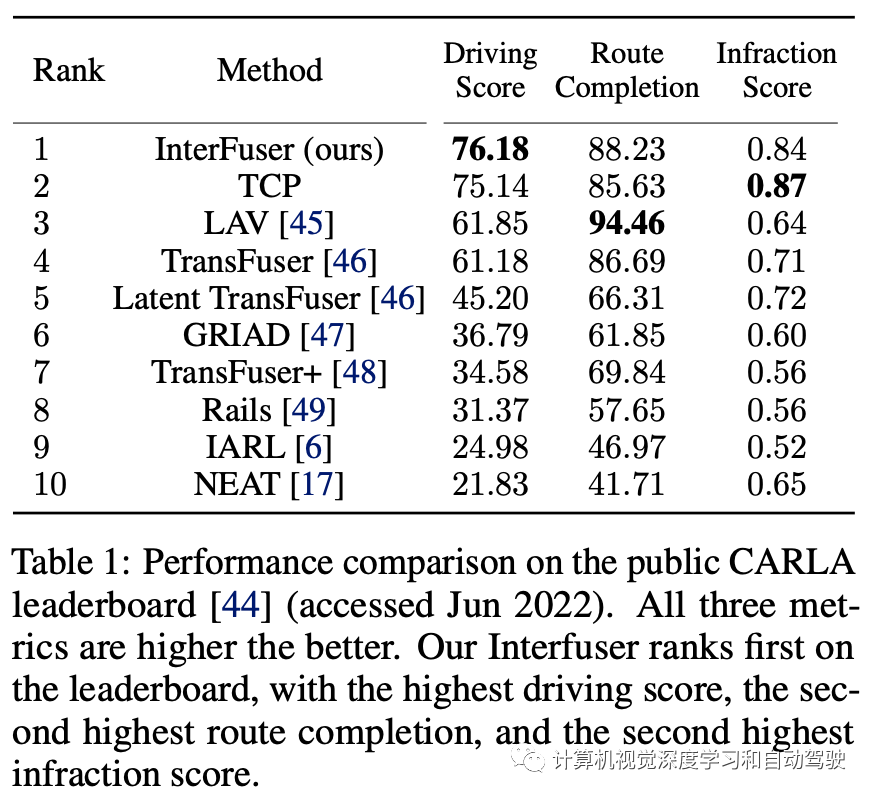
本文提出一种安全增强型自主驾驶框架,称为可解释传感器融合Transformer(InterFuser),用于全面处理和融合来自多模态多视图传感器的信息,实现全面的场景理解和对抗事件(adversarial event)检测。此外,该框架生成了中间可解释特征,叫安全思维图(safety mind map),这些特征提供了更多语义,并用来更好地将动作约束在安全集内。在CARLA基准上进行了大量实验,在公共CARLA Leaderboard上排名第一。
如图所示,安全思维图(safety mind map)提供关于周围目标和交通标志的信息:
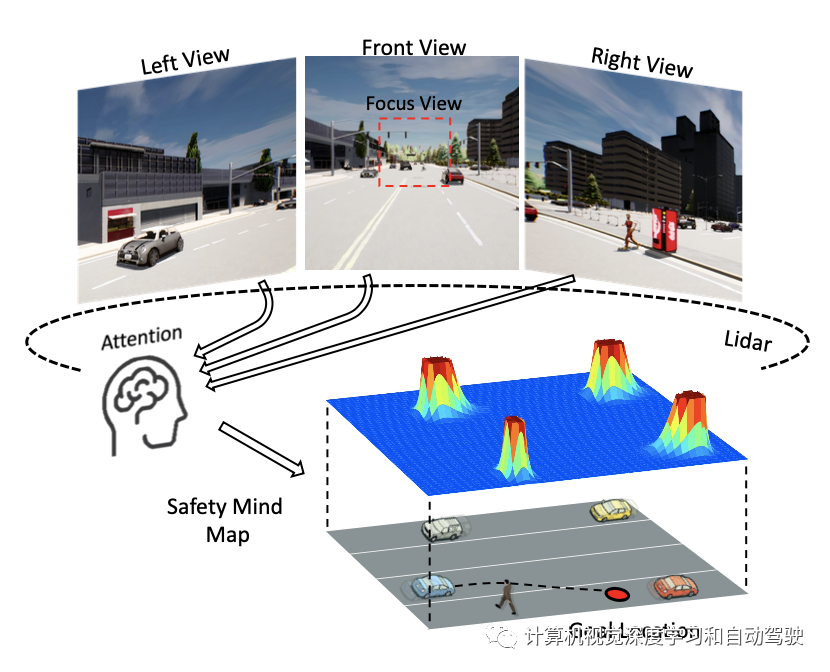
这个模型有明确的失败条件和原因,通过揭示感知和决策过程,是可以改进的。此外,此中间可解释信息作为安全约束启发式,可以将动作约束在安全动作集中,进一步提高驾驶安全性。
如图所示,该框架由三个主要组成部分组成:1)多视图多模态融合Transformer编码器,集成多个RGB摄像机和激光雷达的信号;2) transformer解码器提供低级动作和可解释中间特征,包括自车的未来轨迹、目标密度图和交通规则信号;3) 一种安全控制器,利用可解释中间特征将低级控制约束在安全集内。
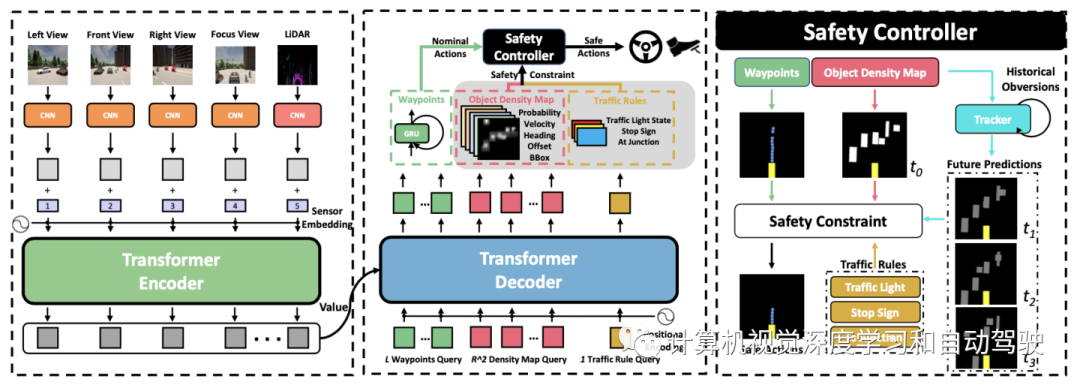
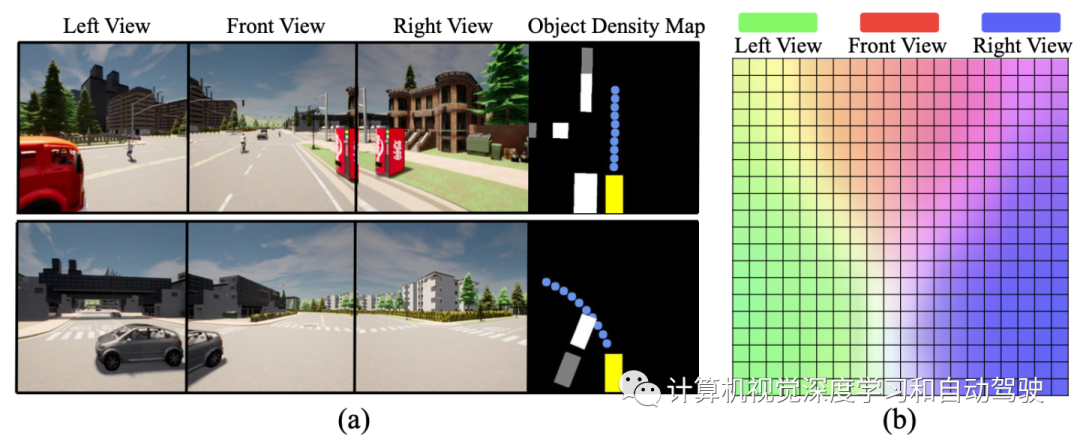
输入表示四个传感器,包括3个RGB摄像机(左、前和右)和一个激光雷达传感器。从3个摄像机获得4个图像输入。除了左、前和右图像输入{Ileft、Ifront、Iright},还设计聚焦视图图像(focusing-view image)输入Ifocus,通过裁剪前RGB图像的中心来捕捉远处交通灯的状态。对于激光雷达点云,转换为2-D BEV网格上的2-bin直方图,从而生成双通道激光雷达BEV投影图像输入Ilidar。
输出表示两种类型的输出:安全不敏感输出和安全敏感输出。对安全不敏感的输出,InterFuser预测L=10个航路点的路径,以便自车驾驶;它指导自车的未来驾驶路线。然而在没有适当速度的情况下沿道路行驶可能是不安全的,并且违反实际的交通规则,因此InterFuser还预测安全敏感输出,包括目标密度图和交通规则信息。目标密度图为检测目标(如车辆、行人和自行车)提供7个特征。地图覆盖自车辆前方R米和两侧R/2米。地图的7个通道是目标存在的概率、距网格中心的2-D偏移、目标边框的大小、方向和速度。此外,InterFuser还输出交通规则信息,包括红绿灯状态、前方是否有停车标志以及自车是否位于十字路口。
每个图像输入和激光雷达输入I的主干用传统的CNN主干ResNet生成低分辨率特征图。对于每个传感器输入的特征映射f,首先进行1×1卷积以获得较低的通道特征图。然后将每个特征图z的空间维度叠为1-D,生成token。固定2D正弦位置编码添加到每个token中,保留每个传感器输入的位置信息,并添加可学习传感器嵌入以区分来自N个不同传感器的token。最后,将来自所有传感器的token连接起来,通过K个标准transformer层的transformer编码器。每个K层由多头自注意、MLP块和层归一化(LN)组成。
解码器遵循标准Transformer架构,用K层多头自注意机制转换一些查询嵌入。设计三种类型查询:L路点查询、R^2密度地图查询和交通规则查询。在每个解码器层,用这些查询通过注意机制从多模态多视图特征中查询空间信息。由于transformer解码器置换不变,因此上述查询嵌入对解码器是相同的,不产生不同的结果。为此,将可学习的位置嵌入添加到这些查询嵌入中。然后,这些查询结果通过以下预测头独立解码为L路点、1个密度图和1个交通规则。
解码器后面是三个并行预测模块,分别预测路点、目标密度图和交通规则。对于路点预测,用单层GRU做自动回归预测L个未来路点序列。对于密度图预测,来自transformer解码器的相应嵌入通过ReLU激活函数的3层MLP来获得特征图。然后将其重塑获得目标密度图。对于交通规则预测,来自transformer解码器的相应嵌入通过单个线性层来预测前方红绿灯的状态、前方是否有停车标志以及自车是否位于十字路口。
通过transformer解码器输出的路点和中间可解释特征(目标密度图和交通规则),将动作约束到安全集。具体来说,用PID控制器来获得两个低级动作。横向转向动作使自车与所需航向ψd对齐,该航向仅仅是前两个路点的平均航向。纵向加速度动作旨在捕捉所需速度vd。vd的确定需要考虑周围目标以确保安全,为此,求助于目标密度图。
目标密度图M网格中的目标,由目标存在概率、距网格中心的2-D偏移量、2-D边框和航向角来描述。一旦满足以下标准之一,就会识别网格为目标存在:1)如果目标在网格的存在概率高于threshold 1。2)如果网格的目标存在概率是周围网格的局部最大值,并且大于threshold 2(threshold 2 < threshold 1)。虽然第一条规则是直观的,但第二条规则用于识别具有高度位置不确定性的目标存在。除了目标的当前状态外,安全控制器还需要考虑其未来轨迹。首先设计一个跟踪器来监测和记录它们的历史动态。然后,通过移动平均(MA)将其历史动态向前传播来预测其未来轨迹。
利用恢复的周围场景和这些目标的未来预测,可以获得自车在时间步t可以行驶的最大安全距离st。然后通过求解线性规划问题得出具有增强安全性的期望速度vd。注意,为了避免不安全集合和未来的安全困难,还增加目标的形状特征,并考虑活动极限和自车的动态约束。除了目标密度图外,预测的交通规则也用于安全驾驶。如果红绿灯不亮或前方有停车标志,自车将紧急停车。
注意,虽然可以使用更先进的轨迹预测方法和安全控制器[,但经验发现,移动平均和线性规划控制器进行动态传播已经足够。对于更复杂的驾驶任务,这些高级算法可以很容易地集成到框架中。
实验结果如下:
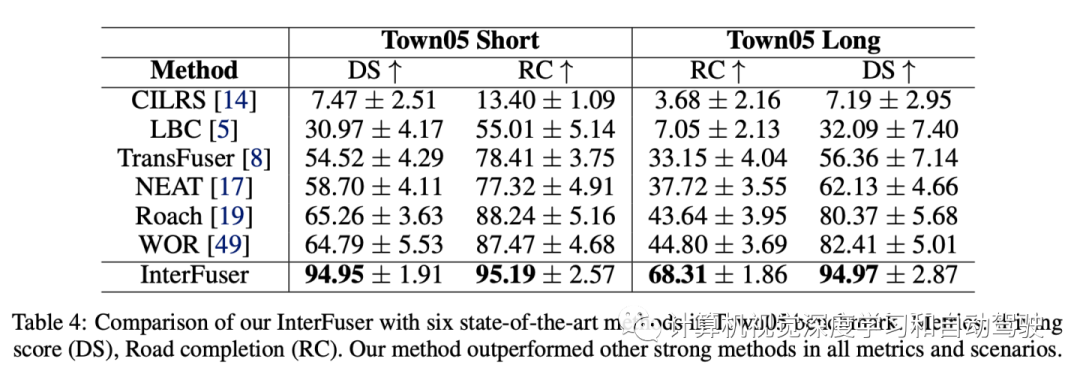
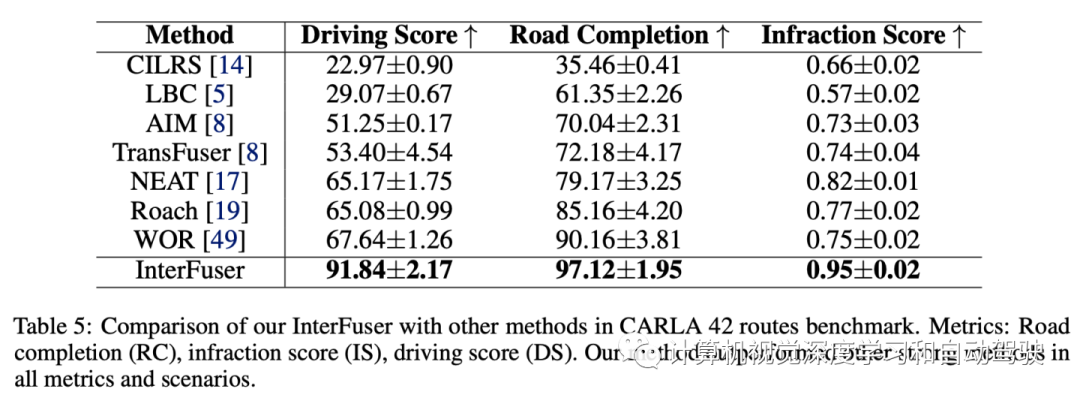
- 下一篇:某型纯电动汽车路噪仿真与优化
- 上一篇:自动驾驶落地之路——道阻且长,而行之将至



编辑推荐




最新资讯
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
-
博世发布突破性电解槽技术
2025-04-02 20:23
-
ESI 全新BM-Stamp软件在汽车行业冲压仿真精
2025-04-02 09:27
-
车辆软件测试工程师的工作内容---解读GBT德
2025-04-02 08:41
-
浅谈机动车检测行业合规经营与检验人员职业
2025-04-02 08:40
