




 广告
广告





















































ViP3D: 通过3D智体query实现端到端视觉轨迹预测

arXiv论文“ViP3D: End-to-end Visual Trajectory Prediction via 3D Agent Queries“,22年8月2日上传,清华、上海(姚)期智研究院、CMU、复旦、理想汽车和MIT等的联合工作。

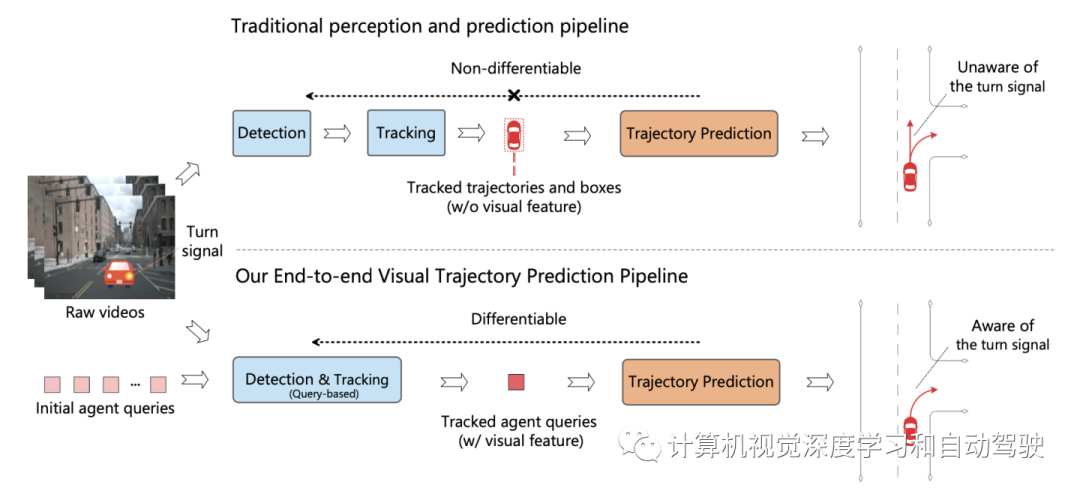
现有的自主驾驶流水线将感知模块与预测模块分开。这两个模块通过人工选择的特征进行通信,如智体框和轨迹作为接口。由于这种分离,预测模块仅从感知模块接收部分信息。更糟糕的是,来自感知模块的错误可能会传播和累积,从而对预测结果产生不利影响。
这项工作提出ViP3D,一种视觉轨迹预测流水线,利用原始视频的丰富信息预测场景中智体的未来轨迹。ViP3D在整个流水线中使用稀疏智体query,使其完全可微分和可解释。此外,提出一种新的端到端视觉轨迹预测任务的评估指标,端到端预测精度(EPA,End-to-end Prediction Accuracy),其在综合考虑感知和预测精度的同时,对预测轨迹与地面真实轨迹进行评分。
如图是传统多步级联流水线与ViP3D的比较:传统的流水线涉及多个不可微模块,例如检测、跟踪和预测;ViP3D将多视图视频作为输入,以端到端的方式生成预测轨迹,可有效利用视觉信息,比如车辆转向信号。
ViP3D旨在以端到端的方式解决原始视频的轨迹预测问题。具体而言,给定多视图视频和高清地图,ViP3D预测场景中所有智体的未来轨迹。
ViP3D的总体流程如图所示:首先,基于查询的跟踪器处理来自周围摄像机的多视图视频,获得有视觉特征所跟踪智体的query。智体query中的视觉特征,捕获智体的运动动力学和视觉特征,以及智体之间的关系。之后,轨迹预测器将跟踪智体的query作为输入,并与HD地图特征相关联,最后输出预测的轨迹。
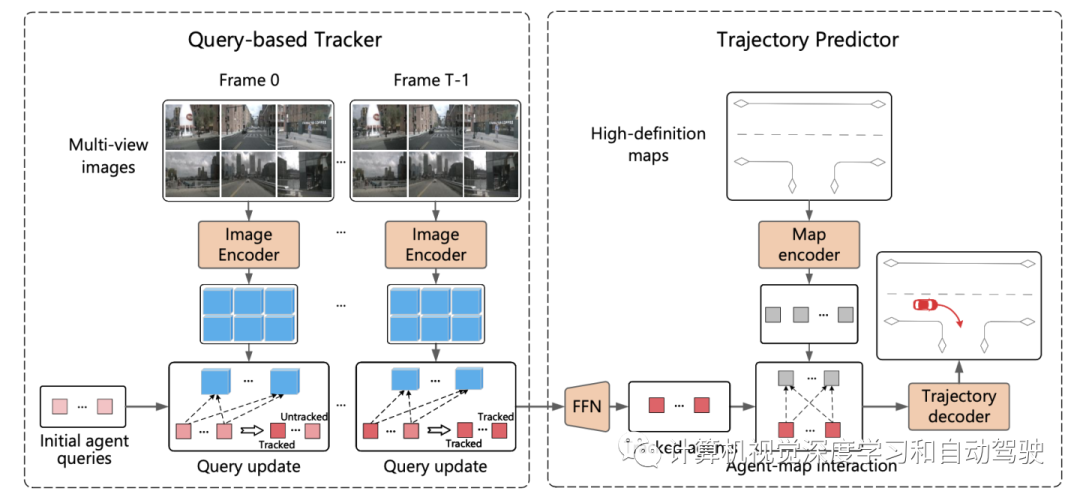
基于query的跟踪器从环绕摄像机的原始视频中提取视觉特征。具体而言,对于每一帧,按照DETR3D提取图像特征。对于时域特征聚合,按照MOTR(“Motr: End-to-end multiple-object tracking with transformer“. arXiv 2105.03247, 2021)设计了一个基于query的跟踪器,包括两个关键步骤:query特征更新和query监督。智体query会随时间更新,建模智体的运动动力学。
大多数现有的轨迹预测方法可分为三个部分:智体编码、地图编码和轨迹解码。在基于query的跟踪之后,获得被跟踪智体的query,该query可以被视为通过智体编码获得的智体特征。因此,剩下的任务是地图编码和轨迹解码。
分别将预测和真值智体表示为无序集Sˆ和S,其中每个智体由当前时间步的智体坐标和K个可能的未来轨迹表示。对于每个智体类型c,计算Scˆ和Sc之间的预测精度。将预测智体和真值智体之间的成本定义为:

这样Scˆ和Sc之间的EPA定义为:
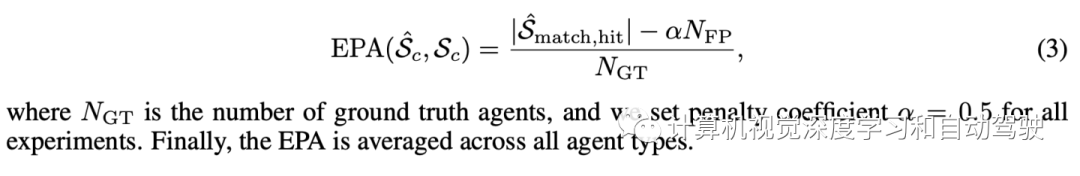
实验结果如下:
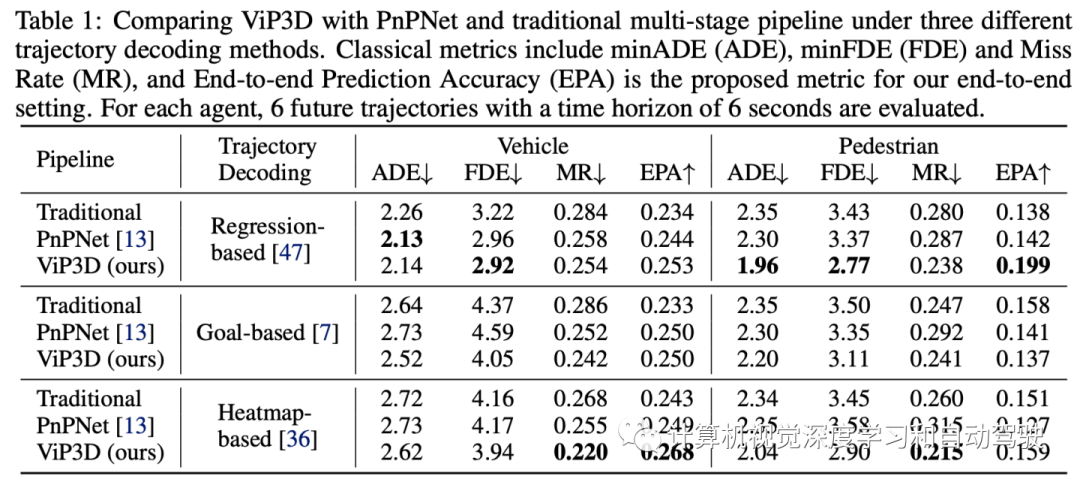
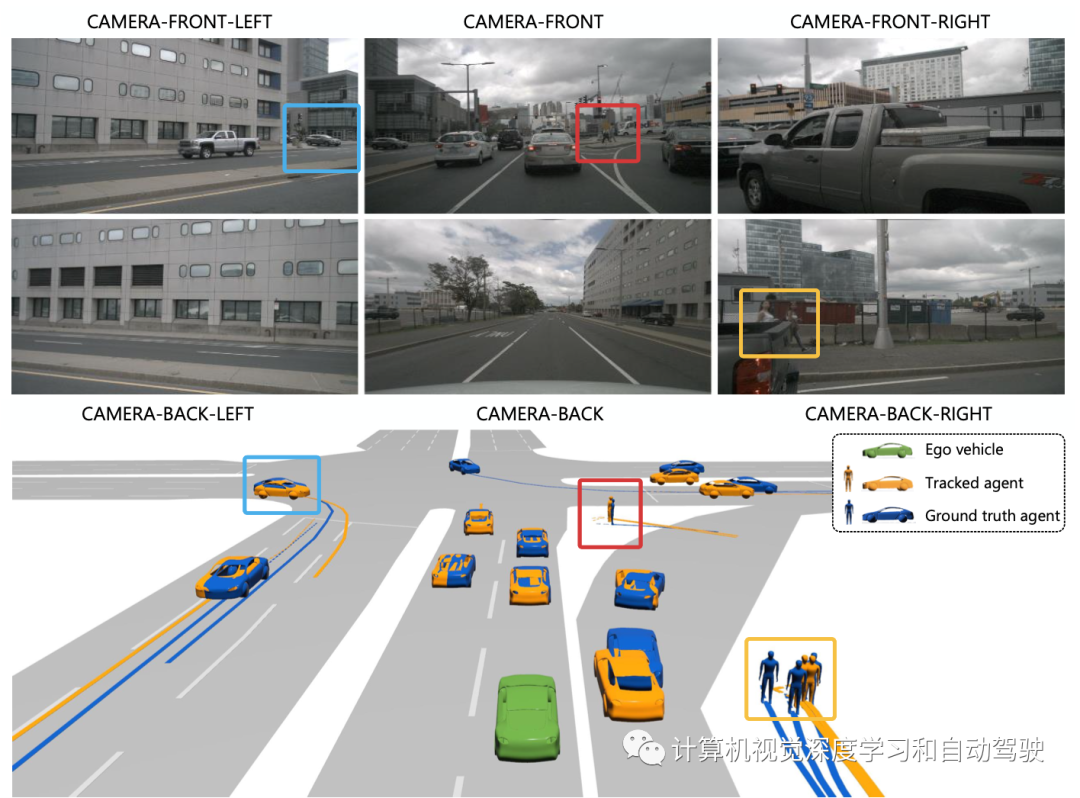

注:这个目标渲染做的不错。



编辑推荐




最新资讯
-
奇石乐推出用于DAQ数据采集系统的KiStudio
2025-04-28 17:51
-
全球首次!IVISTA 2023版修订版引入带灯光
2025-04-28 09:59
-
我国首批5G毫米波行业标准送审稿审查通过
2025-04-28 08:56
-
5/16 厦门- 新能源汽车电驱测试技术的创新
2025-04-28 08:53
-
国内首个汽车电磁防护技术验证体系EMTA正式
2025-04-28 08:49
