




 广告
广告





















































RadSegNet: 雷达摄像头融合

arXiv论文“RadSegNet: A Reliable Approach to Radar Camera Fusion“,22年8月8日,来自UCSD的工作。

用于自动驾驶的感知系统在极端天气条件下难以表现出鲁棒性,因为主要传感器的激光雷达和摄像机等性能会下降。为了解决这个问题,摄像机-雷达融合系统为全天候可靠的高质量感知提供了机会。摄像机提供丰富的语义信息,而雷达可以在所有天气条件下克服遮挡工作。
当摄像机输入退化时,最先进的融合方法表现不佳,本质上导致失去全天候的可靠性。与这些方法相反,RadSegNet,用独立信息提取的设计理念,真正实现在所有条件下的感知可靠性,包括遮挡和恶劣天气。在基准Astyx数据集上开发并验证了提出的系统,并在RADIATE数据集上进一步验证。与最先进的方法相比,RadSegNet在Astyx数据集,平均精度得分提高27%,在RADIATE数据集,提高41.46%。
在良好的条件下,系统应能够使用来自摄像机的丰富纹理和语义信息,以及来自雷达的所有目标的深度和大小等有用信息,而在良好天气出现遮挡或远处目标或恶劣天气下的图像退化而导致摄像机不可靠的情况下,系统仍应能够可靠地使用雷达数据。
RadSegNet,主要通过两个设计原则来实现所需的功能。第一个原则是基于这样一种认识,即对于雷达,BEV表示法比透视图具有多个优势,尤其是在遮挡的情况下。因此,作为其核心,RadSegNet用雷达BEV表示进行检测,对雷达中存在的所有信息进行编码。接下来,注意到摄像头中丰富的纹理和语义信息主要用于清晰地识别场景中的目标。因此,从摄像机RGB图像中独立提取语义特征。
然而,将从摄像机提取的语义信息传播到雷达数据仍然是一项具有挑战性的任务,因为摄像机没有深度信息。为了克服这一挑战,RadSegNet创建一种语义点网格(SPG,semantic-point-grid)表示,将摄像机图像中的语义信息编码到雷达点云中。为了将语义与雷达点相关联,SPG查找每个雷达点的摄像头像素对应关系,而不是将摄像头图像投影到雷达BEV。因此,SPG编码从摄像机中提取信息,添加到雷达中,并在此增强的雷达表示上检测,这样提取所需的独立信息。
即使在摄像机输入不可靠的情况下,RadSegNet仍然可以用雷达数据可靠地工作。请注意,这些条件包括恶劣天气以及晴朗天气下的遮挡和远距离,在这种情况下,摄像机数据可能变得不可靠。
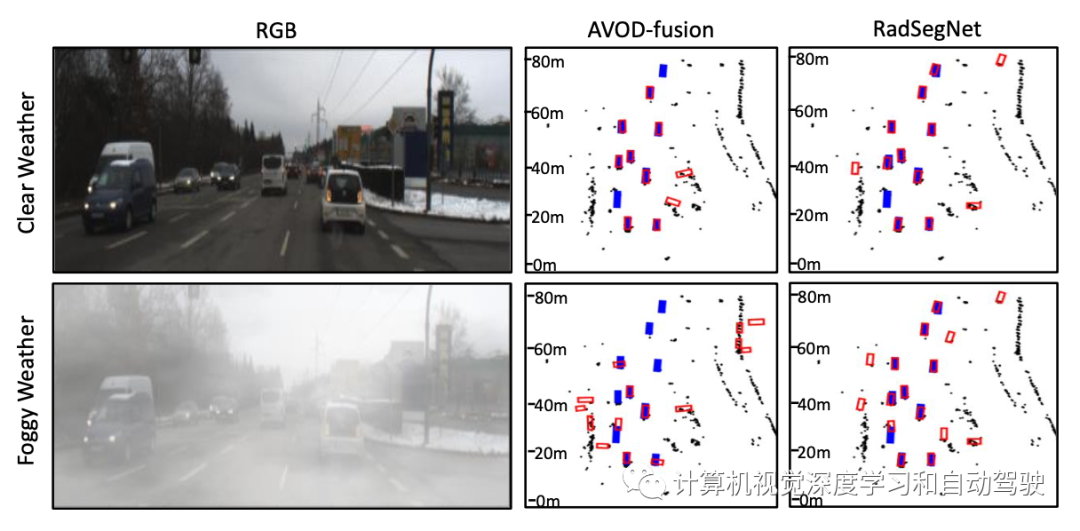
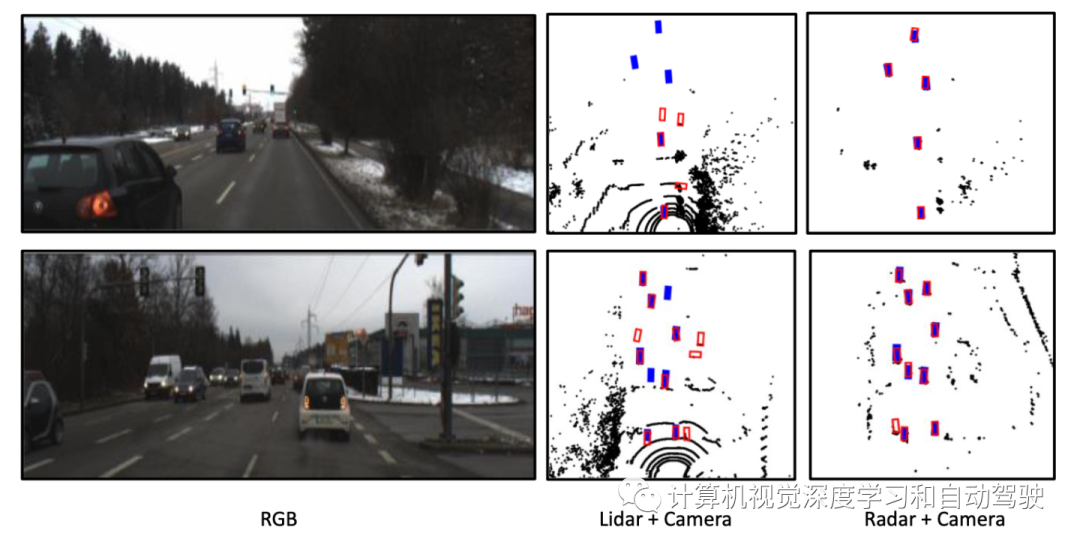
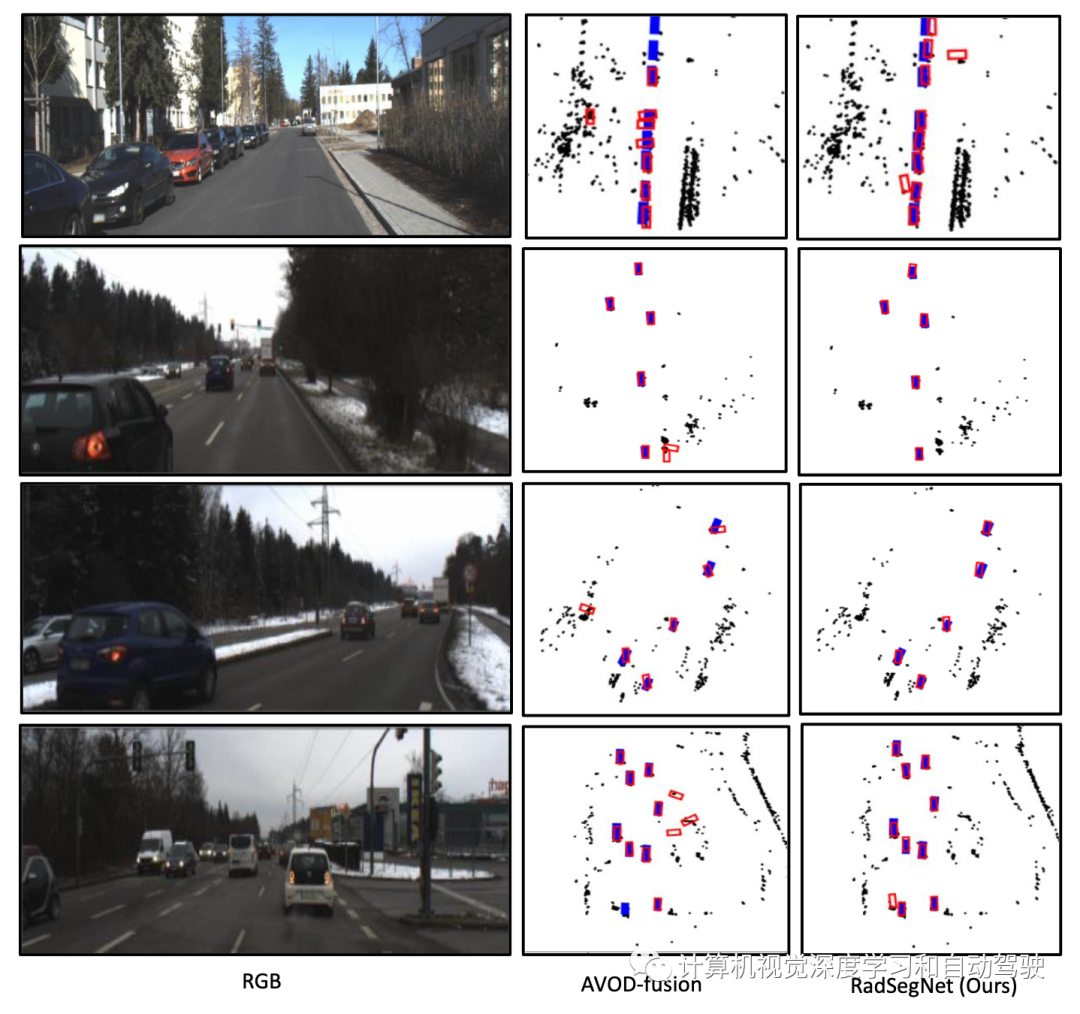
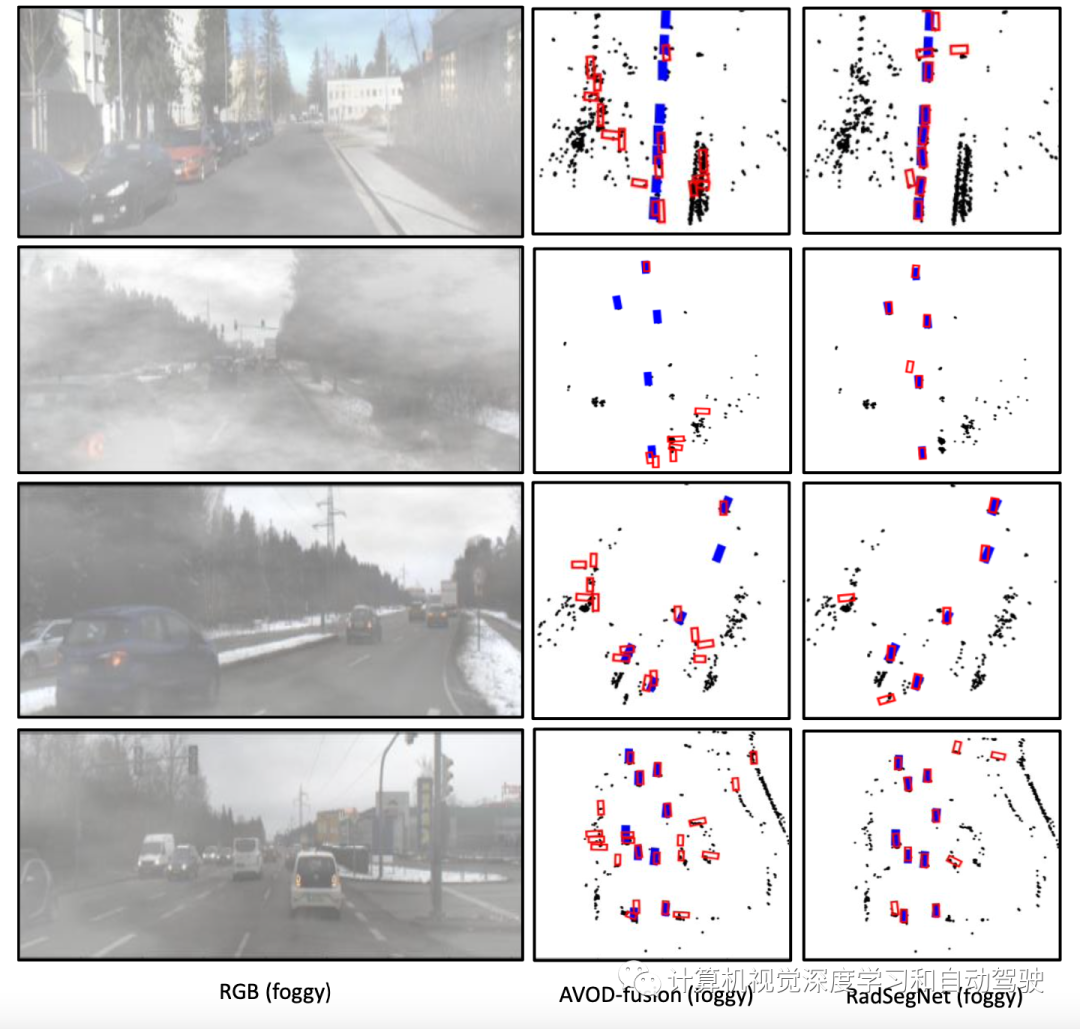
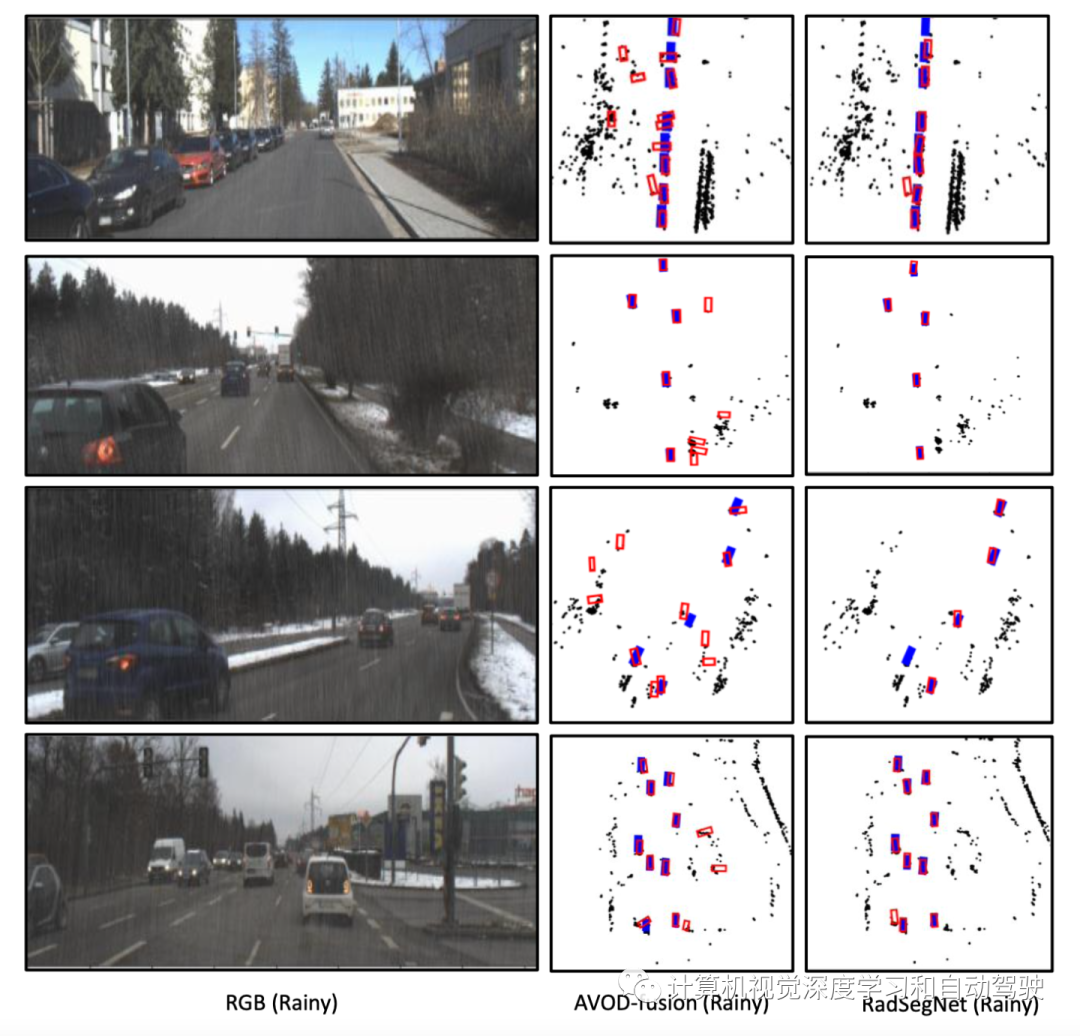
如图所示是摄像机输入增加人工雾时雷达摄像机融合架构的性能。AVOD融合作为基准方法(“Low-level sensor fusion network for 3d vehicle detection using radar range-azimuth heatmap and monocular image“. ACCV‘2020)显著恶化,而RadSegNet方法即使在雾中也能继续提供鲁棒的结果。蓝色盒是真值和红色盒是预测结果。
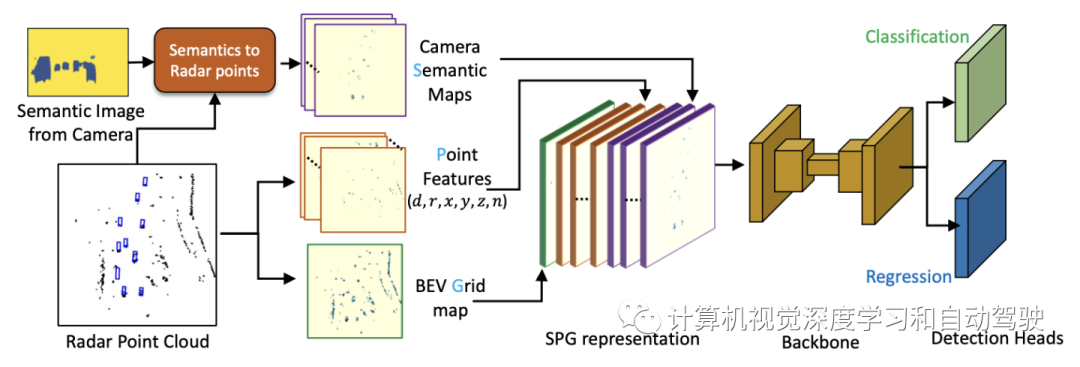
如图所示是RadSegNet一览:利用来自SPG模块的编码来检测目标,编码由来自语义分割网络的语义特征以及基于雷达点的特征和占用网格生成。这些编码图被连接并通过边框检测网络。
雷达用与激光雷达相同的反射飞行时间(ToF)分析来生成点,但工作波长不同。虽然激光雷达用纳米波长信号,由于表面散射,其分辨率非常高,但雷达用毫米波,其中反射功率分为镜面反射和漫射散射。原始雷达数据虽然密集,但包含背景热噪声或多径噪声。
雷达数据通常也会受到恒虚警率(CFAR)滤波的影响,从而产生轻量稀疏的点云输出。因此,雷达点云中的目标边缘定义不如激光雷达点云清晰。例如,在雷达点云中,源自墙壁的点群可能具有与源自汽车的点群相似的空间扩展。直接从雷达点云中学习任何基于形状的特征,想区分感兴趣的目标(汽车、行人等)和背景目标,这种效应使其具有挑战性。
然而,与此同时,由于毫米波段传输的因素,雷达还提供了以下独特的优势:a)比激光雷达提供更长的感知距离,因为波长更高的信号具有更低的自由空间功率衰减。这允许雷达波传播更长的距离。b) 能够看穿遮挡的车辆,因为其信号会从地面反弹,能够感知完全遮挡的车辆。c) 全天候传感器,因为毫米波的波长更大,能够在雾、雪和雨等不利条件下不受影响地穿透。
用于表示输入数据的视图对目标检测任务的深度学习体系结构的性能有重大影响。研究表明,只需将数据从透视摄像机视图转换为3D/BEV视图,即可获得性能提升。
这背后的原因是,在透视图中,存在深度的尺度多义以及遮挡造成的目标重叠。在2D透视图图像上进行2D卷积等局部计算,可以用同一内核处理不同深度的目标。这使目标检测任务更难学习。另一方面,BEV表示法能够在不同深度清晰地分离目标,在部分和完全遮挡目标的情况下具有明显优势。
BEV占用网格为了生成BEV表示,通过折叠高度维将雷达点投影到2-D平面上。然后将该平面离散为占用网格。每个网格元素是一个指示变量,如果它包含雷达点,则其值为1,否则表示为0。该BEV占用网格还保留无序点云点之间的空间关系,并以更结构化的格式存储雷达数据。
BEV占用网格为雷达提供了最佳表示,并为未排序的雷达点云提供了次序。然而,BEV网格也将传感空间离散为网格,从而消化细化边框所需的有用信息。为了保留这些信息,将基于点的特征作为附加通道添加到BEV网格中。具体来说,添加笛卡尔坐标、多普勒信息和强度信息作为附加特征。
为了对高度信息进行编码,将高度维度(y)分为7个不同的级别,并创建7个通道,每个高度bin一个通道,从而生成高度直方图。笛卡尔坐标(x,y,z)有助于细化预测的边框。n通道包含该网格元素中存在的点数。n的数值通常与表面积和反射功率成比例,这有助于细化边框。
先说摄像头语义特征。
摄像头图像中丰富的纹理和语义信息对于理解场景和识别场景中的目标非常有用。这一信息与雷达很好地互补,在雷达中,点云的不均匀性使得学习识别目标特征更加困难。在恶劣条件下保持可靠性的同时,用这种互补性质的关键点是,首先以场景语义的形式从摄像头图像中提取有用信息,然后用来增强从雷达获得的BEV表示。
与每个目标集的特征融合相比,该方法在两种模式的信息提取之间保持了清晰的分离,因此即使一个输入退化,也能可靠地执行。用鲁棒的预训练语义分割网络从场景中存在目标的摄像头图像中获得语义掩码。然而,仍然需要在不存在摄像头图像深度信息的情况下将该信息添加到雷达BEV表征中。
如何将语义添加到SPG呢?
将基于摄像头的语义与雷达点相关联,需要为语义分割网络的每个输出目标类创建单独图。这些图的大小与BEV占用网格相同,并做为语义特征通道。为了获得每个网格元素的语义特征通道值,首先将雷达点变换为摄像机坐标。接下来,在摄像头图像中找到距离该变换点最近的像素,并用该像素的语义分割输出作为SPG语义特征通道值。
如果多个雷达点属于同一网格元素,则对所有生成的语义通道值进行平均。这些特征通道包含从摄像机中提取的语义信息,有助于从雷达BEV占用网格中检测目标。它们有效地减少了雷达可能产生的误报预测,因为由于在雷达数据中固有的不均匀性,雷达在识别目标时可能会糊涂。
如图显示如何用雷达BEV网格对汽车类的语义特征进行编码的示例。
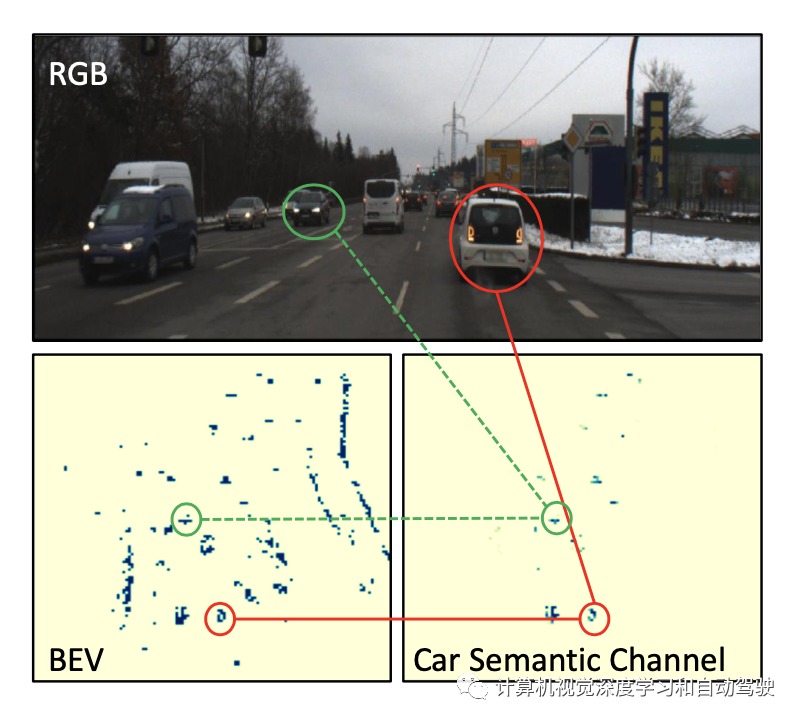
请注意,RadSegNet中用的摄像头融合形式没有过滤掉任何雷达点,同时更好地利用了两种模式带来的优势。这意味着,在基于摄像机的特征信息较少的情况下,场景中的所有目标对雷达仍然可见,从而防止性能大幅下降。来自摄像机的纹理和高分辨率信息被浓缩成语义特征,这有助于雷达的全天候、远距离和遮挡的鲁棒感知。
通过SPG编码生成的每个BEV图都被传递到深度神经网络中,用于特征提取和边框预测。对于主干特征提取,用带跳连接的编码器-解码器网络。在编码阶段用4级下采样层,每个阶段用3个卷积层来提取不同尺度的特征,然后在上采样阶段通过跳连接来组合所有中间特征生成最终的特征集。用基于锚点框(SSD)的检测架构,分类和回归头生成预测。分类头预测输出边框的置信度得分,回归头学习如何细化其维度。
图像分割网络用来自DeeplabV3+实现提供的预训练语义分割模型。在Cityscapes数据集上训练的ResNet-101模型进行语义分割任务。选择CenterFusion作为基线之一,一种基于透视图的摄像头-雷达融合方法。在这种方法中,创建雷达点云的特征图,并将其与相应的基于图像的特征图一起处理执行检测。另外一个是CenterNet,纯摄像机方法。CenterNet本质上是CenterFusion,没有相应的雷达数据。预训练的网络比在Astyx数据集上从头训练网络表现更好。
基于多视图聚合的基线方法是一个雷达R-A热图和摄像头融合的方法,用AVOD架构执行雷达-摄像头融合。称为AVOD融合,这也是传感器融合的SOTA方法。
实验结果如下:
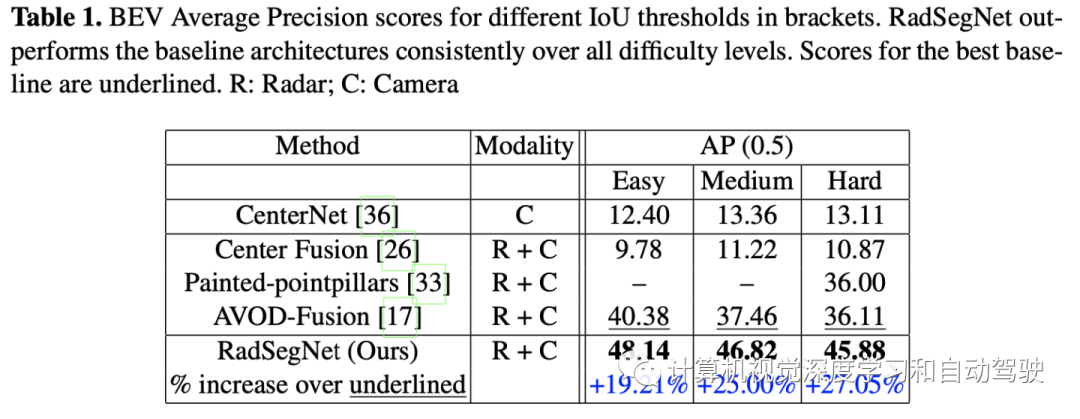
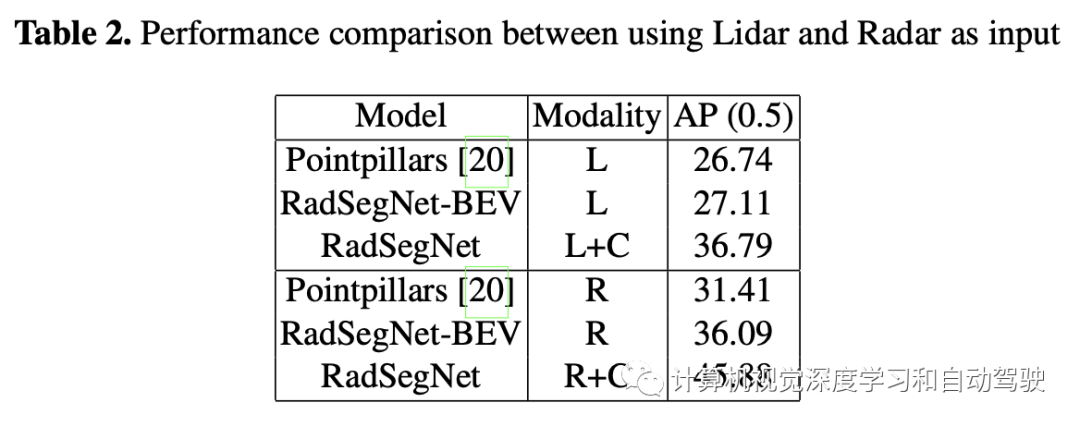
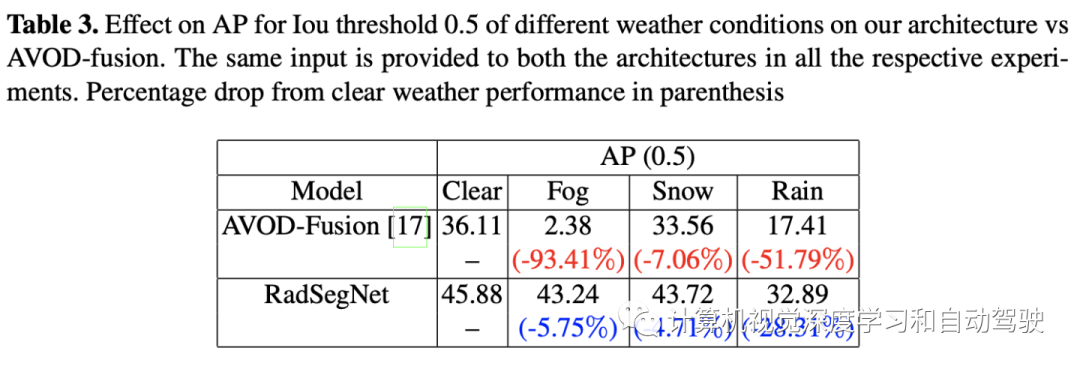
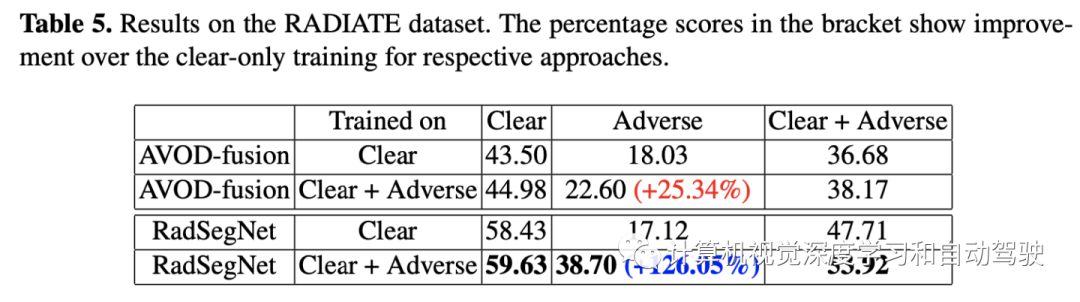

Astyx数据集结果

Astyx数据集结果
 Astyx数据集结果
Astyx数据集结果
 Astyx数据集结果
Astyx数据集结果
 Astyx数据集结果
Astyx数据集结果
 Astyx数据集结果
Astyx数据集结果
- 下一篇:某混动专用箱方案设计及动力性仿真
- 上一篇:汽车座椅舒适性试验解读 之 静载试验



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
