




 广告
广告





















































自动驾驶系统的传感器标定方法

/ 导读 /
传感器标定是自动驾驶的基本需求,一个车上装了多个/多种传感器,而它们之间的坐标关系是需要确定的。湾区自动驾驶创业公司ZooX的co-founder和CTO是Sebastia Thrun的学生Jesse Levinson,他的博士论文就是传感器标定。
这个工作可分成两部分:内参标定和外参标定,内参是决定传感器内部的映射关系,比如摄像头的焦距,偏心和像素横纵比(+畸变系数),而外参是决定传感器和外部某个坐标系的转换关系,比如姿态参数(旋转和平移6自由度)。
摄像头的标定曾经是计算机视觉中3-D重建的前提,张正友老师著名的的Zhang氏标定法,利用Absolute Conic不变性得到的平面标定算法简化了控制场。
这里重点是,讨论不同传感器之间的外参标定,特别是激光雷达和摄像头之间的标定。
另外在自动驾驶研发中,GPS/IMU和摄像头或者激光雷达的标定,雷达和摄像头之间的标定也是常见的。不同传感器之间标定最大的问题是如何衡量最佳,因为获取的数据类型不一样:
-
摄像头是RGB图像的像素阵列;
-
激光雷达是3-D点云距离信息(有可能带反射值的灰度值);
-
GPS-IMU给的是车身位置姿态信息;
-
雷达是2-D反射图。
这样的话,实现标定误差最小化的目标函数会因为不同传感器配对而不同。
另外,标定方法分targetless和target两种,前者在自然环境中进行,约束条件少,不需要用专门的target;后者则需要专门的控制场,有ground truth的target,比如典型的棋盘格平面板。
这里仅限于targetless方法的讨论,依次给出标定的若干算法。
首先是手-眼标定
这是一个被标定方法普遍研究的,一定约束条件下的问题:可以广义的理解,一个“手”(比如GPS/IMU)和一个“眼”(激光雷达/摄像头)都固定在一个机器上,那么当机器运动之后,“手”和“眼”发生的姿态变化一定满足一定的约束关系,这样求解一个方程就可以得到“手”-“眼”之间的坐标转换关系,一般是AX=XB形式的方程。
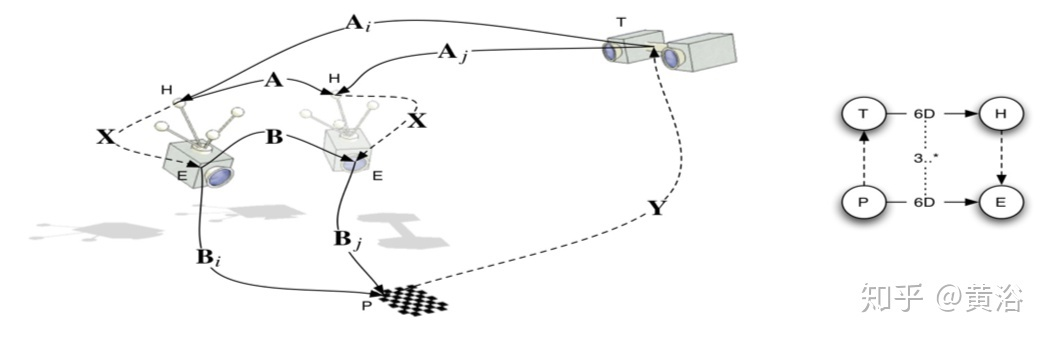
手眼系统分两种:eye in hand和eye to hand,我们这里显然是前者,即手-眼都在动的情况。
手眼标定分两步法和单步法,后者最有名的论文是“hand eye calibration using dual quaternion"。一般认为,单步法精度高于两步法,前者估计旋转之后再估计平移。
这里通过东京大学的论文“LiDAR and Camera Calibration using Motion Estimated by Sensor Fusion Odometry”来看看激光雷达和摄像头的标定算法。
显然它是求解一个手-眼标定的扩展问题-,即2D-3D标定,如图所示:
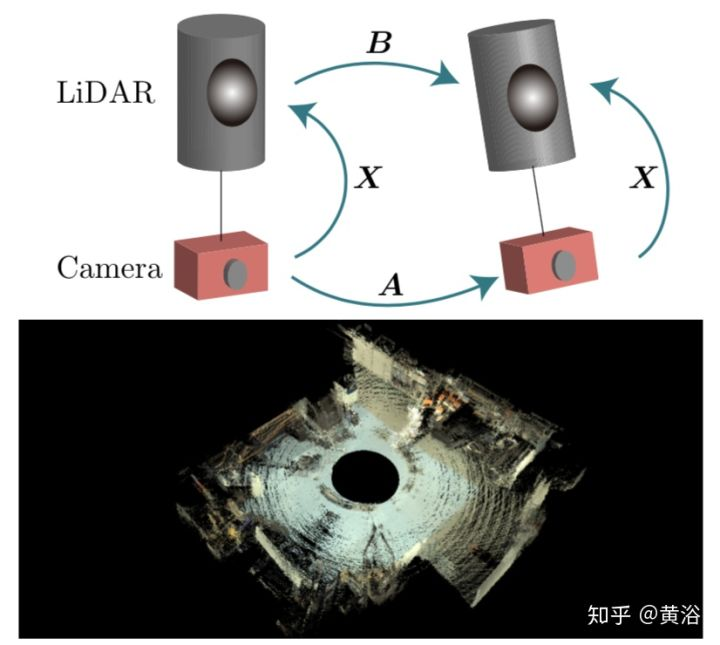
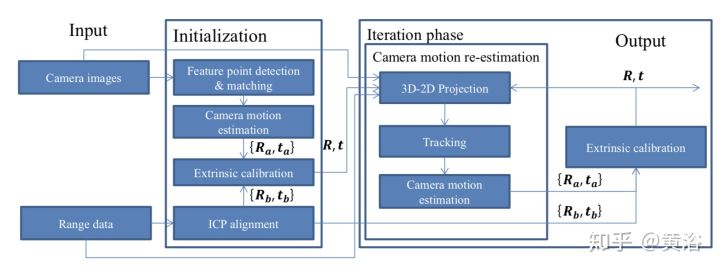
求解激光雷达的姿态变化采用ICP,而摄像头的运动采用特征匹配。后者有一个单目SFM的scale问题,论文提出了一个基于传感器融合的解法:初始估计来自于无尺度的摄像头运动和有尺度的激光雷达运动;之后有scale的摄像头运动会在加上激光雷达点云数据被重新估计。最后二者的外参数就能通过手-眼标定得到。下图是算法流程图:
手眼标定的典型解法是两步法:先求解旋转矩阵,然后再估计平移向量,公式在下面给出:
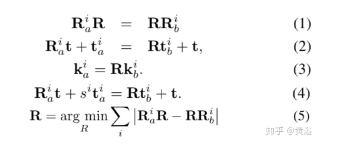
现在因为scale问题,上述解法不稳定,所以要利用激光雷达的数据做文章,见下图:
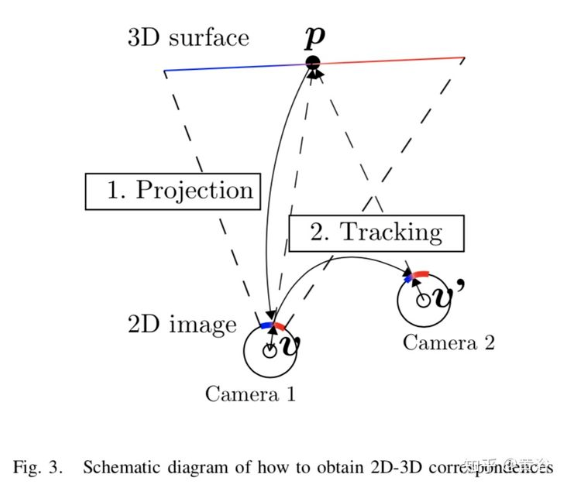
3-D点云的点在图像中被跟踪,其2D-3D对应关系可以描述为如下公式:
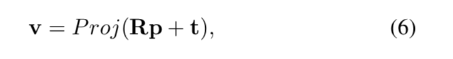
而求解的问题变成了:
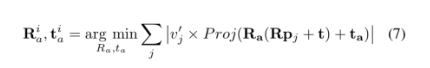
上面优化问题的初始解是通过经典的P3P得到的。
得到摄像头的运动参数之后可以在两步手眼标定法中得到旋转和平移6参数,其中平移估计如下:

注:这里估计摄像头运动和估计手眼标定是交替进行的,以改进估计精度。除此之外,作者也发现一些摄像头运动影响标定精度的策略,看下图分析:
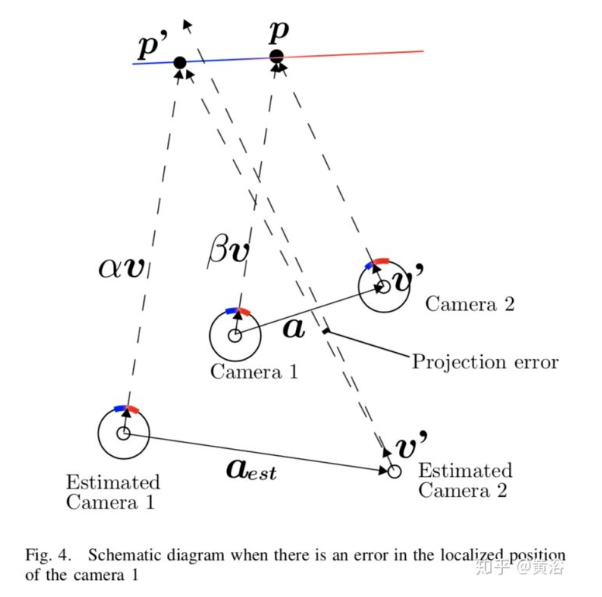
可以总结出:1)摄像头实际运动a 越小,投影误差越小;2) ( )越小,投影误差越小。第一点说明标定时候摄像头运动要小,第二点说明,标定的周围环境深度要变化小,比如墙壁。
另外还发现,增加摄像头运动的旋转角,摄像头运动估计到手眼标定的误差传播会小。
这个方法无法在室外自然环境中使用,因为点云投影的图像点很难确定。
有三篇关于如何优化激光雷达-摄像头标定的论文,不是通过3-D点云和图像点的匹配误差来估计标定参数,而是直接计算点云在图像平面形成的深度图,其和摄像头获取的图像存在全局匹配的测度。
不过这些方法,需要大量迭代,最好的做法是根据手眼标定产生初始值为好。
另外,密西根大学是采用了激光雷达反射值,悉尼大学在此基础上改进,两个都不如斯坦福大学方法方便,直接用点云和图像匹配实现标定。
斯坦福论文“Automatic online Calibration of Cameras and Lasers”。
斯坦福的方法是在线修正标定的“漂移”,如下图所示:精确的标定应该使图中绿色点(深度不连续)和红色边缘(通过逆距离变换 IDT,即inverse distance transform)匹配。

标定的目标函数是这样定义的:

其中w 是视频窗大小,f 是帧#,(i, j) 是图像中的像素位置,而p是点云的3-D点。X表示激光雷达点云数据,D是图像做过IDT的结果。
下图是实时在线标定的结果例子:

第一行标定好的,第二行出现漂移,第三行重新标定。
密西根大学的论文“Automatic Targetless Extrinsic Calibration of a 3D Lidar and Camera by Maximizing Mutual Information”。
这里定义了标定的任务就是求解两个传感器之间的转换关系,如图:求解R,T。

定义的Mutual Information (MI) 目标函数是一个熵值:

求解的算法是梯度法:

下图是一个标定的例子:RGB像素和点云校准。
澳大利亚悉尼大学的论文“Automatic Calibration of Lidar and Camera Images using Normalized Mutual Information”。
本文是对上面方法的改进。传感器配置如图:
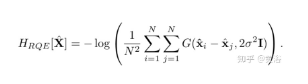
标定的流程在下图给出:
其中定义了一个新测度Gradient Orientation Measure (GOM)如下:
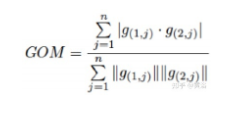
实际上是图像和激光雷达点云的梯度相关测度。
点云数据和图像数据匹配时候需要将点云投影到柱面图像上,如图所示:
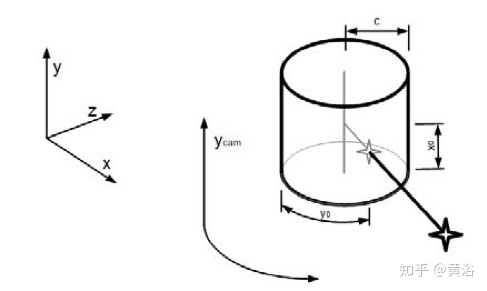
投影公式如下:
而点云的梯度计算之前需要将点云投影到球面上,公式如下:

最后,点云的梯度计算方法如下:
标定的任务就是求解GOM最大,而文中采用了蒙特卡洛方法,类似particle filter。下图是一个结果做例子:

IMU-摄像头标定
德国Fraunhofer论文“INS-Camera Calibration without Ground Control Points“。
本文虽然是给无人机的标定,对车辆也适合。
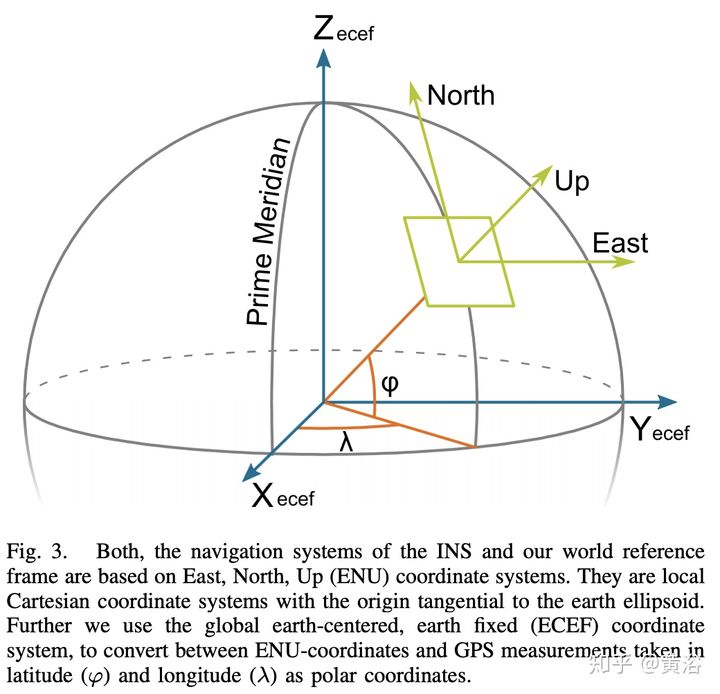
这是IMU定义的East, North, Up (ENU) 坐标系:
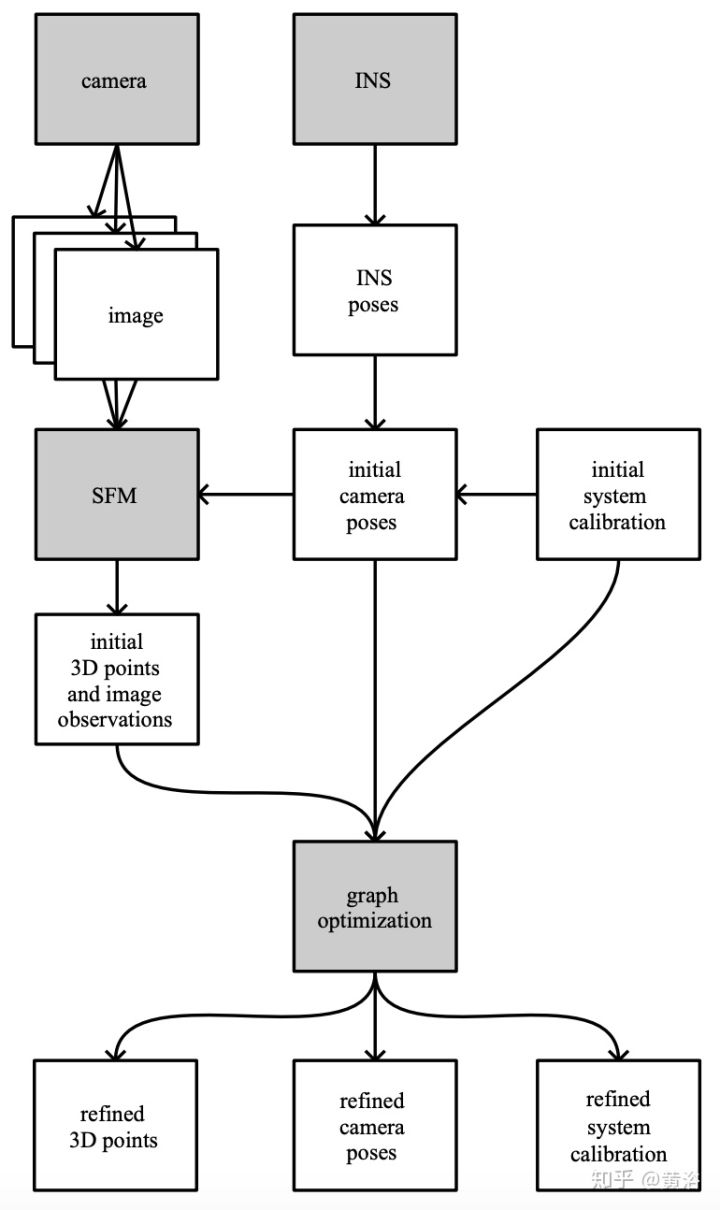
而实际上IMU-摄像头标定和激光雷达-摄像头标定都是类似的,先解决一个手眼标定,然后优化结果。只是IMU没有反馈信息可用,只有姿态数据,所以就做pose graph optimization。下图是流程图:其中摄像头还是用SFM估计姿态。
这是使用的图像标定板:

激光雷达系统标定
牛津大学论文“Automatic self-calibration of a full field-of-view 3D n-laser scanner".
本文定义点云的“crispness” 作为质量测度,通过一个熵函数Rényi Quadratic Entropy (RQE)最小化作为在线标定激光雷达的优化目标。(注:其中作者还讨论了激光雷达的时钟偏差问题解决方案)
“crisp“其实是描述点云分布作为一个GMM(Gaussian Mixture Model)形式下的致密度。根据信息熵的定义,RQE被选择为测度:
下图是一个标定后采集的点云结果:

标定算法如下:

雷达-摄像头标定
西安交大论文“Integrating Millimeter Wave Radar with a Monocular Vision Sensor for On-Road Obstacle Detection Applications”。
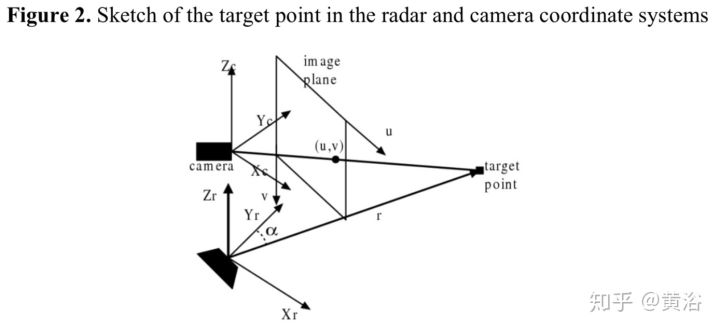
在讲传感器融合的时候提过这部分工作,这里重点介绍标定部分。首先坐标系关系如下:
传感器配置如下:
标定环境如下:
标定其实是计算图像平面和雷达反射面之间的homography矩阵参数,如下图:
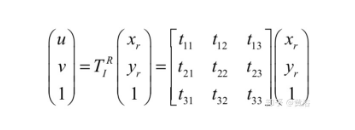



编辑推荐




最新资讯
-
推荐性国家标准《乘/商用车电子机械制动卡
2025-04-30 11:13
-
载荷分解
2025-04-30 10:46
-
布雷博在上海开设亚洲首个灵感实验室
2025-04-30 10:25
-
组分性能对锂离子电池卷芯挤压力学响应的影
2025-04-30 09:00
-
美国发布自动驾驶新框架,放宽报告要求+扩
2025-04-30 08:59
