




 广告
广告





















































智能汽车车用基础软件平台关联技术
2022-09-25 17:59:10· 来源:汽车测试网

2. 车云一体计算架构的设计
车云一体的基本概念,是车端与云端之间基于 SOA 的设计思想以服务化的方式通信的软件架构。车内各 ECU 的服务抽象 ( 如车门开关 ) 与云端服务能力 ( 如生态服务 ) 通过统一的服务化协议完成车与云之间服务的自由调度,充分发挥整车各传感器 / 执行器与云平台服务能力组合带来的场景化优势,从而支撑 OEM 构建海量个性化的智能应用场景,车云一体计算架构如下图 4.3-2 所示:
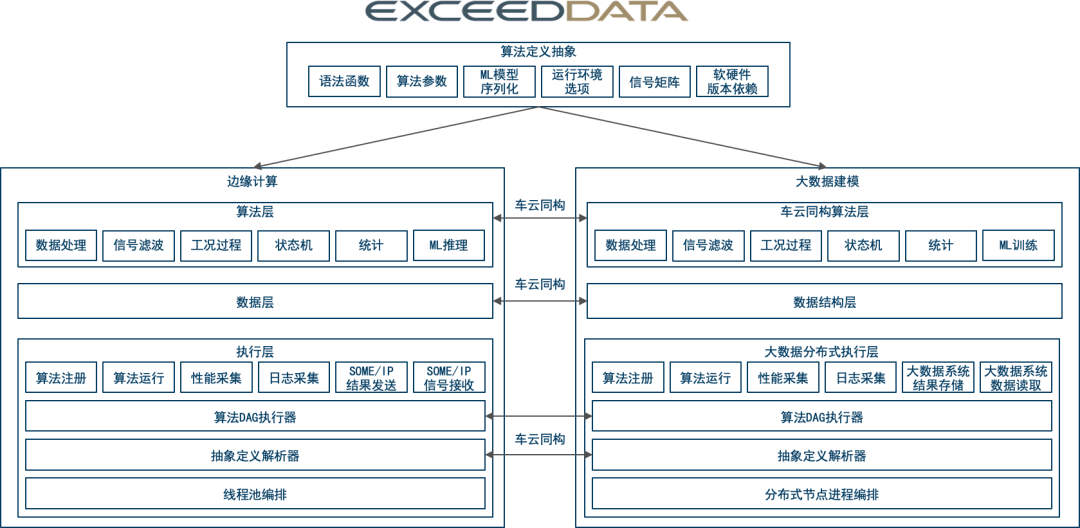
图4.3-2 车云一体计算架构
全栈边缘计算 + 大数据架构:
-
车云一体的数据结构 + 序列化 + 语法编译器 + 流算子 + 算法解析器 + 执行计划优化器,支持同数据同计算结果
-
执行器屏蔽跨平台资源调度与信号接入之间的差异
高层语法支撑动态车内加载部署:
-
算法 = 多算子组合的文本描述,车云算子一致
-
流算子、动态 plugin 加载、在整车测试集成过程测试验证
-
算法更新下发文本描述即可,监测算法文件更新后可自动生成可执行对象线程
面向生态的算法开发灵活性:
-
开发者工具拖拉拽,云上测试即可,无需整车长时间周期成本
-
完善可组合的数据处理,信号,特征,机器学习等算子模型
-
与 FOTA 集成,灵活更新,按需计算,互联网级别的迭代速度
车云一体的计算架构对于 OEM 的价值:
(1) OEM 个性化智能场景的支撑
基于车云一体架构带来的服务化基础能力,实现车云 SOA 服务的高效稳定、协调工作,充分开发车辆硬件能力实现最大化功能和出行场景智能化,构建更贴近使用场景的智能化以及跨域创新组合的场景化应用。
(2) 云端与整车级系统联动能力的提升
一套车云同构的计算框架,意味着工程师无需在 C/C++、Java,Scala、Python 等云端不同语言间来回切换移植,即可实现算法功能云端与车端的无缝衔接;因此,云端对于整车级数据采集、远程诊断 / 标定、整车 OTA 等都可以通过服务化协议实现动态策略的能力提升。
(3) 支持新场景的快速迭代
基于车 / 云服务化的封装可以通过工具化、图形化、流程化的方式支撑新的功能场景的快速开发,面向不同技术背景人员也能够通过场景的企划设计,快速地完成制作。
(4) OEM 生态构建与服务运营支撑
相比于传统的车联网服务运营模式,车云一体带来的智能化的体验,将整车能力和互联网生态紧密的连接;另外,对于第三方开发者的能力开放,相比车机联网模式带来更多的能力提升,支撑更多智能化应用场景的价值创造,帮助 OEM 构建自己的软件服务生态,使软件收益成为 OEM 全新的商业模式。
3. 车端结构化数据管理
由于车端结构化数据大多是高频率、连续的的信号数据,且单车的信号量较大,对于数据系统的写入、存储、计算能力都有较大挑战。在车端数据管理系统的设计思路上,应当以一个时序的、嵌入式的数据库的方式来应对,且应当具备以下关键特性:
· 信号以列存储:信号数据因为物理设计有天然的变化规律,在高质量采集下这些信号数值的详细变化过程可以被精准的识别,而且有数千个的时候以单信号列来存储的格式将比传统以报文条的行存储格式有更高的压缩率。
· 以流压缩算法平摊 CPU 消耗:车端对于服务使用 CPU 的稳定性非常关注。一是边缘资源有限, 二是全局压缩算法容易造成压缩时 CPU 峰值飙高,这时候如果其他服务也出现 CPU 使用飙高造成超过警戒线,对于整个 E/E 架构的服务优先级管理来讲很难处理。设计上应当考虑对 CPU 消耗的平缓占用,避免剧烈波动。
· 带公式自描述:传统数采格式 BLF/ASC 需要配套对应车型和版本的 DBC 才能解析,但在现实量产环境中,不同车辆的信号矩阵版本都可能不一样,实际车端可能和云端记录也不一样,诸如此类的问题会让车辆数据解析非常复杂。传统车联网以 JSON 格式上传数值,JSON 灵活但文本格式导致上传包 / 流量非常大。设计上应当借鉴 MDF 格式带公式自描述的理念,支持如线性、多项式等超过 8 种公式嵌在列存储元数据里,具有支持多种计算转换。使得数据包到云端时无需寻找DBC 版本比对、所有数据包自解析等功能。
· 支持高精度采集:系统应当能够支持 10ms 精度以上,上万个信号的数据的写入,同时能将车端的不同协议按照统一的规则排序以列进行存储。
· 支持边缘计算:系统应当可以通过在边缘计算实现对数据的查询和处理,并筛选需要的数据进行上传,使传输的数据都是有价值的数据。一方面控制了数据量优化了成本,另一方面还大幅减少云端数据处理的工作量。
4. 车端非结构化数据管理
自动驾驶的数据源来自于车身各种传感器的数据,包括车载摄像头、激光雷达、毫米波雷达、超声波雷达等感知数据;同时,在这个场景中还分为自动驾驶路试车数据和量产车数据两种区别较大的数据管理方式。
(1)路试车数据管理系统
路试车往往采用大容量高算力数采盒子全量数据采集的方案。数据落入磁盘后,通过停车后插拔硬盘, 并人工拷贝到对应服务器中。采集量大,数据完整。但同时带来大量的数据整理筛选工作。且数据依赖 测试车和测试员,数据积累成本高,对于 Corner Case 的输入效率低。
(2) 量产车非结构化数据管理系统
面向量产车的非结构化数据采集,无法通过插拔硬盘或者有线传输。用 4G/5G 无线回传需要考虑到流量、算力等成本因素。因此需要在车端进行数据筛选,尽可能只采集有限的,但高价值的数据。需要一定的边缘计算能力和业务 Know how 储备。



 广告
广告  广告
广告
编辑推荐




最新资讯
-
挑战全球高温气候极端场地|中国汽研智能网
2025-02-24 20:26
-
EV/EVSE强检标准上路,Chroma为您全力把关!
2025-02-24 20:18
-
智能网联公司与澳大利亚ANCAP开展技术交流
2025-02-24 16:14
-
《汽车轮胎干路面制动距离试验方法》等团体
2025-02-24 16:13
-
突然解散!又一智驾公司总部封楼!
2025-02-24 12:09
 广告
广告 广告
广告
