




 广告
广告





















































毫米波雷达在多模态视觉任务上的近期工作及简析

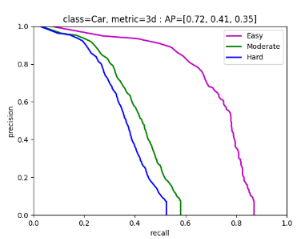
以上结果是IoU=0.3的情况下,三类样本的PR曲线。
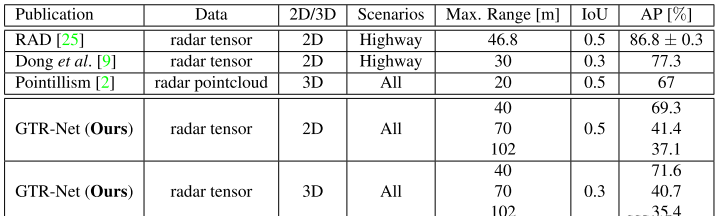
以上作者只与baseline进行了对比,其他的工作只是列举了他们的实验细节,也可以从这一节看出,在非毫米波点云数据的工作中(当然点云数据集也仍然没有高度公认的),还没有大部分工作都认同的数据集,我猜测:一是不同毫米波传感器之间的属性差别大难以统一、二是毫米波的论文开源工作较少,目前我找到的大部分工作都是只有论文,细节描述不清,因此难以复现出原本的性能。三是开源的大型数据集较少。希望未来大家能够将自己的工作开源,至少说明足够复现的细节。
总结
GCN和Voxel两类网络对比:在复杂度方面,graph-based的计算复杂度与点云数量呈线性相关性,而grid-based方法检测性能不仅受到grid大小,大量的voxel等于0值造成计算资源浪费,并且也受到检测距离的关系而需要在检测精度和效率之间做trade-off。在中心特征计算方面,radar pointcloud的点云过于稀疏,许多前景目标仅投影个位数的点云,通过voxel等方法会造成过度降采样和中心特征丢失。当前各类榜单上grid-based方法能够有效避免point数量过大导致的复杂度过高的问题而成为主流超越point-wise的方法,但是由于radar的稀疏性(Nuscenes中radar和lidar大概是50:1的关系),采用point-wise的方法并不会导致很大的延迟。Radar检测优劣:优势:另一方面,radar由于其长波优势,探测的距离也较大,对于高速公路这类检测目标单一且方向等属性较为单一的场景下,radar有着较大的优势。劣势:由于两个工作并不是同一数据集,所以两者无法横向对比,能够得到的几点是:毫米波所包含的信息是能够独立地进行3D检测,但是仅对于车辆(卡车、汽车、建造车辆等)大型反射性良好的目标进行检测,而对于弱反射的交通目标则检测效果较差。两种数据对比:基于radar点云的检测都是需要预定义每个需要检测的类的bouding box大小,毫米波在辨别物体时有一定的优势,但是在物体的regression任务上缺乏可参考的尺寸特征(仅有RCS),在回归任务上需要预设大小。相比之下,在RD原始数据中显示地带有了目标的横截面积反射强度等信息(Doppler),工作2**(暂定没有预设尺寸)**可以在没有预设尺寸情况下较好回归目标属性。但是,在高度属性等地面垂直方向属性预测上,雷达这种平面数据无法有效预测。
1.2 Reference to Lidar
这类工作主要对Lidar based方法进行改进,用于Radar。
1.2.1 Point-wise 的检测方法
2D Car Detection in Radar Data with PointNets (2019 IEEE Intelligent Transportation Systems Cnference)出发点: 在point-level借鉴frustum-pointnet和pointnet进行3D目标检测。

作者基于Frustum-Pointnet和Pointnet进行了改进,提出一种point-wise的3D目标检测网络。整个模块分为三个部分:
-
第一部分基于现有的radar points生成2D的Patch Proposals,相当于Frustum-Pointnet中的Frustum,用于聚合局部特征,现定某个patch内部的point点数为n,相当于对每个patch内部的点做一系列的操作,Patch Proposal的输入为n x 4(2D spatial data, ego motion compensated Doppler velocity and RCS information.)。
-
第二部分将proposal内部的点云提取局部和全局特征,经过对clutter和radar-target的点云过滤,输出mx4的筛选后的radar targets向量(与原始数据一致)。
-
最后一部分,将筛选出来的点经过传统的T-NET和Box-Estimation输出最后的各项属性。下面是更详细的结构图:

1.3 多模态融合
1.3.1 point-wise fusion和object-wise fusion(feature-level & decision level)集合用于多模态检测
Bridging the View Disparity of Radar and Camera Features for Multi-modal Fusion 3D Object Detection (2021 8月 arxiv 清华)出发点: 在BEV空间,在point level和object level两个层面实现图像特征和点云特征的融合。

-
提出RCBEV,该模型主要解决在3D检测中,毫米波和相机数据的异构融合检测问题,提出了一种Point-fusion和ROI fusion两种融合并存互补的想法。
-
模型架构:
图像分支:通过LSS的方法将图像特征转换到BEV空间,并通过ConvLSTM融合多帧的毫米波grid-based特征作为时序radar特征,与图像BEV特征进行point-wise的concate后,通过BEV特征编码器完成模态融合并基于此进行heatmap生成。radar分支:通过对radar特征图的heatmap生成并与图像的heatmap进行融合,送入最终检测头预测。融合分支:采用point-wise fusion和object-wise fusion两种融合兼顾的方式。
-
模型细节:
(1) point-fusion和ROI fusion两种融合并存互补的想法;(2) two-stage-fusion方法:两个模态分支各自完成heatmap生成后,再次进行融合,在特征细粒度和全局信息融合上都有考虑到,融合结构如下所示:在融合之前,不用保持分辨率的一致,在point-wise融合时两个不同分辨率的模态要分别经过上下采样统一后融合。(3) 在radar上使用conv-lstm这类方法进行时序雷达信息融合,作者以此解决点云的部分噪声问题:杂波和数据稀疏,但是没有通过消融实验证明lstm结构的合理性。
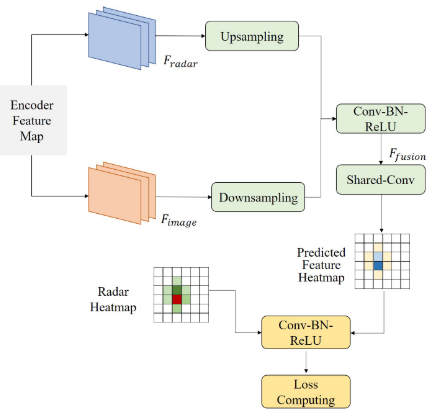
(4) 雷达数据处理:temporal-spatial feature encoder
-
每一帧的雷达点云都经过转换到current frame,输入的raw radar包含:x, y, vr, RCS;空间特征提取:使用常用的voxelnet或者pointpillars;
-
时序特征:ConvLSTM,对空间特征特征图提取时序特征到Temporal Encoder中,具体结构可参考如下结构,将卷积和lstm结合起来,使得模型同时具有提取空间和时序特征的能力,这个在天气预测有一些应用;
(5) 图像特征提取:LSS
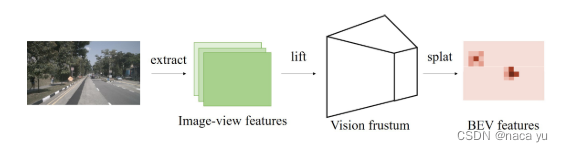
和BEVDet的方法一致,提取feature-map后,经过一系列的转换(lift)将特征转换为基于视锥分布的深度特征图,后通过pooling的方式(splat)特征到BEV空间。
-
评价总结
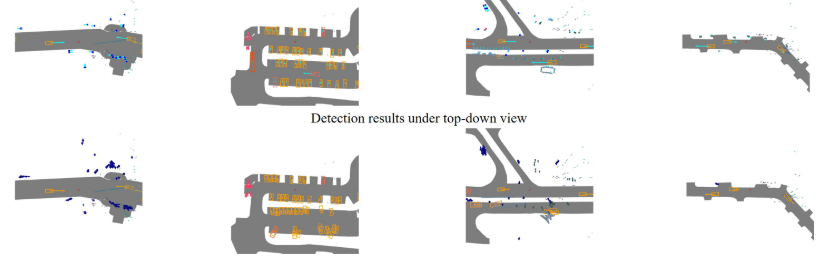
作者在BEV空间中以top-down的形式检测,没有引入先验的目标尺寸信息,而是通过中心点回归其他信息。
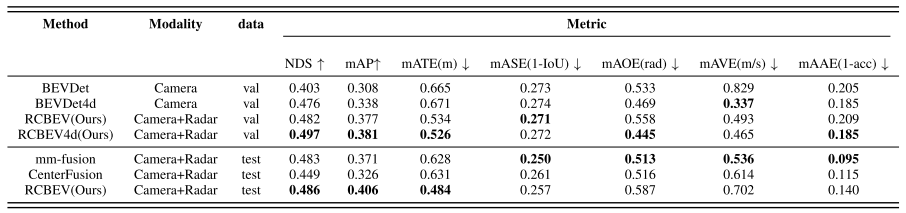
-
baseline:相比未引入时序信息的BEVDet,在整体性能提高的基础上,在mAVE上尤其明显,毫米波雷达的引入,时序特征的提取对网络的速度性能提升非常大,相比BEVFORMER和BEVDET4D预测速度,通过融合毫米波雷达能够在避免多帧图像的计算复杂度增加的同时,提高速度的预测能力。但是通过conv-lstm的方法完成雷达时序特征的提取相对其他方法并没有体现出其优势,这个可以对比目前的camera+radar主流方法的mAVE来看。
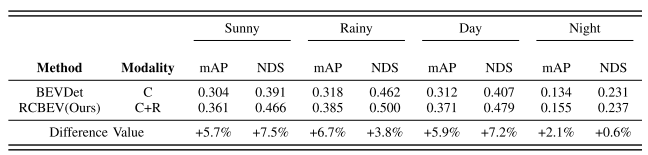
-
模态消融实验:相比晴天,雨天毫米波雷达带来的提升更大,也能证明这种融合方式的鲁棒性。在光照对比上,白天带来的提升更加明显,总体上,本篇工作确实在多个极端天气下达到了良好的性能。
- 下一篇:锂电池散热冷却方式综述
- 上一篇:某纯电动汽车空调采暖性能试验研究



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
