




 广告
广告





















































毫米波雷达在多模态视觉任务上的近期工作及简析

RadSegNet: A Reliable Approach to Radar Camera Fusion (2022 年 8月)出发点: 用语义分割结果渲染点云图,对毫米波点云引入图像语义信息用于3D检测。
-
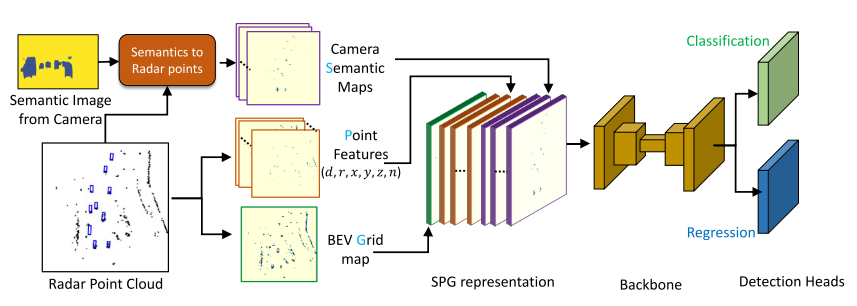
模型架构:这里融合的方式并不复杂,类比与pointpainting的方式,将雷达点云赋予语义信息(图像经过pretrained maskrcnn的分割后的全景分割图像),生成semantic map用于渲染投影到FOV后对应的毫米波点云,然后分别与对应的点云的特征和BEV occupy map进行叠加,到此完成特征的对齐和不同特征向量的叠加。后利用UNet网络提取多尺度特征,分别送入分类和回归检测头。这篇文论的精彩之处我认为在于SPG representation的前面:
-
模型细节:
(1) 点云渲染

通过对比,可以看出在语义通道中,毫米波通过语义分割渲染后的点云带有图像本身的语义信息,能够直观反映了其能够弥补毫米波缺少类别特征的劣势。(2) 检测头
-
最后两个检测头分别预测NC128128也就是N个anchor的类别,而另一个输出为7N128128,7为每个anchor的属性,包括x, y, z, w, h, l, theta这7个属性。
(3) 天气模拟作者使用图像增强库模拟增加极端天气:大雾、大雪等天气,可以控制雪花大小、下降速度等参数模拟真实环境。(4)模型输入:
-
分为BEV occupy grid, RadarPoint Feature, Semantic Maps,共计22 dims,在输入模型前全部通过concate完成grid-level的特征对齐。
-
作者将点云格式化为grid-based feature map,如果多个点投影到同一grid,那么就计算平均值,同时y设置为7个channel代表不同的高度,弥补毫米波雷达不含有高度信息的缺点,n表示点云投影到grid的个数。数据由I(u,v)为0\1布尔值代表是否为空,d,r代表Doppler和Intensity。
-
分析总结
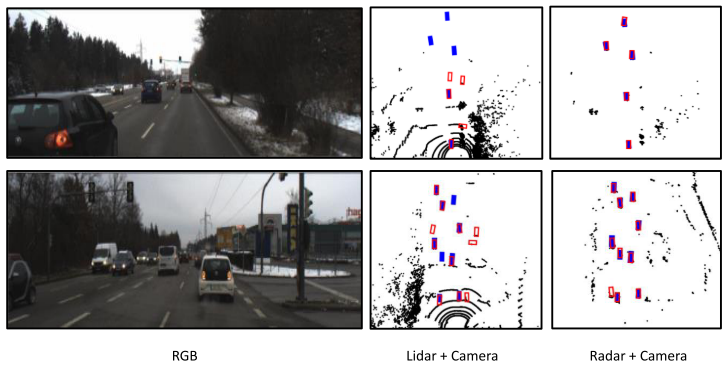
作者在Astyx dataset数据集完成训练任务,在RADIATE进行测试。RADIATE相比训练的数据集,极端环境的占比更多,对模型的鲁棒性要求更高。(1)在Astyx数据集对比中:baseline选取Perspective-view-based方法当时的SOTA-Centerfusion进行比较,为了保持公平,将预训练的centernet微调到新数据集中,实验结果也证明微调后的网络比from-scratch的centernet网络表现更好,作者基于此对centernet进行了微调并用于centerfusion。centerfusion性能下降很多,但是作者没有给出足够的细节,我能推测出来的:RadSegNet在BEV下3D检测的结果与Centerfusion的FOV检测结果相比较。(2)作者使用segmentation后的结果渲染point,所以融合的效果严重依赖于分割的效果,在极端天气下的分割效果如下图所示,点云的语义特征会严重退化;

(3) lidar vs radar
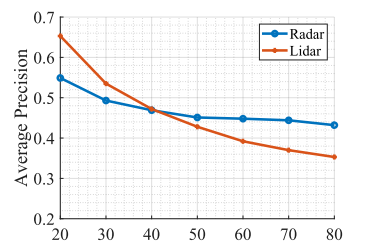
作者将pointcloud换成lidar进行了对比试验,可以看出,在近处激光雷达的效果要优于毫米波,在远处发生了目标的遮挡并且lidar点云的密度急剧下降,作者计算了不同的感知距离上限下性能的变化,可以看出radar在远距离检测的优越性。毫米波作为长波,相比激光雷达,在穿透性和感知距离上都要更优,但是同时也导致了毫米波雷达的多路径干扰等问题。(4) 相比nuscenes,作者使用的这两个采集自真实场景的数据集由于其极端环境的占比较高,因此对于算法的鲁棒性要求更高,在nuscenes数据集上,点云过于稀疏同时极端的环境占比并不高,在许多
二、Depth Estimation
2.1 毫米波雷达辅助视觉进行深度估计
-
题目:Depth Estimation From Monocular Images and Sparse Radar Using Deep Ordinal Regression Network (ICIP,2021,九月)
作者出发点: 随着lidar-based的深度估计方法用于3D目标检测(BEVDepth),radar-based方法也通过改进,根据radar特性设计了一些深度估计的方法。作者结合DORN网络并进行改进,引入radar分支用于深度检测。在阅读之前,Depth Estimation from Monocular Images and Sparse Radar Data,
-
源代码:https://github.com/lochenchou/DORN radar

-
网络架构:由图可以看出,两个模态在FOV分别通过resnet提取feature后(要注意,此时的radar并不是raw data,而是通过滤波后的深度值,可参考模型细节(2)),分别通过DORN深度估计网络和普通的卷积进行编码,随后concate并上采样到输入图像大小,最后通过序数回归对深度进行估计,其中蓝色部分与DORN保持一致,只是将深度估计问题变成分类问题(ordinal regression)。整体结构并不复杂,重要的是作者如何将radar用于深度估计的流程。
-
主要创新点:一个是将点云扩展高度变成line,提高毫米波点云的"感受野",增强深度估计效果。一个是将多模态引入单模态深度估计DORN网络。
-
模型细节
(1) 作者将毫米波雷达的困难定义为:稀疏、噪声比大、无高度信息(影响的高度范围有限),通过预处理,生成一个height-extended multi-frame denoised radar。
(2) 雷达预处理流程如下:1. 高度扩展,类似于crfnet,将点云扩展0.25~2m的范围内,变成一条直线;2. 滤波:将不符合深度阈值的毫米波点云滤除,阈值定义如下,滤波过程和生成radar-depth特征的过程可参考Depth Estimation from Monocular Images and Sparse Radar Data
-
总结
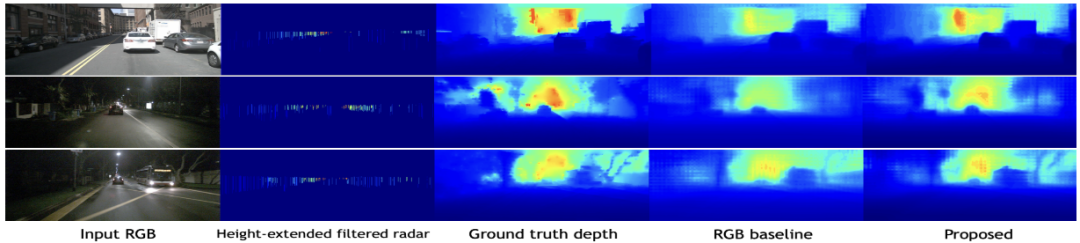

-
评价指标:
第一个评价值代表深度估计值和真实值的最大差异
RMSE是平均深度差值
ABSREL是相对的平均深度差值
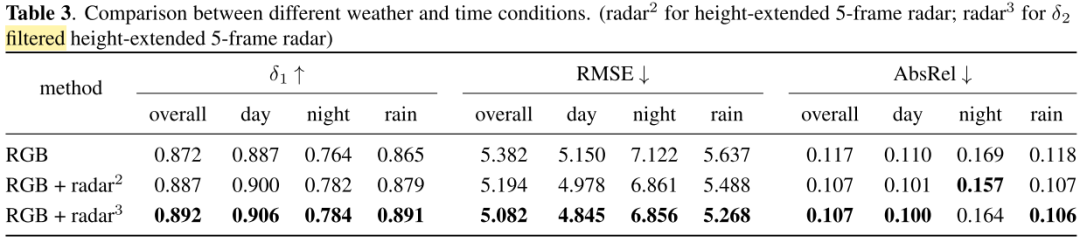
由两个图可知,在经过滤波、高度扩展后,各方面性能都有一定提升,包括平均深度误差等参数。
-
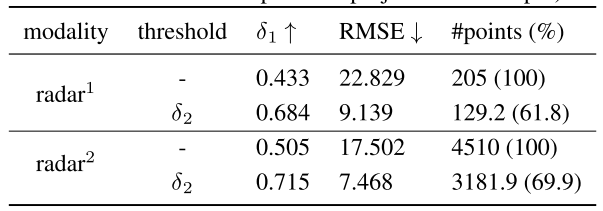
关于高度高扩展和滤波对结果的影响:threshhold为滤波阈值,"-"表示不进行滤波
- 下一篇:锂电池散热冷却方式综述
- 上一篇:某纯电动汽车空调采暖性能试验研究



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
