




 广告
广告





















































自动驾驶多模态融合感知现状及挑战

导读
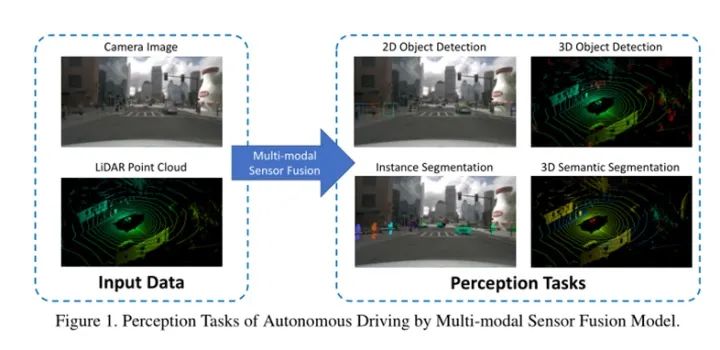
多模态融合是感知自动驾驶系统的重要任务。本文将详细阐述基于多模态的自动驾驶感知方法。包括LiDAR 和相机在内的解决对象检测和语义分割任务。
从融合阶段的角度,从数据级、特征级、对象级、不对称融合对现有的方案进行分类。此外,本文提出了本领域的挑战性问题并就潜在的研究机会进行开放式讨论。
01多模态融合感知的背景
单模态数据的感知存在固有的缺陷,相机数据主要在前视图的较低位置捕获。在更复杂的场景中,物体可能会被遮挡,给物体检测和语义分割带来严峻挑战。
此外,受限于机械结构,激光雷达在不同距离处具有不同的分辨率,并且容易受到大雾和大雨等极端天气的影响。因此LiDAR和相机的互补性使得组合感知方面具有更好的性能。感知任务包括目标检测、语义分割、深度补全和预测等。我们主要关注前两个任务。
02
数据格式
相机提供了丰富的纹理信息的RGB图像。具体来说,对于每个图像像素为 (u, v),它有一个多通道特征向量 F(u,v) = {R, G, B, ...},通常包含相机捕获的红色、蓝色、绿色通道或其他手动设计的特征作为灰度通道。
然而,由于深度信息有限,单目相机难以提取,因此在 3D 空间中直接检测物体相对具有挑战性。因此,许多方案使用双目或立体相机系统通过空间和时间空间来利用附加信息进行3D对象检测,例如深度估计、光流等。
激光雷达使用激光系统扫描环境并生成点云。一般来说,大多数激光雷达的原始数据都是四元数,如(x, y, z, r),其中r代表每个点的反射率。
不同的纹理导致不同的反射率,然而,点的四元数表示存在冗余或速度缺陷。因此,许多研究人员尝试将点云转换为体素或2D投影,然后再将其馈送到下游模块。
一些工作通过将3D空间离散化为3D体素,表示为:
其中每个 xi 代表一个特征向量,如:
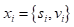
si代表体素长方体的质心,而vi代表一些基于统计的局部信息。局部密度是由局部体素中3D点的数量定义的。局部偏移量通常定义为点坐标与局部体素质心之间的偏移量。
基于Voxel 的点云表示,与上面提到的基于点的点云表示不同,它极大地减少了非结构化点云的冗余。此外,利用3D稀疏卷积技术,感知任务不仅实现了更快的训练速度,而且还实现了更高的准确度。
一些工作试图将LiDAR数据作为两种常见类型投影到图像空间中,包括相机平面图(CPM)和鸟瞰图(BEV)。通过将每个3D点作为 (x, y, z) 投影到相机坐标系中(u, v),可以获得CPM。由于CPM与相机图像的格式相同,因此可以通过使CPM作为附加通道来自然地融合它们。
然而,由于投影后激光雷达的分辨率较低,CPM中许多像素的特征被破坏了。BEV 映射提供了从上方看场景的高视图。检测和定位任务使用它有两个原因。首先,与安装在挡风玻璃后面的摄像头不同,大多数激光雷达位于车辆顶部,遮挡较少。
其次,所有对象都放置在BEV中的地平面上,模型可以生成预测而不会出现长度和宽度的失真。
03
融合方法
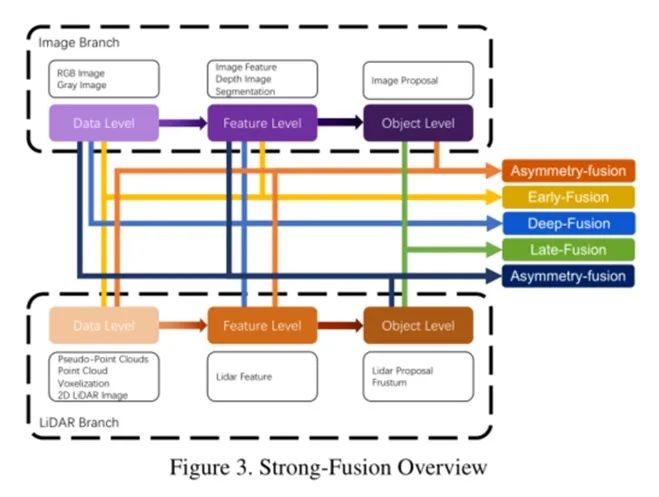
本节将回顾激光雷达相机数据的不同融合方法。从传统分类学的角度来看,所有的多模态数据融合方法都可以很方便地分为三种范式,包括数据级融合(early-fusion)、特征级融合(deep-fusion)和对象级融合(late-fusion)。
数据级融合或早期融合方法通过空间对齐直接融合不同模态的原始传感器数据。特征级融合或深度融合方法关注于特征空间中混合跨模态数据。对象级融合方法结合模型在每个模态中的预测结果并做出最终决策。
04
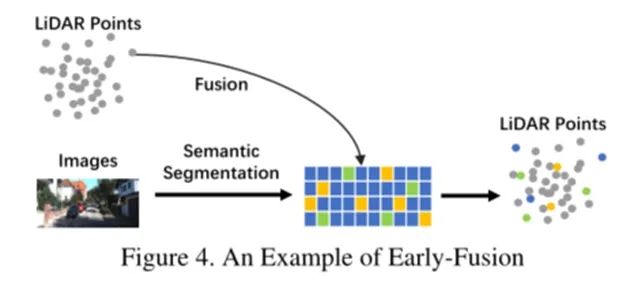
数据级融合
原始数据通过空间对齐和投影直接融合每种模态数据的方法的一个例子是图4中的模型。将图像分支中的语义特征和原始激光雷达点云融合在一起,从而在目标检测任务中获得更好的性能。
3D激光雷达点云转换为 2D 图像,并利用成熟的 CNN 技术融合图像分支中的特征级表示以实现更好的性能。
05
特征级融合
特征级别融合使用特征提取器分别获取激光雷达点云和相机图像的嵌入表示,并通过一系列下游模块融合两种模态的特征。深度融合有时会以级联方式融合特征这两者都利用了原始和高级语义信息。深度融合的一个例子可以是图5中的模型。
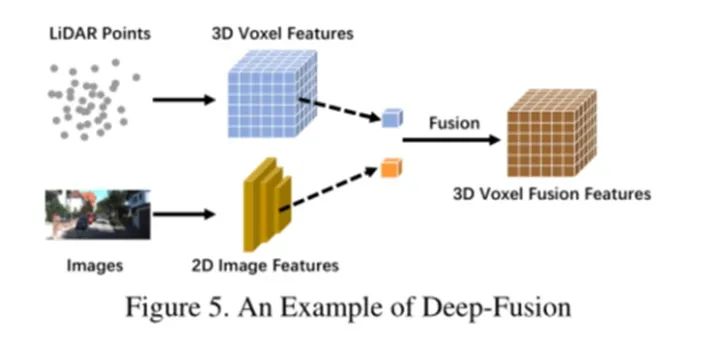
06
对象级融合
后期融合,也称为对象级融合,表示在每种模态中融合不同结果的方法。例如,一些后期融合方法利用来自LiDAR点云分支和相机图像分支的输出,并根据两种模态的结果进行最终预测。
请注意,两个分支应具有与最终结果相同的数据格式,但质量、数量和精度各不相同。后期融合可以看作是一种利用多模态信息优化最终proposal的集成方法。一个例子可以是图6中的模型。
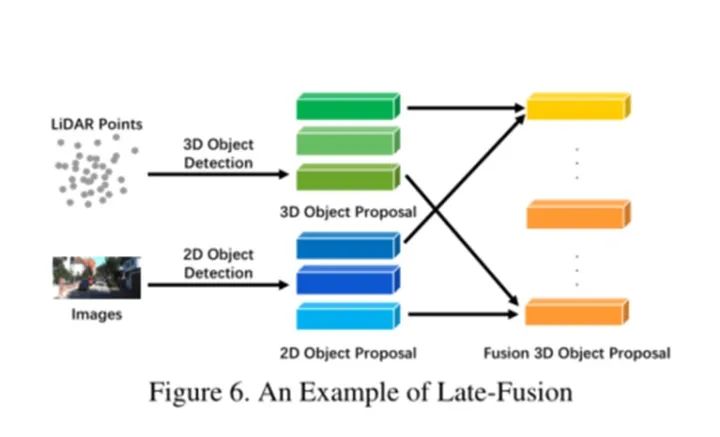
如上所述,利用后期融合来细化每个3D区域proposal的分数,将图像分支中的2Dproposal与LiDAR分支中的3D proposal相结合。此外,对于每个重叠区域,它利用了置信度得分、距离和IoU等统计特征。
07
不对称融合
除了早期融合、深度融合和后期融合之外,一些方法对跨模态分支具有不同的特权。其他方法将两个分支视为看似平等的状态,而不对称融合至少有一个分支占主导地位,而其他分支则提供辅助信息来执行最终任务。
后期融合的一个例子可以是图7中的模型。特别是与后期融合相比,尽管它们可能使用提案具有相同的提取特征,但不对称融合只有一个来自一个分支的提取特征。
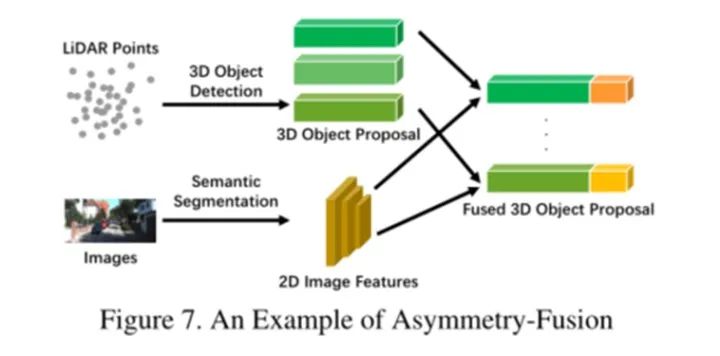
这种融合方法是合理的,因为在相机数据上使用卷积神经网络具有出色的性能,该网络过滤了点云中语义上无用的点,提取原始点云中的截锥体以及相应像素的RGB信息,以输出3D边界框的参数。
使用 LiDAR 主干以多视图样式引导2D主干,并实现更高的精度。利用来自LiDAR分支的3D区域提案并重新投影到2D,结合图像特征,输出最终的3D提案。
08挑战与机遇
近年来,用于自动驾驶感知任务的多模态融合方法取得了快速进展,从更高级的特征表示到更复杂的深度学习模型。然而,还有一些悬而未决的问题。总结为以下几个方面:
错位和信息丢失
相机和 LiDAR 的内在和外在差异很大。两种模式中的数据都需要在新的坐标系下重新组织。传统的早期和深度融合方法利用外部校准矩阵将所有LiDAR点直接投影到相应的像素。
然而,这种逐像素对齐不够准确。因此,我们可以看到,除了这种严格的对应关系之外,有时利用周围信息作为补充会产生更好的性能。此外,在输入和特征空间的转换过程中还存在一些其他的信息丢失。
通常,降维操作的投影不可避免地会导致大量信息丢失,例如将3D LiDAR点云映射到BEV 图像中。因此,通过将两种模态数据映射为另一种专为融合而设计的高维表示,未来的工作可以有效地利用原始数据,同时减少信息丢失。
更合理的融合操作
当前的研究工作使用直观的方法来融合跨模态数据,例如连接和元素乘法。这些简单的操作可能无法融合分布差异较大的数据,因此难以弥合两种模态之间的语义差距。
一些工作试图使用更精细的级联结构来融合数据并提高性能。在未来的研究中,双线性映射等机制可以融合具有不同特征的特征。
多源信息权衡
现有的方法缺乏对来自多个维度和来源的信息的有效利用。他们中的大多数都专注于前视图中的单帧多模态数据。结果,其他有意义的信息没有得到充分利用,例如语义、空间和场景上下文信息。
在自动驾驶场景中,许多具有显式语义信息的下游任务可能会极大地提高目标检测任务的性能。例如,车道检测可以直观地为检测车道之间的车辆提供额外帮助,语义分割结果可以提高目标检测性能。
未来的研究可以通过检测车道、红绿灯和标志等各种下游任务,共同构建完整的城市景观场景语义理解框架,以辅助感知任务的执行。
参考
[1] Huang, K., Shi, B., Li, X., Li, X., Huang, S., & Li, Y. (2022). Multi-modal Sensor Fusion for Auto Driving Perception: A Survey. arXiv preprint arXiv:2202.02703.



编辑推荐




最新资讯
-
高强度碰撞下电控门锁的可靠性思考
2025-04-08 14:26
-
一文解析汽车控制器软件开发过程中的测试
2025-04-08 14:25
-
纯电续航160公里,ReVolt增程电动重卡在美
2025-04-08 14:22
-
FLIR E8 Pro热像仪:汽车漏水检测的“火眼
2025-04-08 10:34
-
德法英日韩之后,瑞士也允许L3上路了
2025-04-08 07:56
