




 广告
广告





















































自动驾驶车辆的社会交互:回顾与展望

社会交互情景描述的是一种条件,个体驾驶员的行为由其自身特征和由其他驾驶员的行为组成的环境决定,反之亦然。从条件概率的角度来看,人类驾驶员间的交互影响可以解释为一个驾驶员在感知到周围其他车辆的状态后采取某个动作的可能性有多大。这个问题可以用条件概率分布或条件行为预测来表示,此概念是贝叶斯网络的基础。此外,Tolstaya等人用一种耳目一新的交互来量化智能体间的交互性,在这种交互中,智能体B由于观测到智能体A的轨迹发生行为变化,计算公式为
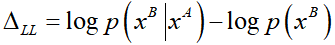
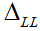
变化较大代表智能体B很大程度上受到智能体A动作的影响。如果在A的轨迹下,B的轨迹更可能发生,则
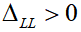
;如果不可能发生,则
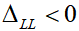
;如果不变,
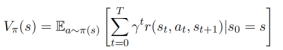
;这一思想使得在信息理论中常用的相似性度量方法(如KL-divergence)变得容易应用。
另一方面,可将交互视为潜在的概率生成过程或条件概率模型。如Anderson et al.提出一个概率图模型,以捕捉前车未来状态和动态系统历史状态间的交互。但是该方法无法考虑汇入车辆对前后车交互的影响。González提出一个感知交互的概率驾驶员模型,以捕捉驾驶员的交互偏好,人类驾驶员基于对周围驾驶员行为的预测,将在当前时间步内执行动作。在逆优化框架下,通过加权特征(如导航和风险特征)的组合来表征交互偏好。
(3) 势/风险场
基于人类驾驶行为源自于基于风险场的假设,提出了势/风险场。采用势函数建立交互模型已经广泛的应用于人机交互、多车间的交互。与物理距离有关的指标能有效地用某个可学习、可解释的函数表征交互。该函数被称为势函数,其中还可以加入交通规则和驾驶场景信息。另外,势函数对坐标系x/y的导数即为虚拟力,推、拉车辆以实现交互过程中局部规划成本最小化。还有研究者基于本车与周围车辆的相对距离(通常是两车轨迹的最小值或最近点)设计能量函数以捕捉车间交互。基于相对距离的量化方法无法保证始终正确捕捉人类驾驶员间的交互。当智能体间存在物理约束(高速隔离带)时,即使人类驾驶员距离很近,但其交互很少或甚至没有交互。
(4)认知模型
研究人员基于心理理论、信息累计度量理论,使用相对距离表征驾驶风格和解释交互过程。研究者还从行为科学和心理学的角度出发,开发出其他类型的交互模型以模仿人类驾驶行为。
3. 建模社会交互中的影响因素
人类可以通过利用交通场景中的显式传感器信息和对其他驾驶员行为的隐式社会推理来做出安全和社会可接受的动作,从而非常出色地驾驶。将社会偏好、社会模仿和社会推理等因素赋予信息吸收能力和行为预期能力是人类的天性,这是社会兼容驾驶行为的核心。对这些社会因素的定量评估需要计算认知科学和技术。
(1)驾驶偏好中的社会价值取向SVO
SVO模型衡量一个驾驶员如何权衡自己的奖励与其他驾驶员的奖励,在逆强化学习(IRL)的结构下,它可以从观察到的轨迹中学习,再将可在线学习驾驶风格的SVO模型整合到博弈场景中。
(2) 社会驾驶模仿中的社会凝聚力
人类驾驶车辆的行为具有社会凝聚力,即驾驶员会采取与周围驾驶员相似的动作。受人类驾驶员的社会凝聚力的启发,Landolfi和Dragan设计了一种凝聚力增强奖励函数,使自动驾驶汽车能够通过确定跟随其他车辆哪一方面、跟随谁以及何时跟随来保证安全,从而自动进行社会性跟随。
(3) 提高情景感知的社会感知
人类可以积极地收集和提取有关环境的附加信息,从而创造一个相对完全的交通场景,从而提供足够的信息,提高环境意识,从而进行安全高效的动作。例如,当驾驶员感知到相邻车辆的减速和停车行为时,无论他的视野是否被遮挡,他都能推断出潜在的行人正在过马路。人类将其他驾驶员视为传感器的这种社交能力已经被制定并集成到自动驾驶汽车中,以增强驾驶员的情景感知能力。Sun et al.和Afolabi et al.通过置信空间上的条件分布,形成对环境遮挡的认知理解。
(4)驾驶风格中的社会交互风格
人类驾驶员通过评估和平衡未来不同的奖励项来制定计划并采取行动。根据人类的内在模型、驾驶任务和动机,人类可能会对不同的奖励项给予不同的关注。这种方式就体现出他们与周围环境互动的不同风格,如激进、保守、礼貌、自私和非理性。因此,交互风格可以表述为在生成轨迹时不同特征的加权结果。例如,研究人员将这些由社会因素诱发的互动风格量化为奖励特征。然后使用逆强化学习(IRL)来学习这些特征的权重或从轨迹中学习目标函数排序。
五、建模和学习交互的方法
如图5所示,常用的量化模型有五种:基于理性效用函数的模型、基于深度神经网络的模型、基于图的模型、社会场/力、计算认知模型。本文主要介绍基于理性效用函数的模型。
日常中最常遇到的交互场景是在城市环境和高速公路上的跟车、汇入/出与换道。研究人员将人类驾驶员视为已知目标函数的最优控制器,以实现以预定义目标为导向的任务,从而决定在这些场景中的行为。然而,在自然交通场景中,驾驶员或其他人类智能体间的交互受物理(如运动学和几何)和社会(如意图、注意力和责任)的约束。Luo等人开发了一种通用的智能体交互模型(GAMMA),通过将交互运动视为带有速度障碍的约束几何优化问题,来预测人类智能体的行为。该交互模型在高保真模拟器(SUMMIT)中得以实现,用于模拟大规模混合城市交通。此外,Lee et al.认为人类智能体在短期未来的交互中应该获得最优的累积奖励。作者在一个优化架构下构建了运动预测问题,最大化一组预测假设的潜在未来奖励。通常,基于优化的方法需要一个待优化的特定目标(车间期望间距和时距)和目标函数。下面,将讨论一些基于优化某个成本函数或目标函数思想而建立的模型,本文选择了一些主流的方法,包括基于群的模型、博弈论模型、模仿学习和马尔可夫决策过程。
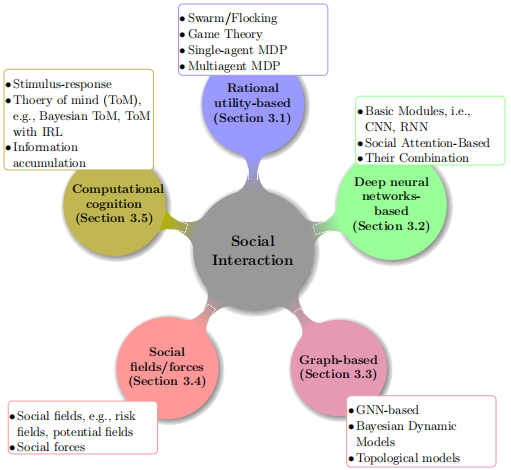
图5 建模和学习人类驾驶员间交互的方法汇总
1.基于生物种群的仿生模型
应用Reynolds规则的大多数实例是基于牛顿运动定律传播的动态模型,因此需要开发一套反映Reynolds规则的完整分力集合,各分力(即凝聚力、分离力和一致力)与用于模拟行人交互的各部分社会力理论完全匹配。Reynolds规则揭示了交互的基本机制,比基于社会力的理论更具普遍性。尽管受群启发的规则成功地揭示了动物(如鸟类、鱼类和羊群)之间的群体交互机制,但它们只能在自由空间或有静态障碍物的空间(如天空中的鸟类和海洋中的鱼类)中很好地工作。在交互式交通中,这些规则可能由于交通环境的约束和智能体本身的约束而失效。
图6 自然界中的生物群聚现象
2.基于博弈论的模型
人类驾驶行为本质上是一个博弈问题,人类驾驶员通过相互耦合不断地做出决策。因此,考虑基于优化的状态反馈策略,驾驶员之间的交互可以形成闭环动态博弈。可以将人类驾驶员间的交互建模为动态马尔可夫博弈,每个智能体都能适应其他智能体的行为,以合作或竞争的方式完成任务,这种情况就形成了多智能体强化学习(MARL)。模仿人类驾驶员交互的博弈论方法通常用于设计多自动驾驶汽车间或自动驾驶汽车与人驾驶汽车之间的交互策略。一些研究者仅用博弈论来建模交互过程中的离散决策过程,另外,一些研究人员将博弈论方法与其他学习方法(如强化学习,逆强化学习、模仿学习)、控制理论和线性二次高斯控制结合,以模拟由决策和控制组成的整个交互过程。
(1)博弈论智能体间如何影响
目前,研究者大多选择动态博弈将交互行为转化为迭代优化问题。在博弈问题中,人类驾驶员角色的分配会影响模型性能。因此,动态博弈中第一个问题就是 ‘How should the ego vehicle consider the effects and roles of other human drivers in one single stage of sequential games?’ 通常有3种:视他车为障碍物、视他车为理智的跟随者、相互影响的执行者。
-
视他车为障碍物
大多数早期研究都遵循一个流程:首先,预测其他人类驾驶员的行驶轨迹,将其视为不变的运动障碍物,再将预测结果反馈给本车的规划模块。图7解释了本车和其他智能体之间的关系,值得一提的是,在自动驾驶汽车与人类驾驶汽车间的交互中,这种假设通常是有效的,因为相比于自动驾驶汽车,人类可能拥有更少的信息和更长的反应时间。因此,与机器人的规划和控制频率相比,人类的行为不会突然改变,因此可以视为障碍。然而,对于同类智能体间的交互,这种方法可能会导致过于保守的行为,甚至在某些情况(如僵局情形)下会导致不安全的行为。这种交互方案本质上是一种单向互动,只有本车受到其他车辆的影响。
-
理性的跟随者
为了解决保守行为和僵局的情况,研究人员将其他人类驾驶员视为理性的效用驱使智能体,他们会积极规划自己的轨迹,以响应(而不是影响)本车在序列博弈单阶段中的内部规划,如图7(b)所示。本车可以选择一个礼貌的行为,从而引起其他人类驾驶员的最佳行为/反应,这就是典型的Stackelberg game,因此,领导者对跟随者的行为有间接的控制。Stackelberg game假设其他人类驾驶员是理性的,通过考虑本车的规划不变,采取其最佳动作;本车知道其他人类驾驶员的代价函数。在该架构下,本车将其他人类驾驶员视为被动的追随者,而不是主动的追随者。Stackelberg game被构建为一个双层优化问题,其有3种求解方法:将其重新表述为局部单层优化问题;近似跟随者的最优解;为每个优化器的唯一性设置假设,该方法的缺点为忽略了车间动态相互影响,本车需要知道其他人类驾驶员的内部函数,并且人类驾驶员只是计算最佳的反应而非试图影响本车;在实际中,没有统一的方法确定leader和follower的角色。
-
相互影响的执行者
在每个时间步长上,智能体间的交互都是彼此相互依赖的,如图7(c)所示。这种动态相互依赖性可通过由strategic和tactical规划器组成的分层博弈架构实现,strategic planner被建模为闭环的动态博弈,tactical planner被建模为开环的轨迹优化器。此外,还可以使用同时博弈来捕捉动态交互依赖性,该博弈中所有车辆遵循同样的推理策略,但每个车在选择动作时不知道其他智能体选择的动作。
博弈论框架为人类驾驶员之间的动态交互提供了一个可解释的显式解决方案。然而,尽管在简化系统动力学和信息结构方面做了很多努力,但仍难以满足连续状态空间和动作空间上的计算可处理性、实时性难保证。大部分基于博弈论的模型都受限于智能体数目,所以被限制在双智能体的模拟实验或两两处理多智能体场景。为了解决这个问题,Liu等人提出了两个实用、可靠、鲁棒的框架,利用带两种求解算法的潜在博弈实现自动驾驶汽车实时决策。
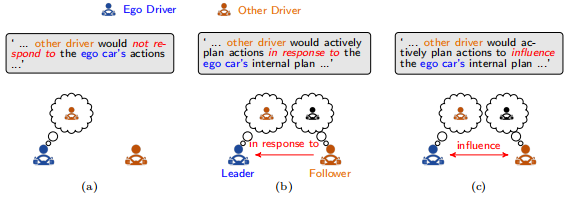
图7 单阶段博弈中两智能体间的三种关系:将其他智能体视为(a) 障碍物, (b) 理性跟随者, (c) 相互影响的执行者
(2)考虑社会因素的博弈
社会价值反映了个体在交互过程中的经验,它可嵌入到智能体的效用函数中。每个驾驶员通过评估每个动作组合来获得奖励,该奖励通常是自身奖励与其他智能体奖励的权重组合,即
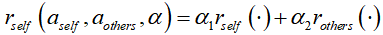
其中,
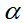
表示驾驶员的社会偏好,社会偏好的平衡可以通过调整指标
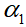
和
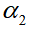
来反映。如图8展示了评估人类驾驶员社会偏好的方法:线性加和为1、社会价值的环形测量、CMetric。
-
线性加和为1
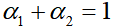
,如果
接近1,会导致本车的自私行为。该结构已被应用于自动驾驶汽车在汇入行为等交互场景下的社会决策设计中。
-
社会价值的环形测量
用环形测量将社会价值投射在二维空间上,这种方法是衡量个人人际效用最可靠的模型之一。基于这一定义,Schwarting等人通过使用SVO角度偏好来评估社会价值,角度偏好与社会价值关系为
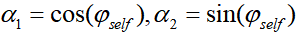
其中,

表示本车的社会价值取向。然而,这些模型无法实时估计人类的社交偏好,而是为每个智能体选择并学习一个固定的参数。
-
CMetric
- 下一篇:基于多项式的智能车辆换道轨迹规划
- 上一篇:磷酸铁锂软包与铝壳电池性能比较



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
