




 广告
广告





















































自动驾驶车辆的社会交互:回顾与展望

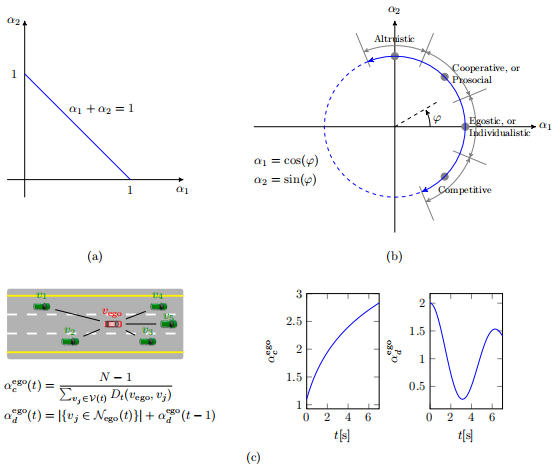
图8 评估博弈论架构下人类驾驶员间社会偏好的方法。(a) 线性加和为1 (b) 社会价值的环形测量 (c) CMetric测量
除了通过上述提到的函数量化社会因素外,一些研究者还通过调整每个博弈智能体的行动集和相关决策模型,考虑人类的其他社会因素(如礼貌水平、有限的感知能力)。
在现实交通中,许多不同的驾驶行为因素会影响人类驾驶员的合作程度。这便引出一个问题 ‘how to leverage these factors into computational models and ensure their fidelity?’ 。答案在于行为理论描述的是怎么假设一个人类驾驶员对路上其他人类驾驶员做出的行动和反应。Hoogendoorn和Bovy总结了一系列由来源不同的经验依据支持的行为假设,为高级交互模型的推导提供了基础。作者还提出了一种主观努力最小化,在此基础上使用微分博弈论建模通用驾驶行为。
(3)智能体自适应性的博弈
人类是适应性的智能体,能够通过奖励强化机制学习驾驶。受此启发,结合强化学习和博弈论架构,可以设计与其他驾驶员交互的学习程序。把本智能体外的其他智能体视为环境的一部分,建模交互的博弈架构可分为两类:异步方案、同步方案。
-
异步方案
该方案中,每个驾驶员都将周围其他所有驾驶员视为环境的一部分,如图9(a)所示。可以通过特定的博弈论方案(如level-k game)实现驾驶员之间的动态交互,人类驾驶员的行为以迭代的方式被预测(图9(c)),而不是被同时评估。具体来说,为了获得一个level-k智能体的策略,其他所有智能体的策略都被设置为level-(k−1),使它们成为环境的一部分,而环境的动态性是已知的。因此,level-k智能体的策略作为对其他智能体动作的最佳响应被估计出来,如图9(b)所示。注意,所有智能体的策略推理层可以保持相同、也可以彼此不同(动态level-k策略),在策略空间上其可以是离散的、也可以是连续的。上述博弈问题的解法是通过正确地定义状态、行动、奖励功能和环境动态,将迭代策略学习任务视为强化学习问题,称为单智能体强化学习。这种单智能体强化学习架构往往导致控制策略不稳定;即使经过训练的策略收敛了,它们仍然缺乏性能保证。另外,由于其他驾驶员的策略行为没有改变,在每一层迭代时将不会影响本智能体的行为,使得单智能体强化学习方案可能导致冒险行为甚至发生碰撞。
-
同步方案
在多驾驶员交互的场景中,每个驾驶员都试图通过反复试错的过程同时地解决顺序决策问题。环境状态的演化和每个驾驶员获得的奖励函数是由所有驾驶员的联合动作决定。因此,人类驾驶员需要考虑环境和其他人类驾驶员,并与之交互。同步方案可以通过马尔可夫博弈(或随机博弈)捕捉到包含多个人类驾驶员的决策过程。每个智能体被视为一个基于马尔科夫决策过程的代理,基于此构成多智能体强化学习(MARL)问题。针对不同的交互任务,可以设计多种不同的MARL算法学习范式。现有部分研究中,所提方法被限制在预定义的交通场景中,每个交互驾驶员的社会偏好是预定义好的。而现实中,人类驾驶员可以利用其他驾驶员的社会合作来避免僵局,并主动说服他人改变自己的行为。受此启发,Hu基于带课程学习策略的马尔可夫博弈,开发了的MARL,以考虑合作程度和模拟汇入场景中道路通行权的社会优先性。一旦Level-k博弈的单次交互level被视为RL任务,现有很多算法都可以使用,如Q-learning。RL还可以预测动态博弈中智能体的时间持续的交互动态性。
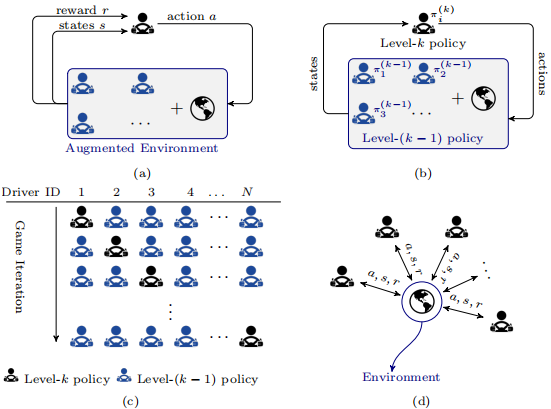
图9 (a)RL (b)level-k博弈 (c)迭代学习角度下的异步方案与(d)同步方法
(4)非完全信息博弈最常用的博弈模型是完全信息博弈,其假设每个人类驾驶员是理性的,彼此之间的信息(如效用函数、驾驶意图或驾驶风格)是可知的。然而在实际交通中,这些信息往往是无法获得的,导致智能体间信息不对称。所以,人们需要对他人的驾驶行为及对非理性行为进行非同理心的评估。为了在与不理性的人类驾驶员交互时,自动驾驶汽车能做出一个有安全保障的决策,Tian等人引入了一对社会参数(β,λ)来表征人类驾驶员的理性水平和角色,并在观察到新信息后通过贝叶斯规则进行更新。此外,当环境状态部分可观时,相互作用可通过部分可观随机博弈(POSG)和部分可观马尔可夫决策过程(POMDP)表示,该问题可以使用Q-learning等强化学习算法求解。(5)估计其他智能体信息的博弈可以参数化交互智能体的社会偏好,再将其嵌入到博弈中每个智能体的代价函数中。为了在决策时利用另一个人类智能体的行为,研究人员基于两个假设建立了人类驾驶员之间的交互模型:所有的智能体都是理性的,都以寻找效用最大化的控制行为为目标;本智能体可以得到另一个人类智能体的奖励/成本函数。然而,在现实环境中,上述假设难以直接获得,所以使用可得到的数据估计更多的信息就变得很有必要。
-
奖励函数估计
第一个假设允许将另一个人类驾驶员的决策过程转化为最优最大化问题。通常,研究人员将其他人类驾驶员的奖励函数作为当前状态的线性结构加权特征。相关的权重向量
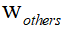
可以通过逆最优控制理论(如IRL)和最大熵原理从交互范例中估计出来。IRL旨在学习在驾驶范例中编码人类驾驶员驾驶偏好的基本代价函数。
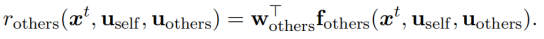
-
未来行为预测
每个智能体的奖励函数可以在固定时域内累积,而不是仅考虑未来的一步。这个操作需要本车在进行交互时预测其他人类智能体在预测域内可能的动作和状态。Level-k博弈论假设其他所有参与者都可以被建模为level-(k−1)推理者并采取相应地动作,使得在预测固定时域内未来车辆动作和状态时,能够考虑车辆对车辆的相互依赖性。3.单智能体马尔科夫决策过程另外一种建立本智能体如何学习与他人交互的方法是采用单智能体MDPs方案。单智能体假设包含其他智能体的环境是静止的,进而可以用MDP构建交互问题。本智能体在与环境交互时,通过在脑海中动态展开交互轨迹来考虑自身行为的影响,试图选择最优规划来最大化相关奖励。因此,可以把本车的驾驶任务构建为关于策略的最优化问题,选择使从环境状态s开始的未来固定时间域内的值函数最大的策略。
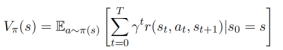
单智能体理MDPs用于对本智能体(固定的)和其他智能体之间的交互进行建模,许多现有的RL算法都可以用来求解。然而,基于异步方案的随机博弈在每个阶段博弈中交替地只将一个驾驶员作为本智能体。在真实的交通中,人类驾驶员可以在他们的头脑中预测其他人类智能体的可能输出,然后将这些潜在的可能整合到他们的实时规划中,在交互场景中产生与社会兼容的决策和行动。使用马尔科夫决策过程构建交互问题会产生两个基本问题,即‘How does the ego agent make predictions of other agents’ future behavior?’和‘How does the ego agent utilize these predictions, i.e., integrate these estimated predictions into their planning? ’本智能体如何预测其他智能体的未来行为?又如何在未来的规划中整合预测到的信息?对于行为如何预测的问题,基于本智能体如何考虑其与其他智能体之间的影响,有反应式和交互式两种预测方法。单向影响:本车预测其他人类驾驶员行为时,不考虑本车当前和未来动作对其他智能体的影响,把其他智能体视为无反应的智能体。其他智能体的行为既可以是确定的、也可以是随机的,行为确定的智能体仅按照预定义的规则和情况(如固定的规划速度、已知的先前状态/意图)行驶。对于行为随机的智能体,本智能体无法明确地知道和预测其行为,但知道他们的意图和目标的不确定性的概率分布。简单来说,在考虑单向影响的行为预测中,他车未来的行为只与自身有关,本车可以知道他车未来的行为/运动/意图。考虑了单向影响,本车可以做反应式规划reactive planning。
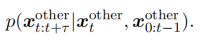
双向影响:本车预测他车未来行为时,考虑本车当前和未来的动作对周围车辆的影响,即假设其他智能体会对本车潜在的未来状态做出理性的回应。简单来说,他车未来的行为除了与自身有关外,还受到本车过去、现在及未来动作/状态的影响。在这种考虑了不确定性的交互问题中,广泛采用的方法是POMDP。考虑了双向影响,本车可以做交互式规划interactive planning。
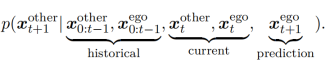
-
部分可观MDP
不确定性信息(其他智能体的意图和重新规划过程、观测不确定性和遮挡)等通常是不可观察的。一种常用的方法是建立当前状态的概率分布,形成一个可用的置信状态。POMDP可以是离线的,也可以是在线的。离线意味着解决POMDP问题关心最佳可能行动,不是针对当前、而是针对每一个可以想象的信念状态。为了使问题在计算上可解,POMDP都是在离散空间中(离散的状态、离散的动作、离散的观测、或它们的组合)构建的。
-
Q-学习
人类在自然界中的行为是通过强化而非自由意志塑造的,交互遵循这一规则。因为人类智能体通过与环境的持续交互来学习在动态和不确定的环境中驾驶,因此,具有MDP形式的强化学习能够制定交互问题。因此,接下来的问题将是‘How do we integrate the interactive influences between agents into RL algorithms?’ 我们如何将智能体之间的交互影响集成到RL算法中?。在规划时,可以通过相关的值迭代过程考虑其他智能体对本智能体的影响。已有研究采用Double Q-Learning(DQL)算法来考虑其他智能体的行为和状态对智能体价值评价的影响。
-
随机博弈
单智能体MDPs和随机博弈可以捕获多个智能体之间的相互作用,但它们之间存在一些区别。通常有两种方式可以得到随机博弈。一是将单智能体MDPs扩展到多智能体MDPs,二者的区别在于每个驾驶员在做决策时是否必须考虑其他驾驶员来采取战略行动。二是将矩阵博弈扩展到多个状态,随机博弈中每个状态都可以看成是一个矩阵博弈,其奖励是所有人类驾驶员的联合动作产生的。在进行完矩阵博弈、得到奖励后,所有智能体的状态根据他们的联合动作转移到另一个状态(进入另一个矩阵博弈)。因此,随机博弈的架构中包含了MDPs和矩阵博弈。4.从人类范例中学习群优化和基于博弈论的方法均是事先设计好的,它们凭借认知洞察力分析场景,然后设计一个与之相关的成本/目标函数来模拟人类驾驶员之间的交互行为,通过启发式地设置超参数方法来求解优化问题,而非用数据进行优化。这两种方法把成本/目标函数是作为待优化的先验知识,然而人类驾驶员间社会交互背后的决策与运动机制是复杂的,难以用简单的、人为设置的规则描述。通常,展示交互行为比确定产生同样行为的奖励函数要更容易。这就为建模和学习人类驾驶员间的交互提供了一种方法,即通过模仿学习直接从人类示例中学习交互行为。基于学习到的是行为轨迹还是效用,分为行为克隆和效用复现两种方法,前者直接学习从观测(如图像)到动作(转向角、油门)的映射,后者间接使用数据检索奖励函数,用于规划的交互行为尽可能接近地模仿范例。
-
行为克隆
行为克隆是最简单的模仿学习形式,专注于使用监督学习复制智能体的策略。行为克隆旨在解决一个回归问题,在这个问题中,优化是通过最大化目标函数(如训练数据中所采取行动的可能性)或最小化损失(如模拟(即模型输出)和真实数据(即演示)之间的行为派生)来实现的。行为克隆的成功依赖于足够多的、能够充分覆盖训练和测试数据集的状态和动作空间的数据。然而行为克隆在训练过程中没有利用级联学习错误。由行为克隆学到的模型在复杂的交互场景中通常表现的较差。
-
效用复现
IRL逆强化学习假定奖励函数在不同交通场景中是最简洁、鲁棒性、可移植性的,其依赖从观测到的交互行为/轨迹中提取/检索代价函数。复现智能体间的交互过程通常假定环境的状态要具有马尔科夫性质,这样就可以将学习任务构建为马尔科夫过程。因此,用一个参数化模型去描述驾驶员的交互过程,模型中的参数可以通过一个设计好的目标函数估计得到。标准的MDP:其他人类驾驶员作为环境中的一部分;部分可观MDP:人类驾驶员感知能力受限、无法准确感知到他们需要的信息。在该架构下,可以用IRL或IOC逆最优控制学习人类驾驶员的交互过程;值得提的一点是,在模仿学习与在基于博弈论的模型中,IRL的角色是不同的。前者中,IRL算法是学习本智能体的奖励函数、以模仿本智能体的驾驶行为,而在博弈论模型中,IRL用来学习其他智能体的奖励函数,以作为本智能体的输入。总结:理性的人类驾驶行为是在回应动态环境的所有可能答案中近最优的或最优的结果,这就可以将人类交互问题构建为数值可计算的最优化模型,最大化某个目标函数。然而,对于如此复杂的优化问题,实时求解的难度很大。参考文献:
Wenshuo Wang, Letian Wang, Chengyuan Zhang, Changliu Liu and Lijun Sun (2022), “Social Interactions for Autonomous Driving: A Review and Perspectives”, Foundations and Trends® in Robotics: Vol. xx, No. xx, pp 1–183. DOI: 10.48550/arXiv.2208.07541.
- 下一篇:基于多项式的智能车辆换道轨迹规划
- 上一篇:磷酸铁锂软包与铝壳电池性能比较



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
