




 广告
广告





















































自动驾驶系统物理世界测试方法

摘要:
深度神经网络已经广泛应用于自动驾驶车辆等自主系统中。最近,DNNtesting被深入研究以自动生成通用示例,该示例在极端情况下将小幅度扰动注入输入以测试DNN。虽然现有的测试技术被证明是有效的,特别是对于自动驾驶来说,但它们主要专注于产生数字敌对扰动,例如改变图像像素,这在现实世界中可能永远不会发生。因此,在关于自动驾驶测试的文献中有一个关键的缺失部分:理解和利用数字和物理的逆向扰动生成来影响转向决策。本文针对一种较为常见和实际的驾驶场景:路过广告牌,提出了一种系统化的物理世界测试方法,即DeepBillboard。Deep-Billboard能够生成一个健壮且有弹性的可印刷广告广告牌测试,该测试可以在动态变化的驾驶条件下工作,包括视角、距离和照明。目标是通过我们生成的敌对广告牌,最大化自动驾驶车辆驾驶的转向角错误的可能性、程度和持续时间。我们通过进行数字扰动实验和物理世界案例研究,广泛评估了DeepBillboard的效率和健壮性。数字试验的结果表明DeepBillboard对各种转向模型和场景都很有效。此外,物理案例研究表明,DeepBillboard具有足够的鲁棒性,可以在各种天气条件下为真实世界的驾驶生成物理世界的敌对广告牌测试,能够误导平均转向角误差高达26.44度。据我们所知,这是第一项证明为实际的自动驾驶系统生成现实和连续的物理世界测试的可能性的研究;此外,深广告牌可以直接推广到沿着路边的各种其他物理实体/表面,例如,在墙上画的涂鸦。
1.介绍
深度神经网络(DNNs)由于其在认知计算任务中最先进的、甚至可以与人类竞争的精度而被广泛应用于许多自主系统中。其中一个领域是自主驾驶,DNNs用于将车载摄像头的原始像素映射到转向控制决策[6,23]。最近的端到端学习框架使得dnn甚至有可能从有限的人类驾驶数据集学习自我驾驶[4]。
不幸的是,采用dnn作为控制管道一部分的系统的可靠性和正确性还没有得到正式的保证。在实践中,这类系统通常会以意想不到或不正确的方式表现不良,特别是在某些特殊情况下,由于各种原因,如DNN模型过拟合/过拟合、训练数据有偏见或不正确的运行时参数。考虑到自动驾驶的安全性,这种不当行为可能会造成严重的后果。最近的一个悲剧例子是,一辆Uber自动驾驶汽车撞死了一名亚利桑那州的行人,因为自动驾驶系统做出了一个错误的控制决定-"当受害者在晚上过马路时,它不需要马上做出反应"。
更糟糕的是,最近的DNN测试研究表明,DNN对带有扰动的有意对抗输入相当脆弱[5,15,22,27,32]。这种对抗性输入可以通过在原始输入中添加恶意扰动来进行数字化处理,从而导致目标DNN输出错误的控制决策。最近的许多DNN测试工作都在研究对抗性输入的根本原因以及如何系统地生成此类输入[5,9,18,19,29,30,33,39]。虽然这些工作提出了各种测试技术,被证明是有效的,特别是对自动驾驶,他们主要关注产生数字对抗性扰动,这可能永远不会发生在物理世界。唯一的例外是最近的一组工作[9,30],他们在打印鲁棒物理扰动方面迈出了第一步,这些扰动会导致静态物理对象的错误分类(例如,[2]中的打印输出,[30]中的人脸,[9]中的停止符号)。我们的工作旨在通过在现实的、连续的驾驶过程中提高测试的有效性,进一步增强自动驾驶的物理世界测试。专注于在任何错误分类的物理对象的任何单个快照上产生对抗性扰动不太可能在实践中起作用,因为任何现实世界的驾驶场景都可能遇到驾驶条件(例如。(视角/距离),这与静态单快照视图中的数据有很大的不同。
在本文中,我们提出了一种系统的物理世界测试方法,即DeepBillboard,针对一种非常常见和实用的连续驾驶场景:自动驾驶车辆通过路边广告牌驾驶。DeepBillboard有助于系统地生成对抗性示例,以在任意一条数字物理信道的路边广告牌上添加扰动时误导转向角。请注意,除了路边的广告牌外,基本概念还可以直接推广到各种其他物理实体/表面,例如墙上的涂鸦;在这项工作中,出于几个实际考虑,我们选择路边广告牌作为目标物理驾驶场景:1)到处都可以租用广告牌做广告。租用广告牌的攻击者可以自定义其大小和内容,如图1所示。2)广告牌通常被认为与交通安全无关或无害,并且没有严格的规则来规范广告牌的外观;3)广告牌通常很大,足以让司机看清,因此行车记录仪可以拍摄不同距离、视角和光线条件;4)攻击者可以容易地构建物理世界广告牌,以影响无人驾驶车辆的转向决策,而不会被其他人注意到,例如,实际的核心敌对绘画只能是整个广告牌的一部分,而广告牌的其他部分看起来仍然正常,例如,一些底部文本栏显示“本周六美术馆”。
DeepBillboard的目标是在车载摄像头捕捉到的每一帧图像上生成一个单独的敌对广告牌图像,该图像可能会在广告牌行驶过程中误导自动车辆的转向角度。为了产生有效的扰动,一个主要的挑战是覆盖一组展示不同条件的图像帧,包括到广告牌的距离、视角和照明。简单地应用现有的数据测试技术[29,33,39]来生成任何特定帧的数字扰动在这种情况下显然是行不通的,因为虚拟驾驶场景可能不会导致任何具有相同或相似条件的帧(例如,插入天空黑洞,如最近获奖的DeepXplore工作[29]中所做的)。此外,单个帧扰动的有效性可能是无效的,因为一个帧上的错误引导可能被下一个帧快速纠正。
为了解决这一关键挑战,我们开发了一种鲁棒且可靠的联合优化算法,该算法可以生成可打印的广告牌图像,该图像在整个驾驶过程中可能会在dashcam捕获的每一帧上误导转向角度。为了最大化对抗效果,我们开发了各种技术来最小化帧间干扰,并设计了考虑所有帧的算法来达到全局最优。此外,通过输入记录具有不同驾驶模式(例如,驾驶速度和路线)的路边广告牌的驾驶过程的视频,我们的算法可以很容易地调整为生成可打印的广告图像,该图像在考虑各种物理世界约束(例如,由于打印机硬件约束而变化的环境条件和像素可打印性)时是鲁棒的和有弹性的。
考虑这种真实世界的驾驶场景并开发相应的数字和物理对抗测试生成方法,在测试效率方面产生明显的优势:由于对抗广告牌,任何驾驶车辆被误导的转向决策的可能性、程度和持续时间可以可靠地增加。我们的主要贡献总结如下:
-
我们提出了一个新的角度来测试物理世界中的自动驾驶系统,它可以很容易地部署。
-
我们引入了一种稳健的联合优化方法,系统地生成对抗性扰动,这些扰动可以在路边广告牌上进行修补,无论是数字还是物理上,都会严重误导具有不同驾驶模式的广告牌自动驾驶车辆的转向决策。
-
我们提出了新的评估指标和方法,以测量数字和物理领域中转向模型扰动的测试有效性。
-
我们通过对数字扰动和物理案例研究进行大量实验,证明了DeepBill-board的稳健性和有效性。数字实验结果表明,DeepBill-board对各种转向模型和场景来说是有效的,能够在各种情况下误导平均转向角高达41.93度。物理案例研究进一步证明,DeepBill-board足够稳健和有弹性,能够在各种天气条件下为真实世界的驾驶生成物理世界对抗性广告牌测试,能够错误引导平均转向角误差从4.86度到26.44度。据我们所知,这是首次研究为实际自主驾驶场景生成真实且连续的物理世界测试的可能性。
2.背景和相关工作
自动驾驶中的DNN。自动驾驶系统通过多个传感器(如摄像头、雷达、激光雷达)收集周围的环境数据作为输入,用DNN和输出控制决策(如转向)处理这些数据。本文主要关注NVIDIA Dave[4]中采用的带有摄像头输入和转向角输出的转向角组件。
卷积神经网络(CNN)在分析视觉图像方面非常有效,是用于转向角决策的最广泛的DNN。与常规神经网络类似,CNN由多层组成,以前馈的方式通过层传递信息。在所有层中,卷积层是CNN中的一个关键组件,它与前一层输出的核进行卷积,并将特征映射发送给后续层。与另一种广泛使用的DNN架构-回流神经网络(RNN)不同,它是一种具有反馈连接的神经网络,基于CNN的转向模型仅根据当前捕获的图像做出转向决策。在本文中,我们重点关注CNN转向模型的测试,并将RNN测试作为未来的工作。尽管如此,我们注意到DeepBill-Board可以进行调整以应用于RNN测试。直观地说,这可以通过根据RNN的具体特性修改梯度计算方法来实现。
Digital Adversarial Examples.最近的研究表明,深度神经网络分类器可以通过对抗性示例进行测试和进一步欺骗[5,15,20,22,27,32]。这种测试可以在黑盒[25,26]和白盒[5,15,22,27,32]设置中进行。Goodfellow等人提出了快速梯度法,该方法应用损失函数的一阶近似来构造对抗样本[14]。还提出了基于优化的方法来为目标攻击创建对抗干扰[5,16]。同时,最近的DeepTest[33]和DeepRoad[39]技术通过简单的仿射/滤波变换或生成对手网络(GAN)来转换原始图像以生成对手图像[13]。总的来说,这些方法有助于理解数字对抗示例,生成的对抗示例可能在现实中根本不存在(例如,DeepTest[33]和DeepRoad[39]生成的雨天驾驶场/景仍然远离真实世界场景)。相比之下,我们的工作考察了动态条件下真实物体(广告牌)的物理扰动,如距离和视角的变化。
Physical Adversarial Examples.Kurakin等人表明,对抗性的例子,当由智能手机摄像头拍摄时,仍然可以导致错误分类[15] 。Athalye等人引入了一种攻击算法,以生成对一组合成变换鲁棒的物理对抗示例[3]。他们进一步制作了扰动物体的3D打印副本[3]。上述工作与我们的工作的主要区别包括:(1)先前工作在优化过程中只使用一组合成变换,可能会忽略细微的物理效果;而我们的工作可以从合成变换和各种现实世界物理条件中取样。(2) 我们的工作修改了真实大小的物体;(3)我们的工作目标是测试现实和持续驾驶场景。
Sharif等人提出了基于DNN的人脸识别系统的躲避和模仿攻击,方法是在眼镜架上打印敌意攻击[30]。他们的研究表明,在相对稳定的身体条件下,在姿势、与相机的距离/角度以及光线变化不大的情况下,成功地进行了身体攻击。这有助于对稳定环境中物理样本的有趣理解。然而,一般来说,环境条件可能变化很大,有助于降低扰动的有效性。因此,我们选择了汽车广告牌分类的固有无约束环境。在我们的工作中,我们明确地设计了扰动,使其在各种连续的物理世界条件下(特别是大距离/角度和分辨率变化)有效。
Lu等人针对检测器对路标图像进行了物理对抗性测试,结果表明当前检测器可能受到攻击[17]。最近的几项工作以数字方式展示了对抗检测/分割算法的对抗性示例[8,21,38]。攻击自动驾驶系统的最新工作是Eykholtand Evtimov等人开展的工作。他们表明,可以为路标分类器构建物理鲁棒攻击[9],并且此类攻击可以进一步扩展到攻击YOLO检测器[10]。我们的工作与此类工作不同,因为以下事实:(1)我们通过在路边广告牌上构建可打印的扰动来攻击转向模型,这些扰动可以在任何地方,并且比路标具有更大的影响;(2) 我们提出的算法考虑了由行车记录仪捕获的一系列连续帧,这些帧的距离和视角逐渐变化,并寻求最大化通过我们的对手路边广告牌驾驶的自主车辆的转向角度的可能性和误导程度;(3)提出了一种新的联合优化算法,以有效地生成数字和物理攻击。
3.生成对抗模式
3.1对抗场景
DeepBillboard的目标是误导自动车辆的转向角,通过在路边的广告牌上绘制对抗性扰动,从车道中心偏离轨迹。我们的目标DNN是基于CNN的转向模型[4,12,31,35,36],不涉及检测/分割算法。转向模型将行车记录仪拍摄的图像作为输入,并输出转向角度决定。
我们使用偏离跟踪距离来测量测试有效性(即转向误导的强度),这已应用于Nvidia的Dave[4]系统,以触发人为干预。车辆速度为v m/s,使用DNN参考的决策频率为i(s秒),地面真实转向角为α,误导转向角为a′,偏移跟踪距离以v·i·sin(α′−α)来计算. 在潜在的物理世界攻击中,测试仪/跟踪仪通常无法控制车辆速度。因此,我们使用转向角误差,即地面真实和误导转向之间的转向角发散,来衡量测试效果。
我们考虑的是实际的驾驶情景,而不是仅仅以单一、固定的姿态和视角误导驾驶决策。具体而言,当车辆驶向广告牌时,我们会试图生成一个物理对抗性广告牌,它可能会误导从不同距离和角度观看的一系列行车记录仪捕获帧的转向决策。捕获帧的数量明显取决于行车记录仪的FPS和车辆从起始位置行驶到实际通过广告牌的时间。考虑到这样一个真实的动态驾驶场景,在攻击强度方面具有明显的优势:由于对抗性广告牌,任何车辆驾驶的误导性转向决策的可能性和程度都会大大增加。我们强调,这一考虑也从根本上区分了DeepBillboard的算法设计与应用更简单的策略,如随机搜索、平均值/最大值池、不同的顺序等。应用这些更简单的方法将改善单帧的误导角度,但降低总体目标。经过几次迭代,这些方法很难改善目标。
3.2评估指标
我们的评估指标旨在反映攻击强度的可能性。车辆可能以不同的速度和角度经过我们的对手广告牌,这可能会影响相机拍摄的图像帧数和不同帧之间的广告牌布局。假设ˆX={x0,x1,x2,…,xn}表示一组详尽的图像帧,这些帧可能由具有任何驾驶模式(例如驾驶速度和速度)的车辆捕获,那么由任何车辆捕获的帧显然是子集X⊆ˆX。我们的目标是生成可以影响(几乎)ˆX中每一帧的物理可打印广告牌,以便与潜在的现实世界驾驶场景相对应的任何子集X都有最大的受影响机会。为了实现这个目标,我们定义了两个评估指标M0,M1,如下所示。
M0 测量ˆX中帧的平均角度误差(AAE):

其中f(·)表示目标转向模型的预测结果,x′表示扰动帧。此指标度量对帧超集的平均攻击强度。较大的M0值意味着在通过广告牌驾驶过程中误导转向角的可能性更大,误差也更大。
M1测量X中角度误差超过预定义阈值的帧的百分比,用τ表示。τ可以根据实际驾驶行为进行计算。M1的正式定义由如下公式给出:

例如,如果我们想在0.2秒的时间间隔内以1米的离轨距离误导40英里/小时的自动驾驶车辆,那么τ可以计算为16.24。我们主要采用M1作为物理世界案例研究的评估指标,因为M1可以根据实践中的安全标准,在给定任何合理的预定义阈值的情况下,清楚地反映导致不可接受的转向决策(例如,可能导致事故的决策)的帧数。
3.3挑战
对物体的物理攻击应该能够在不断变化的条件下工作,并且能够有效愚弄分类器。我们使用目标公告牌分类来构建这些条件的讨论。这些条件的一个子集也可以应用于其他类型的物理学习系统,如无人机和机器人。
1.Spatial Constraints(空间约束)。现有的对抗性算法主要侧重于干扰数字图像,并将对抗性干扰添加到图像的所有部分,包括背景图像(例如天空)。然而,对于一个实体广告牌,攻击者不能操纵除了广告牌区域之外的背景图像。此外,攻击者不能假设存在一个固定的背景图像,因为它会随着经过车辆的行车记录仪的距离和视角而变化。
2.Physical Limits on Imperceptibility(不可感知的物理极限)。现有的对抗性学习算法的一个吸引人的特点是,它们对数字图像的扰动往往在量级上很小,以致于偶然的观察者几乎察觉不到这些扰动。然而,当将这种最小的扰动传输到真实世界的物理图像时,我们必须确保相机能够感知这些扰动。因此,扰动不可测性存在物理约束,这也依赖于传感硬件。
3.Environmental Conditions(环境条件)。在自动驾驶汽车上,摄像头相对于广告牌的距离和角度可能会不断变化。被输入分类器的捕获帧是在不同的距离和观看角度拍摄的。因此,攻击者在广告牌上添加的任何干扰都必须能够在这种动态下生存。其他影响环境的因素包括光照/天气条件的变化,以及相机或广告牌上的碎片的存在。
4.Fabrication Error(制造错误)。要实际打印出包含所有构造扰动的图像,所有扰动值必须是可以在现实世界中打印的有效颜色。此外,即使制造设备(如打印机)可以产生某些颜色,也可能存在某些像素不匹配错误。
5.Context Sensitivity(上下文敏感度)。考虑到上下文,ˆX中的每一帧都必须受到干扰,以最大化整体攻击强度(例如,最大化M0)。每个被扰乱的帧可以被映射到具有一定视角和距离的可打印的对抗性图像上。每个独立帧都有自己的最佳扰动。然而,我们需要考虑所有帧的上下文,以生成一个可打印的、全局最优的、所有帧的对抗图像。
为了对深度学习分类器进行物理攻击,攻击者应该考虑到上述物理世界的限制,否则有效性可能会显著减弱。
3.4DeepBillboard的设计
我们设计了DeepBillboard,它可以生成一个可打印的图像,可以粘贴在路边广告牌上,方法是分析给定的视频,其中车辆通过不同驾驶模式的路边广告牌行驶,从而不断误导任何自动驾驶车辆的转向角决策。Deep Billboards用于为给定视频的每个帧fi生成扰动,而不考虑帧上下文和其他物理条件。然后我们描述如何更新算法来解决前面提到的物理世界的挑战。最后我们详细描述了DeepBillboard的算法伪代码。我们注意到,实际上不可能构建图像帧的详尽集合(即X),可能是由具有任何驾驶模式(例如,驾驶速度和路线)的路过车辆捕获的。尽管如此,由于更大的ˆX,处理更多的驾驶视频将明显增强DeepBillboard的测试效率,但代价是时间复杂性增加。
单帧对抗性示例生成搜索要添加到输入x的扰动σ,以便目标DNN转向模型f(·)可以预测扰动input x′=x+δ,如下所示。
其中,H是一个选定的距离函数,Ax是地面真实转向角。通常,在我们的评估中,地面真实转向角是不应用对抗广告牌的原始预测转向角,根据我们的定义为f(x)。为了解决上述约束优化问题,我们将其重新表述为拉格朗日松弛形式,类似于之前的工作[9,30]:

其中L为损失函数,用于测量模型预测值与地面真实值Ax之间的差异。本文的攻击场景可以看作是一种以不被正确推断为目的的推理躲避。
Joint Loss Optimization(联合优化损失)。如前所述,我们的目标是生成一个单一的对抗图像,可能会误导自动驾驶汽车的转向角度,在每一帧行车时,仪表盘摄像头可能捕捉到的广告牌。当从不同的角度和距离观看时,对抗性广告牌的外观可能会有所不同。因此,为了达到目标,我们需要生成一个可打印的对抗性扰动,它可以误导驾车过程中捕获的每一帧图像。这显然是一个超越单幅图像的优化问题。由于广告牌上的一处改动会影响到所有的框架,因此有必要将所有的框架放在一起考虑。为此,问题变成为图像集X中的每一张图像x找到一个单一的扰动∆,从而对公式3进行优化。我们将这种扰动生成形式化为下面的优化问题。
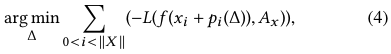
其中,pi是可打印的扰动∆在每个单独帧中的投影函数。
Handling Overlapped Perturbations(处理重叠干扰)。每一帧都可能产生一组扰动,这些扰动由多个像素组成,这些像素将在最终可打印敌方图像上更新。多帧的扰动可能会遇到重叠像素,这可能会在这些帧之间产生干扰。为了最大限度地提高攻击强度,DeepBillboard仅按顺序为每个帧更新固定数量的k个像素,以尽量减少多个帧之间的重叠干扰。这k个像素是对误导决策影响最大的像素。我们假设覆盖摄像头捕捉到的n个帧的最终敌对广告牌图像由m个像素组成。k是满足n * k < m的值,这有助于减少帧间扰动重叠的总体机会。对于每个重叠像素,我们通过贪婪地选择一个最大化客观度量的值(例如M0)来更新它。
Enhancing Perturbation Printability(增强扰动可打印性)。为了使扰动在物理世界中工作,每个扰动像素都需要是现有打印机硬件的可打印值。设 P⊂[0,1]^3是可打印的RGB三元组集合。我们定义像素的非打印性评分(NPS)来反映该像素与任意像素之间的最大距离。NPS值越大,就意味着准确打印出相应像素的机会越小。我们将像素的NPS定义为:
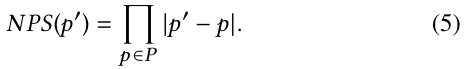
我们将扰动的NPS定义为该扰动中所有像素的NPS值之和。
Adjust Color Difference under Various Environment Conditions(在各种环境条件下调整色差)。对于不同的环境条件,属于广告牌图像的同一像素的可见颜色在行车记录仪捕获的视频中可能看起来不同。这种差异可能会影响不同条件下的对抗效能。在我们的物理世界实验中,我们用单色p={r,g,b}来预填充整个广告牌。在特定的环境条件下,相机显示的实际颜色可能会变为p′={r′,g′,b′}。基于我们的初步实验,我们观察到同一图像中像素的这种色差几乎相同。为了简化这个问题,我们为每个图像引入了一个颜色调整函数ADJi=di(p,p′)来调整色差。
Algorithm overview(算法概述)。DeepBillboard生成对抗广告牌图像的过程如图2所示。为了生成对手广告板图像,我们首先用单色预填充广告牌,并用对比色绘制其四个角,以便(1)数字定位广告牌的坐标,(2)获得颜色调整功能ADJi。然后,我们使用仪表盘摄像头录制视频,以不同的驾驶行为(例如,不同的驾驶速度和驾驶模式)沿路开车经过广告牌。然后,我们将预先录制的视频发送到我们的算法输入,以生成可打印的对手广告牌图像。如前所述,输入更多的驾驶视频将明显增强DeepBillboard的测试效率,但代价是增加了时间复杂性。

我们的对抗算法的伪代码在Alg1中进行了说明。我们的算法本质上是基于迭代的。在每次迭代中,我们首先根据反映每个像素对最终目标影响的梯度,获得一批随机选择的图像的扰动建议。然后,我们只贪婪地应用那些可能导致更好的对抗性效果的拟议扰动。我们应用足够多的迭代次数来最大化转向角分歧和扰动的稳健性。
如Alg1开始时所见。1、输入包括:预录视频中的帧列表、每个帧中广告牌四角的坐标列表、增强迭代次数、批量大小、颜色调整因子列表和目标数字扰动的维度。如Alg1所示,扰动是由RGB像素值组成的先验扰动矩阵(第2行)。我们使用COLOR_INIT函数以一个单色c∈ {0|255}^3预填充可打印扰动矩阵。基于我们广泛的数字和物理实验,使用单色预填充矩阵可以得到更好的结果和更快的收敛速度。根据我们的实验,对于我们的测试目的来说,金色、蓝色和绿色是最有效的单色。pert_data是一个矩阵列表,它存储了一批图像的建议扰动(第2行)。第5到22行通过增强迭代循环,目的是最大化对抗有效性和扰动鲁棒性。在第6行,我们随机打乱捕获帧的处理顺序。目的是避免在早期视频帧中快速收敛到非最优点(类似于深度神经网络训练)。从第7行开始,我们循环处理所有分割成批次的图像。对于每个图像批,我们在循环处理批内的每个图像之前(第10行)初始化并清除pert_data(第8-9行)。
对于批次中的每个图像x,我们计算其梯度,即目标函数对输入图像的偏导数[14](第11行)。通过迭代改变梯度上升,目标函数可以很容易地最大化。我们注意到,我们可以通过选择坡度的正值或负值,故意误导目标转向模型向左或向右转向,坡度由DIRECTION值-1,1控制(第11行)。然后我们对梯度应用域约束(第12行),以确保我们只更新属于广告牌对应区域的像素,并且梯度上升后的像素值在一定范围内(例如,0到255)。在实施过程中,如前所述,我们引入了一个参数k,只应用对对抗效果影响最大的顶梯度值。这是为了减少所有图像之间的重叠扰动。与JSMA[28]中使用的显著性地图不同,它代表了当前图像中X被归入目标类别的信心分数,我们考虑了对这个场景中所有图像的联合目标函数的影响,寻求最大化与地面真实的平均转向角差异。在约束适用的梯度之后,我们将每个图像的梯度值投影到批处理图像的拟议扰动(第13行)。ADJ(即环境因素调整的输入列表)用于纠正不同照明条件下的色差。例如,如果纯黄色(255,255,0)变为(200,200,0),则ADJ设置为(55,55,0)。当投影到物理广告牌上时,梯度值应增加(55,55,0)。
在批处理中的所有图像都得到梯度后,它们之间可能存在重叠的扰动。也就是说,对于对应于重叠扰动的每个像素,它可能具有最终可打印对抗示例的多个建议更新值。为了处理这种重叠(第14行),我们实现了三种方法:
(1)用提出的扰动中的最大梯度值更新重叠像素;
(2)用所有梯度值的总和更新重叠像素,
(3)用对目标函数整体影响最大的建议值之一更新重叠像素。
然后在第15行,我们通过将梯度添加到当前物理扰动扰动来计算建议的更新的tmpt_pert。在颜色校正和不可打印的分数控制(第16行)之后,根据坐标(第17行)将物理广告牌的拟议扰动投影到图像中。我们计算扰动图像的总转向角差(第18行)。如果提议的扰动可以改善目标,或满足模拟退火以避免SA指示的局部最优(第19行)[37],我们接受提议的扰动(第20行),并用这些扰动更新所有图像(第21行)。然后记录当前迭代的总转向角发散,并将其用作下一迭代的起点。当所有增强操作完成时,我们返回物理扰动作为结果输出。我们注意到,虽然我们的主要目标是产生物理扰动,但输出也可以直接拼接到数字图像。
4评估
在本节中,我们评估了DeepBillboard对各种转向模型和道路场景的数字和物理效果。
4.1实验设置
数据集和转向模型。我们使用四个预先训练的大众CNN作为目标转向模型,这些模型已广泛用于自动驾驶测试[18,29,33,39]。具体来说,我们测试了基于英伟达DAVE自动驾驶汽车架构的三个模型,分别为Dave_V1[24]、Dave_V2[12]、Dave_V3[31],以及来自Udacity挑战赛[34]的Epoch模型[35]。(转向模型来源)
具体来说,Dave_V1是NVIDIA的Dave系统[4]中呈现的原始CNN架构。Dave_V2[12]是Dave_V1的变体,它将随机初始化的网络权重标准化,并移除第一批标准化层。Dave_V3[31]是另一个公开可用的转向模型,它通过删除两个卷积层和一个完全连接层,并在三个完全连接的层之间插入两个丢失层,来修改原始Dave模型。由于预先训练的Epoch权重不公开,我们按照相应作者使用Udacity自动驾驶挑战数据集提供的说明进行训练[34]。
(数据集)
我们实验中使用的数据集包括:
(1)Udacity自动驾驶汽车挑战数据集[34],其中包含101396张由安装在仪表板上的驾驶汽车摄像头拍摄的训练图像,以及驾驶员对每张图像同时应用的方向盘角度;
(2) Dave测试数据集[7],其中包含GitHub用户记录的45568张图像,用于测试NVIDIA Davemodel;
(3)Kitti[11]数据集,包含配备四台摄像机的大众帕萨特旅行车拍摄的六个不同场景的14999张图像。
用于我们实际案例研究的数据集包括安装在驾驶汽车挡风玻璃后面的行车记录仪记录的视频,用于驾驶校园内预先放置的路边广告牌。我们使用上述预先训练的转向模型来预测每一帧,并使用最终的转向角决定作为基本事实。(具体的现实实验操作)
4.2
实验设计。根据在第3.2节中的讨论,我们通过测量场景中所有帧的平均角度误差(数字和物理)来评估算法的效率。对于数字测试,我们的场景选择标准是,布告牌应完全出现在第一帧中,像素超过400像素(因为在物理世界中打印和应用时,包含低于400像素的布告牌太小,对对抗目的而言意义不大)。然后,我们从上述数据集中随机选择七个满足此标准的场景,并对所有选定场景进行评估。每个数据集中选定的场景涵盖直车道和弯车道场景。由于所有这些数据集都不包含广告牌的坐标,因此我们必须在选定场景的每个帧中标记广告牌的四个角。在半自动标记过程中,我们使用Adobe After Effects[1]的运动跟踪器功能自动跟踪连续帧中广告牌四个角的移动。然后,我们对某些坐标不够精确的帧进行必要的调整。我们在表1中列出了所有研究场景的统计数据,其中第一列列出了场景名称,第二列显示了每个场景中的图像数量,第三到第五列显示了图像的分辨率和每个场景中广告牌的最小/最大尺寸。在数字测试中,在不同的环境条件下没有颜色调整。最后一个对抗性示例根据投影函数被拼接到每个帧中。然后,我们使用转向模型预测修补后的图像,并将其与给定数据集中记录的地面真实转向决策进行比较。
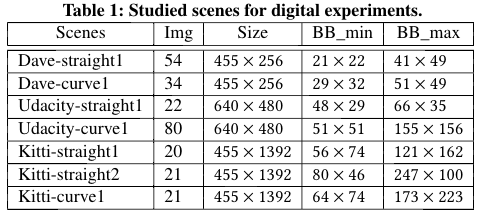
我们比较的基线是每个给定的训练模型的推理转向角。我们的方法是寻求与基线的最大距离,无论基线是地面实况还是推理结果。
由于实验中使用的驱动数据集可能没有地真转向角,因此我们选择以推断为基线的结果进行展示。由于存在许多身体正确的驾驶行为,我们使用统计方法(例如,平均值,百分比)来测试整个驾驶环节的有效性,而不是在每个单独的帧内。
(物理测试主要是为数字测试采集行驶录像数据包含地面真实转向角度,但这里的物理测试并不是真实严格的路况场景)
在物理测试中,我们使用安装在车辆上的测速记录仪以不同的真实驾驶速度记录多个视频。我们在路边放一块广告牌,然后沿着路的中央直朝广告牌开过去。我们在距离广告牌约100英尺处开始录音,当车辆经过广告牌时停止录音。我们在三种不同的天气条件下进行多种物理测试,包括晴天、阴天和黄昏天气。物理测试由以下两个阶段组成:
(1)第一阶段:我们用一个白色的广告牌,四个角涂成黑色,然后用一个金色的广告牌,四个角涂成蓝色。对于每一块广告牌,我们记录并以10英里/小时的慢速沿着道路中央行驶,以捕获足够的帧(即训练视频)。
(2)第二阶段:我们将输入视频发送到我们的测试算法,以自动生成对抗性扰动,然后将其粘贴到广告牌上。然后我们以20英里每小时的正常速度开车经过对面的广告牌,并记录视频(即测试视频)。我们计算视频每帧的平均角度误差与地面真相转向角度的比较。
(严格测试应该采用真实路况的行驶场景,但由于条件现实,提出替代方法)
我们注意到,严格来说,一个真实世界的测试将涉及实际的自动驾驶车辆驶过广告牌来观察对抗性影响。不幸的是,由于缺乏实际的自动驾驶汽车,为了在现实环境中验证DeepBillboard,我们采用了类似的方法应用于以下先进的自动驾驶研究[29,33,39],该研究也没有将实际的自动驾驶汽车纳入评估。具体来说,我们将不同驾驶模式的视频作为输入,可以尽可能详尽地覆盖所有潜在的观看角度,在不同的车辆到广告牌的距离。在物理世界评估中,我们试图预先记录尽可能多的异常驾驶视频,以覆盖实际自动驾驶汽车中大多数可能被误导的驾驶场景。这样的视频已经应用在对抗性建设/训练阶段。我们在以下匿名链接中展示了这段异常驾驶视频:https://github.com/deepbillboard/DeepBillboard。这段视频显示,DeepBillboard能够在每一帧内连续偏离一辆车。这将模拟许多实际的自动驾驶场景中的一个,即车辆在每一帧中都被deepbillboard连续误导(即,每一帧中的误导角度与本视频中显示的角度相似)。
4.2数字扰动结果
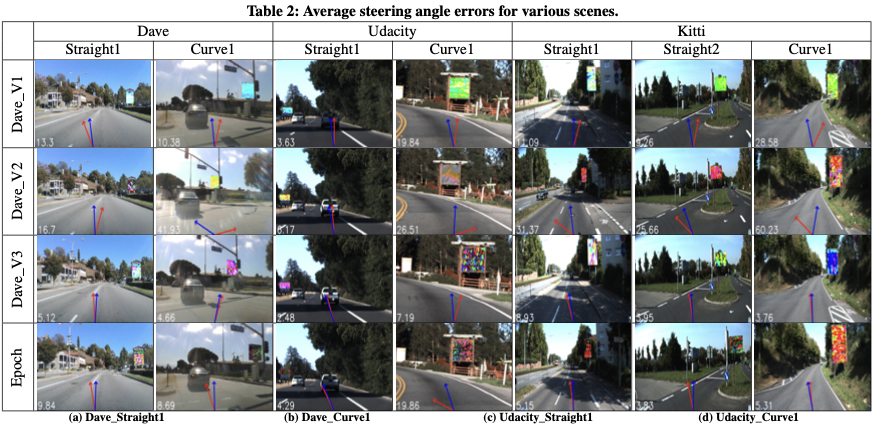
数字扰动的结果如表2所示,其中每列代表一个特定的场景,每行代表一个具体的转向模型。单元格中的每个图像都显示一个具有中间转向角度发散的代表性帧。例如,单元格中的图像(Dave_V1,Udacity_Scene1)表示Udacity数据集Scene1中的图像,当Dave_V2转向模型预测时,Scene1在同一场景中的所有帧中具有平均角度误差。两个箭头显示每个图像中的转向角决策分歧,其中蓝色的是基本事实,红色是生成的对抗示例的转向角。我们注意到,在所有场景中,DeepBillboard都会使所有转向模型产生可观察到的平均转向角偏差。






最新资讯
-
2025年10大隐形车衣品牌排行榜
2025-04-07 10:40
-
沃尔沃卡车与Greenlane合作推动商业电动化
2025-04-07 08:42
-
江铃晶马:美标转欧标充电结构专利
2025-04-07 08:39
-
EMC成为新贸易壁垒,零跑在乌兹被全面叫停
2025-04-07 08:37
-
Euro-NCAP 2026 鞭打规程解读
2025-04-07 08:36
