




 广告
广告





















































虚-实和实-虚的场景图像合成方法

-
虚-实图像合成方法
即使是最复杂的游戏,其实时渲染依然⽆法实现真实的现实场景,⼈眼⼀眼就能分辨模拟图像和真实图像。Intel的工作EPE(Enhancing Photorealistic Enhancement)【1】利⽤游戏引擎渲染过程中产⽣的中间结果G-Buffers,作为训练卷积神经⽹络的额外输⼊信号,可进⼀步增强游戏中图像的真实性。不直接⽣成数据,⽽是在已经渲染的图像上进⾏增强,集成场景信息来合成⼏何和语义⼀致的图像。
在EPE中,卷积网络利用传统渲染流水线生成中间表征G-buffers,提供景深、形状、光照、透明度、材质等特征信息;通过对抗目标训练,在多个感知层提供监督信号,用GAN的鉴别器评估增强图像的真实性;在训练过程中对图像块进行采样,以消除图像伪影。
其网络模型有两个改进点:
1)普通卷积取代strided convolution;
2)渲染-觉察非规范化(rendering-aware denormalization, RAD)模块,取代BN层。
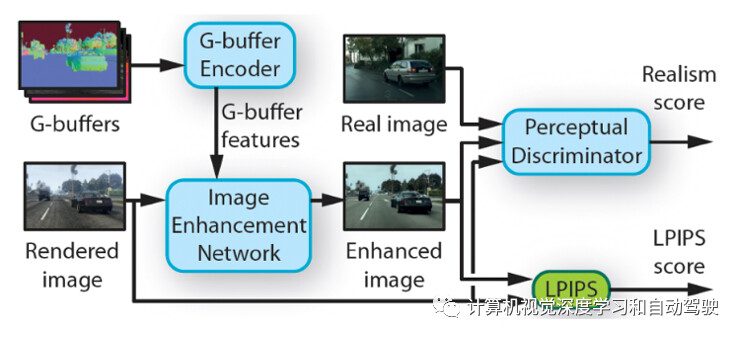
如图所示EPE的总体框架:图像增强网络(Image Enhancement Network)可以转换渲染的图像,除了图像,还有来自传统图形学流水线的渲染信息G-buffer,网络提取多尺度G- buffer特征张量,由G-buffer编码器网络(Encoder)编码;通过LPIPS(Learned Perceptual Image Patch Similarity)损失保持渲染图像的结构,以及感知鉴别器(Perceptual Discriminator)最大化增强图像的真实性,这样联合训练两个网络。
如图是图像增强网络架构:让RAD模块替换HRNet中的BN层,形成一个RAD-块(RB);HRNet每个分支,在匹配尺度接收一个G-buffer特征张量。
RAD通过来自传统渲染流水线的编码几何、材质、照明和语义信息来调整图像特征张量。图像特征通过Group Normalization进行归一化,然后通过每个元素权重进行尺度伸缩和移位。学习权重并适应G- buffer编码器接收的G- buffer特征。为了更好地适应权重,通过每个RAD模块内的三个残差块来变换G-buffer特征。
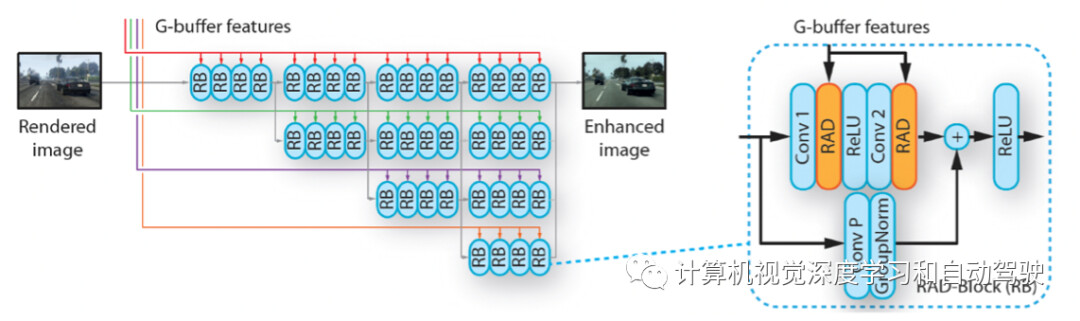
如图是G-buffer编码器网络架构图:考虑不同的数据类型和G- buffer的不同空间密度,通过多个流(0–c)处理这些特征,融合到一个和one-hot编码目标ID一致的联合表征中;通过残差块进一步变换特征;与图像增强网络中的分支,尺度做到匹配。
在G-buffer编码器和RAD模块中,都采用残差块:由卷积层(核大小为3)组成,具有频谱归一化(spectral normalization)和ReLU。

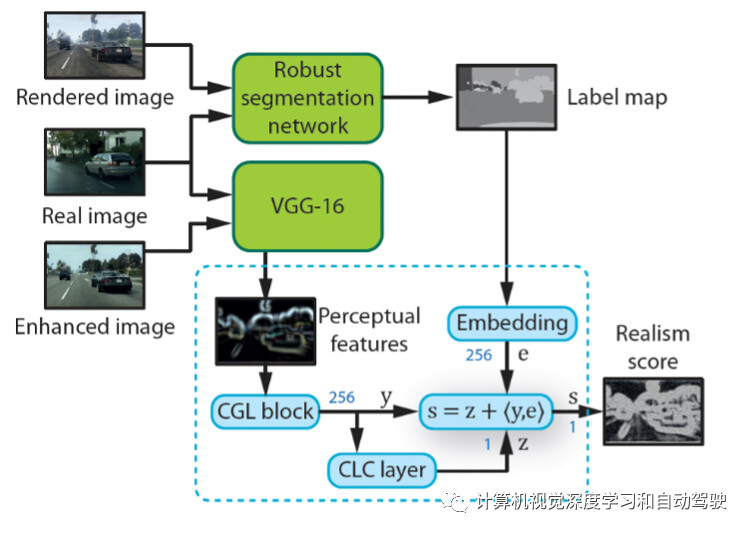
如图是感知鉴别器网络架构图:感知鉴别器评估增强图像的真实性,其由预训练的鲁棒分割(MSeg)和感知(VGG)网络(绿色)组成;通过标签图和感知特征张量提供高级语义信息;图和张量被鉴别器网络获取,产生真实感分数图。
2. 实-虚图像合成方法
当前的图像仿真工作要么无法实现真实感,要么无法模拟3D环境和其中的动态目标,从而失去了高级控制和物理真实感。GeoSim【2】是Uber提出的一种几何-觉察图像合成过程,从其他场景提取动态目标以新姿态渲染,增强现有图像,合成新自动驾驶场景。
其构建一个具有真实几何形状和传感器数据外观的多样化3D目标库。在仿真过程中,合成方法完成几何-觉察的模拟工作:
1. 在给定场景放置合理真实的目标,
2. 从资产库中得到动态目标新视图,
3. 合成和混合渲染该图像。
生成的合成图像具有真实感、交通-觉察和几何一致性,允许扩展到复杂用例。跨多个摄像头传感器进行远程逼真视频模拟,数据生成结果做下游任务数据增强。
如图所示是为自动驾驶通过几何-觉察合成的真实感视频仿真:一种数据驱动的图像处理方法,将动态目标插入现有视频中。生成的合成视频片段是高度逼真、布局清晰且几何一致,允许图像模拟扩展到复杂用例。

首先通过执行3D目标检测和跟踪来推断场景中所有目标的位置。对于要插入的每个新目标,根据高清地图和现有检测的交通,选择放置位置以及使用哪个目标模型。然后,为新放置的目标使用智能驾驶员模型(IDM),为了使其运动逼真,考虑与其他参与者的交互并避免碰撞。该过程的输出定义了要呈现的新场景。然后,用具有3D遮挡推理的新视图渲染,对场景中的所有元素进行渲染,在新图像中创建新目标的外观。最后,用神经网络来填充插入目标的边界,创建任何丢失的纹理并处理不一致的照明。
如图是3D目标放置、片段检索和仿真示意图:3D-觉察场景表征、碰撞-觉察的位置设定和视频仿真概览。

希望在现有的图像中放置新目标,保证在规模、位置、方向和运动方面都是合理的。为了实现这一目标,利用城市中车辆行为的先验信息。用2D目标插入很难实现类似的真实感水平。因此,用有BEV车道位置的高清地图,目标位置参数化为BEV目标中心和方向三元组,随后用局部地面高程将其转换为6DoF姿态。
目标样本应该与现有目标有真实的物理交互,符合交通流,并在摄像头的视野中可见。为了实现这一点,从摄像头视野内的车道区域中随机采样一个位置,并从车道中检索方向。拒绝所有导致与其他参与者或背景目标碰撞的样本,最后得到目标在初始帧的放置。为模拟视频模拟中随时间推移的合理位置,用智能驾驶员模型(IDM)拟合运动模型,更新模拟目标的状态,与周围交通进行真实交互。
插入的目标必须遵守现有场景元素的遮挡关系。例如,植被、栅栏和其他动态目标可能具有不规则或薄的边界,使遮挡原因复杂化。一种简单的策略是,将插入目标的深度与现有3D场景的深度图进行比较,确定目标场景中插入目标及其阴影的遮挡,如图10-41所示:为了实现这一点,首先通过一个深度补全网络(depth completion)估计目标图像的密集深度图。输入是RGB图像和通过激光雷达扫描投影到图像上而获取的稀疏深度图。用这个目标的渲染深度,评估目标图像的深度是否小于相应目标像素的深度,可计算得到遮挡掩码。
在遮挡推理之后,渲染的图像可能看起来仍然不真实,因为插入片段可能是与目标场景不一致的照明和颜色平衡、还有边界处的差异,以及来源视图的缺失区域。为了解决这些问题,用图像合成网络(SynNet)将源片段自然地混合到目标场景,如图所示:网络将目标背景图像、渲染的目标物体(target object)以及目标轮廓作为输入,并输出自然合成背景和渲染目标的最终图像。

合成网络架构类似于图像补全网络,只是将渲染的目标掩码作为附加输入。网络用目标场景中实例分割掩码图像进行训练。
3 参考文献
【1】S R. Richter, H Ab Alhaija, and V Koltun,“Enhancing Photorealistic Enhancement“(EPE),IEEE T-PAMI,2021
【2】Y Chen, F Rong,S Duggal, S Wang,X Yan,S Manivasagam,S Xue,E Yumer,R Urtasun,“GeoSim: Realistic Video Simulation via Geometry-Aware Composition for Self-Driving“,arXiv 2101.06543,2021



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
