




 广告
广告





















































交通场景的真实性驾驶行为仿真方法

仿真是自动驾驶车辆等机器人系统扩大验证和确认(V&V)的关键。尽管在高保真的物理模型和传感器仿真方面取得了进展,但在模拟道路使用者真实行为的方面仍存在严重差距。
AdvSim【1】是Uber提出的一种对抗性框架,为激光雷达自动驾驶系统生成安全关键场景。
如图所示:目标是在现有场景中干扰交互参与者的机动,对抗性行为会导致现实的自动驾驶系统出现故障;给定初始交通场景,AdvSim以物理合理的方式修改参与者的轨迹,并更新激光雷达传感器数据;通过从传感器数据进行模拟,获得对全自主驾驶安全-紧要的对抗场景。
场景扰动的真实激光雷达模拟如图所示:给定参与者动作的场景扰动,修改先前记录的激光雷达数据以准确反映更新的场景配置;在确保传感器真实性的同时,移除原始的参与者激光雷达观测数据,并在扰动位置用模拟的参与者激光雷达观测数据代替。
为了产生物理上可行的参与者行为,将轨迹参数化为自行车模型(bicycle model)状态序列,包括受扰动参与者的中心位置、航向、前进速度和加速度、以及车辆路径的曲率。通过在不同时间步长设定边界内扰动曲率和加速度值的变化,并用运动学自行车模型计算其他状态,可以生成候选对抗轨迹。此外,为了扩大采样对抗行为的空间,还允许初始状态在设定边界内扰动。
为了增加扰动轨迹的合理性,要确保它不会与其他参与者或自动驾驶车的原始专家轨迹发生碰撞。在实践中,首先执行拒绝采样来创建一组物理可行的轨迹,然后将生成的轨迹投影到物理可行的集合上,以L2距离测量。搜索空间是低维的,有利于基于查询的黑盒子优化,同时仍允许细粒度的参与者运动控制。
在论文【2】Uber提出一个交通场景的神经自回归(AR)模型SceneGen,避免对规则和启发式方式的需要。其有助于解决建模真实交通场景的复杂性和多样性这一限制。特别是,考虑到自车状态和周围区域的高清地图,SceneGen将不同类别的参与者插入场景中,并合成其大小、朝向和速度。
SceneGen与传感器仿真相结合,可用于训练适用于现实世界解决方案的感知模型。
自回归交通场景生成方法如图所示:给定自车状态和周围环境的高清地图,SceneGen通过一次插入一个参与者来生成交通场景。
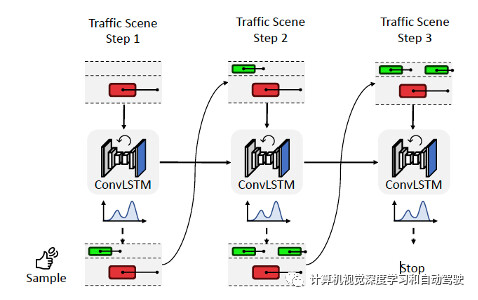
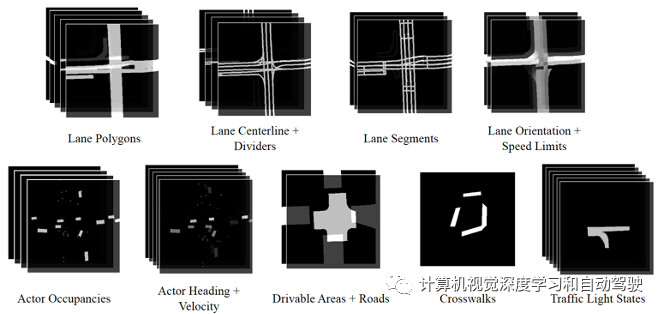
神经AR模型用递归神经网络(RNN)来捕获自回归生成过程中的长期相关性。该模型的基础是ConvLSTM架构,每次迭代中,模型输入的是一幅BEV多通道图像编码,包括自动驾驶车a0、、HD地图和迄今为止生成的其他交通参与者{a1,…,ai−1 }。
如图所示,多通道图像包括:车道多边形(直车道、专用右车道、专用左车道、专用公交车道和专用自行车道)、车道中心线和分隔线(允许跨线,禁止跨线,可能允许跨线);车道线(直行车道、专用右车道和专用左车道)、可行驶区域和道路多边形,以及人行横道多边形。此外将每个车道的红绿灯状态(绿色、黄色、红色、闪烁黄色、闪烁红色和未知)、速度限制和方向编码为填充的车道多边形。总的来说,这产生了24通道图像。
每个参与者由其类标签、BEV位置、定向边界和速度。为了捕获这些属性之间的依赖关系,对其联合分布进行因子分解。如图是参与者概率模型示意图:对每个参与者进行概率建模,作为其类别、位置、边框和速度分布的乘积。
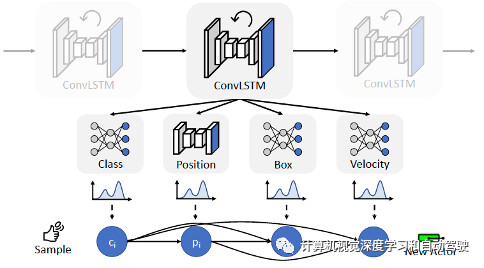
其意思就是参与者位置的分布取决于其类别;其边框取决于其类别和位置;其速度取决于类别、位置和边框。
在每个生成步骤中,从SceneGen的输出分布中采样M次,并保留最可能的样本。这有助于避免退化的交通场景,同时保持样本多样性。此外,拒绝那些边框与目前采样的参与者边框发生碰撞的车辆和自行车。
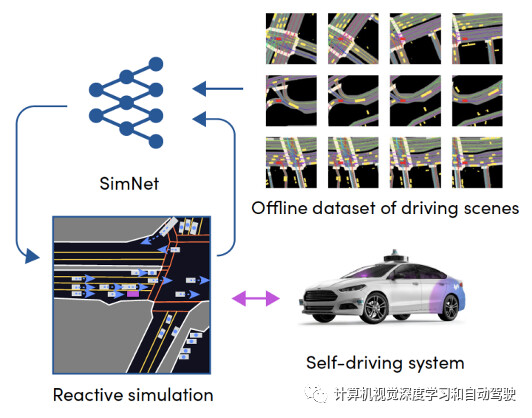
论文【3】是之前Lyft Level 5团队的工作,提出一个端到端可训练机器学习系统,真实地模拟驾驶体验。模拟问题构建为马尔可夫过程(MP),利用深度神经网络对状态分布和转移函数进行建模。直接从现有的原始数据中进行训练,即行为克隆(behavioural cloning),无需在运动模型中进行任何手工设计,所需要的只是一个具有历史交通事件(traffic episodes)的数据集。
它允许系统构建从未见过的场景,这些场景对自驾车的行为真实地做出反应。实际上直接用1000小时的驾驶数据训练系统,模拟的真实性和反应性是测量的两个关键属性。同时,该方法可评估通过专家驾驶数据训练的最新机器学习(ML)规划系统性能,这个规划系统容易出现因果混淆(causal confusion)问题,很难通过非反应性模拟(non-reactive simulation)方法进行测试。
如图是提出的可训练仿真系统框图:
如图是仿真采样的流程:
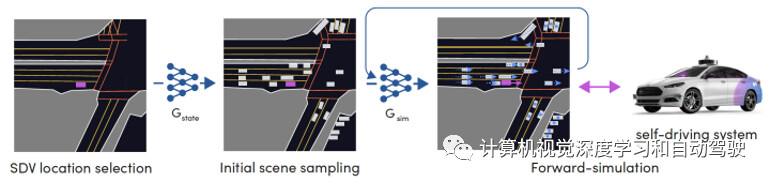
为了生成新的驾驶事件,首先选择并采样一个初始状态,捕获所有交通参与者的位置。 接下来,神经网络控制的交通参与者和自驾控制回路(control loop)控制的自动驾驶车行为对状态进行前向模拟。包括步骤如下:
-
1)从所有允许的地图位置选择初始自驾车的位置;
-
2)初始状态是从所有可行状态的分布得到,该状态捕获交通参与者的数目和初始姿势;
-
3)驾驶事件是通过参与者驾驶策略和自驾车控制系统的逐步前向模拟生成。
该模拟具备的特性包括:
-
完全模拟:执行上述所有步骤,从所有位置生成新的、从未体验过的驾驶场景。
-
旅程模拟:保持初始自驾车位置固定,合成许多不同的初始条件,得到从该位置开始的驾驶事件。
-
场景模拟:现有的历史感兴趣状态作为 初始状态,生成许多可能的未来结果。
-
行为模拟:通过硬编码特定路径来遵循,可替换转向角,迫使交通参与者采取特定的高级行为,但在执行中仍会留下某种反应性模拟结果。 对于模拟自驾车行为,这点儿很有用。
如图是仿真系统交互式状态展开的详细信息:
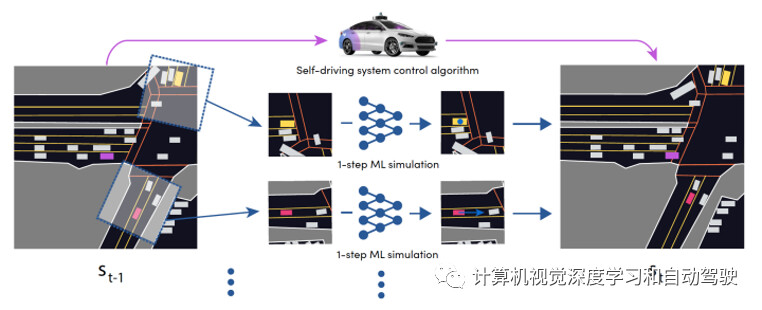
该状态的所有智体,独立运行一步预测来推进,自驾车由控制算法控制,新位置形成一个新状态,然后重复该过程。
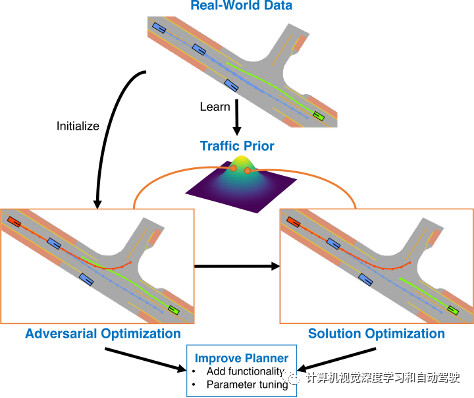
论文【4】介绍STRIVE(Stress-Test dRIVE),一种自动生成具有挑战性场景的方法,该场景会让给定规划器产生不希望的行为,如碰撞。
为了保持场景的合理性,关键思想是以基于图条件VAE的形式采用已学习的交通运动模型。场景生成是在该交通模型的潜空间进行优化,扰动初始真实场景产生与给定规划器发生碰撞的轨迹。随后的优化用于找到场景的“解决方案”,确保它有助于改进给定的规划器。
进一步的分析,基于碰撞类型,聚类这些场景。实验中攻击了两个规划器,并证明在这两种情况下,STRIVE成功地生成了真实具有挑战性的场景。此外,实现“闭环”,并用这些场景优化一个基于规则的规划器超参数。
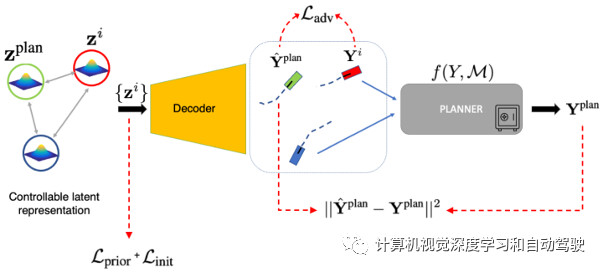
如图所示:STRIVE为给定的规划器生成具有挑战性的场景。对抗优化会扰乱所学习交通模型潜空间的真实场景,导致对抗(红色)与规划器(绿色)发生碰撞。后续的解决方案优化会找到规划器的轨迹避免碰撞,而验证场景有助于确定规划器的改进。
核心思想是,通过学习生成的交通运动模型可能性,衡量优化过程中场景的合理性,该模型鼓励场景具有挑战性,但又真实。因此,STRIVE不会提前选择特定的对抗,而是联合优化所有场景智体,从而产生多种多样的场景。此外,为了适应实践中广泛使用的不可微(或不可访问)规划器,所提出的优化在学习的运动模型中使用规划器的可微智体表征,从而允许用标准的基于梯度方法进行优化。
STRIVE不了解规划器的内部结构,也无法通过它计算梯度。不可取行为包括与其他车辆发生碰撞、不能驾驶地形、驾驶不舒适(如高加速)以及违反交通法规。虽然公式是一般性的,原则上可以处理其他目标(objective)函数优化,但重点是与规划器一起生成车辆碰撞相关的事故多发场景。
如图是学习的交通模型测试架构:为了对场景所有智体未来轨迹进行联合采样,首先对每个智体分别处理过去的运动和局部地图环境信息。然后,计算条件先验,输出每个节点的潜分布,该分布可通过auto regressive(AR)解码器进行采样馈入,预测未来的智体轨迹。
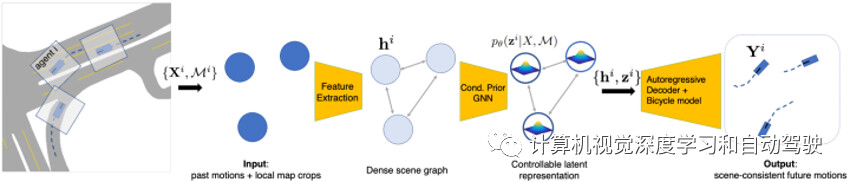
为了在测试时对未来运动进行采样,使用条件先验网络和解码器;两者都是图神经网络(GNN),在所有智体全连接的场景图运行。先验模型,包括一组智体的潜向量。输入场景图的每个节点都包含从该智体过去轨迹提取的上下文特征、局部光栅化地图、边界框大小和语义类等。消息传递(message passing)后,先验网络输出场景中每个智体的高斯分布参数,形成“分布”潜表征,捕捉未来可能的变化。
确定性解码器在场景图操作,每个节点都有采样的潜向量和过去轨迹上下文。解码是自回归(AR)方式执行的:在时间步t,一轮消息传递在预测每个智体加速之前解决交互;通过运动自行车模型,加速度立即获得下一个状态,该状态在继续展开之前更新轨迹上下文。解码器的可决定性和图结构鼓励场景一致的未来,即使在智体独立采样时也是如此。重要的是,对于潜向量优化,即使输入潜向量不太可能,解码器通过动态自行车模型确保合理的车辆动力学。
与场景交互模块一样,先验网络、后验(编码器)网络和解码器都是图神经网络(GNN),包括edge network, aggregation function, 和 update network。解码器会加入一个RNN(GRU)架构。
如图所示:在对抗性优化的每个步骤,规划器和非自车的潜表征都用学习的解码器进行解码,非自车轨迹提供给规划器在场景中展开。最后,计算各个损失。
论文【5】是英伟达的工作,采用一种数据驱动的方法,并提出了一种可以学习真实驾驶日志生成交通行为的方法。该方法将交通模拟问题解耦为高级意图推理和低级驾驶行为模拟,利用驾驶行为的双层结构,实现了高采样效率和行为多样性。
该方法还结合一个规划模型,获得稳定的长期行为效果。用两个大规模驾驶数据集场景对方法进行经验验证,该方法称为BITS(Bi-level Simulation for Traffic Simulation),并表明BITS在真实性、多样性和长时稳定性方面实现了平衡的交通模拟性能。
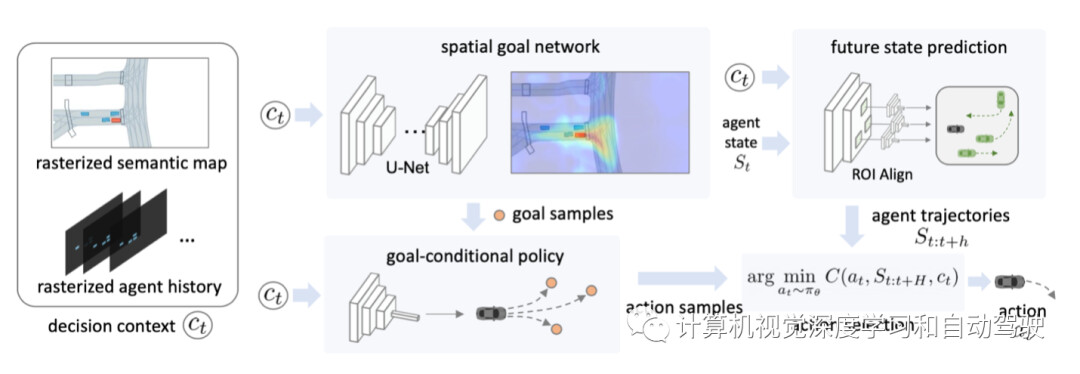
如图是BITS的框架:决策上下文ct是一个张量,包含语义图和光栅化智体历史,按通道连接在一起。给定ct作为输入,(1)空间目标网络产生短视野目标的2D空间分布,(2)目标条件(goal-conditioned)策略为每个采样目标(goal)生成一组动作,(3)轨迹预测模型预测相邻智体的未来运动,以及最后(4)基于预测的未来状态,该框架选择让基于规则的成本函数最小化的一组动作。
交通模拟可以描述为有监督的模仿学习问题。然而,城市驾驶的性质带来了重大的技术挑战。首先,由于模型无法访问演示者的潜在意图和其他与决策相关的线索,例如其他车辆的转向信号,因此是一个部分观察的决策过程。因此,动作监督本质上是模糊的,通常用概率分布建模。
虽然这种模糊性使训练复杂化,但有效地建模动作分布也可以生成不同的反事实(counterfactual)交通模拟。其次,由于每个智体的行为没有明确的协调,它们的联合行为生成了一个可能未来状态的组合空间。这种不确定性使得生成稳定的交通模拟非常具有挑战性。
交通模仿模型的目标,是通过学习真实世界的驾驶日志(作为演示),来产生各种各样的合理行为。轨迹预测中的大多数现有方法用深度潜变量模型(例如VAE)来捕获行为分布。然而,学习生成稳定的长视野行为需要大量的训练数据。相反,这里提出的方法将学习问题分解为(1)训练高层目标网络,捕获可能的短期目标空间分布,以及(2)训练确定性目标条件策略,学习如何达到预测目标。
空间目标网络(goal network)利用驾驶运动的2D BEV结构,并用2D网格高效地表示空间目标分布。这种分解将多模态轨迹建模的负担,转移到高级目标预测器,使低级目标条件策略能够重用达成目标的技能,提高样本效率。
这样一个双层模拟学习方法,可以从有限的数据中生成合理的交通模仿。该策略可以从多模态空间目标预测器中采样,综合各种行为。然而,该策略的执行仍然受到训练数据规模和覆盖范围的限制。
驾驶日志偏向于正常行为,几乎不包含碰撞或越野驾驶等安全-紧要情况。生成多样行为的目标进一步放大了这一挑战,因为鼓励智体进入地图上未见过的区域并创建新的交互。因此,为了实现稳定的长时间模拟,即使在缺乏训练数据指导的状态下,智体也必须生成合理的行为。
为此,建议使用预测和规划模块来增强策略,以稳定长期轨迹展开。
该方法类似于典型的模块化AV堆栈中的运动规划流水线,重要的区别在于,用学习的策略生成类人运动轨迹候选。关键思想是,策略πθ可以直接跟踪分布内状态下的数据似然,其中大多数行为样本都遵循规则,在最可能的动作可能导致不良后果的状态下,接受纠正指导。此外,采样模块允许在无需再训练的情况下对模拟器进行灵活调整(例如,多样性水平、多个目标的强调)。
参考文献
【1】“Advsim: Generating safety-critical scenarios for self-driving vehicles“, CVPR 2021
【2】“SceneGen: Learning to Generate Realistic Traffic Scenes”,arXiv 2101.06541,2021
【3】“SimNet: Learning Reactive Self-driving Simulations from Real-world Observations”,arXiv 2105.12332,2021
【4】“Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior”,CVPR,2022
【5】“BITS: Bi-level Imitation for Traffic Simulation“,arXiv 2208.12403,2022
- 下一篇:模态基础理论知识
- 上一篇:广州检验中心荣获CB实验室(CBTL)资质






最新资讯
-
推荐性国家标准《乘/商用车电子机械制动卡
2025-04-30 11:13
-
载荷分解
2025-04-30 10:46
-
布雷博在上海开设亚洲首个灵感实验室
2025-04-30 10:25
-
组分性能对锂离子电池卷芯挤压力学响应的影
2025-04-30 09:00
-
美国发布自动驾驶新框架,放宽报告要求+扩
2025-04-30 08:59
