




 广告
广告





















































自动驾驶高清地图生成技术综述

摘要
在过去几年里,自动驾驶一直是最受欢迎和最具挑战性的话题之一。在实现完全自主驾驶的道路上,研究人员利用各种传感器,如激光雷达、相机、惯性测量单元(IMU)和GPS,并开发了用于自动驾驶应用的智能算法,如目标检测、目标分割、障碍物回避和路径规划。近年来,高精地图备受关注。由于高精地图在定位上的高精度和信息化程度,它立即成为自动驾驶的关键组成部分之一。从百度Apollo、英伟达(NVIDIA)和TomTom等大型组织到个人研究人员,研究人员为自动驾驶的不同场景和目的创建了高精地图。有必要回顾一下目前最先进的高精地图生成方法。本文综述了近年来利用2D和3D地图生成的高精地图生成技术。本文介绍了高精地图的概念及其在自动驾驶中的应用,并对高精地图生成技术进行了详细的概述。我们还将讨论当前高精地图生成技术的局限性,以推动未来的研究。
目录
-
1 介绍
-
2 高精地图的数据采集
-
3 点云地图生成
3.1.1 基于分割的点云配准3.1.2 仅基于激光雷达的点云建图3.1.3 里程计融合点云配准3.1.4 GPS融合点云配准3.1.5 INS融合点云配准3.1.6 视觉传感器融合点云配准3.1 建图技术
-
4 高精地图的特征提取方法
4.2.1 从二维图像提取道路标志4.1.1 二维航空图像道路提取4.1.2 三维点云的道路提取4.1.3 基于传感器融合的道路/道路边界提取4.1.4 其它方法4.1 道路网提取4.2 道路标志提取4.2.2 三维点云的道路标志提取4.3 杆状物体提取5 高精地图框架5.1 Lanelet25.2 OpenDRIVE5.3 Apollo地图6 局限性和开放性问题7 参考文献
1 介绍
“高精地图”概念最早是在2010年梅赛德斯-奔驰的研究中引入的,后来在2013年为Bertha Drive Project[1]做出了贡献。在Bertha Drive Project中,一辆梅赛德斯-奔驰S500在完全自主模式下完成了Bertha Benz纪念路线,使用了高度精确和信息详实的3D路线图,后来被参与测绘的HERE[2]公司命名为“High Definition (HD) Live map”。高精地图包含自动驾驶所需的道路/环境的所有关键静态属性(例如:道路、建筑物、交通灯和道路标记),包括由于遮挡而无法被传感器适当检测到的物体。近年来,自动驾驶高精地图以其高精度和丰富的几何和语义信息而闻名。它与车辆定位功能紧密相连,并不断与激光雷达、雷达、相机等不同传感器相互作用,构建自主系统的感知模块。这种交互最终支持了自动驾驶车辆[3]的任务和运动规划,如图1所示。
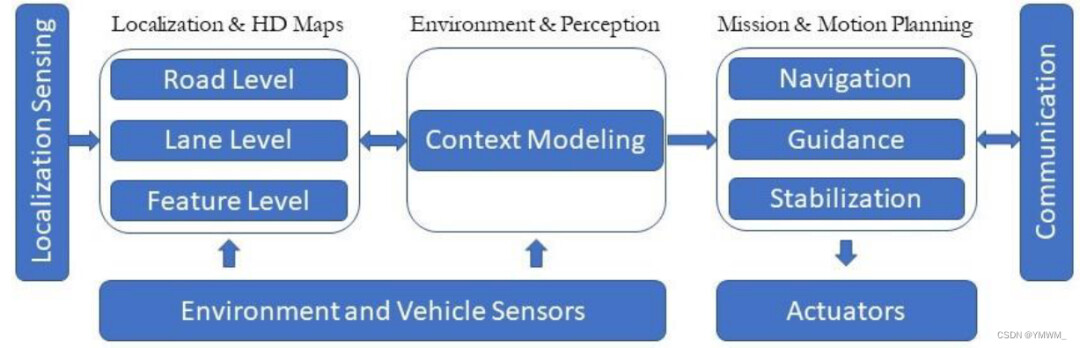
图1 自动驾驶架构。高精地图包含关于道路/环境的静态信息和属性,包括由于遮挡而无法被感知模块检测到的物体。并根据道路特征对车辆进行自我定位。环境与感知模块提供车辆周围的实时环境信息。高精地图和感知模块共同工作,最终支持任务和运动规划模块,包括导航、运动引导和稳定控制。在自动驾驶市场上,没有唯一的标准的高精地图结构。然而,目前市场上的高精地图有一些常用的结构,如导航数据标准(NDS)[4]、动态地图平台(DMP)[5]、HERE高清实时地图[2]和TomTom[6]。大多数结构共享类似的三层数据结构。表1显示了TomTom[7]、HERE[8]和Lanelet (Bertha Drive)[1]定义的三层结构高精地图。本文将采用HERE的术语来指代这三层,如图2所示。表1 三层结构高精地图的示例。
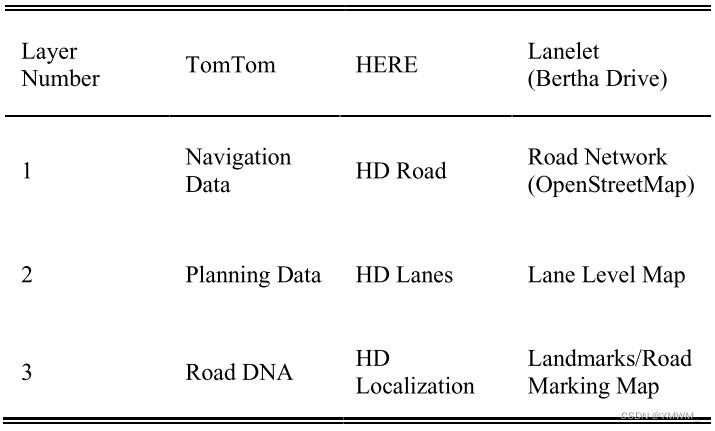
图2 由HERE定义的高精地图结构:高精道路由拓扑结构、行驶方向、交叉路口、坡度、坡道、规则、边界和隧道组成。高精车道由车道级别特征组成,如边界、类型、线条和宽度。HD定位包括道路设施,如交通灯和交通标志等。 第1层道路模型(Road Model)定义了道路特征,如拓扑、行进方向、高程、坡度/坡道、规则、路缘/边界和交叉路口。它用于导航。第2层车道模型(Lane Model)定义了车道层次特征,如道路类型、线路、道路宽度、停车区域和速度限制。该层作为自动驾驶的感知模块,可以根据实时交通或环境进行决策。顾名思义,最后一层,定位模型,在高精地图中定位自动车辆。这一层包含路边的设施,如建筑物、交通信号、标志和路面标记。这些功能有助于自动车辆快速定位,特别是在其特征丰富的城市地区。以上组织制作的高精地图都是精确的,并且不断更新。然而,它们只是用于商业目的,而不是开源的。个人研究人员很难使用上述结构来构建高精地图。因此,本文将对未商业化的高精地图生成方法进行综述,这些方法可能有助于研究人员创建个性化的高精地图,并开发新的高精地图生成方法。本文的结构安排如下:第2节回顾了近年来高精地图数据采集的方法。第3节回顾了近年来高精地图特征提取的方法,包括道路/车道网提取、道路标记提取和pole-like物体提取。第4节介绍了HD地图的常用框架。第5节将讨论目前高精地图生成方法的局限性,并对高精地图提出一些开放性的挑战。最后,第6节给出结论。
2 高精地图的数据采集
数据来源/收集是生成高精地图的第一步。数据收集使用移动地图系统(MMS)完成。MMS是一个移动车辆,它装有地图传感器,包括GNSS(全球导航卫星系统)、IMU、激光雷达(光检测和测距),相机和雷达,以收集地理空间数据。商业化的高精地图提供商都采用众包的方式来收集制作和维护高精地图的数据。Level5与Lyft合作,让20辆自动驾驶汽车沿着加州帕洛阿尔托的固定路线行驶,收集包含17万个场景的数据集,包含15242个标记元素的高精语义地图,以及[9]区域的高精鸟瞰图。TomTom通过多种途径收集数据,包括调查车辆、GPS轨迹、社区投入、政府来源和车辆传感器数据[10]。HERE利用全球400多辆测绘车辆、政府数据、卫星图像和社区投入,不断获得更新的道路信息。通过众包的方式收集数据,可以在短时间内收集到大量最新的道路/交通数据。众包数据还包括不同的环境,包括城市、城镇和农村地区。然而,由于多个移动地图系统的成本较高,且数据收集耗时较长,该方法并不是单个研究人员的最优解决方案。个别研究人员也利用MMS来收集数据。他们不是为世界各地不同类型的环境收集数据,而是专注于一个小得多的区域,如城市、大学校园或住宅区。收集的数据类型也被更详细地指定用于研究目的。此外,还有大量的开源数据,如卫星图像、KITTI数据集[12]、Level5 Lyft数据集[13]和nuScenes数据集[14],供研究人员进行测试和生成高精地图。这些数据集包含二维和三维真实世界的交通数据,包括图像、三维点云和IMU/GPS数据,这些数据已经被组织和添加标签。数据收集方法及比较汇总于表2。表2 数据采集方法比较
下一步是利用采集到的道路环境数据,从原始数据中提取有用的特征。
3 点云地图生成
一旦采集到初始传感器数据,通常进行融合和排序,生成初始地图,主要用于精确定位。建图主要是使用3D激光传感器生成的;然而,它可以与其他传感器融合,如IMU [15]、[16]和[17], GPS[18],里程计[19]和视觉里程计[20],以便得到在高精地图中更准确的状态估计。INS和GPS传感器提供方位和位置信息,以厘米精度更新地图位置。这些点云地图精度很高,可以辅助地面车辆在三维空间中进行厘米级的精确机动和定位。然后,在从建图获得点云配准后,从PCL地图创建矢量地图。点云配准称为多步骤过程(如图3所示),将几个重叠的点云对准,生成详细而精确的地图。矢量地图包含与车道、人行道、十字路口、道路、交通标志和交通灯相关的信息。这一关键特征后来被用于检测交通标志和交通灯、路线规划、全局规划和局部路径规划。毫无疑问,地图生成是高精地图生成的重要组成部分。它可以被定义为高精地图的基础几何地图层。
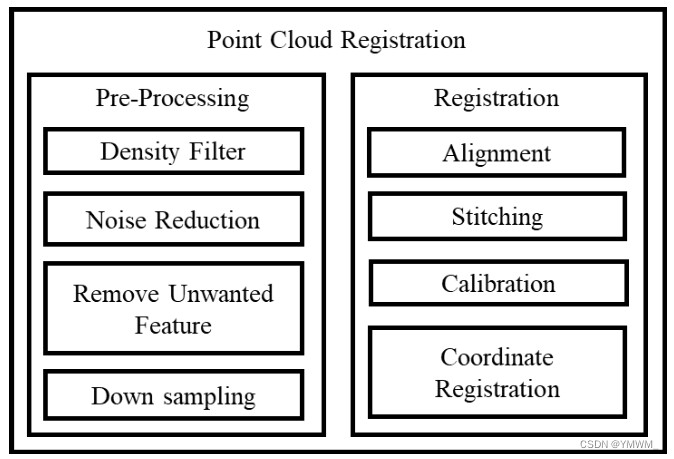
图3 常见的点云配准多步骤过程。
3.1 建图技术
地图生成技术可以分为在线地图和离线地图。离线地图数据全部收集在一个中心位置。这些数据使用的是卫星信息或从激光雷达和相机存储的数据。在收集数据之后,将离线构建地图。另一方面,在在线地图中使用轻量级模块实现机载地图生成。除了地图的形成类型,测绘技术还可以根据传感器的使用和传感器的融合方式进行分类。以下的测绘技术需要基于激光的传感器,因为它们在远距离显示出有希望的准确性。目前所有有前景的测绘技术都采用激光作为主要传感器来测绘和完成高精地图。另一方面,也有一些方法只使用视觉传感器来构建点云地图。本文提出了一种用于三维模型生成的点云配准技术。但是,下面的方法是根据支持高精地图的建图来分类的。
3.1.1 基于分割的点云配准
SegMap[21]是一种基于提取点云分割特征的建图解决方案。该方法通过重构局部特征进行判别,生成点云图。轨迹测试结果显示,与LOAM框架[22]相结合时,LOAM (Laser Odometry and Mapping)的性能得到了增强。构建的地图显示6%的召回准确率和50%的里程计漂移下降。因此,由于数据驱动的段描述符提供了更少的粗糙数据,因此在定位方面有了改进。为SegMap描述符训练一个简单的完全连接的网络,然后根据语义提取重建地图。同样,采用两阶段算法来改善建图误差。该算法采用分段匹配算法与单激光雷达算法相结合的方法。同时,为了减少生成的地图与在线建图[23]之间的错误匹配,引入了基于RANSAC的几何增强算法。
3.1.2 仅基于激光雷达的点云建图
通过改进现有的LOAM[24]点选择方法和迭代位姿优化方法,在小视场和不规则采样的情况下,激光雷达已经实现了更高的精度和效率。整个建图架构如图4所示。提出了一种快速回环技术来解决激光雷达里程计和建图中的长期偏移问题[25]。另一方面,采用分散的小视场多激光雷达平台,利用扩展卡尔曼滤波[26]实现鲁棒建图。此外,还有一种技术,在机器人的不同高度安装激光雷达,生成点云[27]。
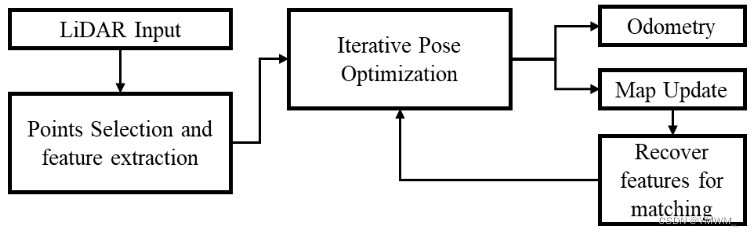
图4 常见建图流程。
3.1.3 里程计融合点云配准
当GPS无法使用或无法连接时,融合里程计就派上了用场,尤其是在室内。迭代最近点(ICP)方法使用6自由度信息来匹配给定点云中最近的几何图形。这样做的主要缺点是,它会停留在局部最小值,需要一个完美的起点,从而导致与真实环境的误差和不对齐增加[28]。NDTMap[29]生成是由点云转化而来的连续可微概率密度[30]、[31]。NDTMap的概率密度包含一组正态分布。它是一个体素网格,其中每个点根据其坐标分配给一个体素。将点云划分为体素云,合并后的体素在建图中进行滤波,减少噪声,减少计算量。因此,以下步骤概述了NDT建图,
-
从点云输入数据构建体素网格
-
估计初始猜测
-
优化初始猜测
-
根据NDT估计和初始估计之间的平移变化来估计状态。根据位置推导计算速度和加速度。
如果在初始估计中不使用里程计,状态估计是由每次NDT更新导出的。最初的猜测来自于基于运动模型的速度和加速度更新。引入里程计时,位置更新基于里程计数据;特别是速度模型和方向更新。
3.1.4 GPS融合点云配准
在基于图的建图中,将GNSS中的绝对位置作为约束,将点云数据与坐标系统一起来[18]。因此,点云中的体素被标记为绝对的三维坐标系信息。基于激光雷达的里程计也被用于LIO-SAM精确的位姿估计和地图构建[19]。
3.1.5 INS融合点云配准
在不使用任何传感器的情况下,车辆的状态和偏航是来自每次NDT更新计算。基于运动模型的初始猜测是由速度和加速度导出的。IMU提供二次模型的平移更新和方向更新。Autoware[32]的NDT制图技术还提供IMU和里程计融合制图。类似地,DLIO方法[33]通过使用松耦合融合和位姿图优化实现精确建图和高速率状态估计。集成了IMU,通过输入IMU偏差来修正后续的线性加速度和角速度值,从而提高可靠性。FAST-LIO[16]和FAST-LIO2[17]是激光雷达惯性里程计测量系统,用于快速和准确的测绘。该系统采用紧耦合迭代EKF(扩展卡尔曼滤波器)将IMU与激光雷达特征点融合。FAST-LIO2使用了一种新的技术,增量kd-Tree,提供了支持地图的增量更新和动态再平衡。
3.1.6 视觉传感器融合点云配准
R2-LIVE[34]和R3-LIVE[35]算法利用Laser、INS和视觉传感器融合实现精确建图和状态估计。R2-LIVE使用基于卡尔曼滤波的迭代里程计法和因子图优化来确认准确的状态估计。R3-LIVE是两个独立模块的组合:LiDAR-IMU里程计和视惯里程计。全局地图实现了激光雷达和IMU的精确几何测量。融合了IMU的视觉传感器将地图纹理投影到全局地图中。类似的两个子模块LIO和VIO也用于FAST-LIVO[20]中的鲁棒和精确建图。类似地,LVI-SAM使用两个类似于R3-LIVE的子模块来设计。根据LVI-SAM[36],视觉惯性系统利用激光雷达惯性计算来辅助初始化。视觉传感器提供深度信息,提高视觉惯性系统的精度。图5显示了使用现有建图算法生成的地图。有一些技术可以融合多个传感器来创建一个完整的地图。视觉里程计(IMU和相机)、GPS和LiDAR数据被组合到一个超级节点中,得到一个优化的地图[36]。图6是不同方法在线测绘得到的轨迹路径。图6(a)是测绘传感器数据的完整路径(ontario Tech Campus)。图6(a)是记录数据的完整里程计数据。图6(b)和图6©为完整轨迹放大图。该真实路径由RTK-GPS与IMU数据融合得到。这些分数表明R3-LIVE遵循真实路径,即RTK-GPS里程计。

图5 建图可视化。(a) LeGO-LOAM, (b) NDT建图(Autoware),(c) LIO-SAM,(d) FAST-LIO,(e) LVI-SAM,(f) R3-LIVE。
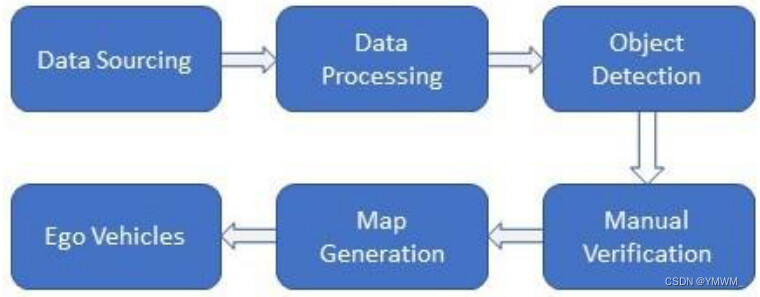
图6 不同建图算法的里程计路径图另一方面,LIO-SAM[19]从原来的航向漂移到中间。对于NDT建图,采用了通用的PCL转换和OpenMP方法。用于作图的里程值为建图后的里程值(例如,在执行建图匹配的附加步骤之后绘制LeGO-LOAM[15]里程计)。
4 高精地图的特征提取方法
为了让车辆定位并遵循运动和任务计划,道路/车道提取、道路标记提取和类极物体提取等特征提取是必要的。传统的特征提取是人工完成的,成本高、耗时长、精度低。近年来,机器学习辅助高精地图生成技术得到了发展,并被广泛应用于提高特征提取精度和减少人工工作量。
机器学习辅助高精地图生成采用人机在环(human-in- loop, HITL)技术,该技术涉及人机交互[37]-[39]。人类给数据加标签,带标签数据使用监督学习进行训练。精度/置信度较高的结果会被保存到高精地图中,精度/置信度较低的结果会被人工检查并送回算法进行再训练。机器学习已被广泛应用于提取道路/车道网络、道路标志和交通灯。
4.1 道路网提取
4.1.1 二维航空图像道路提取
道路地图/网络对于自动驾驶系统定位车辆和规划路线至关重要。从航拍图像中提取路线图也很有吸引力,因为航拍照片覆盖了大量地图,通常是城市规模的地图,并通过卫星不断更新。然而,从航空图像手动创建道路地图是劳动密集型和耗时的。由于人为错误,它也不能保证准确的路线图。因此,需要能够自动化路线图提取过程的方法。二维航空图像道路网自动提取可分为三种不同的方法:基于分割的方法、迭代图增长法和图生成法。基于分割的方法。基于分割的方法从航空图像中预测分割概率图,并通过后处理对分割预测进行细化,提取图像。Mattyus等人提出了一种直接估计道路拓扑并从航拍图像中提取道路网络的方法[40]。在他们名为DeepRoadMapper的方法中,他们首先使用ResNet[41]的变体来将航空图像分割成兴趣类别。然后,他们使用softmax激活函数以0.5概率的阈值过滤道路类,并使用闪光(shinning)提取道路中心线[42]。为了缓解道路分割的断续问题,他们将断续道路的端点与特定范围内的其它道路的端点连接起来。将连接点视为潜在道路,这里采用A*算法[43],为间断道路选取最短的连接点,如图7所示。
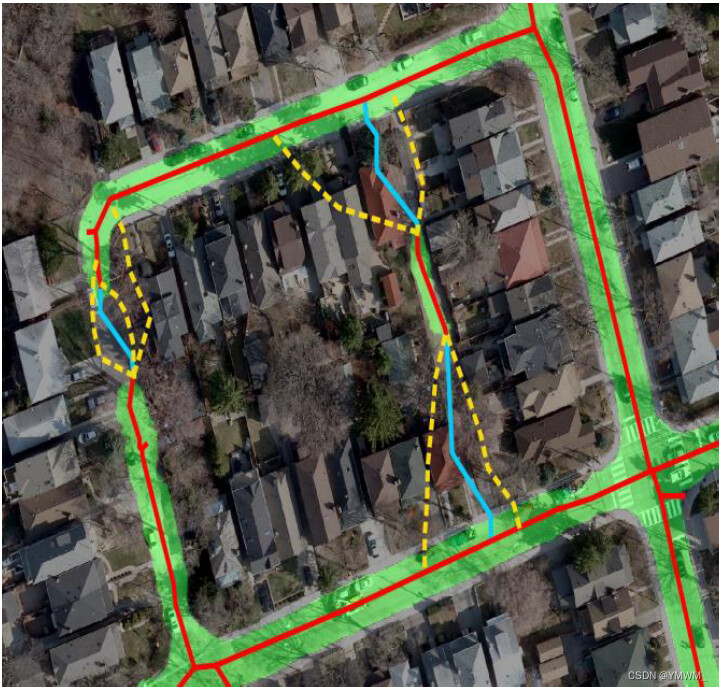
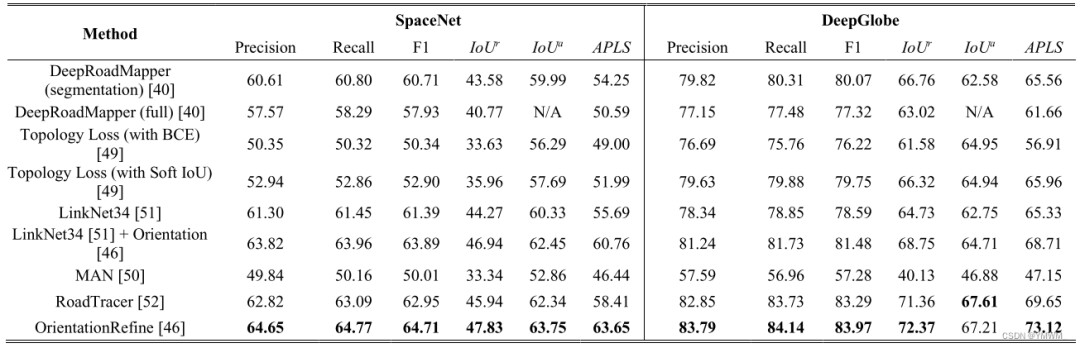
图7 道路分割用绿色突出显示,红线为提取的道路中心线,黄色虚线表示道路的潜在连接,蓝色线条为A*算法选择的潜在线[60]。通过评估他们在多伦多城市数据集[44]上的方法,并将结果与[45]、OpenStreetMap和地面真值图进行比较,他们显示了比出版那年的最先进技术的显著改进。除了改进之外,值得注意的是,当道路或周围环境的复杂性增加(如遮挡)时,启发式算法(A*算法)不是最优解。为了提高基于分割的路网提取性能,解决[40]中路网不连通性问题,[46]提出了方向学习和连通性优化方法。该方法通过预测路网的方向和分割来解决路网不连通问题,并使用 n n n-堆叠的多分支CNN对分割结果进行修正。该方法在SpaceNet[47]和DeepGlobe[48]数据集上进行了进一步评估,并与DeepRoadMapper和其它先进的方法[49]-[52]进行了比较,以显示其先进的结果。评价结果如表3所示。突出显示的粗体值代表最佳结果。根据表3的比较,OrientationiRefine优化设计的结果是最先进的。表3 SpaceNet和DeepGlobe数据集上最先进的道路提取方法的比较。IOU^r和IoU^a分别表示松弛和准确的道路IoU。APLS为平均路径长度相似度[46]。
Ghandorh等人在基于分割的方法中加入边缘检测算法,从卫星图像中对分割后的路网进行了细化[53]。该方法采用了编码器-译码器结构,加上扩展的卷积层[54]和注意机制[55]-[58],使网络具有大规模目标分割能力,并更关注重要特征。然后将分割后的路网输入到边缘检测算法中进行进一步细化。迭代图生长法。迭代图增长方法首先从二维航拍图像中选择道路网络的几个顶点,生成道路网络。然后,一个顶点一个顶点地生成道路,直到创建出整个道路网络。Bastani等人注意到了DeepRoadMapper的相同限制。当道路分割存在不确定性时,启发式算法的性能较差,这种不确定性可能由遮挡和复杂的拓扑结构(如平行道路)引起[52]。随着由于树木、建筑物和阴影导致的遮挡面积增加,基于CNN的道路分割表现较差。以前的方法[59]、[60]没有处理此类问题的可靠解决方案。针对上述问题,Bastani等人提出了一种新的方法RoadTracer,从航拍图像中自动提取道路网络[52]。RoadTracer采用迭代图构造程序,旨在解决遮挡导致的性能不佳问题。RoadTracer有一个由基于CNN的决策函数引导的搜索算法。搜索算法从路网中已知的单个顶点开始,并随着搜索算法的探索不断向路网中添加顶点和边。基于CNN的决策函数决定是否将一个顶点或一条边添加到路网中。通过这种方法,通过迭代图生长方法逐点生成道路图。迭代图生长法如图8所示。在15个城市地图上评估了RoadTracer方法,并将结果与DeepRoadMapper和Bastani等人实现的另一种分割方法进行了比较。RoadTracer可以生成比先进的DeepRoadMapper更好的地图网络结果。
图8 基于迭代图生长法的航空图像道路网络提取。绿线表示被提取出的道路[154]。迭代图构建过程的一个缺点是生成大规模路网的效率。由于这一过程是逐点生成道路图,因此随着道路网络规模的增长,这一过程将变得非常耗时。据作者所知,RoadTracer是第一个使用迭代图增长方法生成道路网络的工作。因此,对该方法的进一步研究可以提高大规模路网生成效率。DeepRoadMapper[40]、RoadTracer[52]、OrientationRefine[46]等最新方法在SpaceNet[47]和DeepGlobe[48]数据集上的评估和比较结果如表3所示。图生成方法。图生成方法直接从航空图像预测路网图。该方法将输入的航空图像编码为向量场,利用神经网络进行预测。然后通过解码算法将预测解码为图。该方法已用于预测路网图,包括线段[61]、线形物体[62]和多边形建筑[63]。Xu等人在图生成方法的基础上,将图生成方法与transformer相结合[64],提出了一种名为csBoundary的高精地图标注道路边界自动提取系统[65]。csBoundary系统首先以4通道航拍图像作为输入。它通过特征金字塔网络(Feature Pyramid Network, FPN)[66]对图像进行处理,预测道路边界的关键点图和分割图。从关键点地图中,提取一组长度为 M M M的顶点坐标。将关键点图、分割图和输入的航拍图像相结合,形成一个6通道特征张量。对于每个提取的顶点,大小为 L × L L × L L×L的感兴趣区域(ROI)被裁剪并放置在关键点地图的中心。Xu等人也提出了邻接网络(AfANet)的注意力机制[65]。AfA编码器利用感兴趣区域计算局部和全局特征向量,AfA解码器对特征向量进行处理,预测提取顶点的邻接矩阵,生成道路边界图。所有得到的图将被用于缝合最终的城市尺度道路边界图。csBoundary的结构如图9所示。
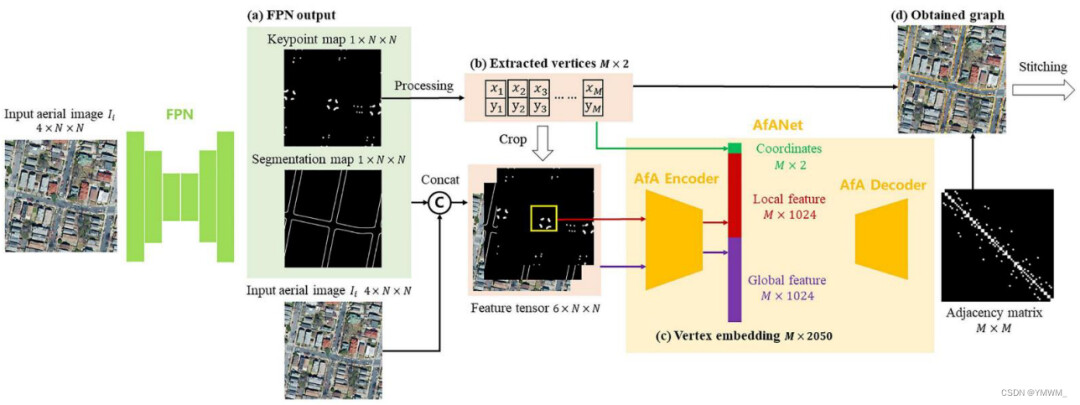
图9 csBoundary系统架构[65]。基于分割的方法可以利用CNN在很短的时间内从航空图像中自动提取大规模路网。然而,该方法的性能在很大程度上取决于航拍图像的质量。如果道路上有遮挡,可能是阴影或较大的建筑造成的,分割性能会下降。即使有DeepRoadMapper辅助的A*路径规划算法,该方法仍然不能保证高性能的路网提取,因为最短路径并不总是现实生活中的实际路径。另一方面,迭代图增长方法利用基于CNN的决策函数的搜索算法,提高了提取有遮挡的道路的性能。而迭代图生长法由于逐点构建路网的顶点,提取整个路网的时间较长。该方法的提取时间也会随着道路地图大小的增加而增加。由于该方法采用迭代的方式进行路网提取,同时由于累积误差而存在漂移问题,使得该方法对大规模路网提取具有挑战性。用于道路网络提取的图生成方法仍然局限于物体的特定形状,严重依赖解码算法,限制了其泛化能力。需要开发更多的解码算法来扩展图生成方法的提取类别。在Topo-Boundary [67]数据集上评估的三种最先进的方法的性能比较如表4所示,包括OrientationRefine [46] (基于分割的方法)、Enhanced-iCurb [67] (迭代图增长)、Sat2Graph [68] (图生成)和csBoundary [69] (图生成)。
4.1.2 三维点云的道路提取
基于三维点云的道路或车道提取已广泛应用于高精地图的生成过程中。激光雷达点云具有很高的精度,通常达到毫米级精度,并包含被扫描物体的几何信息。三维点云的道路提取是利用分割完成的。Ibrahim等人指出,二维道路网络不能提供任何物体相对位置的深度线索,而且二维道路网络中较小的基础设施变化也不是最新的[70]。Ibrahim等人并没有在航拍图像上建立道路网络,而是展示了澳大利亚珀斯中央商务区(CBD)的高精激光雷达地图[70]。在他们的工作中,将Ouster激光雷达放在SUV的顶部,然后驾驶SUV穿过CBD,收集3D点云数据。点云数据采用回环采集方式[71],避免了配准误差累积带来的漂移问题,如图10所示。回环检测算法用于提取形成回环的点云,其中只提取属于特定回环的帧。然后对提取出来的环路点云进行预处理,包括下采样[72]、分割地面点[73]、去除自我车辆和附近无关点。利用三维正态分布变换(NDT)对预处理后的环路点云进行配准和合并[74]。对合并后的原始点云进行空间子采样、噪声去除、重复点去除和平滑等处理后,得到最终的提取道路。
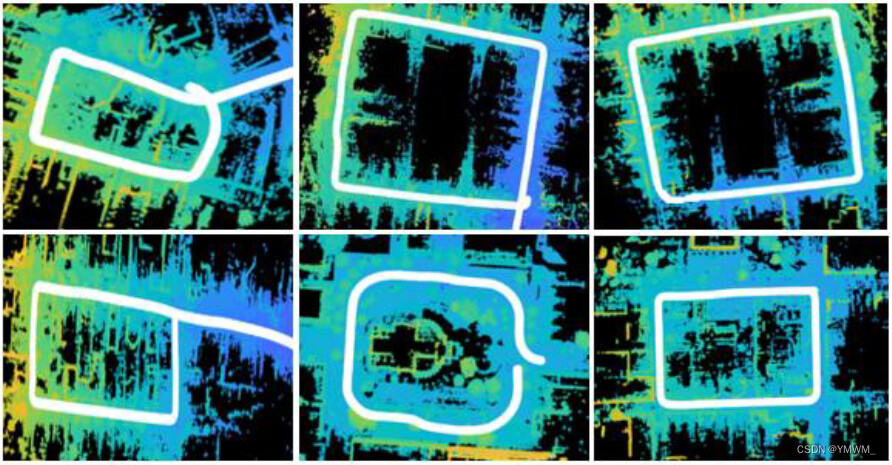
图10 以回环方式采集三维点云。道路点云与其它物体的点云在背景中以回环形式突出显示[70]。Ye等人提出了另一种生成3D地图的方法,用于为特定场景创建高精地图[75]。他们的提案将一个特定的场景定义为自动驾驶应用程序的安全和操作环境。本文以大学校园的一部分为具体场景,构建三维高精地图。Ye等人将他们的HD地图架构划分为四个不同的层,包括定位层、道路矢量和语义层、动态物体层和实时交通层,见表5。定位层存储用于定位的点云和图像。道路向量和语义层存储出行的道路方向、道路类型和道路上的物体。在这一层中,使用的是OpenDRIVE文件格式。动态物体层,顾名思义,存储关于行人、障碍物和车辆等物体的高度动态感知信息。这一层以更高的频率更新,以提供来自周围环境的反馈。实时交通层存储车辆速度、位置、交通信号灯状态等实时交通数据。以实际场景的数字3D场景为参考,使用NDT算法创建3D高精地图。地图结果如图11所示。关于它们的建图过程的更多细节可以在[75]中找到。表5 具体场景高精地图架构

图11 校园建筑的数字3D场景(左)及其高精地图(右)[75]。
4.1.3 基于传感器融合的道路/道路边界提取
二维航拍图像和三维点云的道路提取都存在一定的局限性。由于光照条件差、路边基础设施遮挡以及各种地形因素,从卫星和航空图像提取的道路网络通常不准确和不完整。三维点云的特征提取也面临遮挡和点密度变化的问题,导致道路提取不准确和不完整。在提取道路或道路边界时,使用单一数据源的局限性很明显。因此,研究人员一直在使用多源数据来提取和补全道路或道路边界。Gu等人[76]利用激光雷达的图像和相机透视地图,构建映射层,将激光雷达的图像视图特征转换为相机的透视图像视图。该方法提高了在相机视角下的道路提取性能。Gu等人[77]也提出了条件随机森林(conditional random forest, CRF)框架,融合激光雷达点云和相机图像,提取道路网络的范围和颜色信息。在[78]中,基于残差融合策略,设计了一种全卷积网络(fully convolutional network, FCN),将从激光雷达和相机数据学习到的特征图进行融合,用于道路检测。Li等人[79]采用了一种不同的方法,通过融合GPS轨迹和遥感图像来构建道路地图。该方法利用基于迁移学习的神经网络从图像中提取道路特征,利用U-Net提取道路中心线。此外,[80]设计了一个紧耦合的感知规划框架,利用GPS-相机-激光雷达传感器融合来检测道路边界。Ma等人也提出了一种新的深度学习框架BoundaryNet,利用激光扫描点云和卫星图像,提取道路边界,填补现有道路边界数据中遮挡造成的空白[81]。该方法采用基于路沿的提取方法提取道路边界,并采用改进的U-net[82]模型从道路边界点云中去除噪声点云。然后,将基于CNN的道路边界补全模型应用于提取到的道路边界,以填补一些空白。受生成对抗网络(Generative Adversarial Networks, GAN)方法的启发[83],设计了一种基于条件的深度卷积生成对抗网络(c-DCGAN),利用卫星图像中提取的道路中心线来提取更准确完整的道路边界。所提方法的体系结构如图12所示。
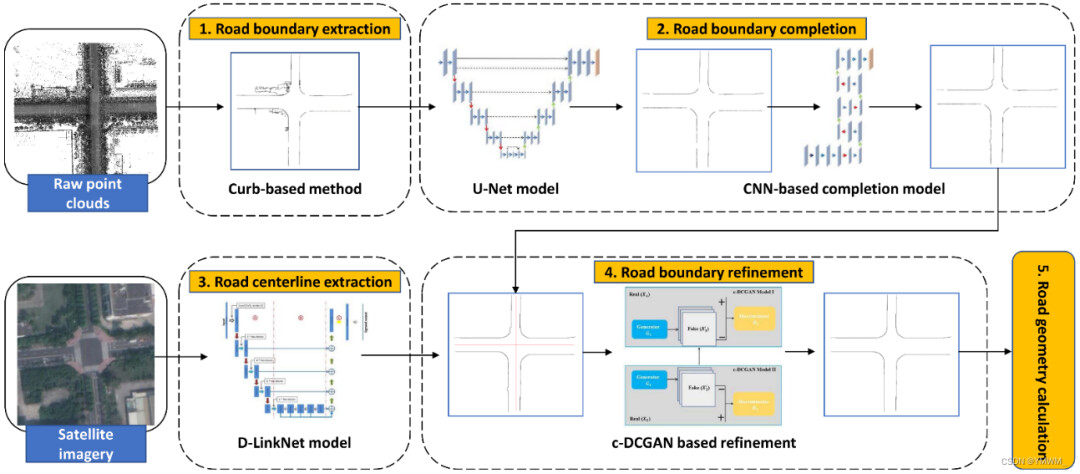
图12 BoundaryNet的架构。利用基于路沿的方法从原始点云中提取道路边界。应用U型编码器-解码器模型和基于CNN的补全模型的道路边界补全。利用D-linkNet模型从卫星图像中提取道路中心线[156]。基于c-DCGAN模型的道路边界优化。基于提取到的道路边界计算道路几何。
4.1.4 其它方法
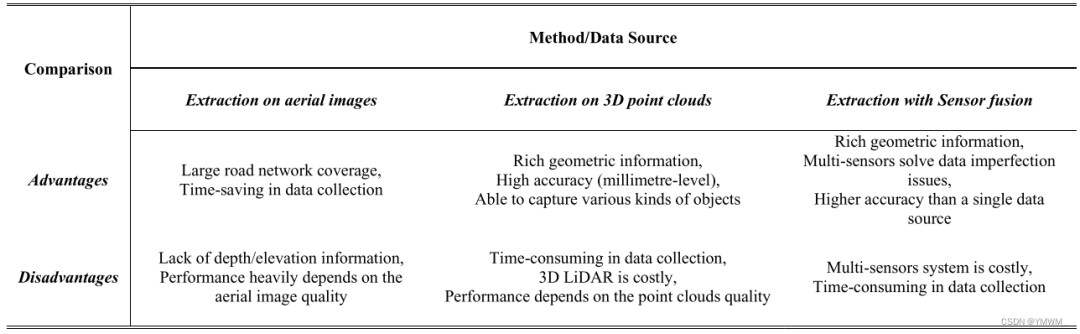
也有不同的方法来提取道路网络。Schreiber等人和Jang等人[84]、[85]采用了不同的方法,从相机图像而不是航空图像中提取道路。前者对相机图像进行三维重建,后者设计了全卷积网络(FCN)对道路进行检测和分类。这两种方法都可以应用于小规模的高精地图,但由于数据收集的工作量和时间巨大,不能用于大型或城市级别的高精地图。[86]列出了更多基于机器学习的道路/车道提取方法,Aldibaja等人[87]也提出了一种3D点云积累方法,该方法也值得学习,但在本文中不做详细讨论。道路提取可以通过不同的数据源进行,包括相机图像、卫星和航空图像、激光雷达点云和GPS轨迹。卫星和航空图像可以覆盖大规模地图,使得城市级别路网的道路提取效率很高。然而,从卫星和航空图像提取的道路网络不包含深度和高度信息。从航空图像中提取道路的性能也在很大程度上取决于图像的质量。光照条件差、路边基础设施遮挡和各种地形因素都会降低提取效果。相比之下,三维点云的道路提取具有更多的几何信息和较高的精度水平(毫米级),但也面临遮挡问题,导致道路提取不完整。点密度变化问题也导致不准确的道路提取。随后引入了传感器融合方法,通过融合不同数据源,如航空图像、GPS数据、相机图像和激光雷达点云,进一步提高了道路提取性能。在道路提取中,传感器融合方法优于单一数据源的方法,取得了显著的效果。表6总结了三种方法的比较。表6 路网提取方法比较。
4.2 道路标志提取
道路标志/路面标记是混凝土和沥青道路表面上的标志[88]。它们通常被涂上高度反光的材料,使人类的视觉和自动驾驶汽车的传感器能够注意到它们。道路标志是高精地图上的基本特征,为车辆提供有关交通方向、转弯道、可行驶和不可行驶的车道和人行横道等信息[89]。与道路提取方法类似,道路标志提取也可以使用2D图像或3D点云。
4.2.1 从二维图像提取道路标志
传统上,二维图像上的道路标志提取是通过图像处理和计算机视觉来实现的。首先对含有道路标志的图像进行去噪和增强处理,使道路标志清晰明显,突出目标与背景区域的对比。然后,利用基于边缘检测(如Roberts、Sobel、Prewitt、Log、Canny)、阈值分割(如Otsu法、迭代法)、k-means聚类、区域生长法等图像处理和计算机视觉方法提取目标道路标志[90]。传统方法在从路面或混凝土路面提取道路标志方面取得了显著的效果。然而,简单的提取方法在没有正确识别不同道路标志的情况下,对于车辆理解道路规则是不够有效的。随着CNN的引入和快速发展,涉及CNN的方法在道路标志检测和识别中得到了广泛的发展和应用。二维图像上的道路标志提取和识别通常有两种不同的方法。一种是利用车载相机捕捉的前视图像。另一种是从航拍图像中提取道路标志。图13显示了两者的一个示例。

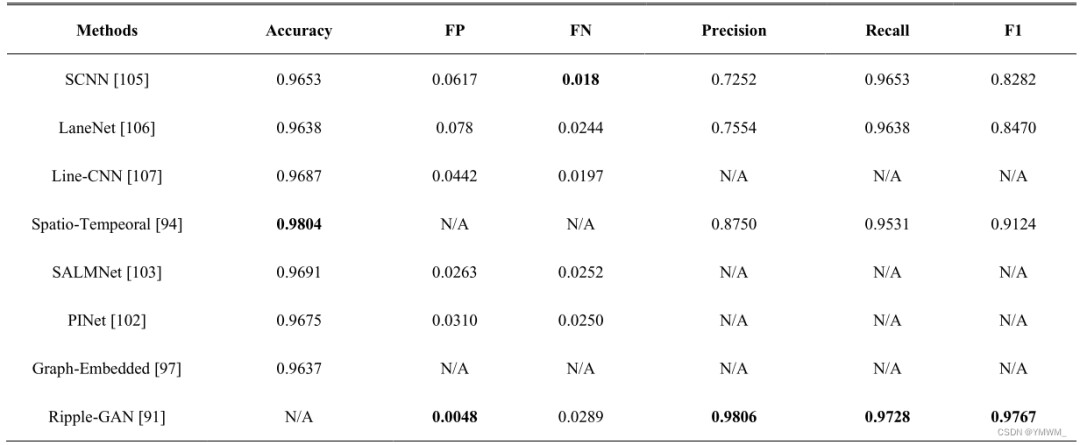
图13 前视图像上的道路标志VS航空图像上的道路标志。基于前视图像的道路标志提取。前视图像因其成本效益和便利性而被广泛用于道路标志提取。几种检测车道线标志的方法已经被提出。Zhang等人[91]提出了Ripple Lane Line Detection Network (RiLLD-Net)用于检测常见的车道线标志,Ripple-GAN用于检测复杂或被遮挡的车道线标志。RiLLD-Net是由U-Net[82]、带有跳跃连接的残差模块以及编码器和解码器之间的快速连接组合而成。利用Sobel边缘检测滤波器将含有车道线标志的原始图像预处理为梯度图[92]。将原始图像和梯度图送入RiLLD-Net,去除冗余干扰信息,突出车道线标志。Ripple-GAN是Wasserstein GAN (WGAN)[93]和RiLLD-Net的组合。将一幅加高斯白噪声的原始车道线标志图像送入信号处理网络,得到分割的车道线标志结果。将分割结果与梯度图一起发送到RiLLD-Net,进一步增强车道线标志检测结果。此外,[94]提出了一种具有双重卷积门控递归单元(ConvGRUs)的时空网络[95]、[96]用于车道线检测。该网络不是一次拍摄一张图像,而是以连续时间戳的车道线标志作为输入,进行多次捕捉。两个ConvGRUs各有其各自的功能。第一个ConvGRU也被称为Front ConvGRU (FCGRU),它被放置在编码器阶段,用于学习物体的低级特征(如颜色、形状、边界等),并过滤掉可能影响模型学习过程的干扰信息。第二个ConvGRU也称为中间ConvGRU,包含多个ConvGRU。它被放置在编码器和解码器相位之间,用于彻底学习FCGRU产生的连续行驶图像的时空行驶信息。然后,该网络连接来自编码器的下采样层和来自解码器的上采样层,以产生最终车道线标志检测。此外,也有人提出了其它方法来解决车道线检测和提取问题,如图嵌入车道检测[97]、基于渐进式概率霍夫变换的车道跟踪[98]、SALMNet[99]、基于分割的车道检测[100]和掩模R-CNN实例分割模型[101]。表7总结了不同方法[91]、[94]、[97]、[102]、[103]在TuSimple数据集[104]上的评价结果,以便进行清晰的比较。表7还包括了之前最先进的方法,包括SCNN[105]、LaneNet[106]和Line-CNN[107],以显示当前最先进方法的改进。表中粗体突出显示的值表示最佳结果。通过比较,Ripple-GAN是目前最先进的方法。表7 基于TuSimple数据集的前视图像道路标志提取方法评价结果。
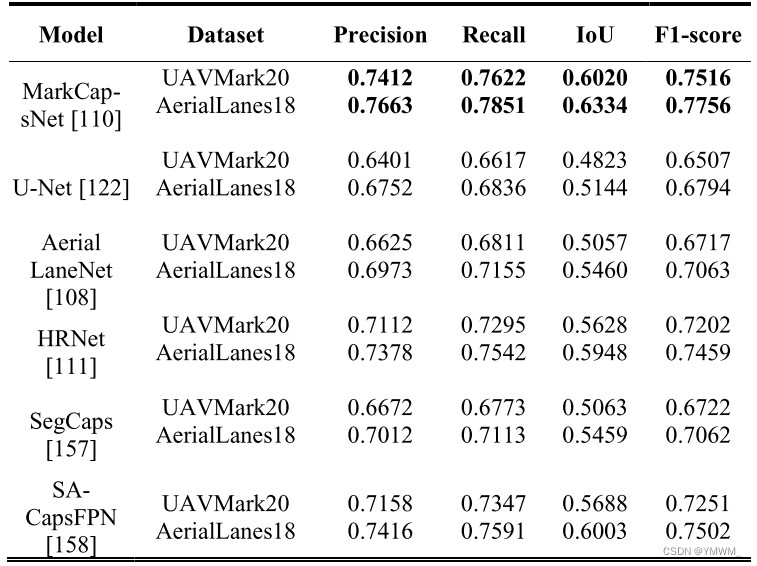
航空图像道路标志提取。卫星图像和航空图像不仅可以用于路网提取,还可以用于道路标志提取。Azimi等[108]提出了从航空图像中直接提取道路标志的Aerial LaneNet。该网络包含一个对称的全卷积神经网络(FCNN)。将原始航空图像分割成多个小块后发送到Aerial LaneNet。Aerial LaneNet对每个输入patch进行语义分割,并为每个patch生成二值图像,表示哪个像素来自车道标志,哪个像素来自背景。将所有二值图像/patch拼接在一起,得到与输入图像具有相同分辨率的最终道路标志图像。该模型还利用离散小波变换(DWT)实现多尺度全谱域分析。类似地,Kurz等人[109]设计了小波增强的FCNN来分割多视图高分辨率航空图像。imagery2D段进一步用于基于最小二乘直线拟合创建道路标志的三维重建。Yu等人也提出了一种自我注意力引导的胶囊网络,称为MarkCapsNet[110],用于从航空图像中提取道路标志。本文提出的网络结合胶囊表述和HRNet[111]架构,通过涉及三个分辨率不同的并行分支,可以提取不同尺度的特征语义。设计了基于胶囊的自我注意(SA)模块,并将其集成到MarkCapsNet的各个分支中,进一步提高了生成的特征图的表示质量,用于道路标志提取。此外,Yu等人还创建了用于道路标志提取应用的大型航空图像数据集AerialLanes18,该数据集可作为未来测试不同道路标志提取方法的基准。在UAVMark20和AerialLanes18两个数据集上对MarkCapsNet等道路标志提取模型进行了实验和比较。结果显示在表8中,MarkCapsNet已经达到了最先进的性能。表8 不同模型的道路标志提取结果。
与航空图像相比,基于前视图像的道路标志提取方法具有更小的视场,且检测/处理时间也比基于航空图像的现有道路标志提取方法要长。然而,由于检测是基于实时相机图像,它对于由磨损和遮挡造成的道路标志改变是灵活的。相比之下,航空图像的道路标志提取可以提取更大尺度的道路标志,并将提取的道路标志存储在高精地图中,以减少检测时间。然而,它对由照明条件、遮挡和道路标志磨损引起的数据缺陷很敏感。
4.2.2 三维点云的道路标志提取
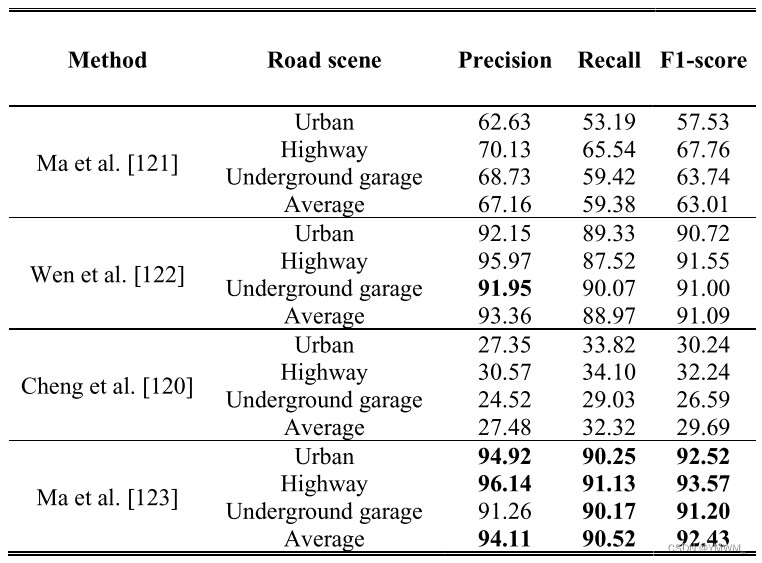
在三维点云上提取道路标志通常有两种不同的方法,自下而上法和自上而下法[88]。自下向上方法通过区分道路标志点云和背景点云,直接提取道路标志。自上向下方法利用CNN检测预定义的几何模型,并在此基础上重建道路标志。至下而上法。自下向上方法采用深度学习算法,在目标检测和分割的基础上,从原始三维点云中直接提取道路标志。与阈值相关的方法及其扩展,包括多阈值法和多阈值法结合几何特征滤波,被广泛应用于道路标志提取[112]-[115]。[116]、[117]在提取道路标志之前,将三维点云转换为二维地理参考灰度图像,以显著降低计算复杂度,但失去位姿(位置和方向)或空间信息。为了填补提取的道路标志缺失的位姿或空间信息的空白,Ma等人提出了一种基于胶囊的道路标志提取与分类网络[118]。该方法通过过滤掉灯杆、交通灯和树等离地特征点云来处理数据,降低了计算复杂度。利用反距离加权(IDW)算法将处理后的三维点云转换为二维地理参考灰度栅格图像。受[119]提出的胶囊网络的启发,Ma等人提出了一种U型胶囊网络,该网络不仅可以从栅格图像中学习灰度方差,还可以学习道路标志的位姿和形状。他们提出了一种混合胶囊网络,将不同的道路标志分为不同的类别。该方法在城市、高速公路和地下车库的道路标志提取中取得了最先进的效果,F1值为92.43%,精度为94.11%。[120]-[123]在定制道路标志数据集上的性能比较可以在表9中查看,其中粗体突出显示的值是主导结果。表9 不同自下向上方法的道路标志提取结果比较[123]。
自上而下法。自上向下方法利用现有的目标检测算法对路标几何模型进行检测和定位。它在检测和定位的基础上,在三维点云上重建道路标志。Prochazka等人[124]使用生成树的使用方法从点云中自动提取车道标志到多边形地图层。该方法在原始点云上进行地面点检测[125],并利用生成树对检测进行识别。在检测和识别后,将车道标志重构为矢量形式。该方法可以检测到车道标志,但不能检测到其它类型的道路标志,如道路方向标志和人行横道标志。Mi等人提出了一种利用MLS点云的两阶段道路标志提取和建模方法[88]。他们的方法利YOLOv3[126]算法检测道路标志,并在每次检测中提供语义标签。在重建和建模过程中,提出了能量函数(1)来确定原始三维点云中道路标志的精细位姿和尺度。
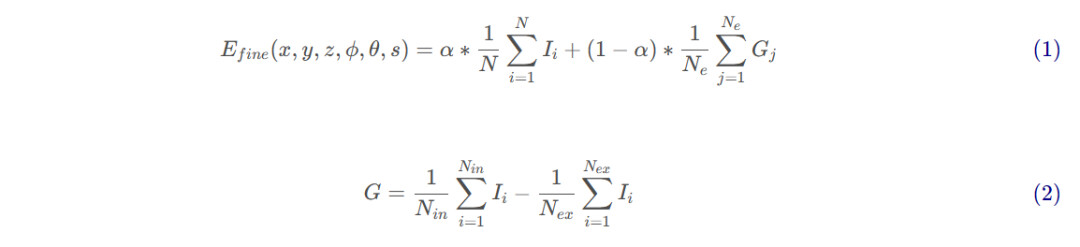
其中 ( x , y , z , ϕ , θ , s ) 是道路标志模板的位置和方向, α是权重, Ii是道路标志中第 i 个点的灰度, N 是模板中点的个数, N e是模板上样本点的数目, G j 是第 j 个边界点的灰度梯度,它在公式(2)中给出, N i n和 N e x分别表示在搜索半径中内点和外点数目[88]。通过最大化能量函数,可以对道路标志进行精确分割和建模。通过结合检测置信度和定位得分的候选者重排序策略,在三维点云上生成最终的道路标志模型,进一步提高道路标志提取性能。候选者重排序策略的目的是在道路标志重叠存在或镜像对称双标志存在的情况下提供最优选择,如图14所示。该方法能够准确提取中国道路交通标志国家标准中规定的12种道路标志。

图14 基于能量函数和候选者重排序策略的道路标志提取[88]。综上所述,自下向上方法可以直接从MLS点云中提取道路标志,加快道路标志提取速度,但对不完善的原始数据敏感。相比之下,不完善的原始数据对自上向下方法的影响较小,但自上向下方法检测时间长,搜索空间大。据笔者所知,相对于自下向上的方法,自上向下的方法并不多。因此,采用自上向下的方法提取道路标志还需要进一步研究。
4.3 杆状物体提取
在高精地图中,交通信号灯、交通标志、路灯、树木和电线杆等杆状物体对道路环境至关重要。它们可以帮助定位(不同于其它道路设施的形状)和运动规划(交通灯信号提供交通流条件)。在MLS三维点云上,杆状物体的提取通常通过分割和分类来实现。在过去的几年里,已经开发了各种杆状物体提取的方法。Lehtomäki等人[127]提出使用MLS三维点云结合分割、聚类和分类方法来检测垂直杆状物体。El-Halawany等人[128]采用一种基于协方差的方法对地面激光扫描点云进行杆状目标分割并求出其维数。Yokoyama等人[129]使用拉普拉斯平滑法,并使用主成分分析来识别具有不同半径和倾角的杆状物体上的点。Pu等人[130]提出了一种基于MLS三维点云的结构识别框架,并基于点云段的大小、形状、方向和拓扑关系等特征提取杆状物体。Cabo等人[131]提出了一种检测杆状物体的方法,通过规则体素化对点云进行空间离散,并对水平体素化的点云进行分析和分割。Ordóñez等人[132]在[131]的基础上增加了分类模块,以区分点云中不同类型的杆状物体。Yu等人[133]提出了一种半自动提取路灯杆的方法,将MLS三维点云分割为道路和非道路表面点,并使用两对三维形状上下文从非道路段提取路灯杆。Zheng等人[134]提出了一种新的基于图切的分割方法,从MLS三维点云中提取路灯杆,然后采用基于高斯混合模型的方法识别路灯杆。Plachetka等人[135]最近提出了一种基于深度神经网络(DNN)的方法,可以识别(检测和分类)LiDAR点云中的杆状物体。受[136]的启发,提出的DNN架构包括三个阶段:编码器、骨干、分类和回归头。将原始的三维点云预处理为单元特征向量,作为编码器阶段的输入。不同于[137]中只有一个编码器阶段,Plachetka等人在[138]之后增加了另一个编码器阶段,以提高细胞特征向量的表示能力。编码器将细胞特征向量编码为空间网格,作为骨干的输入。骨干阶段采用并修改了特征金字塔架构[66],以包含更多的上下文,提高了模型检测小目标的性能[139]。主干阶段将下游路径的低级特征和上游路径的高级特征连接起来,进一步增强输入网格的表示能力。下游路径利用卷积层,上游路径使用转置的卷积层。输出特征网格成为分类回归头输入。最后阶段采用SSD[69]方法进行预测计算。该方法的平均召回率、准确率和分类准确率分别为0.85、0.85和0.93。关于提出的DNN架构、数据集和训练过程的细节超出了本综述的范围,不作进一步讨论。检测类别包括防护杆、交通标志杆、交通信号灯杆、广告牌杆、路灯杆和树木。总之,在高精地图中,由于其特殊的形状,杆状物体是定位的重要特征。杆状物体的提取主要是在三维点云上进行的,因此提取的性能也取决于点云的质量。因此,需要进一步研究如何提高杆状类物体在不完美数据下的提取性能。
5 高精地图框架
随着高精地图越来越复杂,需要提取的环境特征越来越多,需要有一个良好的软件,以框架的形式在地图中充分存储相关信息,并确保地图的一致视图[140]。在本节中,介绍了三种流行的创建高精地图的开源框架,包括Lanelet2[141], OpenDRIVE[142]和Apollo maps[143]。
5.1 Lanelet2
Lanelet2是Liblanelet的扩展和推广,也被称为Lanelet,为Bertha Drive Project开发。Lanelet2地图采用了基于XML(可扩展标记语言)的OSM (Open Street map[144])数据格式Lanelet的退出格式。开放街道地图是一个免费的在线地图编辑工具,由世界各地的地图编辑人员不断更新和贡献。但是,地图的实际数据格式被认为是不相关的,只要这种格式可以转换为Lanelet2格式而不损失任何信息,就可以互换。Lanelet2地图包含三层:物理层、关系层和拓扑层,如图15所示。这三个层的特征与HERE定义的相似。第一物理层由两个元素组成,点和线串。点是地图的基本元素。它可以表示垂直结构,如杆点作为单点、车道或区域作为一组点。线串构造为两个或多个点的有序数组,其中每两个点之间使用线性插值。顾名思义,物理层定义了可检测的元素,如交通灯、标志、路沿石等。第二层关系由三个要素组成:网域、区域和调控要素。Lanelets定义了不同的道路类型,如普通车道、人行横道和铁轨。Lanelets也与交通规则相关,这些规则在Lanelets内不会改变。它是由一个左和一个右的线字符串定义为两个方向相反的边界。通过将左边框更改为右边框(反之亦然),这对线串中的方向是可互换的。区域由一条或多条线组成一个封闭的屏障,通常代表静态建筑,如建筑物、停车场、操场和草地空间。顾名思义,调控要素定义了对车辆进行调控的交通规则。车道和区域可以有一个或多个调控元素,如速度限制和限制。此外,还可以添加基于时间的转向限制等动态规则作为调控元素。Lanelet2是一个简单而强大的支持高精地图的框架。它也经常与Autoware Auto[145]一起用于创建高精地图的矢量地图。关于Lanelet2框架的更多细节可以在[141],[146]中找到。
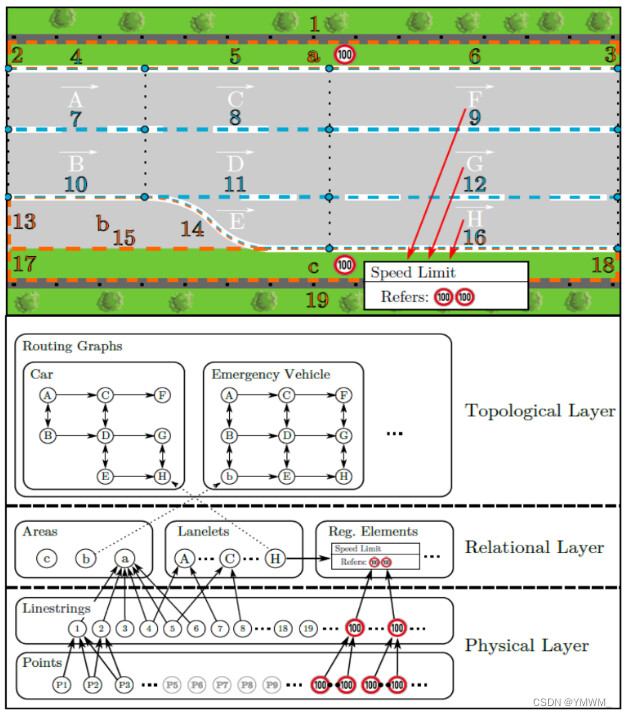
图15 Lanelet2地图结构[14]:物理层定义由点和线串组成的物理元素,如杆状物体、标志和边界。关系层定义区域、车道和管理元素,如建筑物、高速公路、行驶方向和交通规则。拓扑层定义来自前两层的元素之间的拓扑关系。图中拓扑层为普通车辆和应急车辆的routing。
5.2 OpenDRIVE
OpenDRIVE是一个由自动化和测量系统标准化协会(ASAM)开发的用于描述路网和绘制高精地图的开源框架[142]。它还使用XML文件格式来存储地图信息。在ASAM OpenDRIVE地图中,有三个元素/层,Reference Line/Road, Lane和Features,见图15。与Lanelet2地图使用点来描述和构建地图特征不同,OpenDRIVE使用几何基元包括直线、螺旋线、弧线、三次多项式和参数三次多项式来描述道路形状和行驶方向。这些几何基元被称为参考线。参考线是每个OpenDRIVE路网的关键组成部分,所有的车道和特征都是沿着参考线建立的。第二个元素,车道线,附加在基准线上,代表地图上的可行驶路径。每条道路至少包含一条宽度大于0的车道。每条道路的车道数以实际交通车道数为准,没有限制。在构建道路沿线车道时,需要设置宽度为0的中心车道,作为车道编号参考,如图16所示。中间车道根据道路类型定义两边的行驶方向,可以是相反方向,也可以是相同方向。在图16中,由于中心车道与参考线没有偏移,所以中心车道与参考线是重合的。最后一个元素,特征,它包含与交通规则相关的信号和标志等对象。然而,与Lanelet2不同的是,ASAM OpenDRIVE不包含动态内容。
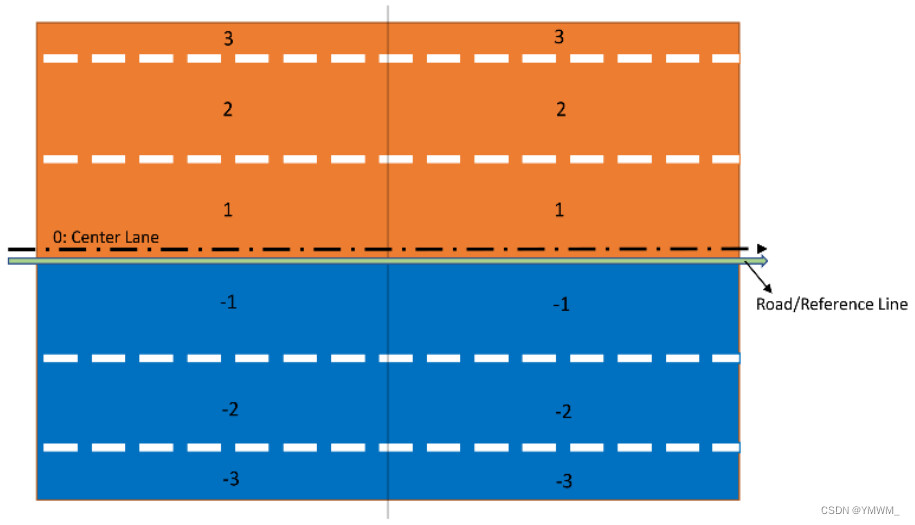
图16 具有不同行驶方向的车道的道路中心车道。ASAM提供的关于OpenDRIVE的文档也可以在[147]中找到。
5.3 Apollo地图
Apollo地图是由中国领先的自动驾驶平台百度Apollo打造的高精地图。Apollo高精地图也使用OpenDRIVE格式,但这是一个专门为Apollo设计的改进版本。与OpenDRIVE使用直线、螺旋线和弧线等几何基元来定义道路不同,Apollo只是简单地使用点。与Lanelet2中的点一样,每个点存储纬度和经度,这些点的列表定义道路边界。在Apollo高精地图中,通常有五个不同的元素。(1)道路要素包括道路边界、车道类型和车道行驶方向等特征。(2)intersection要素包含交集边界。(3)交通信号要素包括交通灯和标志。(4)逻辑关系要素包含交通规则。(5)其它要素包括人行横道、路灯和建筑[148]。为了构建HD地图,百度Apollo将生产过程分为数据源、数据处理、目标检测、人工验证、地图制作5个步骤,如图17所示。详细的Apollo HD地图生成程序见[149]。
图17 Apollo地图生成过程。在笔者看来,Apollo地图是OpenDRIVE的一个更高级、更复杂的版本。Apollo地图包含的要素并不来源于OpenDRIVE,比如OpenDRIVE没有停车场和人行横道。Apollo地图还需要比OpenDRIVE更多的数据来定义车道。OpenDRIVE只需要指定车道宽度,而Apollo需要用点来描述车道边界。为了在Apollo中使用OpenDRIVE地图,可以使用这里[150]提供的方法将OpenDRIVE格式转换为Apollo格式。Lanelet2地图也可以转换为OpenDRIVE地图格式。Carla是一个用于自动驾驶的开源模拟器,提供了一个用于将OSM地图转换为OpenDRIVE地图的PythonAPI[151]。
6 局限性和开放性问题
高精地图生成技术近年来发展迅速。然而,仍然有局限性。航空图像上的特征提取可以快速生成车道线和道路标志等特征,但这些特征并不包含高度或深度信息。通过将路网GPS数据与采集到的GPS数据进行匹配,并添加相应的高度,可以在2D地图上手动添加高度或高度信息,创建2.5D地图。然而,它仍然缺乏深度信息,而深度信息在车辆绕过障碍物时是极其重要的。2D高精地图对基础设施的微小变化也不敏感,这将不能保持地图的更新。MLS三维点云的特征提取是在高精地图中添加详细道路信息的一种更为常见和强大的方法。提取3D特征的高精地图可以提供深度信息和更新的环境信息,但需要昂贵的激光雷达和较高的计算成本。收集可用的点云数据也很耗时。在[70]中可以找到一个例子,Ibrahim等人驾驶SUV进行3次2小时的测试来收集可用的点云数据。[152]使用众包方法来保持高精地图的更新,但众包方法并不总是适用于个体研究人员。采集城市级别地图点云数据将是一个挑战。这些局限性导致了以下开放性问题。(1)在2D地图中添加更多功能,如深度信息,并保持更新。(2)提高3D地图生成过程的效率,使绘制大型3D高精地图成为可能,而不消耗太多的时间和计算能力。一种解决方案是将道路网络和点云集成来生成高精地图,可以通过Autoware[153]。此外,据作者所知,目前提出的用于人行横道特征提取的方法并不多(几乎没有)。这一点至关重要,也很有需求,因为一些自动驾驶系统要么是为了在人行道上行驶而设计的,要么需要在高速公路上测试之前在人行道上进行可行性测试。此外,高精地图的完成和整理(将所有模块和功能合并成高精地图)仍然是地图公司开发的商业化方法。这对于学术界和个人研究者来说仍然是一个有待进一步研究和结论的问题。本文对近年来自动驾驶高精地图生成技术进行了分析。高精地图的基本结构概括为三层:(1)道路模型、(2)车道模型、(3)定位模型。介绍并比较了生成高精地图的数据收集和特征提取方法,包括道路网络、道路标志和杆状物体。还讨论了这些方法的局限性。同时还介绍了支持高精地图的框架,包括Lanelet2、OpenDRIVE和Apollo。还提供了一些有用的工具,用于在三个框架之间转换地图格式。值得进一步研究的问题如下。(1)在2D地图中添加更多功能,如深度信息,并保持它们的不断更新。(2)提高3D地图生成过程的效率,使绘制大型3D高精地图成为可能,而不消耗太多的时间和计算能力。(3)创建人行横道的特征提取方法。(4)高精地图的完成和整理方法去商业化。
7 参考文献
[1] J. Ziegler, P. Bender, M. Schreiber, H. Lategahn, T. Strauss, C. Stiller, T. Dang, U. Franke, N. Appenrodt, C. G. Keller, E. Kaus, R. G. Fig. 18. Apollo Maps Generation Process 18 Herrtwich, C. Rabe, D. Pfeiffer, F. Lindner, F. Stein, F. Erbs, M. Enzweiler, C. Knoppel, J. Hipp, M. Haueis, M. Trepte, C. Brenk, A. Tamke, M. Ghanaat, M. Braun, A. Joos, H. Fritz, H. Mock, M. Hein, and E. Zeeb, “Making bertha drive-an autonomous journey on a historic route,” IEEE Intell. Transp. Syst. Mag., vol. 6, no. 2, pp. 8–20, Apr. 2014, doi: 10.1109/MITS.2014.2306552.[2] R. Liu, J. Wang, and B. Zhang, “High definition map for automated driving: overview and analysis,” J. Navig., vol. 73, no. 2, pp. 324–341, Mar. 2020, doi: 10.1017/S0373463319000638.[3] S. Ulbrich, A. Reschka, J. Rieken, S. Ernst, G. Bagschik, F. Dierkes, M. Nolte, and M. Maurer, “Towards a functional system architecture for automated vehicles,” Mar. 24, 2017, arXiv:1703.08557.[4] J. Houston, G. Zuidhof, L. Bergamini, Y. Ye, L. Chen, A. Jain, S. Omari, V. Iglovikov, and P. Ondruska, “One thousand and one hours: self-driving motion prediction dataset,” Jun. 25, 2020, arXiv: 2006.14480.[5] “Behind the map: how we keep our maps up to date | TomTom Blog.” [Online]. Available: https://www.tomtom.com/blog/maps/continuous[1]map-processing/[6] HERE, “Map Data | Static Map API.” 2021. [Online]. Available: https://www.here.com/platform/map-data[7] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,” Int. J. Rob. Res., vol. 32, no. 11, pp. 1231–1237, Sep. 2013, doi: 10.1177/0278364913491297.[8] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “Nuscenes: A multimodal dataset for autonomous driving,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2020, pp. 11618–11628.[9] T. Shan and B. Englot, “LeGO-LOAM: Lightweight and ground[1]optimized LiDAR odometry and mapping on variable terrain,” in IEEE Int. Conf. Intell. Robot. Syst., 2018, pp. 4758–4765.[10] W. Xu and F. Zhang, “FAST-LIO: A fast, robust LiDAR-inertial odometry package by tightly-coupled iterated kalman filter,” IEEE Robot. Autom. Lett., vol. 6, no. 2, pp. 3317–3324, Apr. 2021, doi: 10.1109/LRA.2021.3064227.[11] W. Xu, Y. Cai, D. He, J. Lin, and F. Zhang, “FAST-LIO2: Fast direct LiDAR-inertial odometry,” IEEE Trans. Robot., Jan. 2022, doi: 10.1109/TRO.2022.3141876.[12] J. Matsuo, K. Kondo, T. Murakami, T. Sato, Y. Kitsukawa, and J. Meguro, “3D point cloud construction with absolute positions using SLAM based on RTK-GNSS,” in Abstr. Int. Conf. Adv. mechatronics Towar. Evol. fusion IT mechatronics ICAM, 2021, vol. 2021.7, no. 0, pp. GS7-2.[13] T. Shan, B. Englot, D. Meyers, W. Wang, C. Ratti, and D. Rus, “LIO[1]SAM: Tightly-coupled lidar inertial odometry via smoothing and mapping,” in IEEE Int. Conf. Intell. Robot. Syst., 2020, pp. 5135–5142.[14] C. Zheng, Q. Zhu, W. Xu, X. Liu, Q. Guo, and F. Zhang, “FAST-LIVO: Fast and tightly-coupled sparse-direct LiDAR-inertial-visual odometry,” Mar. 02, 2022, arXiv: 2203.00893.[15] R. Dubé, A. Cramariuc, D. Dugas, H. Sommer, M. Dymczyk, J. Nieto, R. Siegwart, and C. Cadena, “SegMap: Segment-based mapping and localization using data-driven descriptors,” Int. J. Rob. Res., vol. 39, no. 2–3, pp. 339–355, Mar. 2020, doi: 10.1177/0278364919863090.[16] J. Zhang and S. Singh, “LOAM: Lidar odometry and mapping in real[1]time,” in Robot. Sci. Syst., 2015, vol. 2, no. 9, pp. 1–9.[17] D. Rozenberszki and A. L. Majdik, “LOL: Lidar-only odometry and localization in 3D point cloud maps∗,” in Proc. IEEE Int. Conf. Robot. Autom., 2020, pp. 4379–4385.[18] J. Lin and F. Zhang, “Loam livox: A fast, robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV,” in Proc. IEEE Int. Conf. Robot. Autom., 2020, pp. 3126–3131.[19] J. Lin and F. Zhang, “A fast, complete, point cloud based loop closure for LiDAR odometry and mapping,” Sep. 25, 2019, arXiv: 1909.11811.[20] J. Lin, X. Liu, and F. Zhang, “A decentralized framework for simultaneous calibration, localization and mapping with multiple LiDARs,” in IEEE Int. Conf. Intell. Robot. Syst., 2020, pp. 4870–4877.[21] B. Fang, J. Ma, P. An, Z. Wang, J. Zhang, and K. Yu, “Multi-level height maps-based registration method for sparse LiDAR point clouds in an urban scene,” Appl. Opt., vol. 60, no. 14, p. 4154, May 2021, doi: 10.1364/ao.419746.[22] A. Gressin, C. Mallet, and N. David, “Improving 3D lidar point cloud registration using optimal neighborhood knowledge,” in ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci., 2012, vol. 1, pp. 111–116.[23] M. Magnusson, A. Lilienthal, and T. Duckett, “Scan registration for autonomous mining vehicles using 3D-NDT,” J. F. Robot., vol. 24, no. 10, pp. 803–827, Oct. 2007, doi: 10.1002/rob.20204.[24] M. Magnusson, “The three-dimensional normal-distributions transform — an efficient representation for registration, surface analysis, and loop detection,” Ph.D. dissertation, Dept. of Tech., Örebro universitet, Sweden, 2008.[25] P. Biber, “The normal distributions transform: A new approach to laser scan matching,” in IEEE Int. Conf. Intell. Robot. Syst., 2003, vol. 3, pp. 2743–2748.[26] E. Takeuchi and T. Tsubouchi, “A 3-D scan matching using improved 3-D normal distributions transform for mobile robotic mapping,” in IEEE Int. Conf. Intell. Robot. Syst., 2006, pp. 3068–3073.[27] S. Kato, S. Tokunaga, Y. Maruyama, S. Maeda, M. Hirabayashi, Y. Kitsukawa, A. Monrroy, T. Ando, Y. Fujii, and T. Azumi, “Autoware on board: Enabling autonomous vehicles with embedded systems,” in Proc. 9th ACM/IEEE Int. Conf. Cyber-Physical Syst. ICCPS 2018, 2018, pp. 287–296.[28] K. Chen, R. Nemiroff, and B. T. Lopez, “Direct LiDAR-inertial odometry,” Mar. 07, 2022, arXiv: 2203.03749.[29] J. Lin, C. Zheng, W. Xu, and F. Zhang, “R2LIVE: A robust, real-time, LiDAR-inertial-visual tightly-coupled state estimator and mapping,” IEEE Robot. Autom. Lett., vol. 6, no. 4, pp. 7469–7476, Jul. 2021, doi: 10.1109/LRA.2021.3095515.[30] J. Lin and F. Zhang, “R3LIVE: A robust, real-time, RGB-colored, LiDAR-inertial-visual tightly-coupled state estimation and mapping package,” Sep. 10, 2021, arXiv: 2109.07982.[31] T. Shan, B. Englot, C. Ratti, and D. Rus, “LVI-SAM: Tightly-coupled Lidar-visual-tnertial odometry via smoothing and mapping,” in Proc. IEEE Int. Conf. Robot. Autom., 2021, pp. 5692–5698.[32] S. Song, S. Jung, H. Kim, and H. Myung, “A method for mapping and localization of quadrotors for inspection under bridges using camera and 3D-LiDAR,” in Proc. 7th Asia-Pacific Work. Struct. Heal. Monit. APWSHM 2018, 2018, pp. 1061–1068.[33] “Human in the loop: Machine learning and AI for the people.” [Online]. Available: https://www.zdnet.com/article/human-in-the-loop-machine[1]learning-and-ai-for-the-people/[34] L. Biewald, “Why human-in-the-loop computing is the future of machine learning | Computerworld,” Computer World. 2015. [Online]. Available: https://www.computerworld.com/article/3004013/robotics/why[1]human-in-the-loop-computing-is-the-future-of-machine-learning.html[35] D. Xin, L. Ma, J. Liu, S. Macke, S. Song, and A. Parameswaran, “Accelerating human-in-the-loop machine learning: Challenges and opportunities,” in Proc. 2nd Work. Data Manag. End-To-End Mach. Learn. DEEM 2018 - conjunction with 2018 ACM SIGMOD/PODS Conf., 2018, pp. 1–4.[36] G. Mattyus, W. Luo, and R. Urtasun, “DeepRoadMapper: Extracting road topology from aerial images,” in Proc. IEEE Int. Conf. Comput. Vis., 2017, pp. 3458–3466.[37] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778.[38] T. Y. Zhang and C. Y. Suen, “A fast parallel algorithm for thinning digital patterns,” Commun. ACM, vol. 27, no. 3, pp. 236–239, Mar. 1984, doi: 10.1145/357994.358023.[39] P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,” IEEE Trans. Syst. Sci. Cybern., vol. 4, no. 2, pp. 100–107, Jul. 1968, doi: 10.1109/TSSC.1968.300136.[40] S. Wang, M. Bai, G. Mattyus, H. Chu, W. Luo, B. Yang, J. Liang, J. Cheverie, S. Fidler, and R. Urtasun, “TorontoCity: Seeing the world with a million eyes,” in Proc. IEEE Int. Conf. Comput. Vis., 2017, pp. 3028–3036.[41] J. D. Wegner, J. A. Montoya-Zegarra, and K. Schindler, “Road networks as collections of minimum cost paths,” ISPRS J. Photogramm. Remote Sens., vol. 108, pp. 128–137, Oct. 2015, doi: 10.1016/j.isprsjprs.2015.07.002.[42] A. Batra, S. Singh, G. Pang, S. Basu, C. V. Jawahar, and M. Paluri, “Improved road connectivity by joint learning of orientation and segmentation,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2019, pp. 10377–10385.[43] A. Van Etten, D. Lindenbaum, and T. M. Bacastow, “SpaceNet: A remote sensing dataset and challenge series,” Jul. 03, 2018, arXiv: 1807.01232.[44] I. Demir, K. Koperski, D. Lindenbaum, G. Pang, J. Huang, S. Basu, F. Hughes, D. Tuia, and R. Raska, “DeepGlobe 2018: A challenge to parse the earth through satellite images,” in IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. Work., 2018, pp. 172–181.[45] A. Mosinska, P. Marquez-Neila, M. Kozinski, and P. Fua, “Beyond the pixel-wise loss for topology-aware delineation,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2018, pp. 3136–3145.[46] G. Máttyus and R. Urtasun, “Matching adversarial networks,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2018, pp. 8024–8032.[47] A. Chaurasia and E. Culurciello, “linkNet: Exploiting encoder representations for efficient semantic segmentation,” in 2017 IEEE Vis. Commun. Image Process. VCIP 2017, 2018, pp. 1–4.[48] F. Bastani, S. He, S. Abbar, M. Alizadeh, H. Balakrishnan, S. Chawla, S. Madden, and D. Dewitt, “RoadTracer: Automatic extraction of road networks from aerial images,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4720–4728.[49] H. Ghandorh, W. Boulila, S. Masood, A. Koubaa, F. Ahmed, and J. Ahmad, “Semantic segmentation and edge detection—approach to road detection in very high resolution satellite images,” Remote Sens., vol. 14, no. 3, Jan. 2022, doi: 10.3390/rs14030613.[50] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” 2017, arXiv: 1706.05587.[51] M. Milanova, “Visual attention in deep learning: a review,” Int. Robot. Autom. J., vol. 4, no. 3, May 2018, doi: 10.15406/iratj.2018.04.00113.[52] X. Li, W. Zhang, and Q. Ding, “Understanding and improving deep learning-based rolling bearing fault diagnosis with attention mechanism,” Signal Processing, vol. 161, pp. 136–154, Aug. 2019, doi: 10.1016/j.sigpro.2019.03.019.[53] Y. Chen, G. Peng, Z. Zhu, and S. Li, “A novel deep learning method based on attention mechanism for bearing remaining useful life prediction,” Appl. Soft Comput. J., vol. 86, Jan. 2020, doi: 10.1016/j.asoc.2019.105919.[54] Z. Niu, G. Zhong, and H. Yu, “A review on the attention mechanism of deep learning,” Neurocomputing, vol. 452, pp. 48–62, Sep. 2021, doi: 10.1016/j.neucom.2021.03.091.[55] G. Cheng, Y. Wang, S. Xu, H. Wang, S. Xiang, and C. Pan, “Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 6, pp. 3322–3337, Mar. 2017, doi: 10.1109/TGRS.2017.2669341.[56] N. Xue, S. Bai, F. Wang, G. S. Xia, T. Wu, and L. Zhang, “Learning attraction field representation for robust line segment detection,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2019, pp. 1595–1603.[57] S. He, F. Bastani, S. Jagwani, M. Alizadeh, H. Balakrishnan, S. Chawla, M. M. Elshrif, S. Madden, and M. A. Sadeghi, “Sat2Graph: Road graph extraction through graph-tensor encoding,” in Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), 2020, vol. 12369 LNCS, pp. 51–67.[58] N. Girard, D. Smirnov, J. Solomon, and Y. Tarabalka, “Polygonal building extraction by frame field learning,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2021, pp. 5887–5896.[59] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Adv. Neural Inf. Process. Syst., 2017, pp. 5999–6009.[60] Z. Xu, Y. Liu, L. Gan, X. Hu, Y. Sun, M. Liu, and L. Wang, “CsBoundary: City-scale road-boundary detection in aerial images for high-definition maps,” IEEE Robot. Autom. Lett., vol. 7, no. 2, pp. 5063–5070, Apr. 2022, doi: 10.1109/LRA.2022.3154052.[61] T. Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proc. 30th IEEE Conf. Comput. Vis. Pattern Recognition, CVPR 2017, 2017, pp. 936– 944.[62] Z. Xu, Y. Sun, and M. Liu, “Topo-Boundary: A benchmark dataset on topological road-boundary detection using aerial images for autonomous driving,” IEEE Robot. Autom. Lett., vol. 6, no. 4, pp. 7248– 7255, Jul. 2021, doi: 10.1109/LRA.2021.3097512.[63] J. D. Wegner, J. A. Montoya-Zegarra, and K. Schindler, “A higher-order CRF model for road network extraction,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2013, pp. 1698–1705.[64] M. Ibrahim, N. Akhtar, M. A. A. K. Jalwana, M. Wise, and A. Mian, “High Definition LiDAR mapping of Perth CBD,” in 2021 Digit. Image Comput. Tech. Appl., 2021, pp. 1–8.[65] D. Landry, F. Pomerleau, and P. Giguère, “CELLO-3D: Estimating the covariance of ICP in the real world,” in Proc. IEEE Int. Conf. Robot. Autom., 2019, pp. 8190–8196.[66] I. Bogoslavskyi and C. Stachniss, “Efficient online segmentation for sparse 3D laser scans,” Photogramm. Fernerkundung, Geoinf., vol. 85, no. 1, pp. 41–52, Feb. 2017, doi: 10.1007/s41064-016-0003-y.[67] S. Ding, Y. Fu, W. Wang, and Z. Pan, “Creation of high definition map for autonomous driving within specific scene,” in Int. Conf. Smart Transp. City Eng. 2021, 2021, pp. 1365–1373.[68] S. Gu, Y. Zhang, J. Yang, J. M. Alvarez, and H. Kong, “Two-view fusion based convolutional neural network for urban road detection,” in IEEE Int. Conf. Intell. Robot. Syst., 2019, pp. 6144–6149.[69] S. Gu, Y. Zhang, J. Tang, J. Yang, and H. Kong, “Road detection through CRF based LiDAR-camera fusion,” in Proc. IEEE Int. Conf. Robot. Autom., 2019, pp. 3832–3838.[70] D. Yu, H. Xiong, Q. Xu, J. Wang, and K. Li, “Multi-stage residual fusion network for LIDAR-camera road detection,” in IEEE Intell. Veh. Symp. Proc., 2019, pp. 2323–2328.[71] Y. Li, L. Xiang, C. Zhang, and H. Wu, “Fusing taxi trajectories and rs images to build road map via dcnn,” IEEE Access, vol. 7, pp. 161487– 161498, Nov. 2019, doi: 10.1109/ACCESS.2019.2951730.[72] B. Li, D. Song, A. Ramchandani, H. M. Cheng, D. Wang, Y. Xu, and B. Chen, “Virtual lane boundary generation for human-compatible autonomous driving: A tight coupling between perception and planning,” in IEEE Int. Conf. Intell. Robot. Syst., 2019, pp. 3733–3739.[73] L. Ma, Y. Li, J. Li, J. M. Junior, W. N. Goncalves, and M. A. Chapman, “BoundaryNet: Extraction and completion of road boundaries with deep learning using mobile laser scanning point clouds and satellite imagery,” IEEE Trans. Intell. Transp. Syst., Feb. 2021, doi: 10.1109/TITS.2021.3055366.[74] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), 2015, vol. 9351, pp. 234–241.[75] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” Commun. ACM, vol. 63, no. 11, pp. 139–144, Nov. 2020, doi: 10.1145/3422622.[76] L. Zhou, C. Zhang, and M. Wu, “D-linknet: linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction,” in IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. Work., 2018, pp. 192–196.[77] M. Schreiber, C. Knöppel, and U. Franke, “LaneLoc: Lane marking based localization using highly accurate maps,” in IEEE Intell. Veh. Symp. Proc., 2013, pp. 449–454.[78] W. Jang, J. An, S. Lee, M. Cho, M. Sun, and E. Kim, “Road lane semantic segmentation for high definition map,” in IEEE Intell. Veh. Symp. Proc., 2018, pp. 1001–1006.[79] J. Jiao, “Machine learning assisted high-definition map creation,” in Proc. Int. Comput. Softw. Appl. Conf., 2018, vol. 1, pp. 367–373.[80] M. Aldibaja, N. Suganuma, and K. Yoneda, “LIDAR-data accumulation strategy to generate high definition maps for autonomous vehicles,” in IEEE Int. Conf. Multisens. Fusion Integr. Intell. Syst., 2017, pp. 422– 428.[81] X. Mi, B. Yang, Z. Dong, C. Liu, Z. Zong, and Z. Yuan, “A two-stage approach for road marking extraction and modeling using MLS point clouds,” ISPRS J. Photogramm. Remote Sens., vol. 180, pp. 255–268, Oct. 2021, doi: 10.1016/j.isprsjprs.2021.07.012.[82] D. Betaille and R. Toledo-Moreo, “Creating enhanced maps for lane[1]level vehicle navigation,” IEEE Trans. Intell. Transp. Syst., vol. 11, no. 4, pp. 786–798, Jul. 2010, doi: 10.1109/TITS.2010.2050689.[83] Z. Zhang, X. Zhang, S. Yang, and J. Yang, “Research on pavement marking recognition and extraction method,” in 2021 6th Int. Conf. Image, Vis. Comput. ICIVC 2021, 2021, pp. 100–105.[84] Y. Zhang, Z. Lu, D. Ma, J. H. Xue, and Q. Liao, “Ripple-GAN: Lane line detection with ripple lane line detection network and wasserstein GAN,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 3, pp. 1532–1542, May 2021, doi: 10.1109/TITS.2020.2971728.[85] N. Kanopoulos, N. Vasanthavada, and R. L. Baker, “Design of an image edge detection filter using the Sobel operator,” IEEE J. Solid-State Circuits, vol. 23, no. 2, pp. 358–367, Apr. 1988, doi: 10.1109/4.996.[86] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein GAN,” Jan. 26, 2017, arXiv: 1701.07875.[87] J. Zhang, T. Deng, F. Yan, and W. Liu, “Lane detection model based on spatio-temporal network with double convolutional gated recurrent units,” IEEE Trans. Intell. Transp. Syst., Feb. 2021, doi: 10.1109/TITS.2021.3060258[88] M. Siam, S. Valipour, M. Jagersand, and N. Ray, “Convolutional gated recurrent networks for video segmentation,” in Proc. Int. Conf. Image Process. ICIP, 2018, pp. 3090–3094. doi: 10.1109/ICIP.2017.8296851.[89] B. He, Y. Guan, and R. Dai, “Convolutional gated recurrent units for medical relation classification,” in Proc. 2018 IEEE Int. Conf. Bioinforma. Biomed. BIBM 2018, 2019, pp. 646–650.[90] P. Lu, S. Xu, and H. Peng, “Graph-embedded lane detection,” IEEE Trans. Image Process., vol. 30, pp. 2977–2988, Feb. 2021, doi: 10.1109/TIP.2021.3057287.[91] M. Marzougui, A. Alasiry, Y. Kortli, and J. Baili, “A lane tracking method based on progressive probabilistic hough transform,” IEEE Access, vol. 8, pp. 84893–84905, May 2020, doi: 10.1109/ACCESS.2020.2991930.[92] X. Xu, T. Yu, X. Hu, W. W. Y. Ng, and P. A. Heng, “SALMNet: A structure-aware lane marking detection network,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 8, pp. 4986–4997, Apr. 2021, doi: 10.1109/TITS.2020.2983077.[93] Y. Ko, Y. Lee, S. Azam, F. Munir, M. Jeon, and W. Pedrycz, “Key points estimation and point instance segmentation approach for lane detection,” IEEE Trans. Intell. Transp. Syst., Jun. 2021, doi: 10.1109/TITS.2021.3088488.[94] J. Tian, J. Yuan, and H. Liu, “Road marking detection based on mask R-CNN instance segmentation model,” in Proc. 2020 Int. Conf. Comput. Vision, Image Deep Learn. CVIDL 2020, 2020, pp. 246–249.[95] “GitHub - TuSimple/tusimple-benchmark: Download datasets and ground truths.” [Online]. Available: https://github.com/TuSimple/tusimple-benchmark[96] X. Pan, J. Shi, P. Luo, X. Wang, and X. Tang, “Spatial as deep: Spatial CNN for traffic scene understanding,” in 32nd AAAI Conf. Artif. Intell. AAAI 2018, 2018, pp. 7276–7283.[97] D. Neven, B. De Brabandere, S. Georgoulis, M. Proesmans, and L. Van Gool, “Towards end-to-end lane detection: An instance segmentation approach,” in IEEE Intell. Veh. Symp. Proc., 2018, pp. 286–291.[98] X. Li, J. Li, X. Hu, and J. Yang, “Line-CNN: End-to-end traffic line detection with line proposal unit,” IEEE Trans. Intell. Transp. Syst., vol. 21, no. 1, pp. 248–258, Jan. 2020, doi: 10.1109/TITS.2019.2890870.[99] S. M. Azimi, P. Fischer, M. Korner, and P. Reinartz, “Aerial LaneNet: Lane-marking semantic segmentation in aerial imagery using wavelet[1]enhanced cost-sensitive symmetric fully convolutional neural networks,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 5, pp. 2920– 2938, Mar. 2019, doi: 10.1109/TGRS.2018.2878510.[100] F. Kurz, S. M. Azimi, C. Y. Sheu, and P. D’Angelo, “Deep learning segmentation and 3D reconstruction of road markings using multiview aerial imagery,” ISPRS Int. J. Geo-Information, vol. 8, no. 1, Jan. 2019, doi: 10.3390/ijgi8010047.[101] Y. Yu, Y. Li, C. Liu, J. Wang, C. Yu, X. Jiang, L. Wang, Z. Liu, and Y. Zhang, “MarkCapsNet: Road marking extraction from aerial images using self-attention-guided capsule network,” IEEE Geosci. Remote Sens. Lett., vol. 19, Nov. 2022, doi: 10.1109/LGRS.2021.3124575.[102] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang, W. Liu, and B. Xiao, “Deep high-resolution representation learning for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 10, pp. 3349–3364, Oct. 2021, doi: 10.1109/TPAMI.2020.2983686.[103] C. Wen, X. Sun, J. Li, C. Wang, Y. Guo, and A. Habib, “A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds,” ISPRS J. Photogramm. Remote Sens., vol. 147, pp. 178–192, Jan. 2019, doi: 10.1016/j.isprsjprs.2018.10.007.[104] R. LaLonde, Z. Xu, I. Irmakci, S. Jain, and U. Bagci, “Capsules for biomedical image segmentation,” Med. Image Anal., vol. 68, Feb. 2021, doi: 10.1016/j.media.2020.101889.[105] Y. Yu, Y. Yao, H. Guan, D. Li, Z. Liu, L. Wang, C. Yu, S. Xiao, W. Wang, and L. Chang, “A self-attention capsule feature pyramid network for water body extraction from remote sensing imagery,” Int. J. Remote Sens., vol. 42, no. 5, pp. 1801–1822, Dec. 2021, doi: 10.1080/01431161.2020.1842544.[106] C. Ye, J. Li, H. Jiang, H. Zhao, L. Ma, and M. Chapman, “Semi[1]automated generation of road transition lines using mobile laser scanning data,” IEEE Trans. Intell. Transp. Syst., vol. 21, no. 5, pp. 1877–1890, May 2020, doi: 10.1109/TITS.2019.2904735.[107] L. Ma, Y. Li, J. Li, Z. Zhong, and M. A. Chapman, “Generation of horizontally curved driving lines in HD maps using mobile laser scanning point clouds,” IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., vol. 12, no. 5, pp. 1572–1586, May 2019, doi: 10.1109/JSTARS.2019.2904514.[108] M. Soilán, B. Riveiro, J. Martínez-Sánchez, and P. Arias, “Segmentation and classification of road markings using MLS data,” ISPRS J. Photogramm. Remote Sens., vol. 123, pp. 94–103, Jan. 2017, doi: 10.1016/j.isprsjprs.2016.11.011.[109] M. Soilán, A. Sánchez-Rodríguez, P. Del Río-Barral, C. Perez-Collazo, P. Arias, and B. Riveiro, “Review of laser scanning technologies and their applications for road and railway infrastructure monitoring,” Infrastructures, vol. 4, no. 4, Sep. 2019, doi: 10.3390/infrastructures4040058.[110] B. He, R. Ai, Y. Yan, and X. Lang, “Lane marking detection based on convolution neural network from point clouds,” in IEEE Conf. Intell. Transp. Syst. Proceedings, ITSC, 2016, pp. 2475–2480.[111] L. Ma, Y. Li, J. Li, Y. Yu, J. M. Junior, W. N. Goncalves, and M. A. Chapman, “Capsule-based networks for road marking extraction and classification from mobile LiDAR point clouds,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 4, pp. 1981–1995, Apr. 2021, doi: 10.1109/TITS.2020.2990120.[112] S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic routing between capsules,” in Adv. Neural Inf. Process. Syst., 2017, pp. 3857–3867.[113] M. Cheng, H. Zhang, C. Wang, and J. Li, “Extraction and classification of road markings using mobile laser scanning point clouds,” IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., vol. 10, no. 3, pp. 1182–1196, Mar. 2017, doi: 10.1109/JSTARS.2016.2606507.[114] D. Prochazka, J. Prochazkova, and J. Landa, “Automatic lane marking extraction from point cloud into polygon map layer,” Eur. J. Remote Sens., vol. 52, no. sup1, pp. 26–39, Oct. 2019, doi: 10.1080/22797254.2018.1535837.[115] J. Landa, D. Prochazka, and J. Štastny, “Point cloud processing for smart systems,” Acta Univ. Agric. Silvic. Mendelianae Brun., vol. 61, no. 7, pp. 2415–2421, Jan. 2013, doi: 10.11118/actaun201361072415.[116] J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement,” Apr. 08, 2018, arXiv: 1804.02767.[117] M. Lehtomäki, A. Jaakkola, J. Hyyppä, A. Kukko, and H. Kaartinen, “Detection of vertical pole-like objects in a road environment using vehicle-based laser scanning data,” Remote Sens., vol. 2, no. 3, pp. 641– 664, Mar. 2010, doi: 10.3390/rs2030641.[118] S. I. El-Halawany and D. D. Lichti, “Detection of road poles from mobile terrestrial laser scanner point cloud,” in 2011 Int. Work. Multi[1]Platform/Multi-Sensor Remote Sens. Mapping, M2RSM 2011, 2011, pp. 1–6.[119] H. Yokoyama, H. Date, S. Kanai, and H. Takeda, “Pole-like objects recognition from mobile laser scanning data using smoothing and principal component analysis,” Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci., vol. XXXVIII–5, pp. 115–120, Sep. 2012, doi: 10.5194/isprsarchives-xxxviii-5-w12-115-2011.[120] S. Pu, M. Rutzinger, G. Vosselman, and S. Oude Elberink, “Recognizing basic structures from mobile laser scanning data for road inventory studies,” ISPRS J. Photogramm. Remote Sens., vol. 66, no. 6 SUPPL., Dec. 2011, doi: 10.1016/j.isprsjprs.2011.08.006.[121] C. Cabo, C. Ordoñez, S. García-Cortés, and J. Martínez, “An algorithm for automatic detection of pole-like street furniture objects from Mobile Laser Scanner point clouds,” ISPRS J. Photogramm. Remote Sens., vol. 87, pp. 47–56, Jan. 2014, doi: 10.1016/j.isprsjprs.2013.10.008.[122] C. Ordóñez, C. Cabo, and E. Sanz-Ablanedo, “Automatic detection and classification of pole-like objects for urban cartography using mobile laser scanning data,” Sensors (Switzerland), vol. 17, no. 7, Jun. 2017, doi: 10.3390/s17071465.[123] Y. Yu, J. Li, H. Guan, C. Wang, and J. Yu, “Semiautomated extraction of street light poles from mobile LiDAR point-clouds,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 3, pp. 1374–1386, Mar. 2015, doi: 10.1109/TGRS.2014.2338915.[124] H. Zheng, R. Wang, and S. Xu, “Recognizing street lighting poles from mobile LiDAR data,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 1, pp. 407–420, Jan. 2017, doi: 10.1109/TGRS.2016.2607521.[125] C. Plachetka, J. Fricke, M. Klingner, and T. Fingscheidt, “DNN-based recognition of pole-like objects in LiDAR point clouds,” in IEEE Conf. Intell. Transp. Syst. Proceedings, ITSC, 2021, pp. 2889–2896.[126] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” in Proc. - 30th IEEE Conf. Comput. Vis. Pattern Recognition, CVPR 2017, 2017, pp. 77–85.[127] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2019, pp. 12689–12697.[128] Y. Zhou and O. Tuzel, “VoxelNet: End -to -end learning for point cloud based 3D object detection,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4490 –4499.[129] P. Hu and D. Ramanan, “Finding tiny faces,” in Proc. 30th IEEE Conf. Comput. Vis. Pattern Recognition, CVPR 2017, 2017, pp. 1522 –1530.[130] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), 2016, vol. 9905 LNCS, pp. 21 –37.[131] F. Poggenhans, J. H. Pauls, J. Janosovits, S. Orf, M. Naumann, F. Kuhnt, and M. Mayr, “Lanelet2: A high -definition map framework for the future of automated driving,” in IEEE Conf. Intell. Transp. Syst. Proceedings, ITSC, 2018, pp. 1672 –1679.[132] “ASAM OpenDRIVE®.” [Online]. Available: https://www.asam.net/standards/detail/opendrive/[133] C. W. Gran, “HD -maps in autonomous driving,” M.S. thesis, Dept. Comp. Sci., Norwegian Univ. of Sci. and Tech., Norway, 2019.[134] “Lanelet2 map for Autoware.Auto.” [Online]. Available: https://autowarefoundation.gitlab.io/autoware.auto/AutowareAuto/lane let2 -map -for -autoware -auto.html[135] “OpenDRIVE 1.6.1.” [Online]. Available: https://www.asam.net/index.php?eID=dumpFile&t=f&f=4089&token= deea5d707e2d0edeeb4fccd544a973de4bc46a09#_specific_lane_rules[136] A. Avila, “Using open source frameworks in autonomous vehicle development - Part 2.” Mar. 04, 2020. [Online]. Available: https://auro.ai/blog/2020/03/using -open -source -frameworks -in - autonomous -vehicle -development -part -2/[137] “Generate maps with OpenStreetMap - CARLA Simulator.” [Online]. Available: https://carla.readthedocs.io/en/latest/tuto_G_openstreetmap/[138] K. Kim, S. Cho, and W. Chung, “HD map update for autonomous driving with crowdsourced data,” IEEE Robot. Autom. Lett., vol. 6, no. 2, pp. 1895 –1901, Apr. 2021, doi: 10.1109/LRA.2021.3060406
- 下一篇:碳化硅电驱动总成设计与测试
- 上一篇:特约专栏 | 国内功能安全的发展与现状



编辑推荐




最新资讯
-
沃尔沃汽车:创新驱动的豪华品牌
2025-04-24 18:16
-
飞书项目落地ASPICE解决方案,助力汽车软件
2025-04-24 09:59
-
驾驶员监控系统DMS合规认证的“中西结合”
2025-04-24 08:23
-
自动驾驶汽车测试关键行人场景生成
2025-04-23 17:12
-
R171.01对DCAS的要求⑧
2025-04-23 17:08
