




 广告
广告





















































自动驾驶一体化安全评价实验

为实现对不同自动驾驶解决方案系统的量化分析,本实验基于自动驾驶仿真模拟器Carla二次开发了交通仿真平台,支持模拟使用不同感知与决策控制算法的驾驶行为,并基于不同评价标准,对系统结果进行对比分析。
通过对百度实际测试数据与自动驾驶领域公开数据集的分析与归纳,实验选取了行人鬼探头、无保护左转、异常障碍物与异常交通情况四个典型场景,作为自动驾驶领域备受关注的安全问题与边缘场景的代表。真实数据被用于建模各场景的初始参数分布模型,以在仿真平台上渲染构建高保真的实验场景。
对每一个典型场景,均开展单车智能、车路协同感知、车路协同感知与决策控制三种对照实验各1000 次,并从安全和通过效率等评价维度,对实验结果进行统计分析,为自动驾驶解决方案的量化分析与评价提供理论参考。
B.1 场景分布模型
通过对百度Apollo提供的近三万条真实交通流轨迹数据进行统计分析,采用最大似然估计等方法,拟合得到自由交通流状态下的场景分布函数[1][2]。
其中,非路口环境下的车头时距分布为负指数分布:
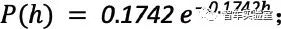
非路口环境下的车速分布满足对数正态分布:
路口环境下的车速分布符合对数正态分布:
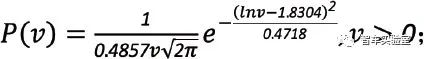
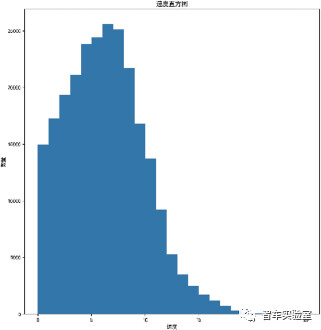
图B.1 路口环境下的车速直方图
在行人鬼探头场景中,超参数{θ }={v ,v ,d ,h },其中v 为主车速度,v 为跟车速度,h 为车头时距[3],为主车与路端设备之间的距离,d2为后车与路端设备之间的距离并可以通过d2=d1+abs(v2-v1)h2计算。其中两车速度v ,v 均满足对数正态分布,行人速度假设为常值,h 的分布为负指数分布[4],根据真实车辆数据状态分布,推算d1的分布近似满足均匀分布。
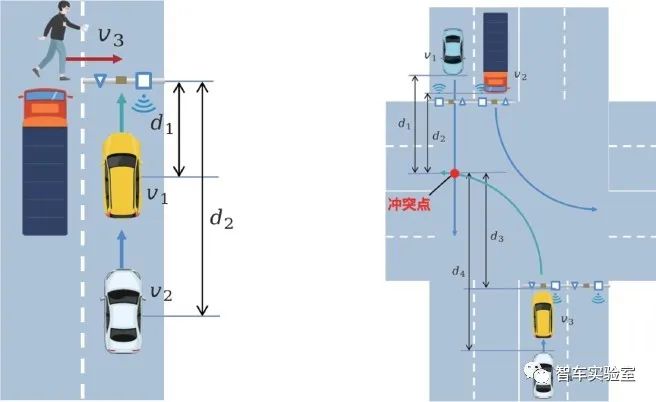
图B.2 行人鬼探头 图B.3 无保护左转
在无保护左转场景中,超参数{θ0 }={v1,v2,v3,v4,d1,d2,d3,h4},其中v1为对向直行车1的速度,v2为遮挡车2的速度,v3为左转车3的速度,v4为车4跟车速度,定义左转车3与对向直行车1之间发生碰撞的点为冲突点[5],突点所在平行直线的距离,h4为车3与车4间的车头时距。根据真实车辆数据状态分布,v1,v2,v3的分布均满足对数正态分布,d1,d2,d3假设为均匀分布,h4的分布为负指数分布。
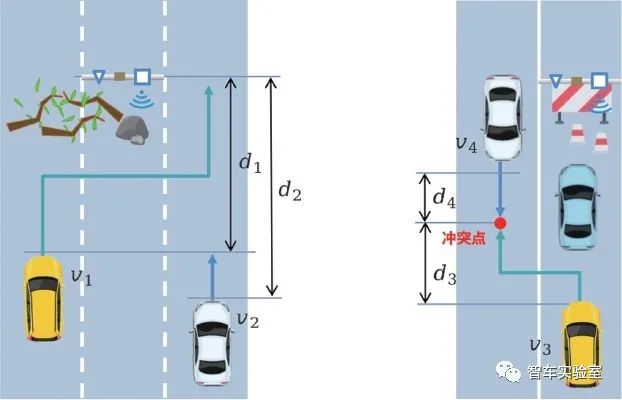
图B.4 异常障碍物 图B.5 异常交通情况
在异常障碍物场景中,超参数{θ0}={v1,v2,d1,d2},其中v1为左侧车道的前车1的速度,v2为右侧车道的后车2的速度,d ,d 分别为车1与车2距离路侧设备之间的距离[6]。两车速度v ,v 均满足符合城市道路速度规范的均匀分布[7][8],根据真实车辆数据状态分布,推算d ,d 的分布近似满足均匀分布。
在异常交通情况下,超参数{θ0}={v1,v2,v3,v4,d3,d4},其中v1,v2分别为异常情况发生前,驶过该区域的其他非自动驾驶车辆车1与车2的速度,车5为停在修路路段前的静止车辆,v3为需决策在车5后是否违反交通规则进行“逆行”的车3的速度,v4为对向转入车辆车4的速度。定义车3与对向车4之间发生碰撞的点为冲突点,d3为车3与冲突点的距离,d4为对向车4与冲突点的距离。根据真实车辆数据状态分布,可推算出v ,v ,v ,v 的分布近似满足对数正态分布,1/d ,1/d 近似满足泊松分布[2][9][10]。
-
感知模型
在本实验中,感知模型将RGB相机与深度相机采集的图像作为输入,基于语义分割模型对当前车辆所处环境进行理解,并将感知结果提供给后续的决策模型作为参考。一般情况下,感知结果以像素级的语义标注和异常标注作为输出形式。
语义分割模型遇到训练集分布之外的异常输入时无法准确地进行预测,使得语义分割模型难以被部署到对安全性要求极高的场景。为了能够检测到异常的物体,如道路上意料之外的障碍物,需要使用异常检测算法。在训练异常检测算法时,需要在异常检测数据集上验证模型效果。
常用的异常检测数据集包括Fishyscapes[11],RoadAnomaly[12],StreetHarzards[13],Road Obstacles[14],Lost and Found[15]等;图片中的异常部分可能来自物体图片数据集,也可能为场景中的真实异常物体。
现有的异常检测算法中,以Synboost[16]为代表的方法融合了语义分割、图像生成等多个模型的结果, 具有较好的效果但是运行速度较慢;以SML[17]为代表的方法对现有语义分割模型的输出结果进行归一化调整,从而得到异常分割的阈值,具有更高的实时性。本实验采用SML方法进行异常分割任务。
SML方法[17]提出对语义分割模型的输出分数进行标准化。分割算法将一个像素分类为一个物体类别时,像素确实属于此类别的情况下模型的预测分数会比像素属于异常输入时的分数要高。但并不是所有像素属于预测的类别的情况下,模型输出的分数都比像素属于异常时高。因此,SML算法提出对输出的分数进行标准化,从而使得这两种情况下模型输出的分数差别更大、重叠更少、更容易区分。为了对输出的分数进行标准化,算法在训练集中统计每个类别的模型输出分数的均值 μc
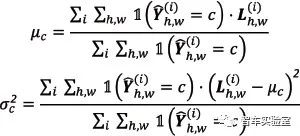
上式中i 表示第i 个训练样本。
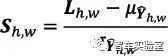
取得均值与方差后,模型在测试集上运行时,对模型的输出分数进行标准化。每个位置 h,w 的标准化最大分数Sh,w 定义为:
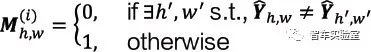

在对分数进行标准化之后,模型的预测的边缘仍然会错误地含有一些假阳和假阴。为了解决边缘的错误预测,该算法对边缘的预测结果进行迭代抑制。该算法逐渐将临近的非边缘区域的标准化最大分数传播到边缘区域。具体来说,该算法将边缘的宽度定为一个特定的值并逐渐缩小这个值。给定一个在第i 次迭代时的边缘宽度ri 和语义分割输出,位于每个 h,w 的像素非边缘面具 为:
上式用于计算每一个满足 。
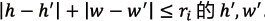
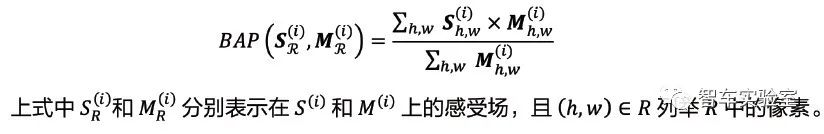
接下来,算法使用边缘自觉平均汇集。对于一个边缘像素 b 和它的感受场 R,边缘自觉平均汇集(BAP) 定义为:
因为边缘抑制只能更新边缘像素,在非边缘区域的异常值无法被边缘抑制解决。该算法使用扩张平滑来解决非边缘区域的异常值。因为高斯核能够去除噪声,边缘抑制使用高斯核。通过已知的标准差σ 和大小为k 的卷积过滤器,在 i,j 位置的核权

定义为:
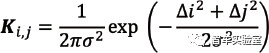
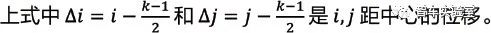
车路协同场景下,车端与路端同时部署一个SML模型,首先根据路端相机的位姿以及深度信息将路端的像素级异常检测结果先投影到世界坐标系下,然后根据车端相机的位姿,将世界坐标系下的异常点再投影到车端视角下;对车端自身和路端投影到车端的两套语义分割结果,如果路端和车端一致认为某一点是异常,或者路端和车端对某一点的语义分割结果不一致,两种情况均将对应点处理为异常。实验结果显示,采用上述方式的车路协同下的感知模型性能优于单车条件下的感知模型性能。
-
决策控制模型
本实验的决策控制模型基于CARLA自有决策与控制方法改进而得[3]。针对不同驾驶状态,分别定义了对应的决策规划策略。状态之间的转换根据感知模块提供的估计与全局规划器提供的拓扑信息执行。自动驾驶车辆的当前位姿、速度和规划的导航点被传送给PID控制器,以执行对转向、油门和制动器的控制。对仿真器中可能出现的慢响应时间情况,PID控制器表现出了较好的鲁棒性。5种不同驾驶状态下的决策控制模型定义如下:
-
沿道路行驶状态下,局部规划器基于语义分割算法计算的本车道掩码,选择与道路右边缘保持固定距离的系列点作为后续导航点;
-
路口左转状态下,由于车道线缺失、目标车道较远且前视摄像头视野有限,需要使用相对复杂的决策规划策略:先以预定义的倾斜角计算驶向路口中心的导航点,以提升对目标车道的识别;随后,从路口中心向目标车道规划出平滑轨迹;
-
右转状态下,使用与左转类似的策略。但由于右转的目标车道更近,需规划的导航点更少,且只需前向信息而无需附加补充信息;
-
路口直行状态下,决策控制策略与沿道路行驶状态类似;
-
急停状态下:在检测出动态障碍物的累积概率高于预定义阈值,即具有潜在危险时,系统将激活急停模式,向控制器请求紧急中断连续控制。
-
评价模型
评价模型由车辆安全评价模型、行人安全评价模型和通行效率评价模型三部分组成。
其中车辆安全评价模型是在车辆模型为单车智能、车路协同感知及车路云一体化的情况下,基于真实数据生成的场景初始参数模拟行车状况,输出特定场景大规模仿真结果中的行车碰撞率,并推算至绝对概率[18][19]。基于统计的车辆碰撞概率为
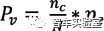
,其中 为车辆发生碰撞的试验次数,N为实验总次数 为场景出现概率。行人鬼探头场景下的碰撞率推算自CIDAS数据库,描述的是自动驾驶车辆与行人和其他车辆的碰撞概率;其余场景的出现概率基于小规模真实数据采样推算得出。
行人安全评价模型是基于真实的数据库,通过风险因素分析,得出碰撞车速与行人重伤或死亡概率的关系模型[20][21][22]。此模型应用于场景一对行人安全的评估。
其中逻辑回归-风险曲线模型是一种通用的行人安全评价模型[23][24]。在Jacques Saadé[20]的研究中,用于逻辑回归-风险曲线模型函数拟合的数据基于VOIESUR Accident Database的真实数据集,VOIESUR Accident Database数据来源于8500个交通事故致行人死亡或受伤的事件[20][25],剔除车辆本身失控致行人受伤或死亡的案例,并以行人受伤或死亡是由于第一次车辆碰撞而非二次碰撞,以及车辆没有从行人身上碾压过的情况作为筛选条件,最终筛选出了5163个满足条件的案例。其中有2483个案例有充足的信息,其它案例使用了修正系数来补偿信息缺失,使数据可以最大化利用。
在风险因素分析方法方面,该逻辑回归-风险曲线模型通过计算优势比的方法,分析了不同的撞击速度、行人年龄、撞击的身体部位、车辆生产年份、引擎盖高度和行人行走方向的存在与否对死亡率产生的影响。其中,撞击速度(V)和行人年龄(A)是最鲁棒且显著的影响因素[20]。此外Jacques Saadé
[20]在研究工作中设计了2*2实验,测试了两种自变量关系(V+A,V2+A)和两种回归模型(Comprehensive-loglog, Logit)形成的四种组合在预测行人死亡率或重伤率的准确性上的表现: 评价标准采用赤池信息量准则(AIC)和误差项。
表B.1 回归误差分析结果[20]
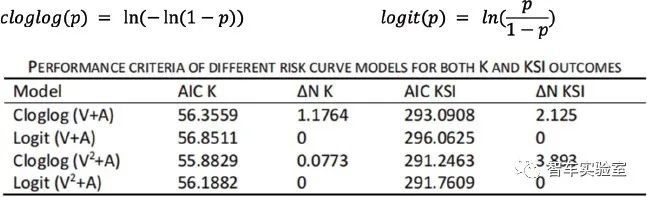
实验结果表明损失最小的组合为Logit(V2+A)。最终得出撞击速度(V)与行人年龄(A)对行人死亡率 或重伤率影响的关系模型及其风险曲线:
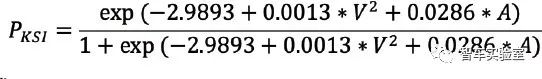
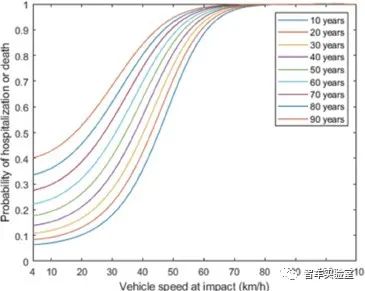
图B.6 行人安全风险曲线[20]
基于Jacques Saadé [20]的研究工作,在仿真实验条件下,我们引入碰撞发生概率(P ),由条件概率h
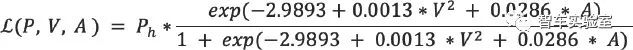
公式可得,行人安全性评价模型在仿真实验场景一中的函数公式为:
其中行人年龄(A)采用由真实数据统计得到的高频出行事故人群年龄(40岁)[26],由上述行人安全性评价模型函数公式可知,碰撞发生概率(Ph)与撞击速度(V)越小,行人受伤或死亡的概率越小,证明用于测试的仿真实验模型的安全性越高。
通行效率评价模型评估了对象车辆在单车智能、车路协同感知及车路协同决策控制下行驶过四种场景的目标通行区域所需时间(T)。在每个场景下,记录对象车辆进入划分区域和离开划分区域的时间戳以计算通行时间,具体的划分区域定义如下:场景一中定义为包含左车道静止车辆与整个十字路口的矩形区域;场景二中定义为十字路口及各方向距人行横道2车身距离的区域;场景三中定义为主车最早可能产生变道行为位置到完全超越异常障碍物位置的矩形区域;场景四中定义为进入单车道区域位置到完全驶离单车道位置的矩形区域。此评价模型主要量化不同决策控制方案对交通通行效率的影响。对于发生碰撞的单次实验计算交通事故的处理时间,与车碰撞情况下的通行时间取平均值33分钟[27], 与人碰撞情况下的通行时间取平均值35分钟,该数据根据公开交通数据集计算[28]。
综合安全与效率评价模型,可以更完备地考量单车智能、车路协同感知和车路协同决策控制在具体场景下的表现[29][30][31]。



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
