




 广告
广告





















































AIR学术|浙大特聘研究员廖依伊:面向自动驾驶仿真平台的混合现实图像生成

12月28日下午,由DISCOVER实验室主办的第18期AIR青年科学家论坛顺利开展。本期活动荣幸地邀请到了浙江大学特聘研究员廖依伊博士,为我们线上做题为《面向自动驾驶仿真平台的混合现实图像生成》的精彩报告。

讲者介绍
廖依伊,浙江大学特聘研究员。2013年获西安交通大学学士学位,2018年获浙江大学博士学位。2018至2021年,她在德国马克思普朗克智能系统研究所 (MPI-IS) 及德国图宾根大学从事三年博士后研究,师从CVPR PAMI青年研究员奖得主Andreas Geiger教授。期间,她作为第一负责人搭建了国际上首个包含大规模语义及样例标签、面向自动驾驶的近1TB大规模数据集KITTI-360。她的研究兴趣为三维视觉,包括场景重建、场景语义理解、可控图像生成。累计发表文章二十余篇,包括TPAMI、TIP、CVPR、ICCV、NeurIPS等多篇国际顶尖期刊/会议论文。担任CVPR2023、3DV 2022、BMVC 2021-2022的领域主席。
报告内容
廖博士为我们介绍了为构建自动驾驶仿真平台的最终目标所展开的一系列工作。报告开始,廖博士为我们介绍了现有面向自动驾驶仿真平台的研究现状。其中,CARLA以及Virtual KITTI虽然能够提供逐像素标签信息,但是仍然构建成本高并且与现实世界存在Domain Gap。

因此,廖博士设想直接从现实世界数据直接构建自动驾驶仿真平台,这样做有两个优点:
-
不再有Domain Gap的问题;
-
不再需要投入大量人力物力设计场景和物体。
但是仍然存在三个挑战:
-
如何从现实世界数据直接构建仿真平台逐像素高精度场景信息;
-
假如我们已经构建了高精度场景,那么如何获取场景逐像素语义信息也是一项非常具有挑战的任务;
-
对于一些现实世界数据没有出现的物体,仿真平台很难重建出来。
基于这三个挑战, 廖博士团队展开了一系列工作。

一、自由视角高精度实时渲染
这个方向的研究主要是要实现对现实世界采集的数据直接进行任意视点的高精度实时渲染。
要解决这个问题,廖博士团队主要采用的是NeRF方案,不过NeRF在渲染一张图需要百万次的查询来实现自由视点的高精度渲染,导致渲染效率极低。基于这个问题,廖博士团队提出了KiloNeRF方案,大幅提升了NeRF的渲染速度从而使其满足自动驾驶仿真平台需求。 KiloNeRF通过将大MLP换成多个独立的小MLP,并且在渲染的时候,采用Empty Space Skipping(ESS)和Early Ray Termination(ERT),从而提升NeRF渲染速度。
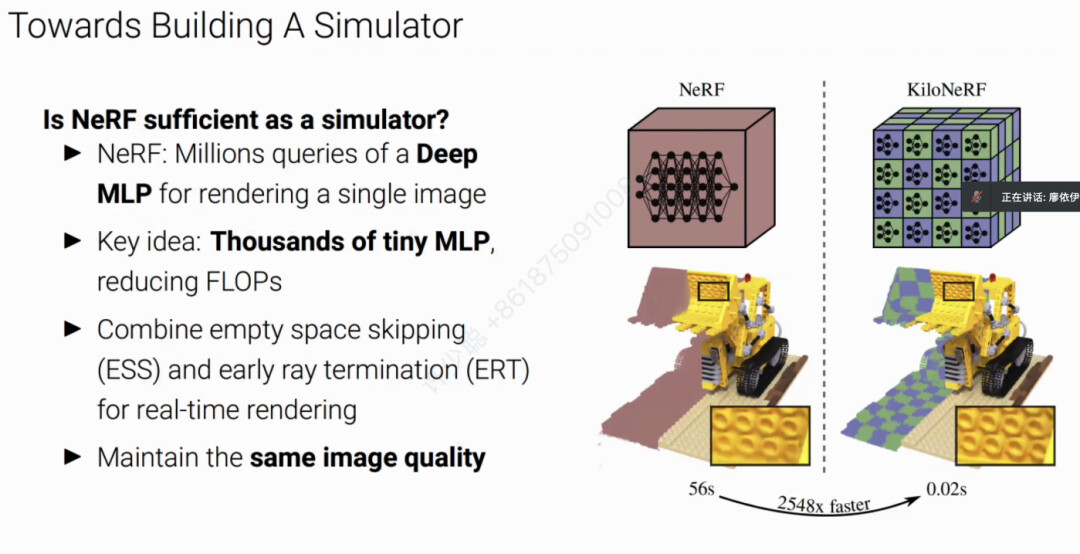
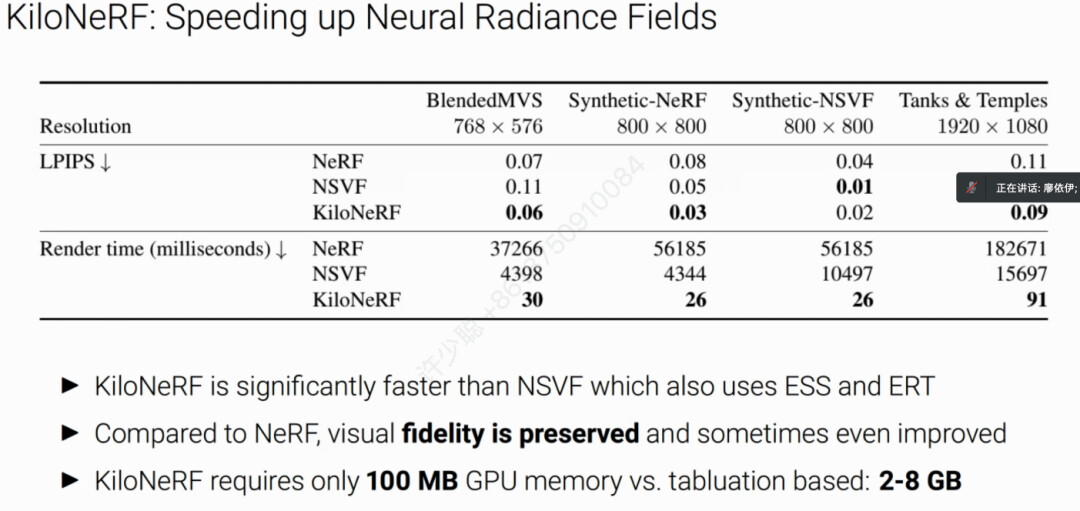
定量结果和定性结果表明KiloNeRF渲染速度和以及渲染的图像质量均优于传统方法,并且显存占用少于基于制表缓存的加速方法。 而后,廖博士为我们分析常用加速NeRF渲染速度的策略。
加速渲染本质上就是降低渲染需要的浮点运算次数。假如每个像素光线需要采样K个点,渲染每个像素需要L次运算,那么渲染一张高为H宽为W像素的图像需要的浮点运算次数就是
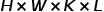
。要提升渲染速度,主要是从减少K(ERT, ESS和 Adaptive Sampling)和减少L(制表缓存类的方法 或者更小的MLP)入手。通过分析,廖博士团队发现现有的NeRF加速方法都需要消耗比较大的内存。为了解决内存和渲染时间之间的冲突,廖博士团队基于视角之间的变化是连续这一发现提出SteerNeRF,充分挖掘视角时间的时序关系从而减低W,H和K提升渲染速度且保持较低内存占用。
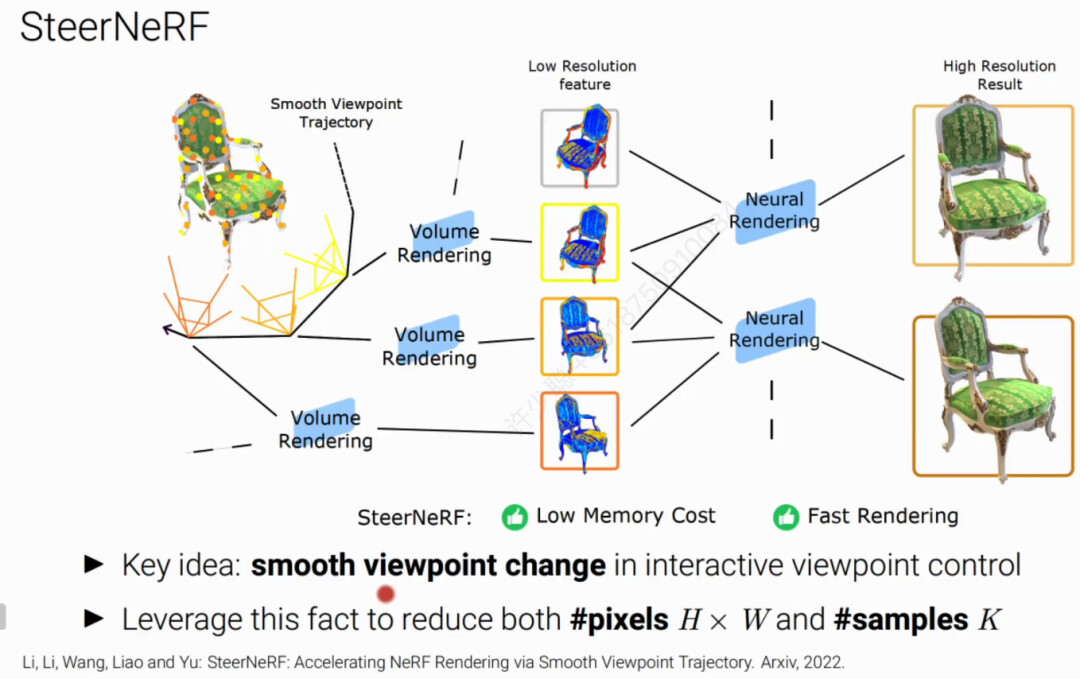
SteerNeRF先用Volume Rendering渲染低分辨率的特征图,再用Neural Rendering结合前帧和当前帧来渲染高分辨率的图像。
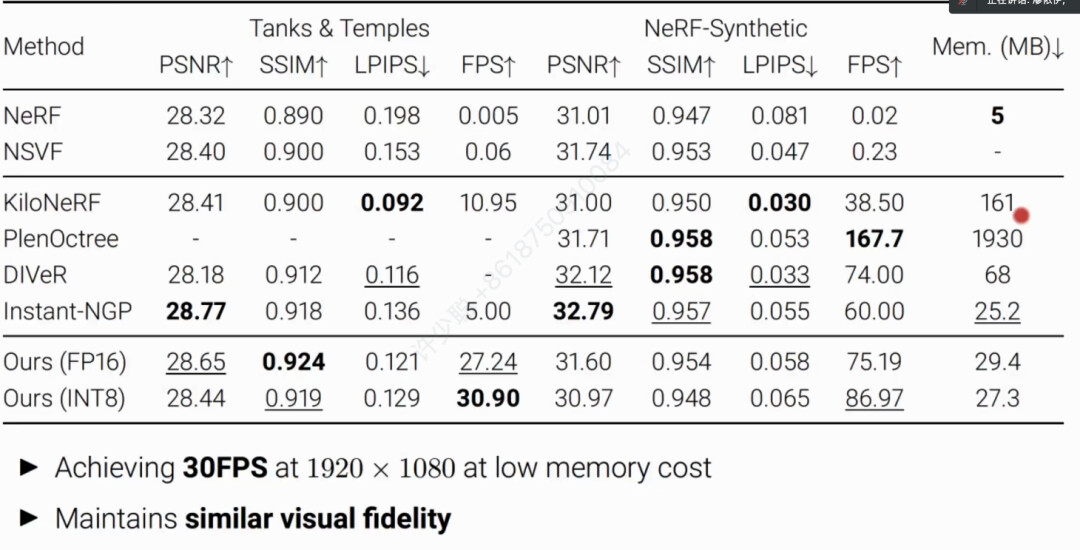
实验定性结果和定量结果表明 SteerNeRF不仅在大分辨率数据集(Tanks &Temples)能够达到实时渲染而且占用内存较小。
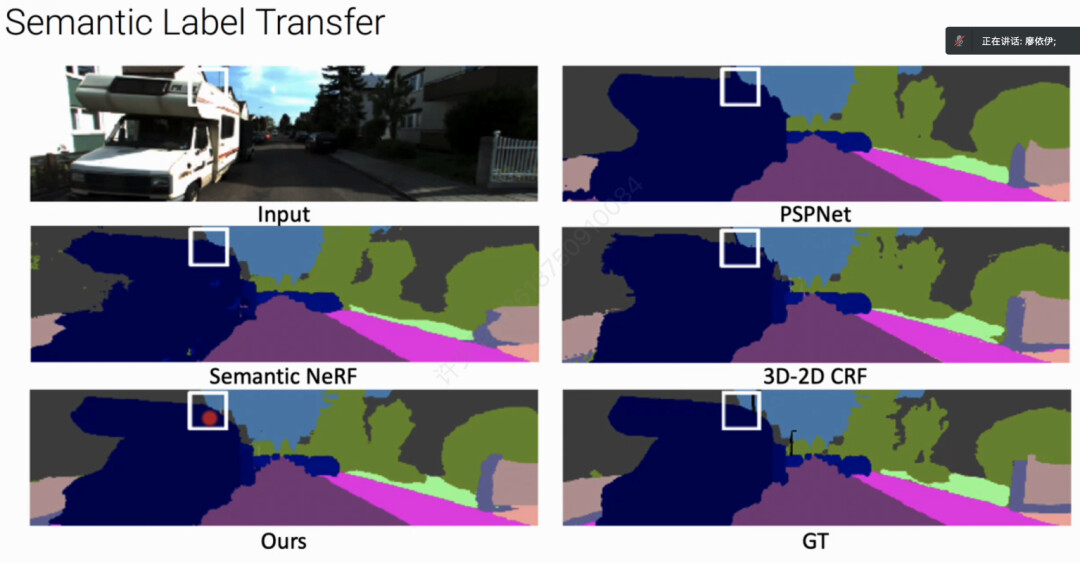
二、自由视点高精度语义迁移
KiloNeRF或者SteerNeRF搭建仿真器很自然的就能解决仿真器的domain gap问题。但是这两个工作还是没办法提供自由视点的语义信息。因此,廖博士为我们介绍了其团队最新的工作:Panoptic NeRF。

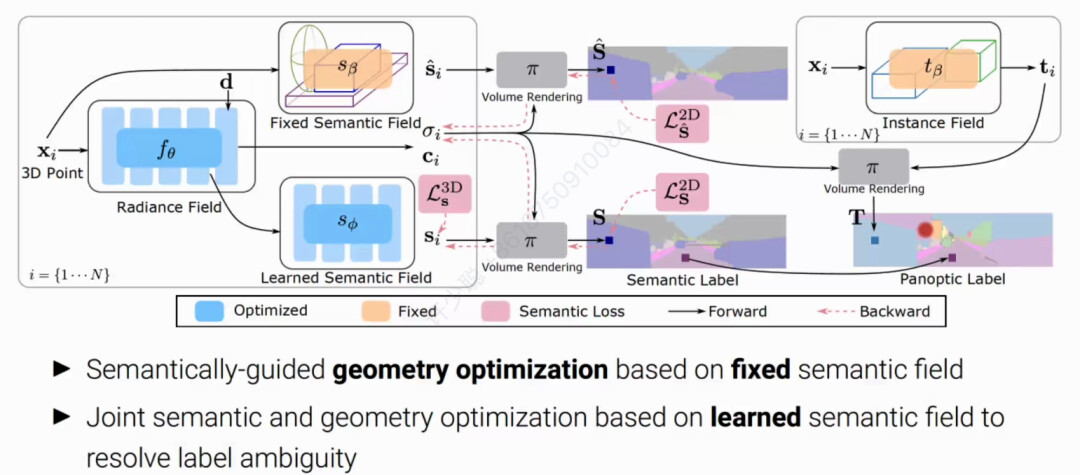
Panoptic NeRF 主要通过一个固定的语义场来提升几何重建质量,通过一个可学习的语义场来解决三维标注框相交区域的歧义。
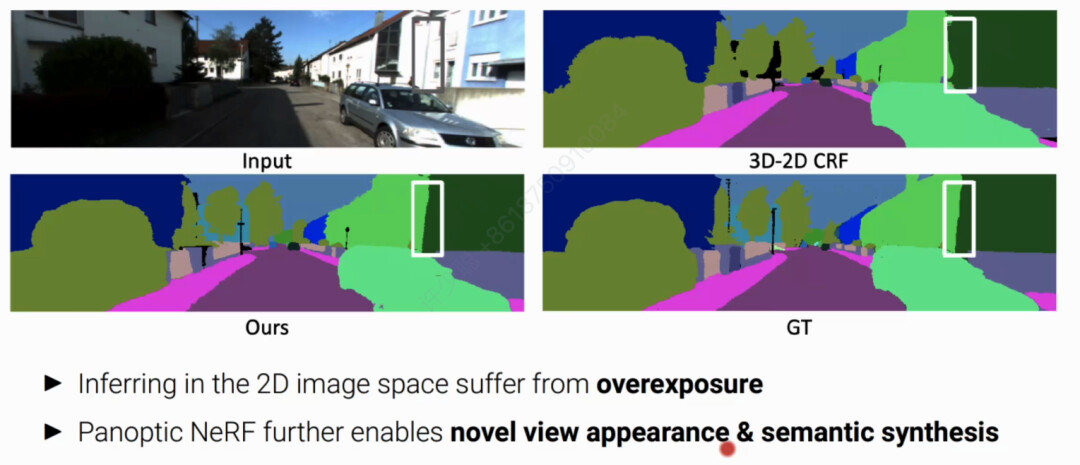
三、仿真器新物体生成
这个研究方向主要解决如何在仿真器里生成新物体。
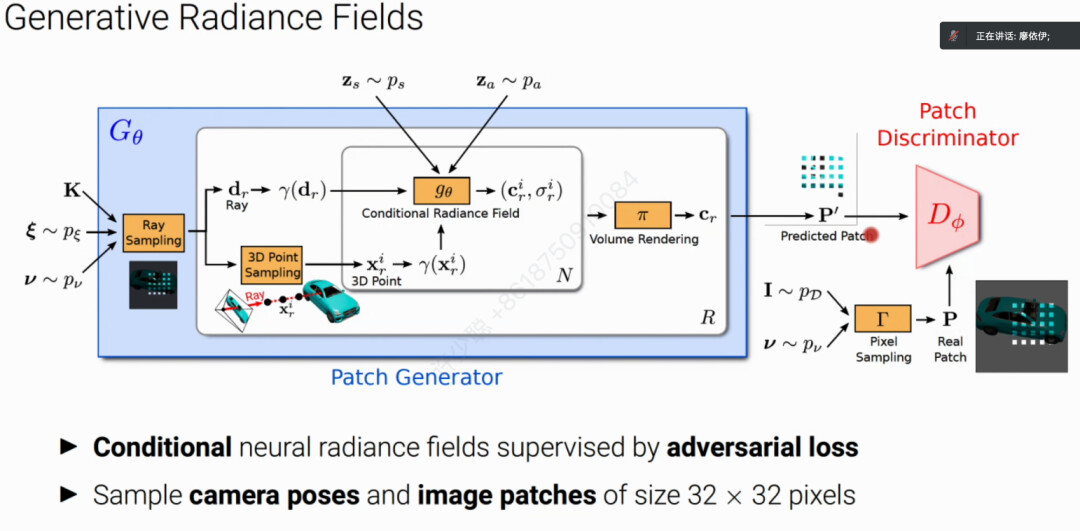
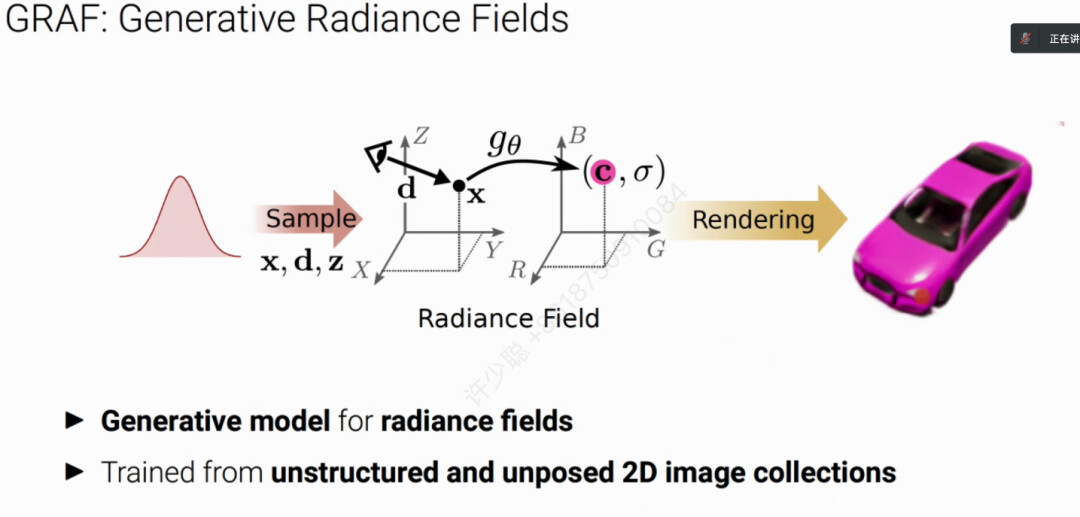
廖博士团队提出了GRAF方案,即输入像素点x和相机Pose D以及从高斯分布采样的隐变量z来生成渲染新物体。

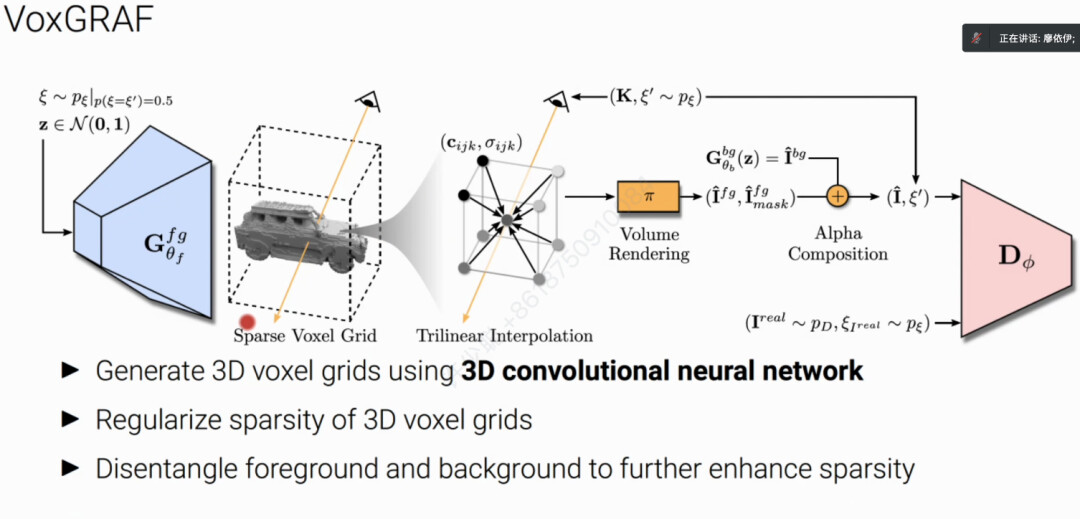
GRAF在高分辨率渲染的图像质量还是有些许不足,于是廖博士团队又提出了VoxGRAF技术,不仅渲染分辨率高、渲染速度快,而且能够保证多视角的一致性。
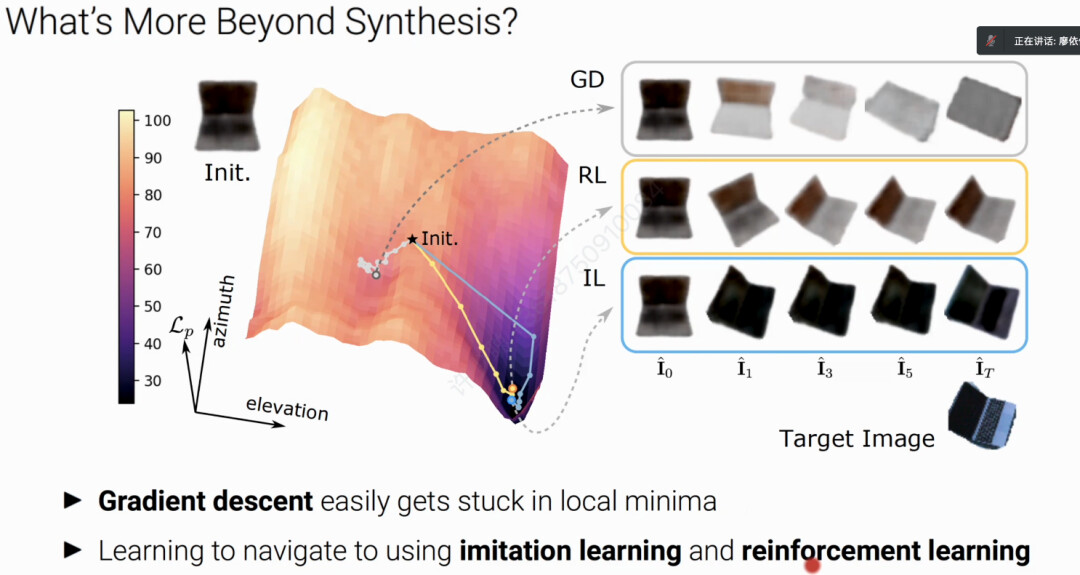
廖博士又为我们介绍其发表在ECCV2022的一篇利用GRAF等生成模型进行位姿估计的工作。任务定义为给定一个初始图像,找到一个latent code来生成目标图像,廖博士介绍了用不同搜索策略找目标状态从而克服收敛到局部最优解的问题。
最后廖博士展望了实现自动驾驶仿真平台未来三个极具价值的探索方向:城市级别的自由视点渲染,虚实图像融合以及基于仿真器训练测试自动驾驶下游任务的模型。报告结束后,廖博士与参会的老师和同学对报告所涉及的领域进行了热烈的讨论。
四、报告总结

文稿撰写 / 许少聪
排版编辑 / 王影飘
校对责编 / 黄 妍
- 下一篇:电驱动总成及相关标准简介
- 上一篇:保险杠动态谐振机理分析和怠速抖动控制研究



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
