




 广告
广告





















































面向智能汽车测试的弱势群体服饰色彩研究

全部事故样本中,危险场景包含公路、城市街道、郊区以及农村道路。自然环境涵盖:晴、阴、雨、雪等常见天气和早、中、晚等不同光照条件;VRU群体包括行人、自行车骑行者、电动车骑行者、摩托车骑行者等。厘清数据样本中所包含的各类事故现场,从而可构建智能汽车测试危险场景下道路弱势群体服饰颜色数据库。

图1 VRU典型重大交通事故表1 VRU样本分布情况
注:自行车、划分为非机动车的电动车等中低速二轮交通工具,统称二轮车;高速二轮交通工具,统称摩托车。
2 样本服饰色彩数据处理
2.1色彩空间选取
颜色聚类是模式识别和计算机视觉中的一个重要领域,每一种颜色可以通过色彩空间下的数学标准进行定义,自动紧急制动系统中行人服饰颜色识别通过颜色在色彩空间的各项数值进行分析。由于对所模拟的VRU上、下衣颜色进行标准化定义,需要统计分析大量数据,为此,通过聚类算法对相关数据的像素点进行统计处理,从而得出现实交通环境下VRU服饰的代表颜色。典型的色彩空间可以分为两大类:基色空间和色亮分离空间。其中,RGB(Red-Green-Blue)、CMY(Cyan-Magenta-Yellow)以及CMYK(Cyan-Magenta-Yellow-BlacK)属于基色空间,YUV、YCC和LUV属于色亮分离空间。广为人知的三基色RGB色彩空间是与人体视觉系统对色彩感知最为契合的[9],但三基色之间的相关程度过高,细微的颜色变化即可能导致几个参数的显著波动。由于行车环境的复杂性,不同光照场景下同样颜色的RGB值可能会产生明显差别,因此,RGB色彩空间内像素点的距离不能作为衡量颜色相异性的标准,这也限制了聚类算法在RGB色彩空间的使用。LUV色彩空间具有视觉统一性,即使微小的色彩波动在空间中也能准确表达,用作图像处理时,效果优于RGB色彩空间。本研究采用基于国际照明委员会(CIE)XYZ空间变换得到的LUV空间进行像素数据的处理分析,使得像素点分布可以更加清晰地展示样本的聚集情况,各聚类组的聚点更具合理性。
综上所述,RGB色彩空间虽便于理解,但用于聚类则不具备线性化特性。因此,本文通过LUV空间对色彩数据进行聚类处理分析,以RGB空间对原始色彩数据及最终的代表性颜色数据进行呈现。
2.2 颜色数据转换
在解决色彩聚类问题时,常见色彩空间有线性化的RGB、YUV空间、LUV空间和改进型LUV空间。Dong[10]和Matkovic[11]对这4种色彩空间进行了深入研究和讨论,其中改进后的LUV空间在复杂环境下的表现更好,通过对亮度参数的调整,使得空间更加线性,可以有效提高聚类结果的代表性。
基于文献[10]~[12]的研究结果,选用改进的LUV空间作为聚类算法的执行基础,并列出RGB空间向CIELUV空间的转换公式。
方式如下:
第1步,RGB到CIEXYZ。
人眼有响应短、中、长3种不同波长范围光线的感受器,因此原则上3个参数即可描述颜色感觉。CIEXYZ表色系统是在RGB系统的基础上,通过数学方法选用3个理想的颜色来代替实际的三原色,3种原色的分量称作三色刺激值,分别以X、Y和Z表示。依据国际电信联盟无线电通信部门(ITU-R)的BT.709标准,通过数值固定的3×3矩阵可以将RGB空间的像素点转换到CIEXYZ空间。

第2步,CIEXYZ到CIEL*u*v*。
以CIEXYZ空间下的像素数据计算空间变换的中间变量u′和v′
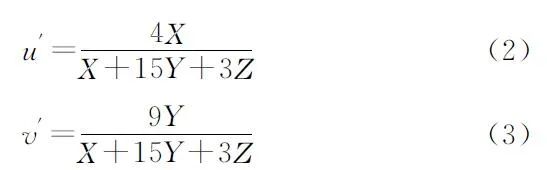
第3步,CIEL*u*v*到改进L*u*v*。在复杂环境下实现色彩的感知,LUV空间下的亮度参数应与■Y成正比。因此,改进的LUV最终转换为

式中:L*表示图像中的亮度;u*和v*分别表示图像中的从绿色到红色与从蓝色到黄色的色度;u′n和v′n均为空间变换的中间变量,文献[10]给出了详细的计算公式。对样本中目标人群的服饰颜色数据进行聚类分析,获取最具代表性的颜色参数,将颜色数据通过以上步骤即可由RGB空间格式向LUV空间格式进行转换。2.3 K-means算法的逻辑获取大量样本中最具代表性颜色的像素参数,本质上属于数据挖掘过程,即从大量数据中辨识出隐藏的有价值信息。处理颜色分割问题时,欧氏距离是一种被广泛使用的判据[12],定义如下

K-means是常用的基于欧氏距离的聚类算法,其认为2个目标的距离越近,相似度越大。通过评估数据间在同一距离度量尺度下的相似度,划分出不同的聚类组,并通过聚类组的特征进行信息的提取。K-means算法流程如下:设有n个像素点数据。
(1)选取k个像素点作为初始聚类中心;
(2)计算n个像素点与聚类中心点间的距离;
(3)将各个像素点归入距离其最近的聚类中心;
(4)更新聚类中心并计算各像素点至中心距离;
(5)重复上述过程至距离最小平方差不变;
(6)获得最终聚类中心。通过聚类算法对色彩数据进行总结,获取最具普适性的VRU服饰颜色。该算法的优点在于复杂度低且聚类效果显著,处理大数据集时能够保证较好的伸缩性。2.4 最佳聚类数组的确定采用K-means聚类算法进行颜色像素点集的数据分析,首先需将所有数据点分为k个聚类组,通过计算求得使得组内所有像素点与之距离平方和最小的中心点,即为聚点。传统的K-means聚类算法预先人为给定聚类组数,但聚类组数的给定对聚类结果的影响较大。本文选取文献[13]、[14]中提出并定义的Silhouette参数作为最优聚类数的选取和评价指标。Silhouette实质上是一种比例性质的指标,通过类内紧密性和类间分离性的比例计算,评估聚类组数以及聚类结果的有效性。类内紧密性指聚类组中各像素点之间的紧密程度,类间分离性代表不同聚类组之间像素点的分离程度。算法首先给出一定数目范围的聚类组数,并对不同给定的聚类组数分别计算Silhouette参数组的值。根据参数的大小来决定对聚类组数的选择。一般情况下,算法定义的聚类组数最小为2。假设A是通过聚类算法得到的一个聚类组,a(yi)指的是聚类组A中第i个像素点与其余所有像素点之间相异度的平均值。d(yi,Ci)为一个数组,指的是聚类组A中的像素点i与除A以外任一聚类组Ci中各像素点之间相异度的平均值。定义b(yi)=d(yi,C),也是数组d(yi,Ci)的最小值,即C是拥有和像素点i最高相似性的聚类组。则聚类组中的像素点i对应的Silhouette参数值s(yi)为
由此获得每一个像素点的Silhouette值,所有像素点的Silhouette值构成Silhouette数组,对数组内的数值进行平均值计算,即可得到这种聚类组分割情况下的评估指标。基于以上定义可以发现,Silhouettes能够反映算法获取的各聚类组之间的类内紧密性和类间分离性,进而帮助实现类内紧密性高、类间分离性好的聚类效果。在本研究中,聚类组数将依次设定为2到10,并分别计算有效性指标Silhouettes值进行相应评估,选取Silhouettes值最大的聚类组数作为算法的目标组数。
获得最佳聚类组数后,通过聚类算法对样本数据进行处理,获取各聚类组中聚点在LUV空间格式下的各项参数,随后再通过空间的反向变换,将聚点参数由LUV空间格式转换到RGB格式,从而得到最具代表性的颜色数据。
3 服饰色彩聚类结果
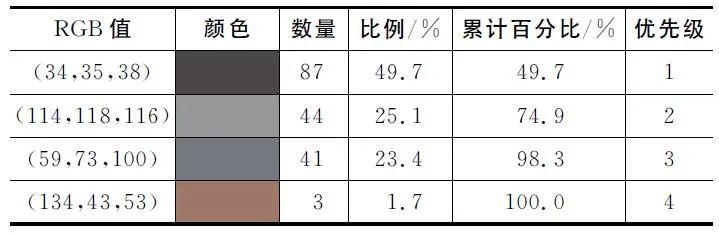
VRU群体的上、下身服饰色彩在颜色空间中具有不同分布,因此,应分别对上、下衣装的颜色进行数据分析。由于儿童样本量太少,且儿童在现实交通事故中伤亡比例较低,因此本文将针对成人代表服饰颜色进行研究。为了使色彩能够直观呈现,下文表格中列出的结果将从LUV色彩空间转换回RGB色彩空间。






最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
