




 广告
广告





















































生成式AI,ChatGPT和自动驾驶的技术趋势漫谈

作者简介:Dr. Luo,东南大学工学博士,英国布里斯托大学博士后,是复睿微电子英国研发中心GRUK首席AI科学家,常驻英国剑桥。Dr. Luo长期从事科学研究和机器视觉先进产品开发,曾在某500强ICT企业担任机器视觉首席科学家。
元宇宙是人类社会网络化和虚拟化,通过对实体对象对应生成数字”智能体”来构建一个人机共存的新社会形态。元宇宙零距离社会里的社会计算,是一种数据行为的社会计算和人机交互的社交计算。
对于生成式AI行业,我们也许可以将其核心演进趋势定义为人机智能的社交计算,简单表述为通过完成类似通用的问题答问Q&A系统任务,以及特定内容的高清图像生成,来促进各行业转型升级,尤其是数字内容生产,人机交互与问答(聊天,教育和金融服务,医疗诊疗,自动驾驶等)行业,从而进一步打通元宇宙中真实世界与虚拟世界的社交沟通能力。
对于自动驾驶ADS行业,我们也许可以将其核心演进趋势定义为群体智能的社会计算,简单表述为,用GPU/NPU大算力和去中心化计算来虚拟化驾驶环境,通过数字化智能体(自动驾驶车辆AV)的多模感知交互(社交)决策,以及车车协同,车路协同,车云协同,通过跨模数据融合、高清地图重建、云端远程智驾等可信计算来构建元宇宙中ADS的社会计算能力。
生成式AI
生成式AI大模型,包括近两年推出的ChatGPT和Stable Diffusion,能够比较满意地完成类似通用的问题答问Q&A系统任务,以及特定内容的高清图像生成。对各个行业来说,呈现着一定程度的颠覆性意义和充满未来想象的商业空间,可以促进各行业转型升级,尤其是数字内容生产,人机交互与问答(聊天,教育和金融服务,医疗诊疗,自动驾驶等)行业。
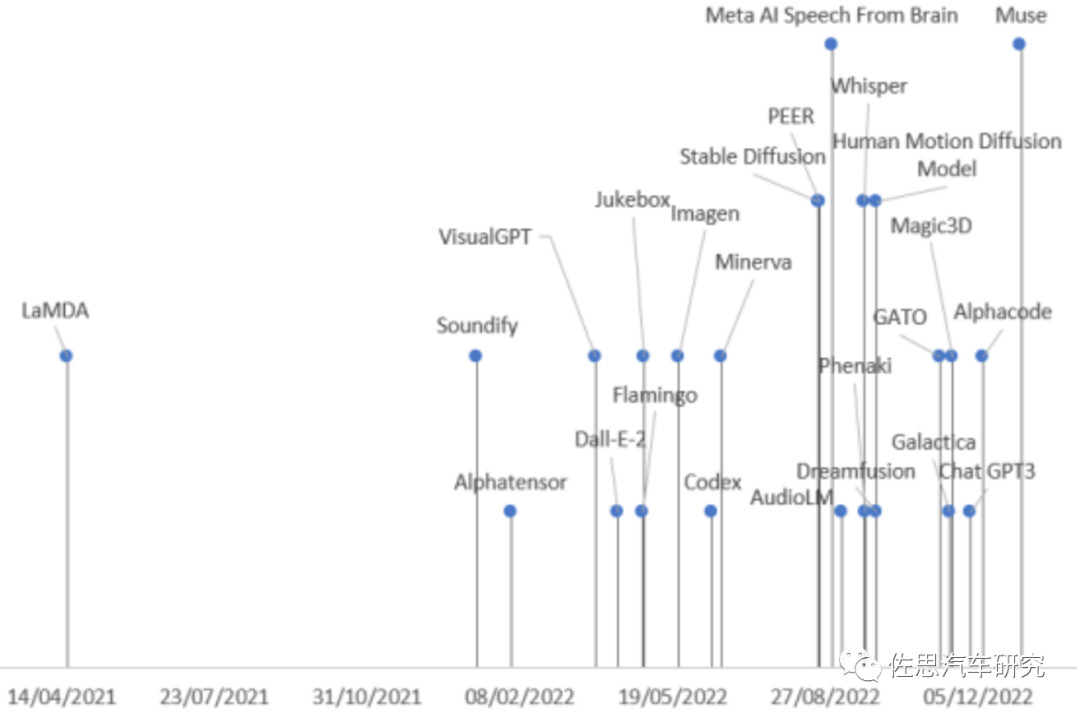
图1: 生成式大模型发布时间轴(G-Brizuela, 2023)
如图1所示,2021-2022年,我们很幸运地迎来了DNN大模型的一轮大爆炸,即所谓的生成式AI(AIGC)浪潮。在演进中的生成式AI大模型包括:
-
Text-to-Texts:ChatGPT3, PEER, LaMDA, Speech From Brain
-
Text-to-Image: Starry A.I.(GAN-based), DALLE-2 (Diffusion-based), Stable Diffusion, Muse, Imagen
-
Text-to-3D-Image: Dreamfusion, Majic3D
-
Image-to-Text: Flamingo, VisualGPT
-
Text-to-Video: Phenaki, Soundify
-
Text-to-Audio: AudioLM, Jukebox, Whisper
-
Text-to-Code: Codex, Alphacode
-
Text-to-Scientific: Galactica, AlphaTensor, Mineva, GATO
上述的主流生成式AI大模型,如果从开发到最终拥有关系角度,可以简单分类如下:
-
OpenAI: DALLE-2, ChatGPT3, Jukebox, Whisper
-
Google: Imagen, DreamFusion, Minerva, LaMDA, Muse, Phenaki, AudioLM
-
DeepMind: Flamingo, AlphaTensor, AlphaCode, GATO
-
meta AI: PEER, Galctica, Speech From Brian
-
Runway: Stable Diffusion, Soundify
-
nVidia: Magic3D

从上述几个生成式AI大模型的能力对比分析(G-Brizuela, 2023),以及图2中ChatGPT在不同场景的逻辑错误对比,我们也许可以简单总结以下:
-
创造性任务:Text-to-Text, Text-to-Image, Text-to-Video
➤ 准确率仍然远低于预期,有待成熟完善。
-
个性化任务:Text-to-Audio
➤ 有限数据集问题,大规模参数训练困难,有待成熟完善。
-
科学类任务:Text-to-Science, Text-to-code
➤ 有限数据集问题,大规模参数训练困难,准确率低于预期。
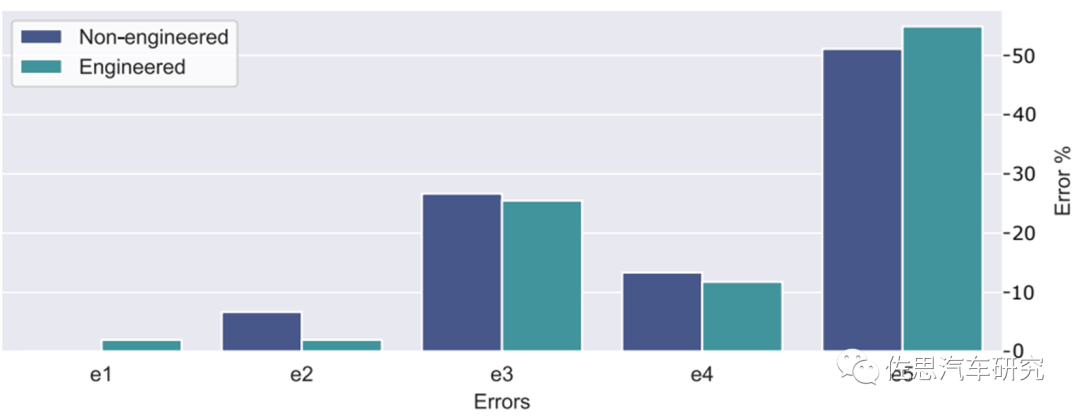
图2: ChatGPT在不同场景下的逻辑错误对比
ChatGPT
ChatGPT(Generative Pre-trained Transformer)是OpenAI开发的一款生成式AI模型,它结合了监督学习和强化学习方法,通过对话的方式来进行交互:依据用户的文本输入来做多种语言的智能回复,简文或者长文模式,其中可以包括不同类型的问题答复,翻译,评论,行业分析,代码生成与修改,以及撰写各类计划书与命题书籍等等。各类生成式AI模型也可以联合调用来提供丰富的人机对话的能力。生成式AI模型多需要海量的参数,来完成复杂的特征学习和记忆推理,例如ChatGPT模型参数为1750亿。
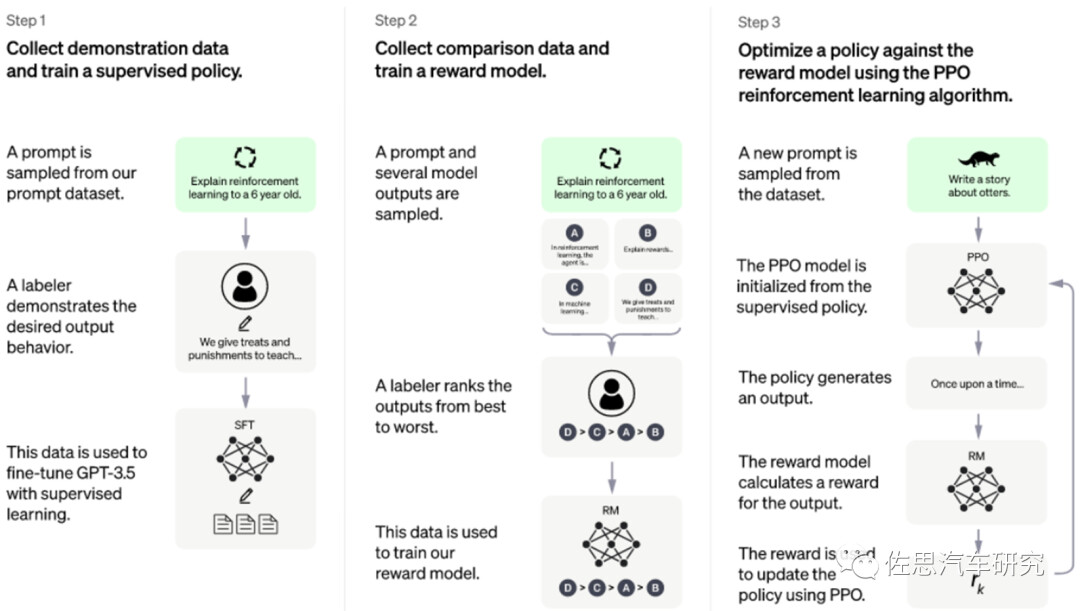
图3: ChatGPT模型的训练流程(G-Brizuela, 2023)
如图3所示,ChatGPT模型结合了监督学习和强化学习方法,采用了基于人类反馈的强化学习RLHF训练方法,与此同时采用了迁移学习(或者叫自监督学习)的训练方法,即通过预训练方式加上人工监督进行调优(近端策略优化PPO算法)。RLHF训练方法确实可以通过输出的调节,对结果进行更有理解性的排序,这种激励反馈的机制,可以有效提升训练速度和性能。在实际对话过程中,如果给出答案不对(这是目前最让人质疑的地方,可能会错误地引导使用者),可以通过反馈和连续谈话中对上下文的理解,主动承认错误,通过优化来调整输出结果。给出错误问答的其中一个主要原因是缺乏对应的训练数据,有意思的是,虽然缺乏该领域的常识知识和推广能力,但模型仍然能够胡编乱造出错误或者是是而非的解答。ChatGPT的另外一个主要缺陷是只能基于已有知识进行训练学习,通过海量的参数(近100层的Transformer层)和已有的主题数据来进行多任务学习,目前来看仍缺乏持续学习或者叫做终身学习的机制,也许下一代算法能够解决这个难题,这也需要同步解决采用终身学习新知识引发的灾难性遗忘难题等等。
自动驾驶:多智能体间的社交决策
在真实的交通场景里,一个理性的人类司机在复杂的和拥挤的行驶场景里,通过与周围环境的有效协商,包括挥手给其它行驶车辆让路,设置转向灯或闪灯来表达自己的意图,来做出一个个有社交共识的合理决策。而这种基于交通规则+常识的动态交互,可以在多样化的社交/交互驾驶行为分析中,通过对第三方驾驶者行为和反应的合理期望,来有效预测场景中动态目标的未来状态。这也是设计智能车辆AV安全行驶算法的理论基础,即通过构建多维感知+行为预测+运动规划的算法能力来实现决策安全的目的。而会影响到车辆在交互中的决策控制的驾驶行为包括驾驶者(人或AV)的社会层面交互和场景的物理层面交互两个方面:
-
社会层面交互:案例包括行驶车辆在并道、换道、或让道时的合理决策控制,主车道车辆在了解其它车辆的意图后自我调速,给需要并换道的车辆合理让路来避免可能的冲突和危险。
-
物理层面交互:案例包括静态物理障碍(静态停车车辆,道路可行驶的边界,路面障碍物体)和动态物理线索(交通标识,交通灯和实时状态显示,行人和运动目标)。
ADS群体智能的社会计算,对这种交互/社交行为,可以在通常的定义上扩展,也就是道路使用者或者行驶车辆之间的社交/交往,即通过彼此间的信息交换、协同或者博弈,实现各自利益最大化和获取最低成本,这一般包括三个属性(Wang 2022):
-
动态Dynamics:个体之间间和个体与环境之间的闭环反馈(State, Action, Reward),驾驶人/智能体AV对总体环境动态做出贡献,也会被总体环境动态所影响。
-
度量Measurement:信息交换,包括跨模数据发布与共享,驾驶人/智能体AV对道路使用者传递各自的社交线索和收集识别外部线索。
-
决策Decision:利益/利用最大化,理性来说道路使用者追求的多是个体的最大利益。
显然,交通规则是不会完全规定和覆盖所有驾驶行为的,其它方面可以通过个体之间的社交/交互来补充。人类司机总体来说也不会严格遵守交通规则,类似案例包括黄灯初期加速通过路口,让路时占用部分其它道路空间来减少等待时间等等。ADS通过对这类社会行为的收集、学习与理解,可以部分模仿和社会兼容,通过Social-Aware和Safety-Assured决策,避免过度保守决策,同时提供算法模型的可解释性、安全性能和控制效率。具体实现来说,可以采用类似人类司机的做法,依据驾驶任务的不同,使用环境中不同的关注区域ROI和关注时间点,以及直接或间接的社交/交互,采用类似概率图模型和消息传递等机制来建模。
如何用生成式AI来提升自动驾驶ADS的产品竞争力
目前来看,生成式AI有可预期的未来,但依旧任重而道远,尤其是数据的多样性收集,如何从多模态海量知识里学习和融合各种知识,理解人类的使用需求,从上下文学习中,通过生成的方式来解决各类实际任务。对于跨行业技术推动而言,生成式AI采用的自监督学习训练方法以及可以有效生成多类图像视频的能力,已经开始在机器视觉任务中和自动驾驶的感知决策任务中得到应用,可以有效填充自动驾驶场景覆盖不足的Corner Case问题。下面将简单列举几个典型应用案例来讨论一下生成式AI采用的核心技术在机器视觉和自动驾驶行业的应用前景。
1、基于生成式AI的图像数据拓展
机器视觉任务,包括自动驾驶领域,一个核心的挑战是数据多样性分布不平衡(Dataset Bias)问题。采用生成式AI模型,可以生成或者基于已有数据集进行有效拓展(Image Augmentation)。一个典型的应用案例,例如采用Stable Diffusion模型的语义指导的图像拓展SIP模型,其架构如图4所示。
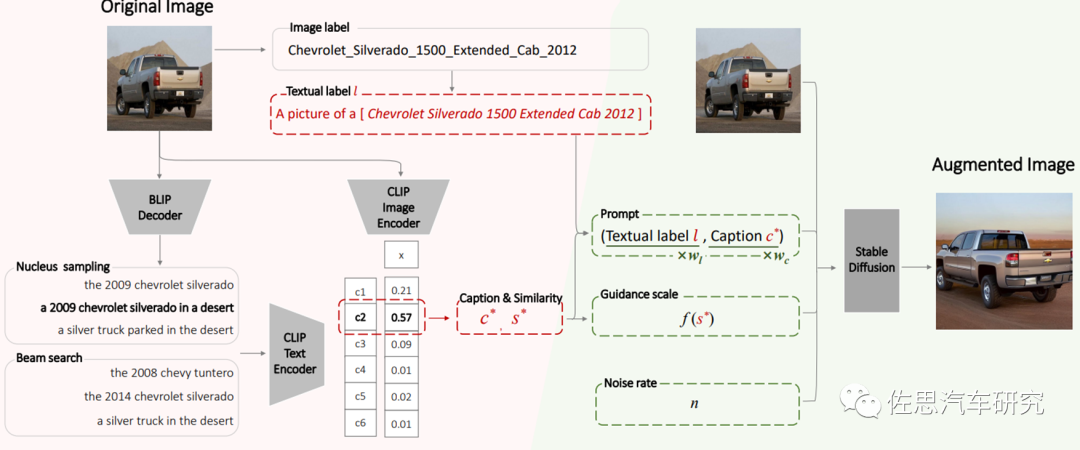
图4: 采用Stable Diffusion模型的语义指导的图像拓展案例(Li, 2023)
常用的图像数据拓展多采用平移,变换,拷贝黏贴等策略,有像素级或者特征级等几种类别,这些多数只是对图像或者目标进行局部处理,很难在保持语义信息和多样性之间找到平衡,而SIP模型的优势可以通用的生成式AI大模型,通过图像的标签和标题来指导Image-To-Image高清图片生成,对比常用处理算法而言,性能也会有几个百分点提升。
2、行动(action)可解释的自动驾驶
对于自动驾驶技术而言,DL-based方法由于模块化的设计和海量数据贡献,性能占优,但如何能够提供安全能力和大规模部署,需要解决几个挑战:在保证性能基础上改善可解释性;在不同的驾驶个体,场景和态势下继续增强模型的推广能力。
显然生成式AI是可以用来对自动驾驶的每个决策过程进行多任务的文本解释。图5是一个行为可感知可解释的模型ADAPT设计架构案例。ADAPT算法模型为每个场景可以提供用户友好的自然语言的描述和对于每个决策控制指令/行为的比较合理的一系列解释和推断。这种实时的行为的文字表述和推断,某种意义上会让乘客了解车辆的状态,理解ADS决策如何以安全行驶为第一生产要素,以及决策的透明度和易于被使用者理解接受。
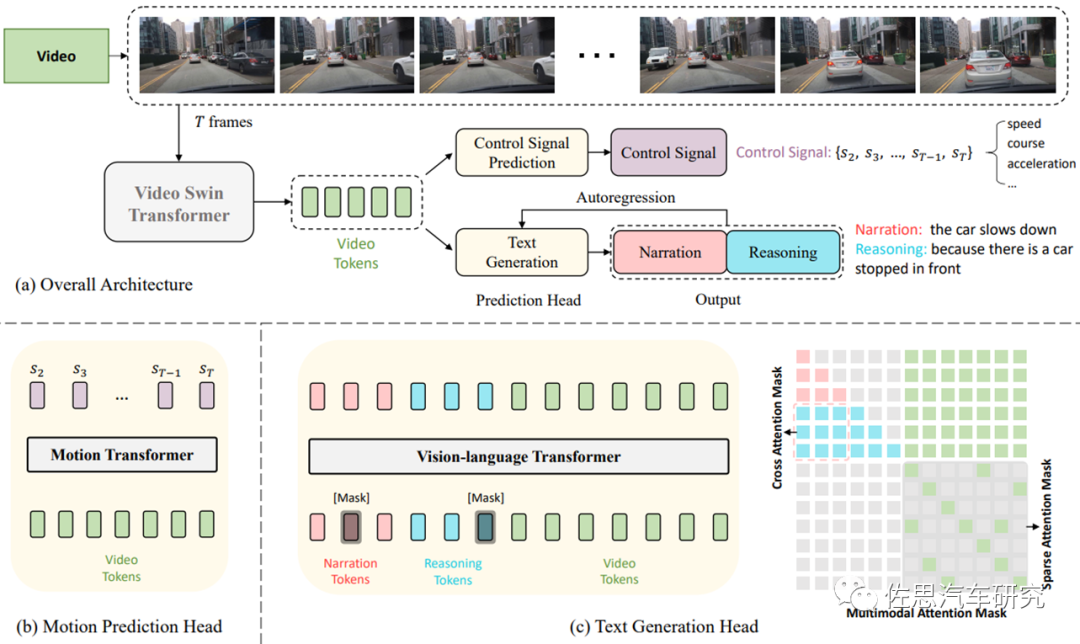
图5: ADAPT:Action-aware Driving Caption Transformer (Jin 2023)
ADAPT算法模型的量化分析如图6所示。ADAPT所提供的基于语言的可解释性,虽然只是一种简单的尝试,但未来对ADS能否被社会完全接受,有非常重要的意义。

图6: ADAPT算法模型的量化分析(Jin 2023)
参考文献:
[1] R. G-Brizuela an etc., “ChatGPT is not all you need: a State of the Art Review of large Generative AI models”, https://arxiv.org/abs/2301.04655v1
[2] S. Frieder and etc., “Mathematical Capabilities of ChatGPT”,https://arxiv.org/pdf/2301.13867.pdf
[3] B. Li and etc., “Semantic-Guided Image Augmentation with Pre-trained Models”, https://arxiv.org/pdf/2302.02070.pdf
[4] B. Jin and etc., “”, https://arxiv.org/pdf/2302.00673.pdf
[5] W. Wang, and etc., “Social Interactions for Autonomous Driving: A Review and Perspective”, https://arxiv.org/pdf/2208.07541.pdf



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
