




 广告
广告





















































如何测试和优化骨传导产品?结构声应用是关键


蓝牙耳机的应用日益频繁,但是,蓝牙耳机的使用有一个重大问题仍未解决:在嘈杂环境中,蓝牙耳机的麦克风离使用者的嘴巴更远,导致在耳机麦克风处捕获到的讲话者语音信号的信噪比显著降低。
骨传导传感器可以提高信噪比。但是如何测试和优化带骨传导传感器的耳机产品,这在之前行业内一直是一片空白。为此,HEAD acoustics 改善了头和躯干模拟器 (HATS) HMS II.3 LN-HEC (根据ITU-T P.57 [1]配备 type 4.4 人工耳 ),以对入耳式蓝牙耳机的人体结构音信号进行逼真的模拟。
本文从人体结构声测量和模拟的背景知识入手,介绍了使用结构声作为耳机信号处理中附加输入信号的潜在益处,并用测量试验和测试结果加以说明。
01、人体结构声——测量和模拟
测试耳机结构声的第一步,就必须了解耳机的骨传导传感器应该放置在哪个位置,才是让使用者声音的人体结构声传输到使用者耳中的最优路径。为此, 我们在入耳式耳机模型中放置了一个结构声传感器,并且在不同人类个体身上进行测量。目的就是为了测量空气声和结构声的单独频谱。这些测量结果让我们对个体传播差异有了大概了解,成为获取平均传递函数的基础。
除此之外, 我们采集到的信息也显示了男性和女性之间是否存在巨大差异。作为测试的一部分, 我们对11名女性和24名男性进行了测量。图1 对比了个体结构声信号与嘴参考点(MRP)的空气声信号。图2显示了这两个信号的男性讲话者和女性讲话者的平均值。这种差异主要表现在300 Hz以下的频率范围内,此时女性声音由于基频较高,往往没有任何信号能量。因此,我们选择男性平均频谱作为结构声模拟的目标频谱。
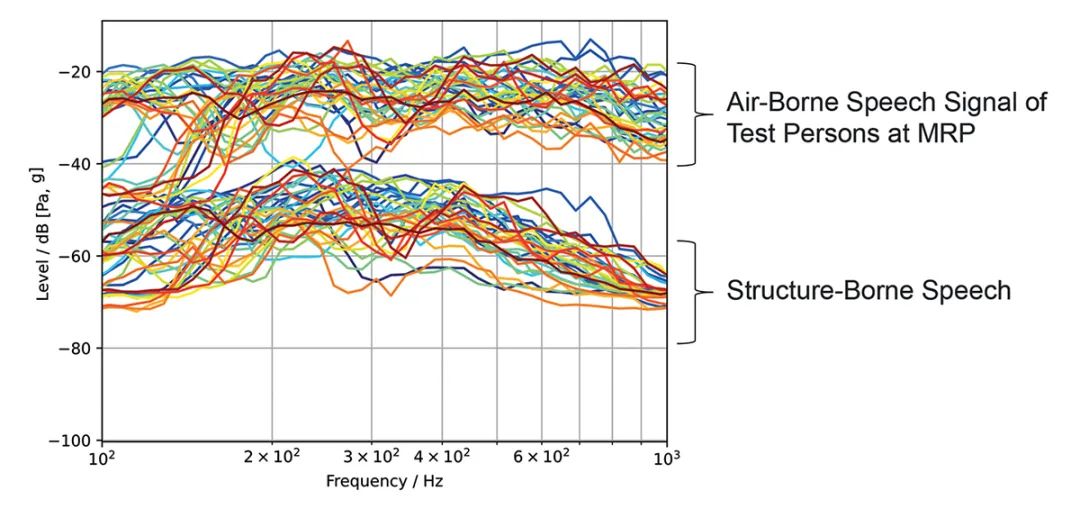
图1: 不同测试人员的个体空气声信号与嘴参考点(MRP)的个体结构声信号进行对比
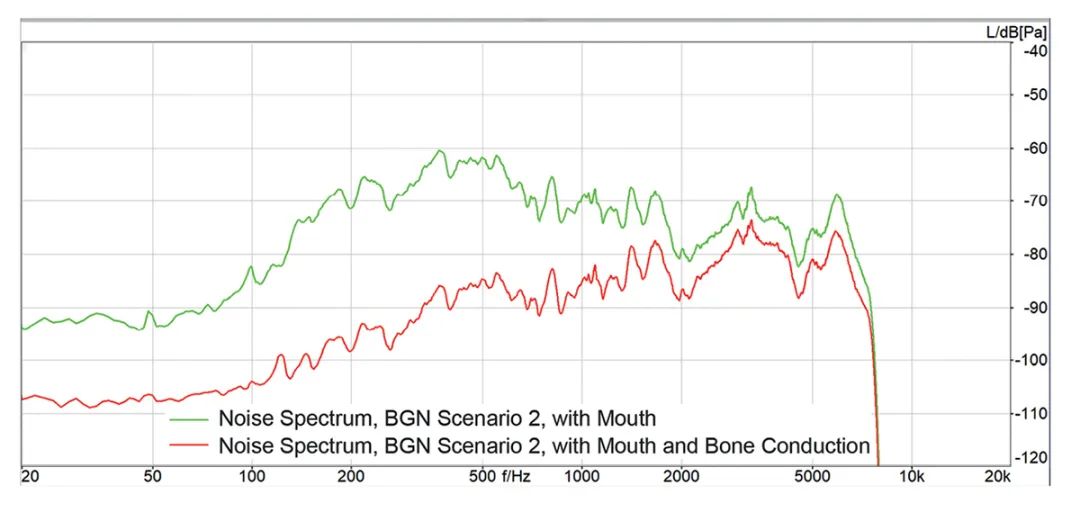
图2: 平均结构声信号与嘴参考点(MRP)的平均空气声信号进行对比
下一步是模拟人体结构声。我们在人工头HMS II.3 LN-HEC上接入了激励器,在进行人体测量的位置准确地再现了人工耳中的平均人体结构声。图3显示了新的LN-HEC人工耳的模拟结构声与平均人体结构声的频谱。请注意,由于目前可用传感器的信噪比不足,只能对3 kHz以下的结构声模拟进行精准测量。如图3所示,模拟在±3 dB的容差范围内,是可以接受的。
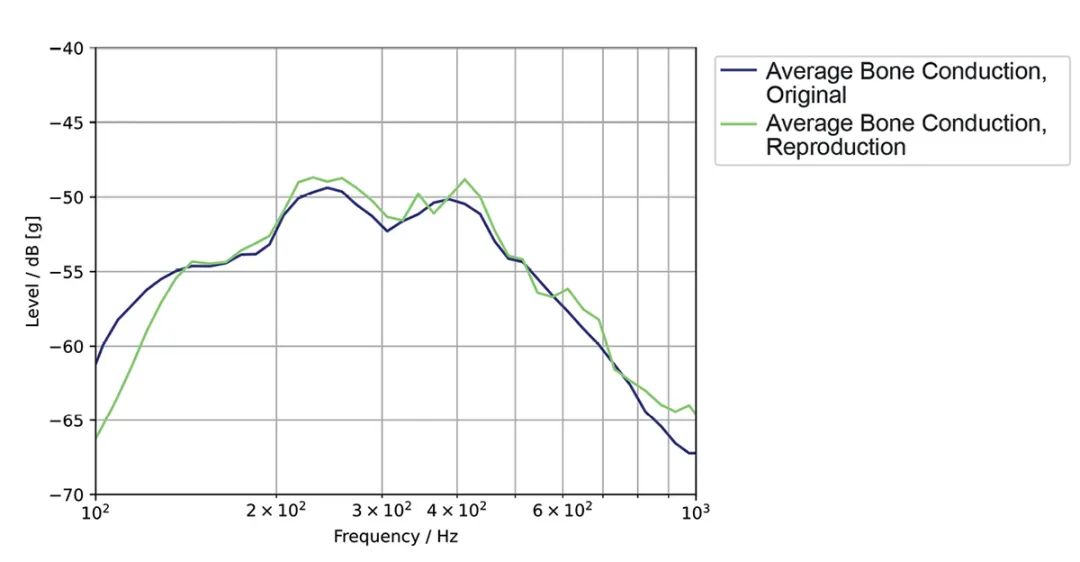
图3:模拟平均结构声与人类平均结构声对比
02、耳机信号处理和结构声的有待改进之处
耳机信号处理中使用结构声的主要目的是改善分离效果:近端讲话者和近端背景噪声的分离、近端讲话者和近端受损讲话者的分离、近端讲话者和远端讲话者的 (双讲检测)的分离。
使用结构声的第二个好处就是传输结构声信号,而非近端麦克风信号,至少在低频中是这样的。结构声几乎没有背景噪声,因此理想情况下是“噪声消除”。
图4显示了噪声消除模块收到的信号。使用结构声信号可以显著改善近端语音和受损信号的分离。在增强信号处理方面会发生什么?噪声消除模块是一种自适应滤波器,可以评估背景噪声,并通过评估其信号功率和尽量降低噪声水平等各种策略来降低背景噪声。噪声估计越精准,消除噪声效果越好。
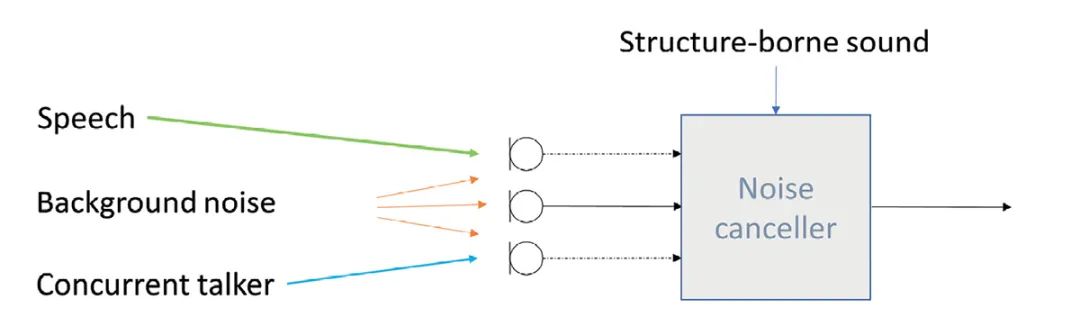
图4: 这些是近端噪声消除模块的信号
然而,分离噪声和语音是复杂的。噪声消除模块可能会无法收敛,导致语音信号降低。如果能够更好地基于结构声区分语音和噪声,则可以大幅改善自适应控制。可以冻结自适应或降低自适应速度,以此避免噪声消除模块的发散。
因此,可以提供一个带有低背景噪声的高质量语音信号。共同讲话者的行为与之类似。假设只评估戴耳机的说话者的声音的传输信号,则共同讲话者的声音就能被当做是背景噪声。
03
真实的入耳式耳机的测量结果
基于这项基础研究,我们对不同耳机进行了测量。测试设置使用的是典型的实验室基础配置——根据ETSI TS 103 224[2]标准,用八个扬声器和一个预录的背景噪声进行仿真声场模拟。人工头放置在测试房间中,并将耳机小心地戴在人工头上。所有实验使用的语音信号都基于建议书ITU-T.P501[3]。测试结果在稳定的状态下不太可能会显示出任何差异,因此我们针对骨传导模拟的性能差异创建了特定的测试序列。
如图5所示,测试序列A侧重于噪声消除模块的潜在发散。如果背景噪声突然出现,发散可能会发生。那么在这种情况下,语音和噪声也许无法再分离,并且在噪声未充分消除时,语音可能会降级。
图 5: 此处显示了测试序列A及相应分析
在语音信号停止后直接测量剩余的背景噪声可以很好地了解噪声消除性能。降噪量表示即使语音存在,噪声消除模块也能有效收敛的效率。图 6 和图 7 给出了两个示例结果。
图6: 在上行中带有和不带有骨传导模拟的设备1噪声频谱,背景噪声:根据ETSI TS 103 224用3PASS[2][4]模拟的公共噪声。
图 7: 在上行中带有和不带有骨传导模拟的设备2噪声频谱,背景噪声:根据ETSI TS 103 224用3PASS[2][4]模拟的公共噪声。
有结构声和没有结构声的剩余噪声频谱差异明显,耳机性能之间的差异亦是如此。虽然设备1仅在高达500 Hz的频域提升了高达30 dB,而设备2在传输的整个语音频谱上将背景噪声降低了多达30 dB。
实验 B
类似的测试序列可以用来评估共同讲话者存在的情况,该测试无需使用背景噪声,而是用第二个人工头模拟共同讲话者。这个实验的测试序列如图8所示。
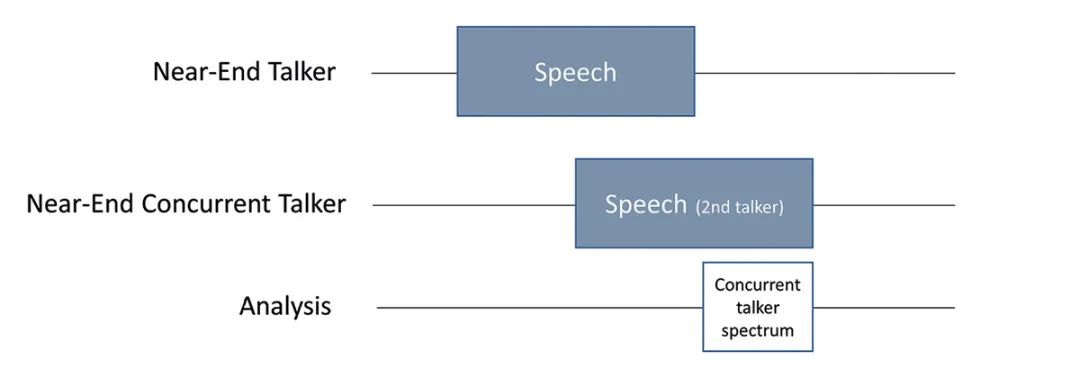
图8: 此处显示了有同时讲话者时的测试序列A及相应分析
你可以在实验中使用不同的讲话者位置。在本文中,我们讨论一个特别有意思的组合。图9显示了两个共同讲话者的位置。在位置1中,人工头直接面对戴有耳机的讲话者。在位置2上,共同讲话者对同一方向进行讲话。
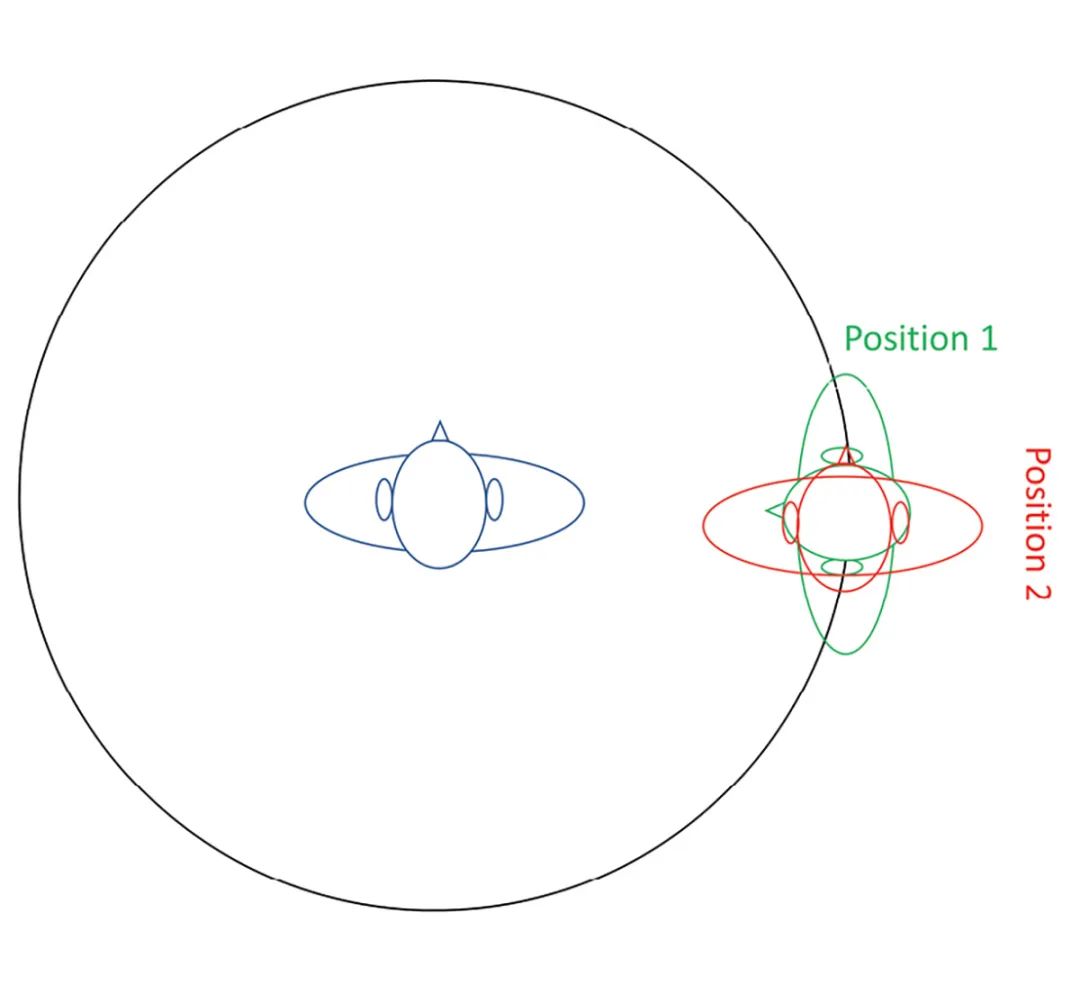
图9: 此处显示同时讲话者的两个位置
这两种场景的测试结果非常有趣。对于设备1,共同讲话者的两个位置并没有差异,也没有观察到骨传导模拟的差异和缺失。(图10)

图10: 在上行中带有和不带有骨传导模拟的同时讲话者语音频谱,同时讲话者处于位置1
设备2的结果却大相径庭。当讲话者面向戴着耳机的人并对其方向说话时,在传输上没有任何衰减。但旋转90°后,设备2就显示出了差异,第二说话者无法再对戴着耳机的人说话,并且当骨传导存在时,他的声音被判定为背景噪声(图11),衰减程度大约为10 dB。
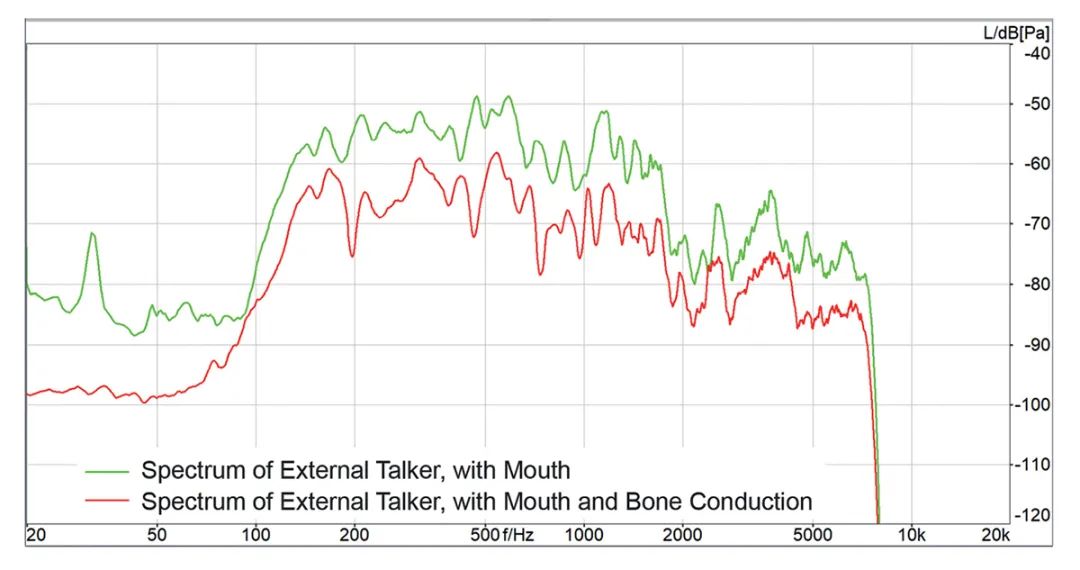
图11: 在上行中带有和不带有骨传导模拟的共同讲话者语音频谱,共同讲话者处于位置2
实验 C
第三个测试使用了图12所示的测试序列。该测试侧重于在背景噪声之后存在语音时噪声消除模块的潜在发散。在这里,我们重点介绍语音信号(S-MOS)受损和降噪性能的变化。根据ETSI TS 103 281 [6] 规定,此类基于感知的评价测试可以使用3QUEST[5]来测量这些差异。
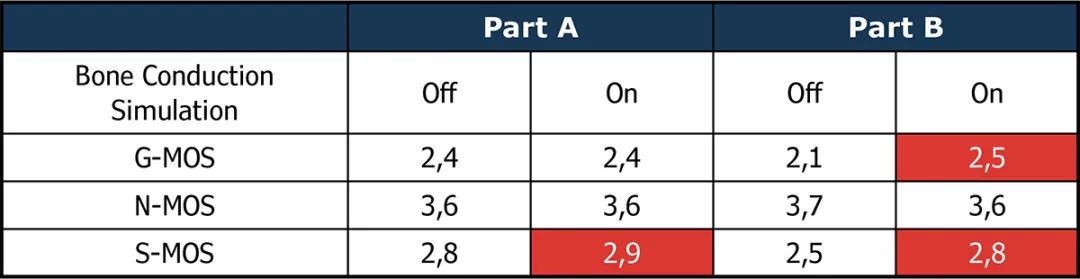
图 12: 此处显示了测试序列B和相应分析
两种设备的测试结果(表1和表2)显示,使用骨传导感应能显著改善语音质量(S-MOS)。在这两款设备中,改进了的语音检测都有助于更好地控制降噪器。当存在背景噪声的情况下,语音信号的劣化程度降低,语音质量更高。通过这种方式,可以在实验室中有效地测试和优化带有骨传导传感器的设备,以更好地调整降噪算法。
表 1: 背景噪声存在场景下设备1的S、N和G-MOS结果
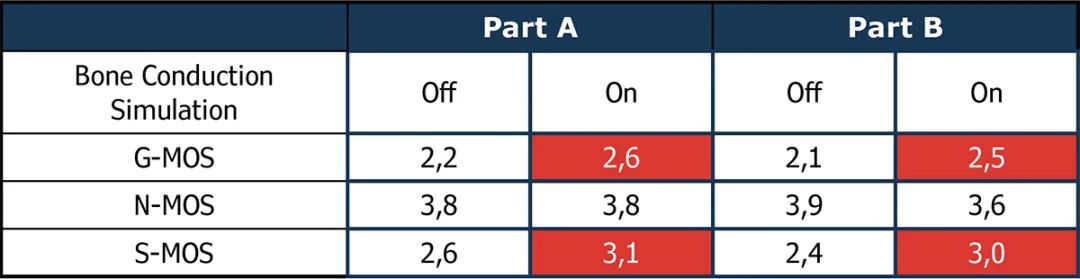
表 2: 背景噪声存在场景下设备2的S、N和G-MOS结果
实验 D: 双讲
结构声感应也能使双讲情况得到改善。在通话设备中,回声消除能防止远端收听者听到近端产生的回声。总的来说,回声消除装置(图13)是一种自适应滤波器,对回声路径进行建模,并且通过减去逆回声信号使回声信号最小化。如果不能有效地检测受损的近端语音信号,回声消除装置会发散。自适应控制质量至关重要,回声与近端讲话人信号的分离效果越好,在双讲情况下回声消除效果就越好。使用骨传导信号可以改善这种分离,因为它仅代表近端语音信号。
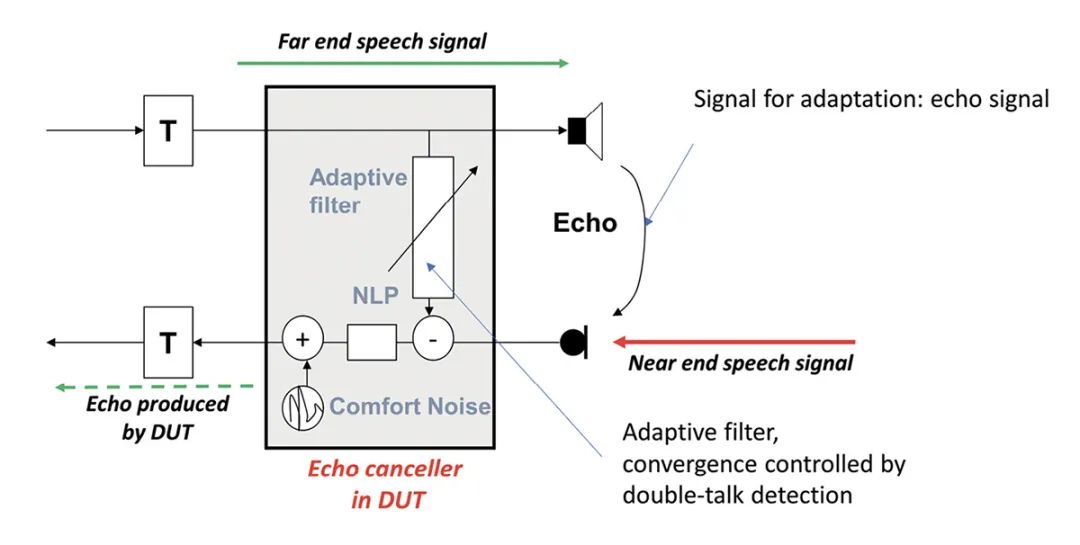
图 13: 此处显示了回声消除器的基本功能和相关信号
结构声仿真在测试现代耳机时起着举足轻重的作用。只有对人体产生的空气声和结构声模拟进行相互补充,才能全面评估和优化耳机在不同对话情形下的性能。HEAD acoustics 推出全新带有骨传导声模拟的低噪人工头HMS II.3 ViBRIDGE,内置的高灵敏度麦克风能够提供一流的动态范围:本底噪声低至16 dBSPL(A),使得该头部与躯干模拟器成为测量近耳与入耳式音频及通信设备的理想之选。麦克风的最大声压级高至 148 dBSPL(A),因此该人工头也同样适合用于测量免提系统、车内通讯系统或智能音箱中的远耳声学传感器。了解 HMS II.3 ViBRIDGE 详细信息,请点击下图。
参考目录
[1] Recommendation International Telecommunication Union (ITU) ITU-T P.57 (06/21): Artificial Ears
[2] European Telecommunications Standards Institute (ETSI) ETSI TS 103 224: Speech and multimedia Transmission Quality (STQ); A sound field reproduction method for terminal testing including a background noise database
[3] Recommendation ITU-T P.501: Test signals for use in telephony and other speech-based applications
[4] HEAD acoustics datasheet: 3PASS
[5] HEAD acoustics datasheet: 3QUEST
[6] European Telecommunications Standards Institute (ETSI) ETSI TS 103 281: Speech and multimedia Transmission Quality (STQ); Speech quality in the presence of background noise: Objective test methods for super-wideband and fullband terminals
(本文编译自发表于 2023年1月audioXpress文章, 作者:Dr. Hans W. Gierlich)
作者简介:

Hans W. Gierlich 于1983年在亚琛工业大学的通信工程研究所开始了他的职业生涯。1988年2月,获得电气工程博士学位。1989年,加入 HEAD acoustics并担任副总裁。 自1999年以来,一直担任HEAD acoustics电信部门的负责人。2014年,被任命为董事会成员。 Hans主要从事声学、语音信号处理及其感知效果、QOS和QOE主题、测量技术、语音传输和音频质量。 他积极参与各种标准化机构,如ITU-T、3GPP、GCF、IEEE、TIA、CTIA、DKE和VDA。任欧洲电信标准协会(ETSI)“语音和多媒体传输质量”技术委员会副主席,2016年至2020年担任主席。2021被评为ETSI院士。
- 下一篇:时域传递路径优化分析
- 上一篇:航裕电源助力第30届测试与故障诊断技术研讨会



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
