




 广告
广告





















































ChatGPT 框架带给自动驾驶规划任务的启发

轨迹规划是自动驾驶算法中的一个重要任务,其目的是根据车辆当前的状态和环境信息,确定车辆的行驶路线传递到控制模块以实现自动驾驶。而这个问题是非常复杂的,其难点包括了以下几个方面
1. 引言
01 不确定性
自动驾驶汽车需要在实时变化的交通环境中做出决策,但这些环境是充满不确定性的。例如,突然出现的障碍物、交通拥堵等情况都可能影响决策的正确性。而车辆驾驶事件具有“长尾效应”和“小概率事件”特点,为算法带来巨大挑战。
02 多样性
不同的驾驶场景、路况和驾驶习惯会导致决策的多样性。例如,在遇到交通堵塞时,有些驾驶员会选择等待,而有些则会选择绕路。因此,如何处理不同的决策情况成为规划问题的难点之一。
03 安全性
自动驾驶汽车需要保证安全性,如车辆控制系统的故障、路况不良、交通事故等安全问题都可能影响到运动规划的准确性和安全性。因此,开发算法需要综合考虑这些因素,并采取相应的安全措施和风险管理措施,以确保车辆的安全和可靠性。
04 实时性
自动驾驶汽车需要在实时变化的交通环境中做出决策,这需要算法能够快速地响应,并在短时间内做出正确的决策。
2022 年 11 月 30 日发布的 ChatGPT 的框架思路为我们的进阶开发带来了崭新的思路。Chat-GPT(Chat Generative Pre-trained Transformer) 基于 2017 年提出的 Transformer 结构与大模型的预训练过程,通过人类反馈强化学习 (RLHF, Reinforcement Learning from Human Feedback)输出更符合人类偏好的对话。它在输出高质量的文本内容之外,具有很好的上下文语义处理能力能够根据连续对话内容进行有效优化。
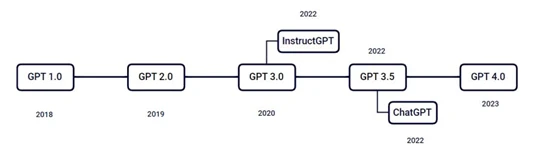
图1 ChatGPT的发展历程
本文的其余内容组织如下:
-
第2章梳理了 ChatGPT 的人类反馈强化学习框架流程和 GPT 各代模型的主要特点。
-
第3 章比较了自动驾驶运动规划算法和 ChatGPT 两者的异同。
-
第4章讨论了 ChatGPT 给自动驾驶运动规划任务带来的启发。
-
第5 章总结了本文了主要内容和观点。
2.ChatGPT 框架
ChatGPT 通过 RLHF 训练模型。这一训练方式增加了人类对模型输出结果的主观排序,得到了更符合人类偏好的优质答案。
RLHF 主要分为三个阶段
第一阶段
监督学习
随机采样请求收集人工撰写的回答,训练监督模型(GPT3.5 based)。
第二阶段
训练奖励模型
收集人工标注的模型多个输出之间的排序数据集。并训练一个奖励模型,以预测用户更喜欢哪个模型输出。
第三阶段
基于强化学习 loss 持续迭代生成模型
使用奖励模型作为奖励函数,以 PPO 强化学习算法,微调监督学习训练出来的生成模型。
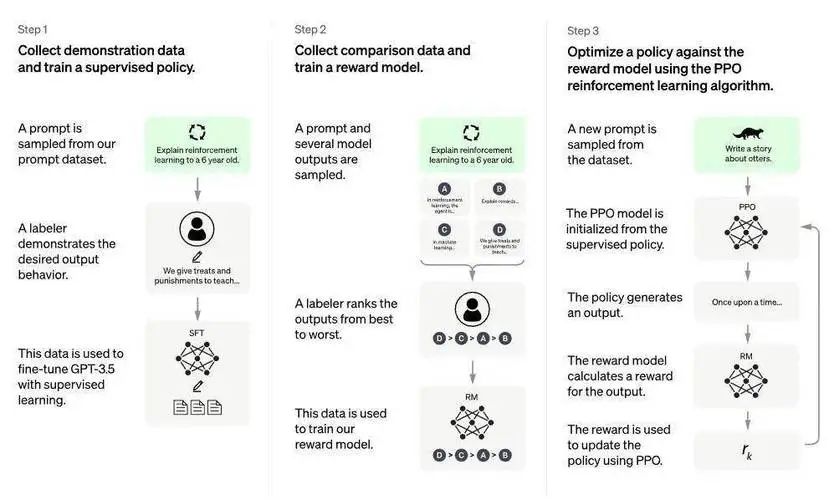
图2 RLHF主要流程
2.1
RLHF:监督学习
监督学习过程通过提问 (prompt)-回答 (demonstration) 获得的数据集对 GPT 模型结构进行微调。下面对不同版本的 GPT 模型做一个总结。
GPT3.5 与之前的模型相比:1. 拥有更高质量的写作能力,产出更智能、更有吸引力的内容;2. 能够处理更复杂的指令,更灵活地使用其各种能力;3. 在较长形式的文本生成有更好的表现,完成过去难以承担的任务。
近期发布的 GPT-4.0 的特点包括:1. 支持文本和图像输入的多模态深度学习模型;2. 在多个专业和学术基准测试中表现出不低于人类水平的性能;3. 训练效果更加稳定;4. 具有更高的可靠性、创造性和能够处理更加微妙的指令。
2.2
RLHF: 训练奖励模型
训练奖励模型主体流程如下:1. 对请求收集模型多个输出;2. 人工对不同输出进行排序;3. 训练奖励模型(模型输出为分数)。
奖励模型结构采用阶段 1 中的监督模型将最后一层移除后添加维度为 1 的全连接层即可得到一个回归模型。问题:如何从排序得到分数/损失函数?InstructGPT 给出了如下的损失函数:
其中 K 为不同回答的个数,σ 为sigmoid 函数, 为模型参数为 θ的奖励模型, 为回答对 中排序较高的回答。对于排序较高的回答,最小化损失函数意味着最大化奖励模型。
此处还有另外一个思路:ELO 算法是一种综合评估玩家实力的算法,通过计算得到一个代表玩家实力的数值。依据此逻辑把每个偏序当作比赛,把奖励分数看作排位分,就能够得到奖励分数作为输出训练上述奖励模型。
假设条件:一个答案的分数服从正态分布 ,其中 是该答案的平均分数, 为其波动水平。
那么,两个答案之间进行排序时均分高的答案排在前边的概率是:
其中D = µ1 − µ2 为两者的平均分数差。利用最小二乘法,对于某个给定的 ,我们可以得到与它的函数图像相近的另外的一个函数,这也是实际运时更常用的函数:
初始化所有答案的平均分之后,每一对答案之间的排序可以对分数进行更新,其迭代公式为:
其中 α 为更新系数,W是排序的结果 (高位为 1,低位为 0)。
2.3
RLHF: 基于强化学习 loss 持续迭代
基于强化学习 loss 持续迭代的流程如下:1. 从数据集中采样问题;2. 初始化 PPO 模型;3. 监督模型输出结果,奖励模型计算奖励分数;4. 通过奖励分数利用 PPO 算法更新监督模型参数。
整个流程的核心点是 PPO 算法,PPO(Proximal Policy Optimization, 近端策略优化) 算法是强化学习中对策略梯度计算更新的一种改进算法,其训练速度与效果在实验上有明显的提升。对一组模型参数 θ,可以得到一组轨迹序列的概率分布 对一条由多个状态动作对组成的轨迹τ, 有奖励方程: 。
目标函数定义为: 。求解其梯度的过程:
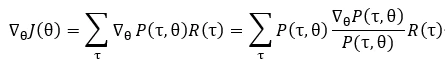
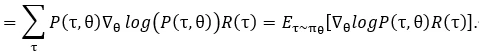
于是可用采样来逼近上式,注意到上式中更新时采用的样本均来自于当前参数,且更新公式也是基于当前参数的函数,一旦采样的样本分布发生了变化便需要收集新数据,这导致训练需要大量互动,降低效率。为了解决这个问题,采用重要性采样对用来更新的样本来源进行改进。
其中 τ ∼ πθ′可通过已有采样逼近,目标函数在重要性采样参与之下转化为:
用 替代 ,用 替代 ,PPO算法迭代解决下述问题:
其中 β 为惩罚参数, 为 KL 散度用来约束 θ 更新的速度。
3.自动驾驶轨迹规划算法和 ChatGPT 两者的异同
强化学习在自动驾驶算法中的应用相对较新,但已经显示出了巨大的潜力和前景。自动驾驶汽车需要通过路径规划算法来找到最佳的驾驶路径。强化学习可以通过与环境的交互学习到最佳的路径规划策略。例如,可以使用强化学习算法来训练车辆在城市道路上遵守交通规则,避免碰撞和行人,并优化车辆行驶速度和燃油效率。
ChatGPT 算法-RHL
自动驾驶规划算法-RL
框架
1. 基于Transformer 的自回归大模型,具有参数量大、网络层数多的特点;2. 基于人工排序训练奖励模型;3. 基于强化学习算法微调大模型;1.基于深度强化学习训练奖励函数和策略;2.基于安全性、舒适性等方面优化路径;
数据来源
GPTX模型数据来自于网络文本、对话数据等获取较为容易;RLHF数据来源于人工标注排序,以对齐语言模型和人类偏好;
在封闭场地/开放路段采集大量的人类驾驶数据,获取较为困难并且依赖感知模块的输出结果;
数据特点
输入是任何自然语言文本(新版本支持图像,多模态输入),输出是响应文本;
输入是环境车辆和道路交通情况(根据多种传感器数据,由多模态感知得到),输出是规划轨迹;
目标
学习人类偏好,微调GPTX模型参数;
学习人类驾驶技术,获取模型参数;
奖励函数
基于语法正确性、连贯性和相关性等方面的人类排序结果训练奖励函数;
基于平滑性、安全性、舒适性、并道意愿等方面给出的奖励函数或者通过逆强化学习训练得到;
学习算法
PRO;
PPO;
TRPO(Trust Region Policy Opt);
DQN(Deep Q-Network);
Actor-Criti;
容错度
对于模型训练有一定容错度。
追求功能安全、信息安全等方面的高要求,对于模型训练的容错度极低。
表2 chatGPT的流程框架与自动驾驶规划方案的差异对比
强化学习的描述如下:假设未知环境 (unknown environment) 中有一个智能体 (agent),该智能体与环境互动可获得奖励 (reward)。智能体以最大化累计奖励 (maximize cumulative rewards) 为目标采取行动 (action)。
首先定义标记如下:状态: 行为: 策略: 状态转移概率: 衰减系数: 回报函数: 状态价值方程: 行为价值方程: 强化学习的目标是寻找最优策略:接下来我们列举在 chatGPT 的流程框架与自动驾驶规划方案的差异对比,具体如表2所示。 接下来我们列举在 ChatGPT 的流程框架与自动驾驶规划方案的差异对比,具体如表2所示。
4.
规划算法优化方向-来自于 ChatGPT 的启发
ChatGPT 算法框架是一种基于深度学习的模型,其具有以下几个特点:
基于大数据集的预训练:ChatGPT 使用海量的语料库进行预训练,从而使得模型具备了更加广泛的语言理解能力。
自回归生成:ChatGPT 使用自回归生成技术生成文本,最大化下述似然函数,能够在保持语法、语义正确的前提下,生成具有逻辑性和连贯性的文本。
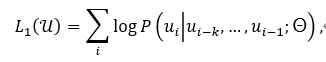
其中 为字符 (token),k 为文本窗口的尺寸。
多层级注意力机制:ChatGPT 使用多层级的注意力机制,无论是从参数数量还是网络深度的角度来看远远高于传统的神经网络,能够在处理输入序列时关注不同层级的信息,从而提高模型的准确性和鲁棒性。
人类反馈强化学习的框架:在模型预训练完之后,ChatGPT 依赖人类专家提供的大量反馈结果训练奖励函数,利用强化学习迭代微调模型参数,能够提高学习效率和性能。
这些特点可以为自动驾驶规划算法框架带来以下启发:➡ 借鉴大数据集的预训练技术:自动驾驶规划算法需要处理复杂的场景和环境,因此可以通过利用大规模的数据集 (包括真实数据以及泛化仿真数据) 进行预训练,提高算法的智能化程度和适应性。
➡ 借鉴自回归生成技术:自动驾驶规划算法需要在复杂的路况下做出决策,因此可以借鉴自回归生成技术,学习老司机的驾驶经验和技术,从而保证决策的正确性和安全性。➡ 借鉴多层级注意力机制:自动驾驶规划算法处理关于空间的时序信息,需要能够抓取上下文联系的能力,可以借鉴 Transformer 的多层级注意力机制,通过大规模的网络结构提高算法性能,从而能够在路径规划时更加准确、全面。
➡ 借鉴人类反馈强化学习的框架:自动驾驶算法需要满足安全性和合法性等要求,然而深度学习算法具有“黑盒性”和“不可解释性”使得并非所有策略都是可行的,可以借鉴人类反馈强化学习的框架将大量基于安全性、合法性等条件的评价反馈给自动驾驶规划算法,通过强化学习模式不断迭代微调相关模型。
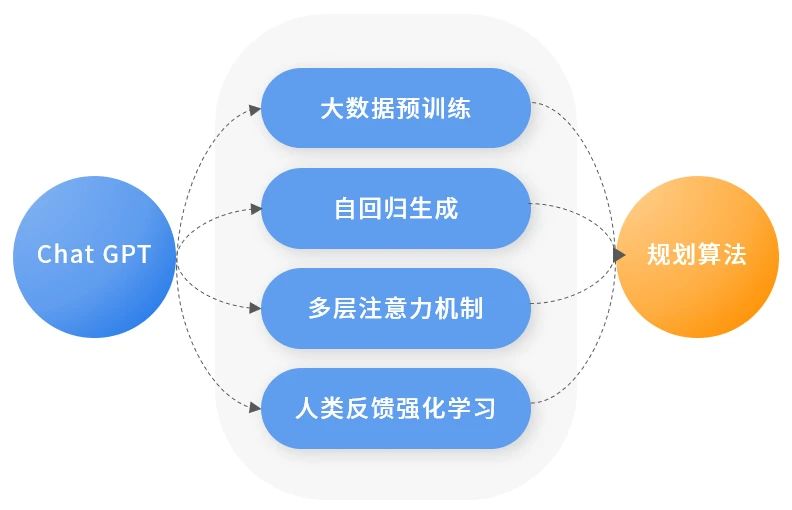
图3 ChatGPT 的特点及其带来的启发
总之,ChatGPT 算法框架的特点可以为自动驾驶规划算法提供启发,从而帮助其更好地应对复杂的场景和环境,提升算法的智能化程度和安全性。
5.总结
本文主要介绍了 ChatGPT 框架和 GPT 各代模型的主要特点,及其引发的对自动驾驶规划
任务未来优化方向的探讨。ChatGPT 的学习思维提供了如下可借鉴的方向:
1. 借鉴大数据集的预训练技术;
2. 借鉴自回归生成技术;
3. 借鉴多层级注意力机制以及大模型设计;
4. 借鉴人类反馈强化学习的框架。
参考文献
[BMR+20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[OWJ+22] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Train-ing language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
[RNS+18] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
[RWC+19] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
[SWD+17] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov.Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.



编辑推荐




最新资讯
-
风噪测试在电动汽车时代的关键作用
2025-04-29 11:34
-
汉航车辆性能测试系列之操纵稳定性测试--汉
2025-04-29 11:09
-
新能源汽车热管理系统验证体系PITMS正式发
2025-04-29 11:09
-
试验载荷谱采集
2025-04-29 11:07
-
APx500 软件演示模式 (Demo Mode) 竟有这些
2025-04-29 08:37
