




 广告
广告





















































一种考虑通信时延的协同感知系统

编者按:随着智能网联汽车的快速发展,单车智能的局限性日益突出,基于协同的自动驾驶成为未来发展方向。多智能体协同感知系统基于多智能体不同视角的观测数据对同一场景执行感知,从根本上突破了单一智能体感知的物理限制如超视距、遮挡。基于智能体共享数据类型与融合策略,协同感知可划分为三类:原始数据级融合、中间特征级融合与感知目标级融合。考虑感知数据通信传输损耗与感知性能之间的平衡,并得益于近年来深度学习的快速发展,中间特征级融合是目前协同感知领域的主要研究方向。协同感知系统的一大关键是通信系统,然而目前大部分协同感知方法均假设一个理想的通信条件,比如不考虑数据传输时延、不考虑通信损耗,这使得许多特征级协同感知方法只能停留在数据集仿真上。本文则考虑协同感知系统在实际应用中面临的带缺陷通信问题,首次提出考虑传输时延的特征级协同感知系统。通过利用深度学习方法,主动地将周围智能体的时延异步感知特征与自车当前时刻的特征进行同步,以提高协同感知系统在通信延迟下的鲁棒性和有效性。
本文译自:
《Latency-Aware Collaborative Perception》
文章来源:
European Conference on Computer Vision (ECCV), 2022
作者:
Zixing Lei, Shunli Ren, Yue Hu, Wenjun Zhang, Siheng Chen
原文链接:
https://arxiv.org/pdf/2207.08560.pdf
代码链接:
https://github.com/MediaBrain-SJTU/SyncNet
摘要:相比于单智能体感知,最近多智能体协同感知在提升感知性能方面显示出巨大潜力。现有协同感知方法通常考虑理想的通信环境。然而,在实际应用中,通信系统不可避免地会产生传输时延问题,导致潜在的性能下降,并给自动驾驶等安全关键型应用带来高风险。为了减轻不可避免的通信时延所造成的影响,我们从机器学习的角度出发,提出了第一个具有时延意识的协同感知系统,它能主动将多个智能体的异步感知特征同步于同一时间戳上,从而提高协同的鲁棒性和有效性。为了实现这种特征级同步,我们提出了一种名为 SyncNet 的新型时延补偿模块,该模块主要应用了特征-注意力共生估计和时间调制技术。实验结果表明,在考虑通信时延设置下,采用 SyncNet 的带时延意识的协同感知方法比最先进的协同感知方法高出 15.6%,并在严重时延情况下保持协同感知优于单智能体感知。
关键词:协同感知,车车通讯,自动驾驶,深度学习
1 引言
协同感知系统考虑基于多智能体感知同一场景,多个智能体通过通信网络执行协同[4,6,8,15,17,27,34,35,37,40]。基于多个智能体的观测,协同感知可以从根本上克服单智能体感知的物理限制,如超视距和遮挡。这种协同感知系统可广泛应用于自动驾驶和机器人测绘等实际应用中。以往的协同感知方法[15,7,27] 已在多种感知任务中取得了显著的成功,包括2D/3D目标检测[21,22,36]和语义分割[5,20,33,41]。其中[16,17]侧重于无人机的语义分割,[15,27]则讨论了基于车车通信辅助的自动驾驶的3D目标检测。考虑到通信带宽与感知性能之间的权衡,以往许多工作在中间特征级实现协同,并利用注意力机制来融合协同特征。
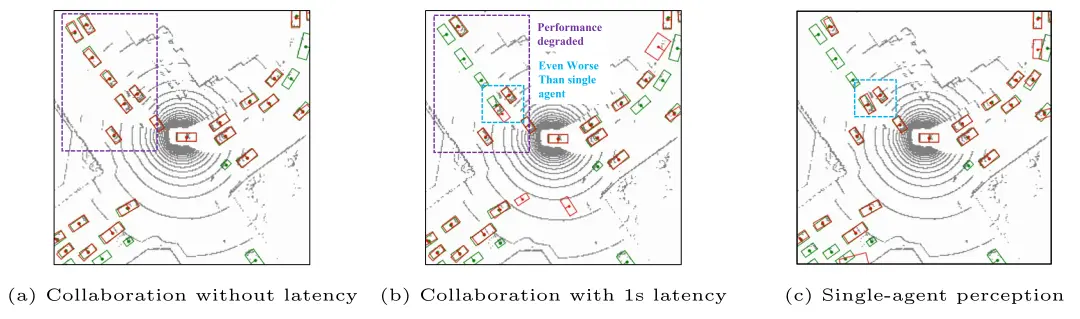
图1 协同3D目标检测。红色:检测值,绿色:真值。当存在传输时延时,无时延考虑的协同感知模型可能比单智能体感知模型效果更差。
然而,这些先前的协同感知方法都没有考虑现实通信环境中不可避免的时延问题。如文献[13]所述,在实时LTE-V2X通信系统中,通信延迟时间平均可达131.30 ms(498个通信周期)。此外,不同通信通道的不同延迟时间会导致严重的时间异步问题。实验表明,时延问题严重损害了协同感知系统,导致其性能甚至比单智能体感知更差。从图1中我们可以看到:1)(a)中紫色框内经协同感知检测到的车辆在(b)中缺失;2) (c)中蓝框内由单智能体感知正确检测到的车辆在(b)中没有被正确检测。原因是自车接收到的他车具有时延的协同数据代表了1s前的情况,它会误导检测器输出具有显著偏差的边界框。这促使我们考虑设计一种对不可避免的通信延迟具有鲁棒性的协同感知系统。
为了解决时延问题,我们从机器学习的角度提出了第一个具有时延意识的协同感知系统,该系统主动地将多个智能体的异步感知特征同步于同一时间戳,提高了协同感知的鲁棒性和有效性。如图2所示,我们的具有时延意识的协同感知系统沿用一个先进的中间特征级协同感知框架[15],并由五个部分组成:1)编码模块:从原始数据中提取感知特征;2)通信模块:在变化的通信时延条件下传输智能体之间的感知特征;3)时延补偿模块:将传输至自主智能体下周围多个智能体的时延特征同步于当前时间戳;4)融合模块:聚合所有经同步后的各智能体特征并生成融合特征;5)解码模块:利用融合特征得到最终感知输出。我们的协同感知系统的主要优点是,它能够在聚合协同特征之前同步各智能体特征,而不是直接融合接收到的异步特征,以减轻通信时延造成的影响。
我们所提系统的关键是时延补偿模块,该模块旨在对周围智能体所传输的时滞特征执行特征级补偿,进而与自主智能体当前时刻特征同步。为了实现这一点,我们提出了一个新颖的同步补偿网络SyncNet,它利用周围智能体历史协同信息来同时估计当前协同特征及对应的协同注意力权重,这两者由于通信时延在当前时刻都是而未知的。协同过程中成对智能体之间的注意力权重与协同特征图具有相同的空间分辨率,表示所接收协同特征中各空间区域的信息水平。因此,它为协同伙伴提供了关于如何利用协同特征的信息提示。直观地说,协同特征和相应的协同注意力权重是耦合在一起的。基于此设计原理,本文提出的SyncNet采用特征-注意力共生估计结构,同时推断出当前时刻其他智能体由于时延而未知的协同特征和协同注意力权重,二者相互增强并避免了级联误差。
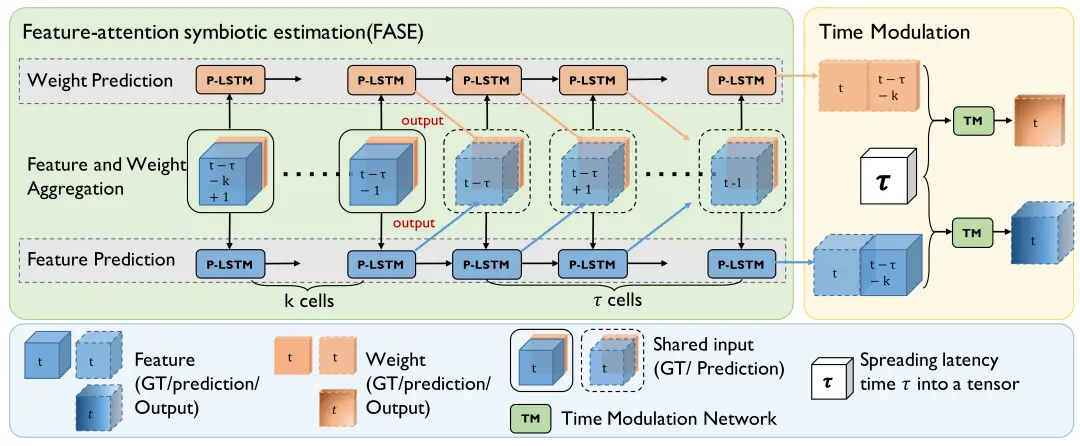
图2 本文提出的具有时延意识的协同感知系统框架:关键模块是时延补偿模块。为了实现这一点,我们提出了SyncNet,它利用历史协同信息来同步由通信时延引起的多个智能体的异步信息。
与常用的时间序列预测方法相比,本文提出的SyncNet有两个主要区别:1)执行特征级估计而不是输出级预测;2)耦合式估计协同特征和协同注意力权重,而不是预测单个输出。
我们在V2X-Sim数据集[14]上广泛评估了基于SyncNet的新型协同感知模型,用于自动驾驶的协同3D目标检测。结果验证了我们的系统的鲁棒性,并比最先进的方法有了实质性的改进。通过使用SyncNet,我们的协同感知系统在不同的通信延迟下始终显著地优于单智能体感知。
综上所述,我们的贡献如下:
1.本文首次提出了协同感知中的通信时延挑战,提出了一种新的具有时延意识的协同感知系统,该系统通过减轻不可避免的通信延迟影响来促进多智能体协同的鲁棒感知。
2.我们提出了一种新的时延补偿模块,称为SyncNet,以实现特征级同步。该模块实现了中间特征和协同注意力两类关键协同信息的共生估计、相互促进。
3.我们进行了广泛的实验,并验证了我们所提SyncNet在时延场景下比以前的方法取得了巨大的性能提升,在严重时延条件下我们依然保持了协同感知优于单智能体感知。
2 相关工作
2.1 V2V 通信: V2V通信主要有两大协议:IEEE 802.11p协议和蜂窝网络标准[18]。在IEEE 802.11p协议中,有一个无线车载环境接入模式(Wireless Access in Vehicular Environment,简称WAVE),允许用户跳过基本服务集(Basic Service Set,简称BSS),从而减少了连接建立的开销[11]。在蜂窝网络中,长期演进(Long Term Evolution,简称LTE)标准衍生出LTE-V2X[1]。虽然V2V网络取得了进展,但仍然面临通信延迟问题,这对协同感知来说风险极大,通信时延时间平均高达 131.30 ms(498个通信周期))[13]。我们旨在从机器学习的角度减轻不可避免的通信延迟所带来的影响,而不是从通信的角度避免延迟,从而设计一种新的具有时延意识的协同感知系统。
2.2 协同感知:协同感知使智能体能够通过通信网络共享感知到的信息,从根本上提升了单智能体感知能力。[16,17]使用握手(handshake)机制来确定哪两个智能体应该通信。[27]引入了一种多轮消息传递的图神经网络。[15]则提出了一种基于图的协同感知系统,通过知识蒸馏来平衡通信传输损耗和感知性能。以往的研究大多集中在理想情境下的协同策略学习。最近,人们开始考虑更现实的情况。[25]利用位姿误差回归模块来校正接收到的噪声位姿误差。然而,以往的研究都没有考虑到实际协同系统中带缺陷的通信的影响。为了填补这一空白,我们考虑协同感知通信中不可避免的时延问题,这对协同系统来说是非常危险的,并构建了一个具有时延意识的协同感知系统来减轻通信延迟带来的影响。
2.3 时间序列预测:时间序列预测的目标是根据历史数据预测未来的信号。[23]在临近降水预报(now-casting)中提出了一种conv-LSTM架构。视频预测作为一种具有普遍性和代表性的时间序列预测类型,一直受到人们的积极研究[19,24,28,31]。通过利用预测技术,我们的工作从历史协同信息中恢复由于时延而丢失的信息。然而,与标准预测不同,我们的目标是最大化最终感知性能,而不是精确估计当前状态。
3 本文方法
为了解决时延问题,我们在3.1节中提出了一个具有时延意识的协同感知系统。3.2节介绍时延补偿模块SyncNet,这也是整个系统的关键。最后,3.3节介绍了网络监督训练的损失函数。
3.1 具有时延意识的协同感知系统
协同感知系统中多个智能体基于由通信网络共享的数据来共同感知一个场景。由于通信延迟在现实通信系统中是不可避免的,因此我们重点研究考虑时延设置下的协同感知系统。也就是说,给定一个通信延迟不可控的非理想通信信道,我们的目标是通过减轻时延的影响来优化协同系统下智能体的感知能力。
我们考虑在一个场景中有个在执行环境感知的智能体。设、和分别为第个智能体在时间戳的原始观测、中间感知特征和最终感知输出。表示特征从智能体传输到智能体的延迟时间。 是智能体和智能体在时刻的协同注意力权重。协同注意力权重由可学习网络计算:对协同感知系统中所有协同特征执行点素级注意力分配。需注意的是:1)延迟时间本身是时变的,为了简化符号,从这里开始我们将省略它的上标。2)本工作认为多智能体协同发生在离散时间戳,并且也是离散的,因为每个智能体都有确定的观测采样率。实验结果也验证了在合理小的时间间隔内对连续时间进行离散时,产生较少不匹配。然后,我们将提出的考虑时延的协同感知表述为:
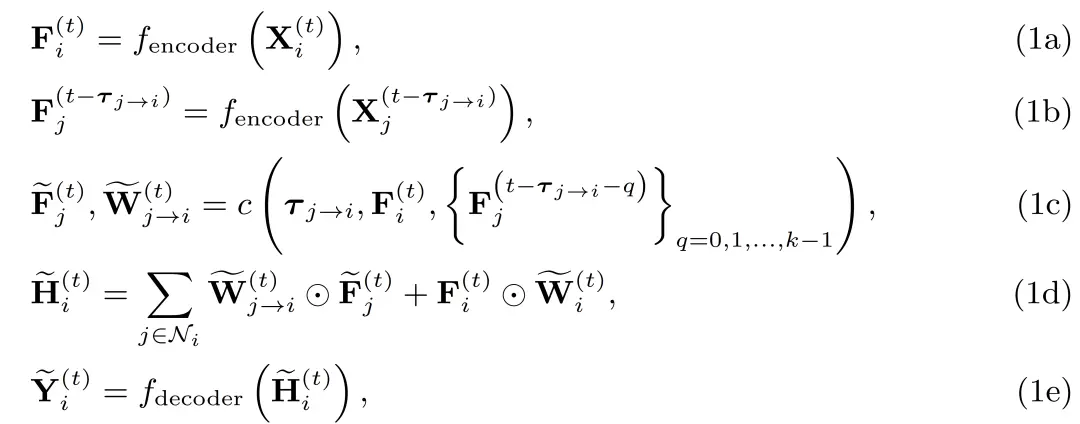
其中为所估计的智能体在时刻同步后的特征,是智能体与智能体在时刻的协同注意力权重,是智能体在当前时间戳对所有周围智能体估计的同步特征执行聚合后的特征,表示智能体的邻域智能体集,是一超参数。
步骤(1a)考虑从原始观测数据中提取感知特征,其中为编码网络。在步骤(1b)中,我们从其他智能体接收具有不同传输延迟时间的感知特征。为了补偿时延,步骤(1c)通过利用来自各智能体的历史特征和主体智能体感知的实时特征来估计当前时间戳下其他智能体的协同特征和协同注意力,其中表示该估计网络。这里我们假设每个智能体可以在内存中存储前帧的历史特征。步骤(1d)则融合所有经时延补偿后的协同信息。最后,步骤(1e)输出最终感知输出,其中为解码器网络。对应于图2,步骤(1a)和(1b)构成编码模块,步骤(1c)属于时延补偿模块,步骤(1d)为时延融合模块,步骤(1e)构成解码模块。
我们提出的时延协同感知系统有四个优点:1)我们明确地将通信时延纳入协同感知系统的设计中(见(1b)、 (1c)),这在以前的工作中从未做过。2)我们通过从历史协同信息中估计当前信息来减轻传输时延的影响(见(1 c))。对此,我们考虑特征级同步,而不是同步感知输出,因为它允许端到端学习框架具有更高的学习灵活性。3)在(1c)中,我们同时推理协同特征和协同注意力权重。如果我们只估计特征,我们将需要基于估计的特征来计算协同注意力,这将放大估计误差,导致级联错误。4)我们采用基于注意力的估计,利用(1c)中的协同注意力权重促进对感知敏感区域的更精确的估计(见(1d))。
3.2 SyncNet :时延补偿模块
由于时延补偿模块是本文所提协同感知系统的关键,我们专门设计了估计网络,并提出了新颖的同步补偿网络SyncNet。它的功能是利用各周围智能体历史协同信息来对其所传输特征执行时延补偿。SyncNet包括两个部分:特征-注意力共生估计模块,其采用双分支金字塔LSTM来同时估计实时特征和协同注意力;时间调制模块,其利用时延时间自适应调整协同特征的最终估计。
图3 SyncNet结构:SyncNet包括特征-注意力共生估计(FASE)模块和时间调制(TM)模块。前者是共享相同输入的双分支金字塔LSTM(图中P-LSTM),即特征和注意力的聚合。时间调制模块则用于在估计的特征和接收的原始异步特征之间分配时域注意力。
特征 - 注意力共生估计:特征-注意力共生估计(FASE)利用一种新的双分支结构,由特征估计分支和注意力估计分支组成,进而同时估计当前时刻特征及其协同注意力权重。双LSTM网络的两个分支共享相同的输入,包括主体智能体感知的实时特征和其他协同智能体感知的前帧历史特征。每个分支由一个金字塔LSTM网络实现,该LSTM对一系列历史协作信息建模并估计当前状态。金字塔LSTM网络专门用于捕获空间相关的协同特征。如图4所示,当红框内的车辆相对于中心车辆右移时,特征图上的对应区域也会发生相同的移动。事实表明,空间信息对我们的估计任务是重要的。我们将LSTM[10]中的矩阵乘法修改为多尺度卷积结构,详见图5a。本文提出的金字塔LSTM与普通LSTM的主要区别在于:标准LSTM[10]没有专门考虑提取空间特征,而[23]则仅提取单尺度空间特征。本文所提出的金字塔LSTM则是在多个尺度上捕捉局部到全局的特征。
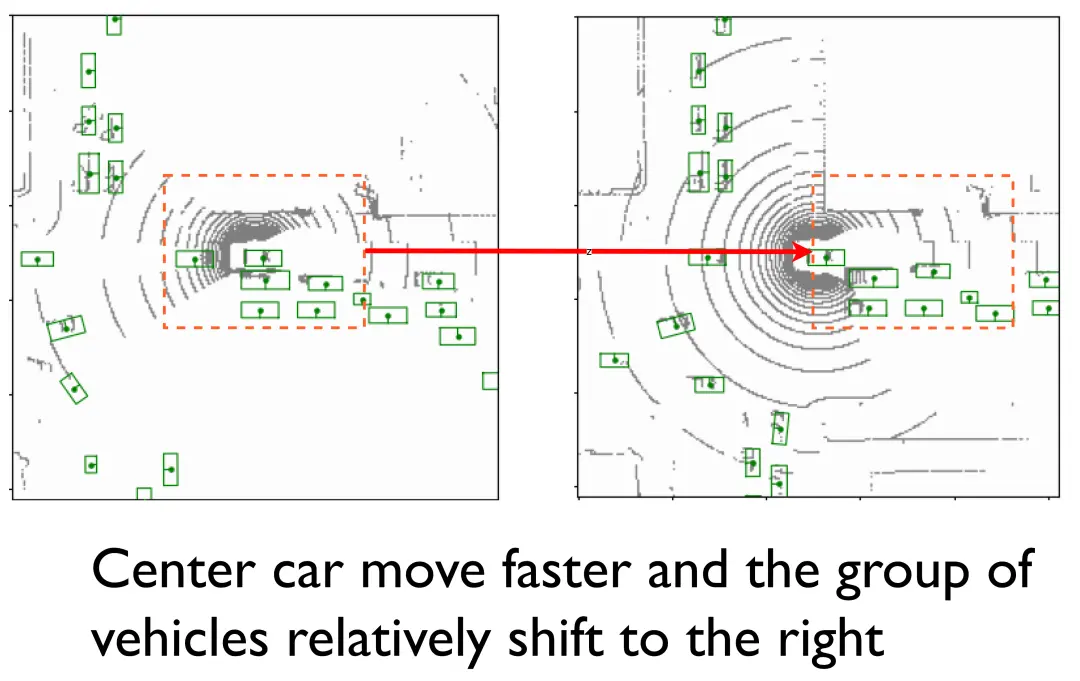
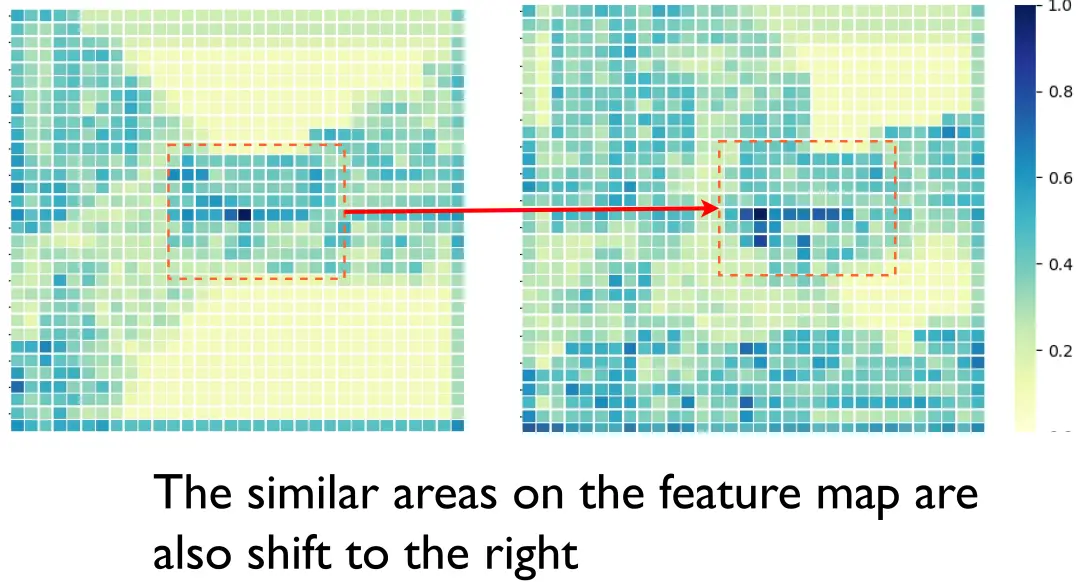
图4 特征域的空间相关性。上半部分图中绿框代表真值目标。下半部分热力图由特征沿特征通道求和得到。
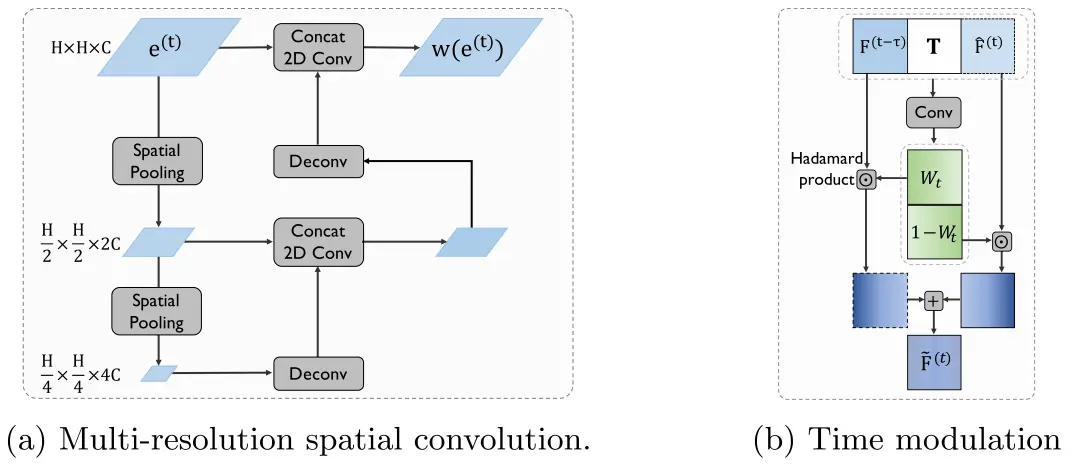
图5 (a)为金字塔LSTM的多分辨率空间卷积, (b)表示时间调制,最终估计特征为。
特征估计分支旨在获取当前协同中最具信息的特征。为了实现这一点,特征估计分支应该是具有注意力意识的。而注意力估计分支的目的是寻找当前信息量最大的特征区域,同时还要抑制估计误差较大的区域。为了实现这一点,注意力估计分支应该是具有特征意识的。为了允许所估计的特征和相应的注意力能相互关注到彼此,我们循环地利用来自前一个时间戳估计的特征和协同注意力作为两个分支下一个时间戳的输入。
整个过程如算法1所示,是特征传输延迟时间,代表历史帧,表示当前时间戳,和分别表示在时刻自主智能体接收到其他智能体的协同注意力权重和协同感知特征,和则分别表示时刻经时延补偿估计的协同特征和协同注意力,是时刻金字塔LSTM 的输入,,,和分别是金字塔LSTM在每个分支中的隐藏状态和元胞状态。
我们所提出的特征-注意力共生估计网络具有三个特点:1)双分支结构同时推断协同特征和相应的协同注意力,保持二者的独立性并消除级联错误。2)该估计网络将协同注意力作为输入,从而聚焦于具有更多信息的区域,促进更有效的估计。3)可学习的注意力估计网络获取协同特征的信息,并基于理想无时延环境下获取的协同注意力和融合特征进行监督训练。在端到端优化过程中,它不仅可以模拟计算出无延迟的权重分布,还可以主动学习减少对特征中噪声较大的空间区域的关注。
算法 1:特征-注意力共生估计

时间调制:虽然FASE实现了的基本功能,但我们发现,当时延较小时,传输时延引起的协同感知性能下降相对于FASE导致的估计噪声要小。为了解决这个问题,我们提出了时间调制模块,它将原始传输的中间特征(在低时延下工作良好)和基于FASE估计的特征(在高延迟下工作良好)融合在一起,结合延迟时间,产生更全面和可靠的估计。
设,为反映各空间区域估计不确定程度的置信度矩阵。和分别为延迟时间经扩展得到的时延张量,二者形状分别与和相同。时间调制模块的工作原理如下:
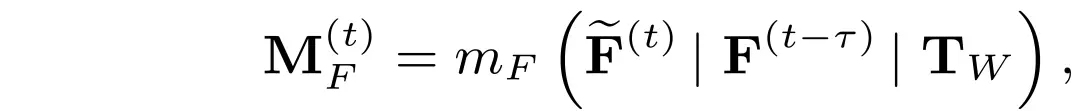
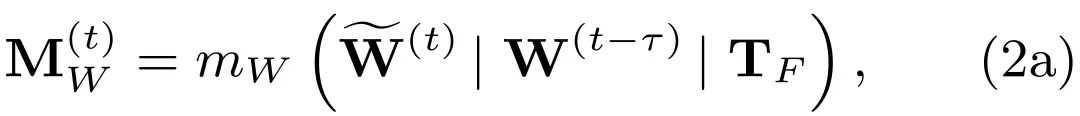
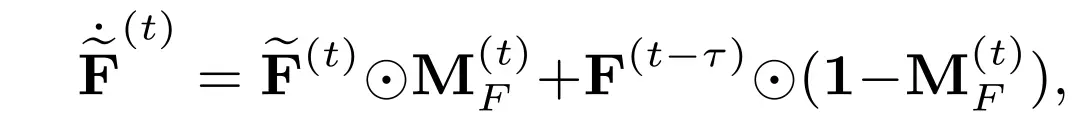
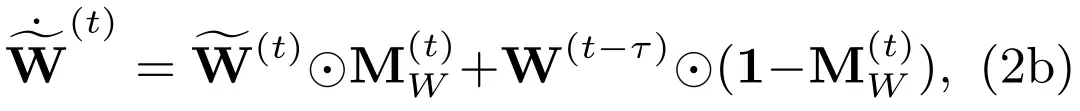
其中和均为配有sigmoid激活函数的轻量级卷积神经网络,为所有元素均为的矩阵。步骤(2a)将FASE估计的协同特征/注意力、当前接收的时滞特征/注意力和时延扩展张量进行对应拼接,得到代表每个空间区域下所估计的协同特征与协同注意力的置信度。根据置信度矩阵,步骤(2b)分别将估计的特征/注意力和原始异步特征/注意力组合起来。我们期望当时延较大时,置信度矩阵的权重会更高,表示此时经时延补偿估计的特征/注意力对最终估计的贡献会更大。具体过程同样可见图5b。
3.3 损失函数
设为智能体在时刻的最终感知输出的真值目标信息,为智能体在时刻融合各智能体协同特征后的真值特征,为智能体在时刻的真值协同特征,是时刻智能体到智能体的真值协同注意力权重。我们考虑最小化以下目标以优化整个考虑时延的协同感知系统:
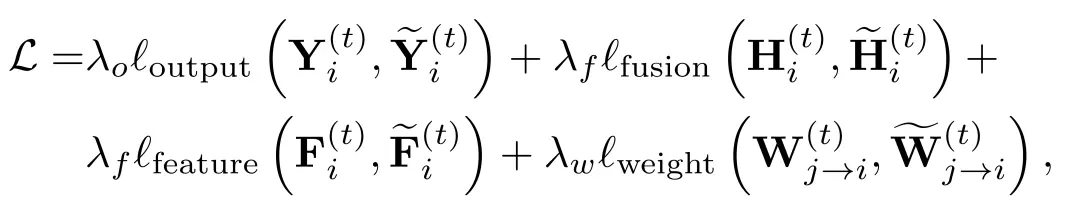
其中表示每个项目的权重,是最终目标检测损失项,, , 分别为融合特征、中间估计特征和估计协同注意力损失项。第一项监督目标检测输出,第二项监督估计的融合特征。第三和第四项提供了对中间特征映射和协同注意力的监督,以促进更快的收敛。
4 实验
4.1 多智能体 3D 目标检测数据集
我们使用多智能体数据集V2X-Sim[14]验证了SyncNet在基于lidar的3D目标检测任务[3,9]上的效果。V2X-Sim是由SUMO[12]和CARLA[7]联合仿真构建的数据集。V2X-Sim训练集包含80个场景,测试集包含11个场景。数据集中每个样本平均包含2.67个智能体,并具有3D点云输入和3D边界框注释。3D点云由32通道、最大距离70m、旋转频率20Hz、记录频率5Hz的激光雷达生成。为了模拟时延场景下的协同感知,我们异步加载其他智能体感知数据。延迟时间是根据指数分布随机生成的并最终四舍五入为整数。
4.2 实现细节
实验设置:基于自车笛卡尔坐标系,我们对3D点云执行范围裁剪,只取位于[−32m,32m] ×[−32m,32m]×[0.5m]范围下的点云。考虑对点云执行体素化处理,我们设置每个体素栅格的大小为0.25m×0.25m×0.4m。对点云执行范围裁剪和体素化之后,我们得到了一个尺寸为256×256×13的鸟瞰图。各智能体需传输的编码特征的尺寸为32×32×256。两个智能体之间的时延时间由指数分布四舍五入生成,可以是固定或随机整数。我们使用NVIDIA RTX 3090 GPU和Pytorch训练我们的模型。评估指标选用IoU阈值为0.5和0.7的平均精度(AP)。
基准:我们提出的具有时延意识的协同感知系统沿用DiscoNet[15]框架,这是目前最先进的协同感知框架之一。此外我们利用所提出的SyncNet作为时延补偿模块来处理各种时延设置。为了验证我们的协同感知系统Disconet + SyncNet,我们与三个基准进行比较:1)单智能体感知系统,即无协同感知;2)无时延意识的协同感知系统,DiscoNet[15];3)基于卡尔曼滤波[32]的具有朴素时延意识的后融合协同感知系统,Late collaboration + Kalman Filter。需要注意的是,SyncNet也可以作为其他中间特征级协同感知框架(如V2VNet)的时延补偿插件模块[27]。SyncNet相当于特征-注意力共生估计(FASE)+时间调制(TM)。与双分支结构的FASE相对应,一种简化的变体是简单估计(Vanilla Estimation, VE),它只采用单分支LSTM来估计协同特征。在消融研究中,我们将比较DiscoNet、Disconet + FASE、Disconet + VE和Disconet + SyncNet的性能。
训练策略:我们在训练阶段采用课程学习(Curriculum Learning)[2]策略。课程学习从简单的样本开始,然后逐渐增加难度。为了处理变化的延迟时间,我们在不同的时延设置下训练模型。然而,随着延迟时间的增加,训练损失急剧增加,导致训练过程不稳定,容易受到攻击。为了解决这个问题,我们采用课程学习技术,每10个epoch逐渐增加1个延迟时间,直到增加到第10个延迟时间。然后,我们以平均为5的指数分布随机采样延迟时间,以进一步升级模型以适应灵活的通信延迟。
4.3 定量评价
图6比较了我们的具有时延意识的协同感知系统、无协同感知、无时延补偿的DiscoNet以及基于卡尔曼滤波的后融合协同感知系统的性能。我们可以发现:1)DiscoNet易受传输时延的影响,在高时延条件下其性能甚至低于无协同感知模型。2)我们的Disconet + SyncNet对时延具有鲁棒性,即使在通信延迟高达10帧的糟糕通信条件下也优于无协同感知模型。3)我们的Disconet + SyncNet在不同的通信延迟下始终优于DiscoNet,并将AP@0.5/0.7的性能对应提高了15.6%和12.6%。

图6 无协同感知、DiscoNet[15]、卡尔曼滤波的后融合协同感知、Disconet + SyncNet在1-10帧延迟下的性能比较。
图7显示了其他框架(包括V2VNet和基于Transformer的融合模块)在使用和不使用SyncNet时的性能对比。基于Transformer的融合模块采用多头注意力[26]来融合每个空间位置的协同特征。SyncNet模块在AP@0.5上的性能分别提高了11.8%和8.7%。研究表明,各种协同感知模型都容易受到通信时延的影响,而我们所提出的时延补偿模块一致且显著地改善了这些框架。
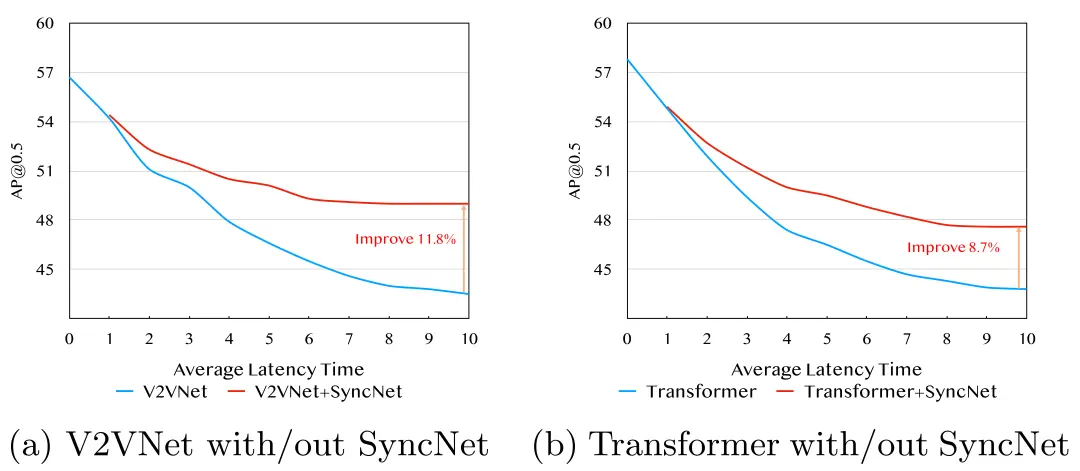
图7 SyncNet在AP@0.5中集成于不同的协同感知框架的性能对比。
4.4 消融研究
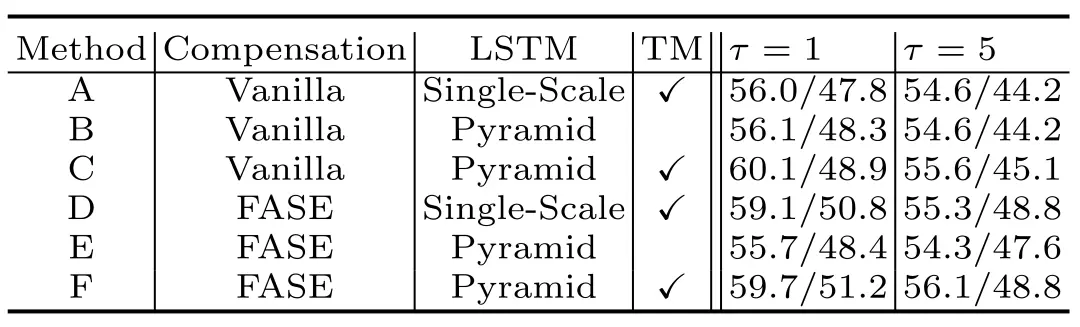
我们首先在图8中展示了时延补偿时所考虑历史帧数对协同感知性能的影响。我们看到,明显优于,但相比于仅带来较小的增益。因此本文默认选择,以实现计算效率和性能之间的平衡。我们进一步验证了我们提出的同步补偿网络(SyncNet)的两个主要组件(FASE和TM)的有效性。简单估计(Vanilla Estimation, VE)采用单分支结构,只对协同特征进行估计。图9是DiscoNet、Disconet + FASE、Disconet + VE和Disconet + SyncNet随延迟时间的变化对比图。我们可以看到:1)对比绿线和蓝线,我们的协同感知系统只需要一个普通的LSTM补偿模块就可以在时延场景下实现显著的性能提升。2)对比红线和蓝线,FASE架构可以提高AP@0.7指标的性能。3)对比红线和黄线,当时延较小时,TM可以提高性能。表1进一步讨论了补偿模块、多尺度卷积和时间调制模块在低时延和高时延下的效果。我们可以看到:1)D优于A, E优于B, F优于C,反映FASE在AP@0.7指标中始终有效;2)C优于B, F优于E,反映TM在高时延时始终有效。
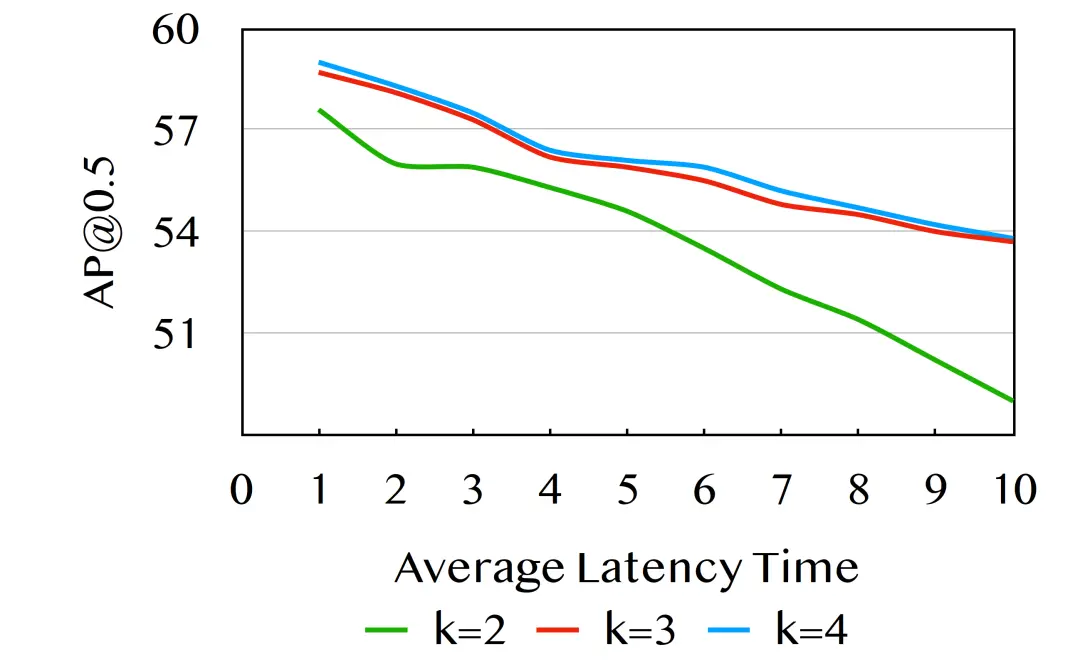
图8 历史帧数k的消融研究。
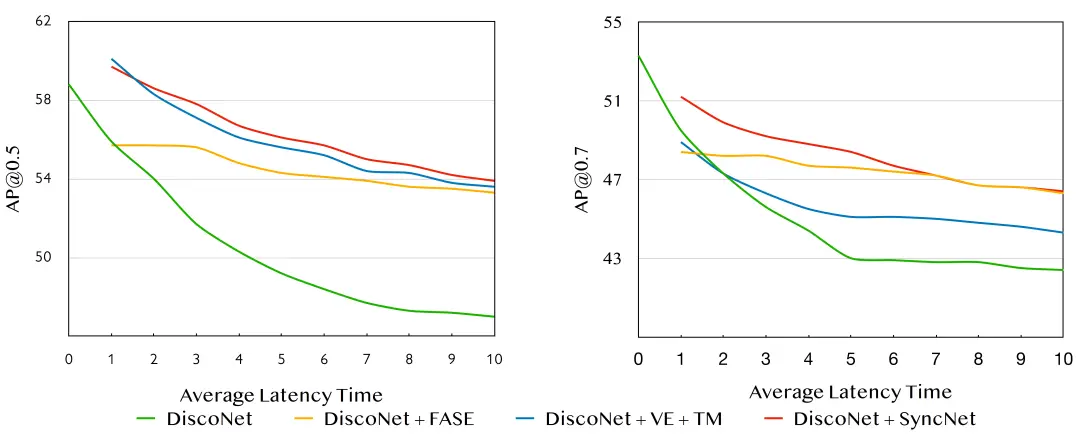
图9 消融研究:比较DiscoNet, Disconet + FASE,Disconet + VE + TM,Disconet + SyncNet随时延变化的性能。FASE在AP@0.7中有明显改进作用,TM在小时延时具有改进作用。
表1 AP@0.5/0.7指标下SyncNet消融研究
4.5 定性评价
图10为无时延设置下的DiscoNet、有时延设置的DiscoNet、有时延设置的Disconet + VE和有时延设置的Disconet + SyncNet的检测结果。对比(a)和(b),我们可以看到(a)中紫色框中正确检测到的车辆由于传输时延而在(b)中被遗漏或被错误检测到。(c)表明,简单估计VE(无FASE)部分补偿了蓝框中的延迟误差,但在橙色框中无法实现准确估计,而我们的SyncNet可以精确地恢复两辆车的真实位置,如图(d)的紫色框所示。从图(d)可以看出,SyncNet实现了最佳补偿,并精确地恢复了车辆的真实位置。
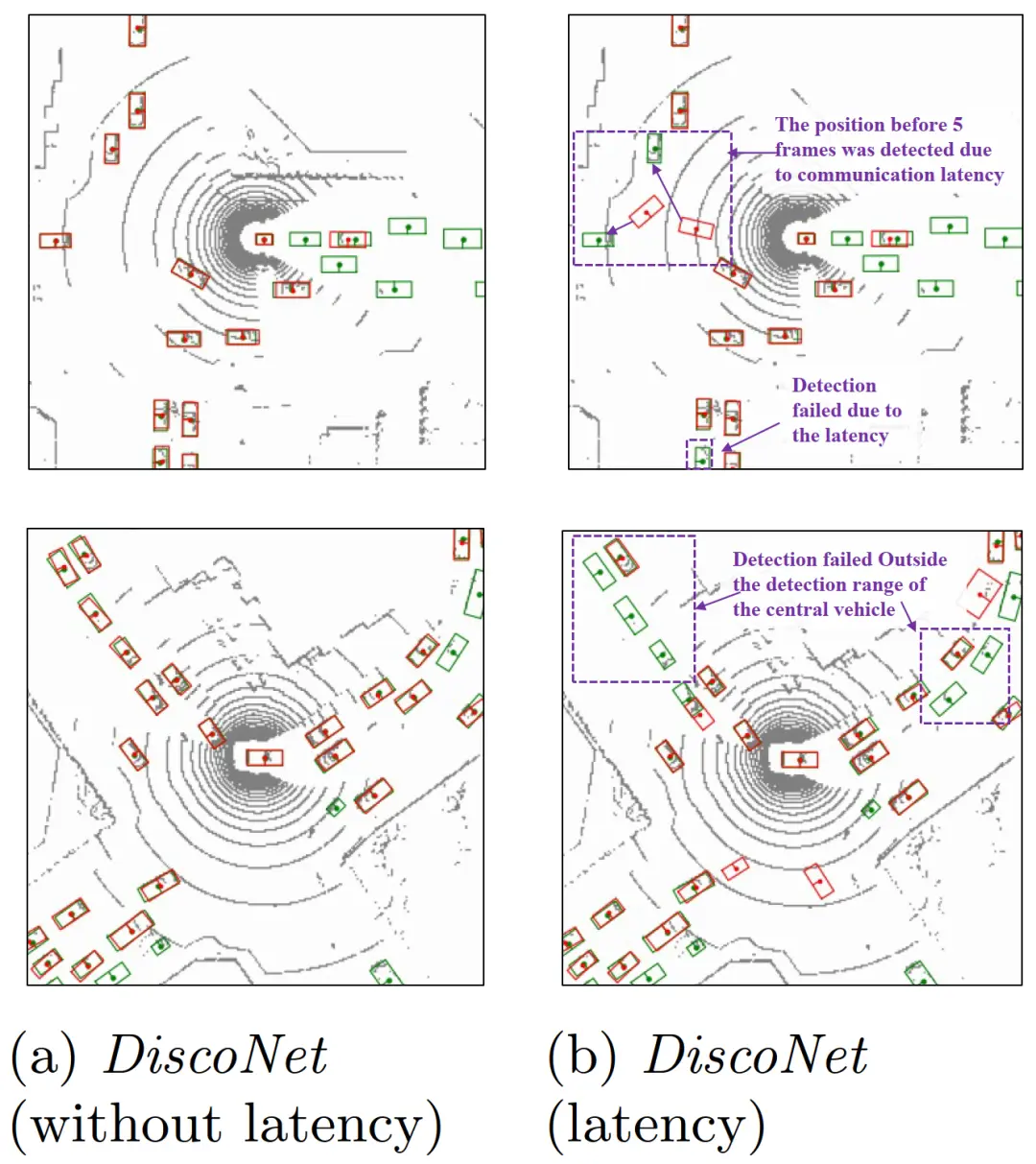
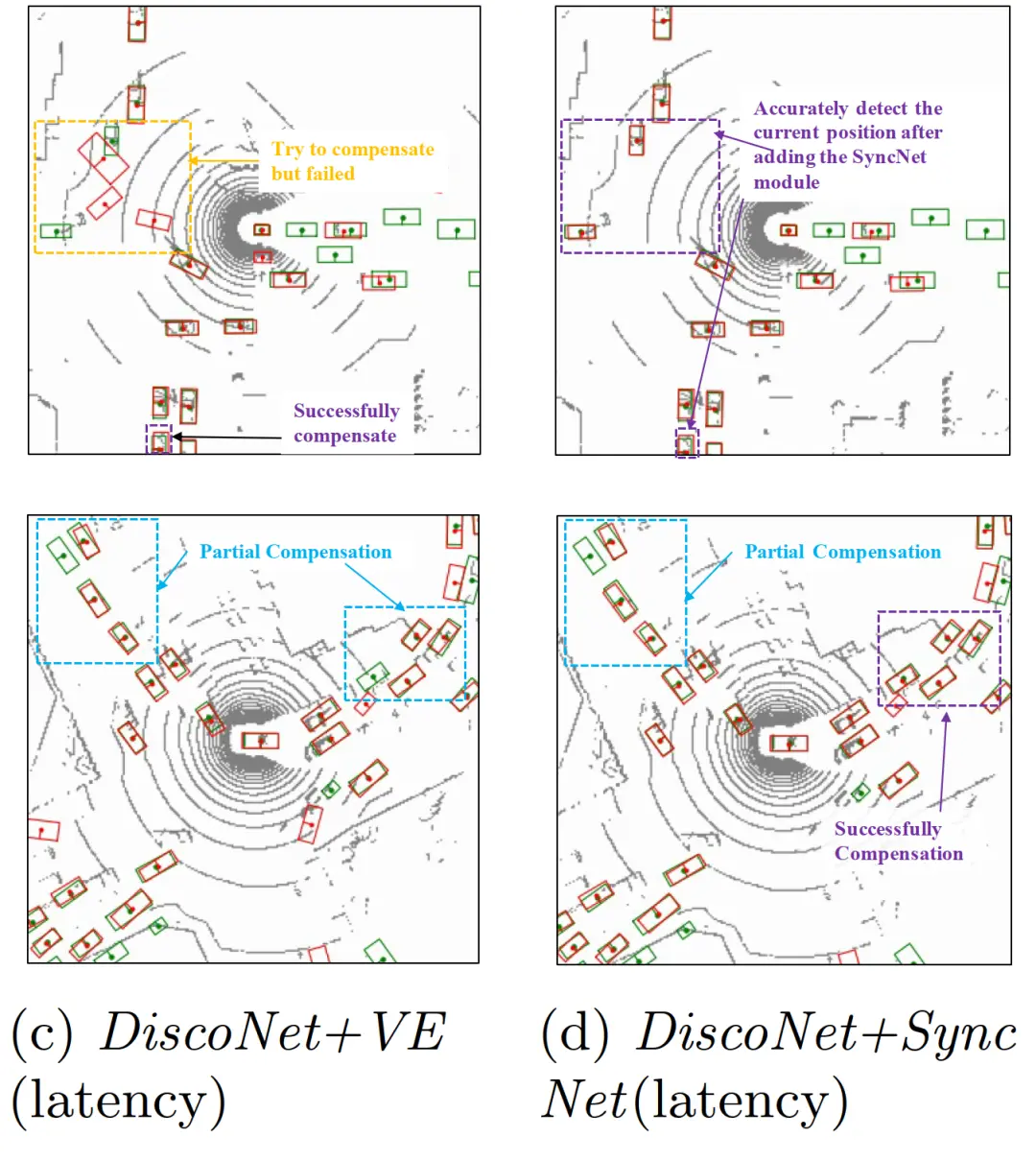
图10 FASE架构定性地提高了通信延迟下的性能。(a)为无时延设置的DiscoNet[15]检测结果。(b) (c) (d)显示平均时延设置为5帧下的检测结果。
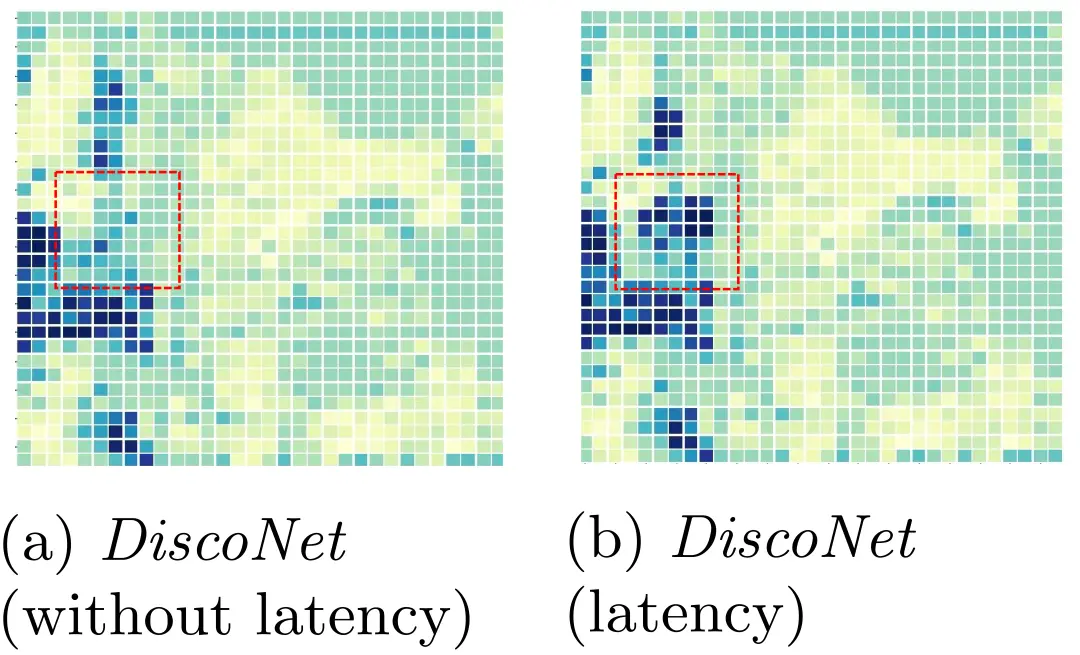
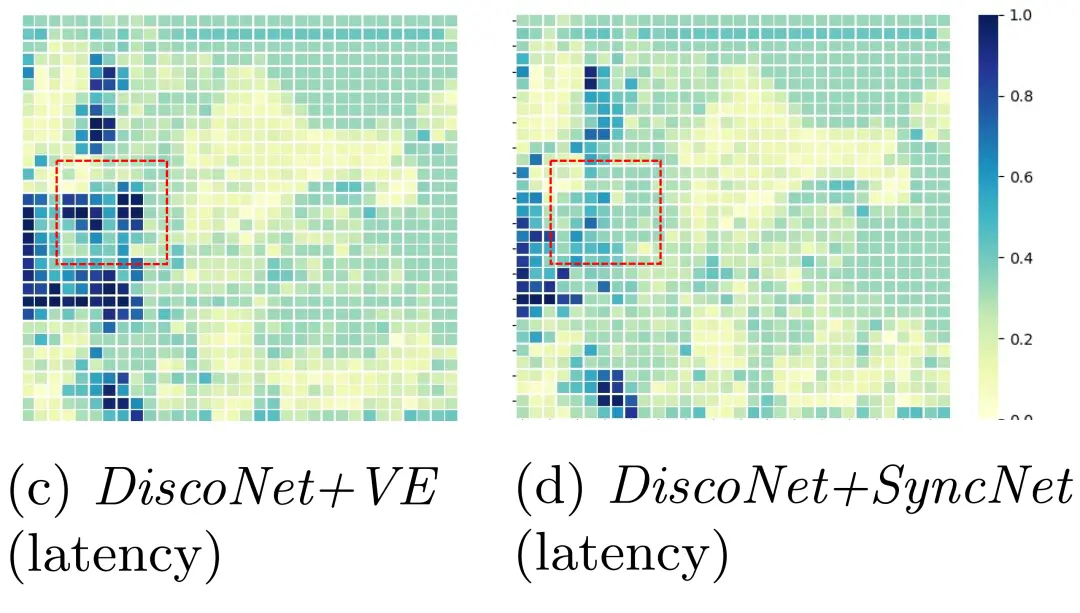
图11这里展示了图10中四组模型第一行场景中自车对周围某个智能体所传输特征的协同注意力权重。(b) (c) (d)为平均延迟5帧设置下的结果。对比(b)、(c)和(d)我们可以看到SyncNet得到了一个更接近(a)的特征(无时延设置),并且主动降低了红框中有噪声位置的权重。
图11显示了图10中四组模型第一行场景所示示例中来自周围智能体所传输特征的注意力权重。我们可以看到:(b)、(c)在红框中都有类似的大权重,这表明它们将噪声引入到协同特征中。得益于SyncNet中的协同注意力估计分支(基于真值协同注意力权重的监督训练),(d)在红框有类似(a)的小权重,其关注真实的具有更多有效信息的区域并避免由于特征估计不准确而导致的级联误差。这些定性结果验证了SyncNet的有效性。
5 结论
我们引入了一个具有时延意识的协同感知系统,并提出了一种新的时延特征补偿模块SyncNet,用于时域同步,适合现有的中间特征级协同感知方法。 SyncNet采用了一种新型的共生估计结构,该结构联合估计中间特征和注意力权重。SyncNet基于特征-注意力共生估计和时间调制模块,显著提高了较小时延范围内的协同感知性能。系统性的定量和定性实验表明,所提出的SyncNet可以提高通信延迟场景下的感知性能,有效解决协同感知中的时延问题。
参考文献





编辑推荐




最新资讯
-
R171.01对DCAS的要求⑤
2025-04-20 10:58
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
