




 广告
广告





















































GPT-4V在自动驾驶上应用前景如何?面向真实场景的全面测评来了

GPT-4V 的发布让许多计算机视觉(CV)应用看到了新的可能。一些研究人员开始探索 GPT-4V 的实际应用潜力。
最近,一篇题为《On the Road with GPT-4V (ision): Early Explorations of Visual-Language Model on Autonomous Driving》的论文针对自动驾驶场景对 GPT-4V 的能力进行了难度递增的测试,从情景理解到推理,再到作为真实场景驾驶员的连续判断和决策。

论文地址:https://arxiv.org/pdf/2311.05332.pdf
具体来说,论文对 GPT-4V 在自动驾驶领域的探索主要集中在以下几个方面:
1、情景理解:该测试旨在评估 GPT-4V 的基本识别能力,包括识别驾驶时的天气和光照条件,识别不同国家的交通信号灯和标志,以及评估不同类型摄像头拍摄的照片中其他交通参与者的位置和行动。此外,出于好奇,他们还探索了不同视角的模拟图像和点云图像。
2、推理:在这一阶段,研究者深入评估了 GPT-4V 在自动驾驶环境下的因果推理能力。这项评估包括几个关键方面:首先,他们仔细研究了它在处理复杂 corner case(边缘情况,即发生概率较低的可能场景)时的表现,这些情况通常是对数据驱动感知系统的挑战。其次,他们评估了它在提供全景视图(surround view)方面的能力,这是自动驾驶应用中的一项重要功能。鉴于 GPT-4V 无法直接处理视频数据,他们利用串联的时间序列图像作为输入来评估其时间相关性能力。此外,他们还进行了测试,以验证其将现实世界场景与导航图像关联起来的能力,从而进一步检验其对自动驾驶场景的整体理解能力。
3、驾驶:为了充分发挥 GPT-4V 的潜力,研究者让它扮演一名经验丰富的驾驶员,让它在真实的驾驶环境中根据环境做出决策。他们的方法是以一致的帧率对驾驶视频进行采样,然后逐帧输入 GPT-4V。为了帮助它做出决策,他们提供了基本的车速和其他相关信息,并告知了每段视频的驾驶目标。他们要求 GPT-4V 采取必要行动,并对其选择做出解释,从而挑战其在实际驾驶场景中的能力极限。
测试采用了经过精心挑选的代表不同驾驶场景的图片和视频。测试样本来自不同渠道,包括 nuScenes、Waymo Open 数据集、Berkeley Deep Drive-X (eXplanation) Dataset (BDD-X)、D2 -city、Car Crash Dataset (CCD)、TSDD、CODA、ADD 等开源数据集,以及 DAIR-V2X 和 CitySim 等 V2X 数据集。此外,还有一些样本来自 CARLA 模拟环境,其他样本则来自互联网。值得注意的是,测试中使用的图像数据可能包括时间戳截至 2023 年 4 月的图像,有可能与 GPT-4V 模型的训练数据重叠,而本文中使用的文本查询完全是重新生成的。
实验结果表明,GPT-4V 在情景理解、意图识别和驾驶决策等方面展现出超越现有自动驾驶系统的潜力。但是在区分左右、信号灯识别、视觉定位任务与空间推理方面存在局限。
在 corner case 中,GPT-4V 可利用其先进的理解能力来处理分布外(OOD)的情况,并能准确评估周围交通参与者的意图。GPT-4V 利用多视角图像和时间照片实现对环境的完整感知,准确识别交通参与者之间的动态互动。此外,它还能推断出这些行为背后的潜在动机。他们还见证了 GPT-4V 在开放道路上做出连续决策的性能。它甚至能以类似人类的方式解释导航应用程序的用户界面,协助、指导驾驶员进行决策。总之,GPT-4V 的表现证明了视觉语言模型在应对自动驾驶领域复杂挑战方面的巨大潜力。
需要注意的是,研究者详述的所有实验都是在 2023 年 11 月 5 日之前,利用网络托管的 GPT-4V (ision)(9 月 25 日的版本)进行的。最新版本的 GPT-4V 在 11 月 6 日 OpenAI DevDay 之后进行了更新,在呈现相同图像时可能会产生与本研究测试结果不同的反应。
情景理解能力
要实现安全有效的自动驾驶,一个基本前提是清楚透彻地理解当前场景。该研究主要关注两个方面:模型对周围环境的理解、模型对各种交通参与者的行为和状态的理解,旨在通过评估阐明 GPT-4V 解释动态交通环境的能力。
理解环境
为了评估 GPT-4V 理解其周围环境的能力,该研究进行了一系列测试,涵盖以下关键方面:判断一天中的时间、了解当前天气状况、识别和解释交通灯及标志。
如下图 2 所示,GPT-4V 可以识别出前视图像是一天中什么时间的场景,例如「傍晚」:

天气是一个显著影响驾驶行为的关键环境因素。该研究从 nuScenes 数据集中选择了在不同天气条件下,在同一路口拍摄的四张照片,要求 GPT-4V 识别这些图像中的天气状况,结果如下图 3 所示:

在识别和解释交通灯及标志方面,GPT-4V 的表现明显存在不足。如下图 4 所示,GPT-4V 在夜间条件下成功识别出黄色路灯和红色交通灯。然而,在图 5 中,当图像中的交通灯在远处时(图像显示较小),GPT-4V 就错误地将绿灯的倒计时识别为红灯的倒计时。

交通标志包含驾驶员需要遵守的各种规则和说明。自动驾驶系统需要识别交通标志、理解并遵守这些规则,从而降低交通事故的风险,提高驾驶安全性。
从下图 6 可以看出,GPT-4V 可以识别大多数路标,包括附近的「SLOW」和远处的限高「4.5m」,但错误地识别了「Speed Bump」标志。GPT-4V 具有一定的交通标志识别能力,但仍有进一步增强的空间。

理解交通参与者
如下图 7(左)所示,模型能够完整、准确地描述驾驶场景:识别行人、交通标志、交通灯状态和周围环境。图 7 (右)显示模型可以识别车辆类型及其尾灯,并可以猜测其打开尾灯的意图。然而,GPT-4V 也输出了一些不正确的描述,例如认为前面的车有后视摄像头。


该研究评估了 GPT-4V 使用各种传感器输入理解交通参与者行为的能力,包括 2D 图像(图 9)、3D 点云的可视化(图 10 )、从 V2X 设备(图 11)和自动驾驶模拟软件(图 12)获取的图像。


高级推理能力
推理是正确驾驶行为的另一个重要因素。鉴于交通环境的动态性和不可预测性,驾驶员经常会遇到一系列意外事件。面对这种不可预见的情况,熟练的驾驶员必须凭借经验和常识做出准确的判断和决策。该研究进行了一系列的测试来评估 GPT-4V 对意外事件的响应。
Corner Case
如图 13(左)所示,GPT-4V 可以清晰地描绘出不常见车辆的外观、地面上的交通锥以及车辆旁边的工作人员。识别这些条件后,GPT-4V 会意识到自我车辆应稍微向左移动,与右侧工作区域保持安全距离,并小心驾驶。

多视图图像
通过利用多视角摄像头,GPT-4V 可以捕捉驾驶环境的全面视图,该研究评估了 GPT-4V 处理多视图图像的能力。
如下图 16 所示,该研究选择使用一组周围环境图像并以正确的顺序将它们输入到模型中。结果表明,GPT-4V 能够熟练地识别场景中的各种元素,例如建筑物、车辆、障碍物和停车场,甚至可以从重叠的信息中推断出场景中有两辆汽车,其中一辆白色 SUV,一辆卡车。然而,GPT-4V 会错误地识别出人行横道。

如下图 17 所示,在另一个实验中,GPT-4V 提供了对场景基本准确的描述,但也出现了一些识别错误,特别是在车辆的数量和形状方面。值得注意的是,GPT-4V 会产生一些令人困惑的错觉,例如认为图片上有左转标志。研究团队推测这些问题可能是由于 GPT-4V 的空间推理能力有限。

此外,该研究还尝试给出正确的前视图,让 GPT-4V 识别并给乱序的周围图像进行排序。尽管模型进行了大量看似有意义的分析和推理,但最终仍然输出错误答案。显然,GPT-4V 在建立相邻图像之间的连接方面遇到了挑战。

时间序列
为了评估 GPT-4V 理解时间序列图像的能力,该研究从视频片段中提取四个关键帧,用序列号标记它们,并将它们组合成单个图像以供输入,要求 GPT-4V 描述该时间段内发生的事件、自我车辆采取的行动及原因。测试结果如下图 19、20、21、22 所示:




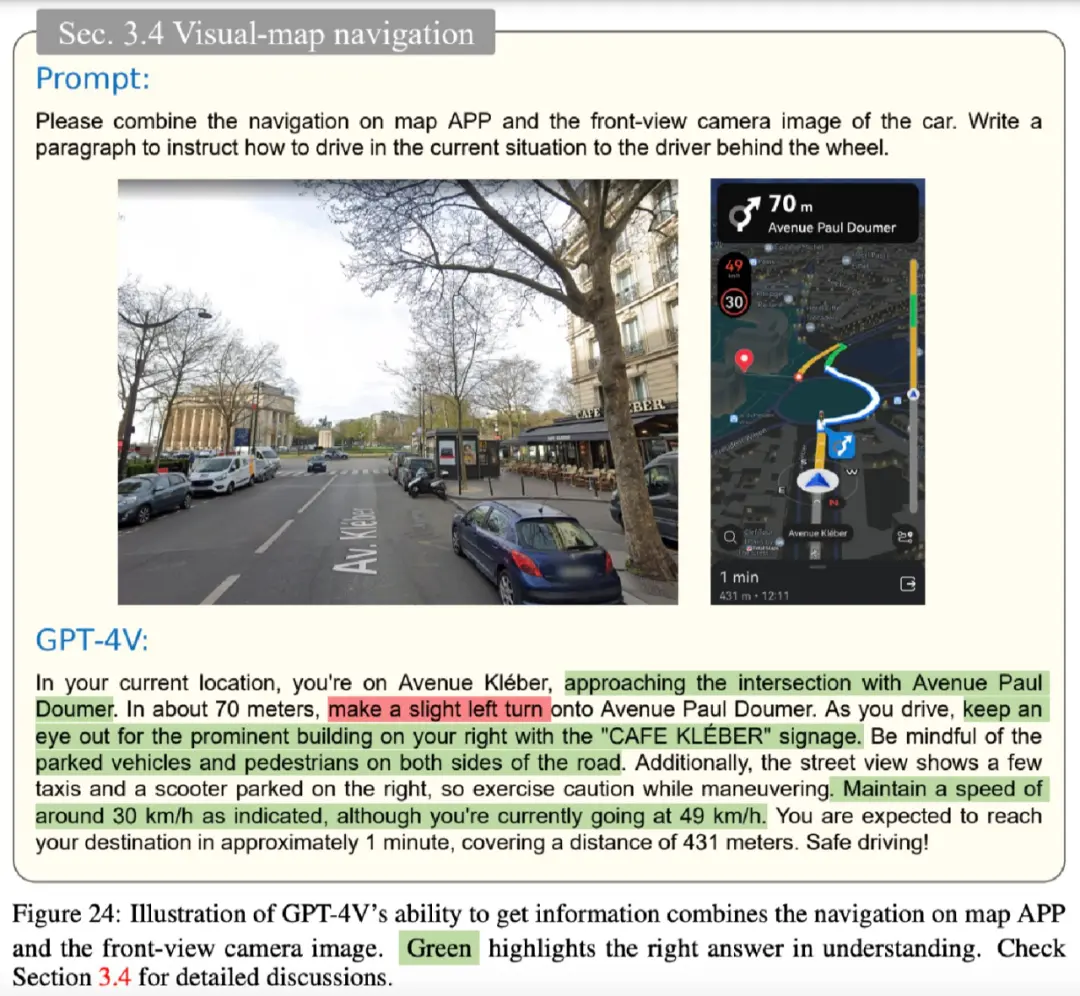
此外,在实际驾驶场景中,驾驶员经常利用外部设备的辅助信息来增强决策能力,例如地图导航 app。该研究为 GPT-4V 配备了前视摄像头图像以及来自地图软件的相应导航信息。
下图 23、24 表明,GPT-4V 可以利用前视摄像头和地图导航 app 信息准确定位其位置,并给出相应的驾驶建议,但在一些情况下给出的建议是错误的。
驾驶能力
自动驾驶算法的最终目标是复制人类驾驶员的决策能力。实现这一目标需要精确识别、空间感知以及对各种交通要素之间时空关系的深入理解。该研究通过在几个不同的现实驾驶场景中测试 GPT-4V 的决策能力来评估 GPT-4V 在自动驾驶方面的潜力。
例如,为了测试 GPT-4V 在封闭区域内的驾驶决策能力,该研究选择的场景是「右转离开停车场」,并需要通过安检,测试结果如下图 25 所示。

该研究还选择「交通繁忙的十字路口」场景进行了测试,结果如下图 26 所示:

局限性总结
在测试中,研究人员发现 GPT-4V 在以下任务中表现不佳:
1、区分左右:如图 17 所示,在一些情况下,模型在识别方向方面遇到困难,而这正是自主导航的一个关键方面。图 8 和图 21 也显示了类似的问题。这些图突出显示了模型在解释复杂路口或做出变道决策时偶尔出现的混乱。
2、信号灯识别:在图 12、15、22、26 和 29 中发现了该问题。研究者怀疑出现这一问题的原因是全图中包含大量语义信息,导致交通信号灯的嵌入信息丢失。当图像中的交通灯区域被裁剪并单独输入时,模型能够成功识别,如图 5 所示。
3、视觉定位任务:如图 7 所示,GPT-4V 很难指定像素级坐标或边界框,只能指示图像中的大致区域。
4、空间推理:准确的空间推理对于自动驾驶汽车的安全运行至关重要。无论是如图 18 所示的多视角图像拼接,还是如图 21 所示的滑板车与自动驾驶汽车之间相对位置关系的估算,GPT-4V 都难以做出精确的判断。这可能源于根据二维图像输入理解和解释三维空间的内在复杂性。



编辑推荐




最新资讯
-
Rivian与MAE合作定制电动车测试设备安装项
2025-04-10 14:41
-
重型商用车辆和客车的动力学——操纵性
2025-04-10 14:40
-
新能源汽车VCU、BMS、MCU控制器图解
2025-04-10 14:39
-
陶琳回应电动车辐射高:特斯拉辐射值远低于
2025-04-10 13:14
-
nCode2025版本发布说明
2025-04-10 13:12
