




 广告
广告





















































预期功能安全专栏 | 自动驾驶语义分割模型的对抗鲁棒性研究

自动驾驶语义分割模型的对抗鲁棒性研究
On Adversarial Robustness of Semantic Segmen-tation Models for Automated Driving
作者:Huilin Yin, Ruining Wang, Boyu Liu, Jun Yan
人们已经提出了一些研究工作来评估基于深度学习的自动驾驶语义分割模型在对抗攻击下的鲁棒性。然而,在以往的实证研究中,所测试的对抗样本和所评估的分割模型的类型受到了限制,这导致了对语义分割模型的鲁棒性理解的限制。为了缓解这些问题,本研究将在数据层面从模型结构的内部因素和环境扰动的外部因素两个方面系统地推进语义分割模型的鲁棒性研究。本研究使用具有不同内部结构的典型模型进行了全面的研究:全卷积网络(FCN)、金字塔场景分析网络(PSPNet)、DeepLapv3+和具有不同主干网络的 SegNet。这些模型将采用鲁棒性评价指标对在白盒攻击和黑盒攻击下的结果进行评估。在实验的基础上,对不同影响因素下不同模型的鲁棒性进行了定性和定量分析。随着更多的实证研究案例,我们的工作为自动驾驶语义分割的鲁棒性研究提供了灵感,这对预期功能安全(SOTIF)研究是有意义和有利的。
➡本文内容主要分为4部分
01 简介
近年来,随着深度学习的快速发展,自动驾驶技术取得了巨大进步。在自动驾驶领域,语义分割的性能对安全驾驶非常重要。
然而,深度神经网络容易受到对抗性示例的影响[1]-[4]。在没有视觉表征修改的情况下,轻微的对抗性扰动会导致神经网络上的欺骗。此类攻击可能威胁图像分类器、对象检测器和语义分割模型。
为了缓解此类安全问题,一个合格的神经视觉系统既需要在正常场景下的高泛化能力,也需要在对抗性攻击下的鲁棒性。对这种对抗性攻击的实证研究是提高深度学习鲁棒性的一项重要任务。在实际应用中,用于自动驾驶的基于深度学习的语义分割模型在模型结构的先验知识的情况下遭受白盒对抗性攻击。此外,自动驾驶中常见的黑匣子对手,比如异常天气和相机散焦也可以被视为语义分割模型的隐患,这可能导致预期功能(SOTIF)的安全性受到威胁[5]。SOTIF被认为是自动驾驶安全的一个重要方面。它处理人工智能模型的局限性和人类滥用造成的风险。
尽管语义分割模型在对抗性攻击的鲁棒性方面已经取得了一些研究成果,但攻击方法和评估模型的类型仍然有限。实际自动驾驶场景中的扰动是复杂的,自动驾驶车辆中存在各种基于深度学习的语义分割模型。如果没有详细的实证研究,就不可能深入理解自动驾驶中语义分割模型的鲁棒性。为了解决这些问题,我们将从影响因素的两个方面系统推动语义分割模型鲁棒性的研究:模型结构的内部因素和数据层面环境扰动的外部因素。
在本文中,我们评估了Cityscapes[6]上的分割模型在数据级别上对自动驾驶的白盒攻击(FGSM[2],GD-UAP[7])和黑盒攻击(图像腐蚀[8])的鲁棒性。
此外,根据不同自动驾驶场景的鲁棒性指标,对相同语义分割模型的各种主干网络进行评估,以探索模型结构的影响。我们对实验结果进行了定量和定性分析得出了一些发现,这些发现可能会对自动驾驶语义分割的鲁棒性研究产生启发,这对SOTIF是有意义和有益的。
我们的贡献主要包括两个方面:
• 在模型层面,通过实证研究,我们发现了模型和主干网络对鲁棒性的影响,如PSPNet的非鲁棒特征学习、ReLU6激活函数对GD-UAP攻击的鲁棒性等。此外,我们的理论分析也证实了这一发现。
• 在数据层面,我们研究了各种对抗性扰动的影响,特别是异常天气和相机畸变等黑匣子攻击。实证和理论研究均能支持SOTIF相关风险的触发条件分析,有助于提高驾驶安全。
02 相关工程
在本节中,我们全面回顾了基于深度学习的自动驾驶语义分割模型的开发、对抗性攻击,以及对语义分割鲁棒性的实证研究工作。
A. 基于深度学习的自动驾驶语义分割模型
自2012年以来,卷积神经网络(CNN)已被广泛用于图像分类[9]-[12]并取得了巨大成功。与图像级分类相比,语义分割使像素级识别成为图像分类的一项扩展任务。研究人员致力于提出具有最先进性能的语义分割模型,包括全卷积网络(FCN)[13]、SegNet[14]、金字塔场景解析网络(PSPNet)[15]、DeepLab系列模型[16]-[19]等。FCN是语义分割领域的一个里程碑,它利用全卷积层而不是全连接层进行像素识别。SegNet在FCN的基础上使用了编码器-解码器结构,并在池化期间缓存像素位置的索引信息,这允许解码器在上采样时拥有更准确的位置信息。PSPNet将特征图输入到空间金字塔池化(SPP)[20]模块,该模块使PSPNet能够融合不同分辨率的特征,并对其进行改进以获得全局信息。DeepLab系列型号已经更新了四次,从DeepLabV1[16]、DeepLabV2[17]、DeepLab V3[18]到最先进的DeepLabV3+[19]。
DeepLabV3+不仅利用了空洞空间卷积池化金字塔(多孔空间金字塔池化)(ASPP)模块,而且还将深度卷积神经网络(DCNN)与扩张卷积相结合,以提高目标边界的性能。由于这些具有不同主干网络的典型模型将应用于自动驾驶领域,因此值得对这些语义分割模型的鲁棒性进行评估。
B. 对语义分割的对抗性例子和对抗性攻击
语义分割模型被白盒对抗性攻击和黑箱对抗性攻击所困扰。
白盒攻击:科学家们在了解L-BFGS[1]、快速梯度符号法(FGSM)[2]、投影梯度下降(PGD)[3]、Carlini和Wagner攻击(C&W)[4]等模型的基础上,提出了白盒对抗性攻击方法。FGSM是一种基于梯度更新的单步无目标对抗性攻击。FGSM作为一种无目标对抗性攻击,只需要损失值变大,模型就无法识别正确的分类。另一种特殊类型的白盒攻击是通用对抗性扰动(UAP)[21]。通过将这种准不可察觉的扰动添加到干净的图像中,深度神经网络估计的标签很有可能发生变化。这种图像不可知的扰动被称为普遍对抗性扰动。制作通用对抗性扰动的通用无数据目标(GD-UAP)[7]是普通UAP攻击方法的一种变体,它与数据无关,可以在不同的视觉任务之间传输。
黑箱攻击:黑箱对抗性攻击不需要模型的先验知识。异常天气和相机畸变可归因于黑匣子对抗性攻击。Hendrycks等人[8]在他们提出的ImageNet-C数据集中应用了15种噪声来评估图像分类任务的鲁棒性。Michaelis等人[22]在先前工作[8]的基础上评估了基于自动驾驶的物体检测器的鲁棒性。通常,黑盒图像损坏[22]包含19种不同类型的噪声,这些噪声模拟了自动驾驶中的真实对抗场景。
对语义分割模型进行对抗性攻击的实证研究:我们的工作受到了几项关于语义分割的实证研究的启发。Arnab等人[23]利用FGSM作为对抗性攻击来评估语义分割模型(如 DeepLabV2)的鲁棒性。
Kamann[24]生成损坏的图像以攻击图像并评估模型的鲁棒性。然而,在先前的实证研究中,测试的对抗性示例和评估的分割模型的类型是有限的。为了促进语义分割模型鲁棒性的研究,本文将从影响因素的两个方面研究问题:模型结构的内部因素和数据层面环境扰动的外部因素。更多关于不同对抗性攻击下不同语义分割模型的实证研究案例将有助于深入理解语义分割模型在自动驾驶中的鲁棒性。
03 框架
在本节中,我们提出了我们的鲁棒性分析框架。四个模型将在干净的城市景观数据集上进行训练:FCN、SegNet、PSPNet和DeepLabV3+。对于对抗性攻击,FGSM和GD-UAP是白盒对抗性攻击的两种类型,黑盒攻击将由图像损坏产生。研究了异常天气和摄像机畸变的驾驶环境因素。
图一阐述了我们的框架,包括典型的语义分割模型、对抗性扰动和综合分析。
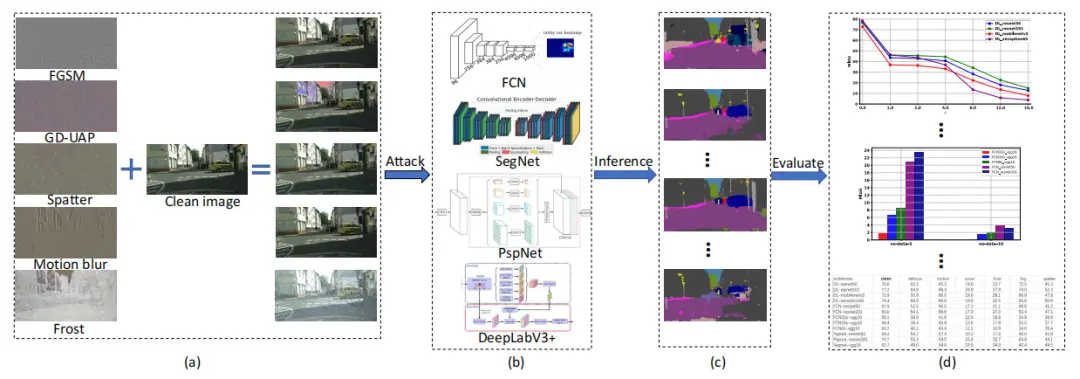
图1:我们提出的鲁棒性分析框架。为了评估模型的鲁棒性并分析影响因素,我们在干净的自动驾驶数据集上训练了四种用于自动驾驶的语义分割模型,然后在各种对抗性扰动下进行测试。(a)对抗性摄动 扰动世代的过程,其中左侧展示对抗性摄动 扰动,右侧显示对抗性示例;(b)每个分割模型的结构块包括FCN、SegNet、DeepLabV3+和PSPNet;(c)来自输入对抗性示例的预测;(d)定量和定性分析。
A. 语义分割模型
这四种语义分割模型是实际应用中常用的模型,它们具有不同的内部结构。因此,我们基于这四个模型研究了鲁棒性。
FCN[13]可以被视为第一个基于深度学习的语义分割模型。通过利用转置卷积和反池化操作,FCN可以识别图像中的特定对象。此外,FCN会丢弃丢失空间信息的结构,例如全局池化。为了避免“梯度消失”的现象,在分割模型中加入了跳跃层结构。
经典编码解码结构中的SegNet[14]推断。为了实现最大池化的效果,模型会选择最大的像素来存储特征图中像素的位置,这些像素位置信息被称为索引。在解码过程中,SegNet通过对特征图的反池化,根据索引恢复原始位置的最大值,然后用零填充其他位置,以获得最终的分割预测图像。SegNet中的池化操作会记住在选择最大值期间的相对位置,以便进一步使用上采样,这是它与FCN的最大区别。
PSPNet[15]在训练过程中添加了一个辅助损失函数,以加速模型收敛。该模型利用扩张网络策略,有效地逐个像素提取特征图。然后,该模型使用金字塔池化模块通过多尺度特征映射提取上下文信息。
DeepLabV3+[19]的贡献在于编码器-编码器结构,它不仅提高了分割效果,还改善了边界的信息。为了提取和纯化多尺度信息,DeepLabV3+使用空洞空间卷积池化金字塔(多孔空间金字塔池化)(ASPP),在主干网络之后进行可分离卷积。与DeepLabv3相比,DeepLabv3+引入了解码器模块,该模块将低级特征与高级特征进一步融合,以提高分割边界的准确性。
B. 对抗性扰动
FGSM和GD-UAP是鲁棒性研究中两种典型的白盒对抗性攻击。此外,评估黑盒攻击下的鲁棒性有助于提高自动驾驶的SOTIF。
FGSM[2]是一种单步无目标对抗性攻击方法。扰动将被添加到具有最大梯度变化的方向上,以干扰分类模型的推断。它是一个最优的最大范数约束对抗性扰动,如方程(1)所定义。
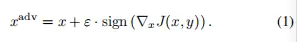
在上式中,x表示原始输入图像,xadv表示对抗性样本,ϵ是最优最大范数约束扰动的参数,sign表示梯度方向。扰动预算ε越大,其获得的攻击效果就越好。然而,人眼可以检测到对抗性扰动,这可能会降低对抗性攻击的隐蔽性。
通过控制ε的大小,可以实现攻击效果和图像质量之间的折衷,这意味着人眼无法识别与原始图片的差异。
GD-UAP[7]是一种独立于数据的通用对抗性扰动生成方法,可应用于各种任务,包括图像分类、语义分割和深度估计。这种方法的目的是通过干扰多层提取的特征来欺骗模型。
具体而言,攻击其他模型的方法是在多个层上过度填充激活函数,如等式(2)所定义。
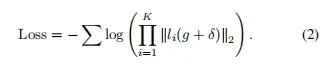
在上述公式中,g可以被视为先验数据。在无数据设置中,g是一个空矩阵。在带有数据的设置中,g是图像矩阵。δ是需要优化的随机噪声,li(δ)是当g+δ被馈送到网络时,第i层的输出张量(非线性之后)中的激活。
图像破坏扰动[22]是用19种不同的过程对抗性噪声实现的,包括变焦模糊、运动模糊、散焦、磨砂玻璃、高斯模糊、高斯噪声、脉冲噪声、散粒噪声、斑点噪声、雪模拟、飞溅模拟、雾模拟、霜模拟、数字亮度、数字对比度、JPEG压缩、饱和度,像素化和弹性变换。每种对抗性噪声都有5个严重程度,扰动将由从1到5的不同自然数值控制。神经网络在这种黑箱攻击下的脆弱性和不确定性可归因于SOTIF的风险问题。
04 试验
A. 试验设置
数据集:试验基于cityscape数据集[6],该数据集广泛应用于自动驾驶语义分割基准测试领域。该数据集由车载摄像头拍摄的道路场景组成,共有19个类。验证数据集有500张图像,训练数据集总计约23000张图像。所有这些图像都是高分辨率图像(1024×2048)取自50多个城市的道路场景。其他自动驾驶的基准数据集,如KITTI[25]和Udacity[26],只能用于对象检测和跟踪,不能用于分割。因此,cityscape更适合我们的研究。
模型:最先进的DeepLabV3+[19]模型-具有多个网络主干网的模型在PyTorch框架中进行训练。MobileNetV2[11]、ResNet50[10]、ResNet101[10]和Xception65[27]被选为网络主干网。为了与Deep-LabV3+进行比较,我们选择FCN8s[13], FCN16s [13], FCN32s[13]与VGG16[9]主干网,FCN与ResNet50和ResNet101主干网,SegNet[14]与VGG16主干网,PSP- Net[15]与ResNet50和ResNet101主干网。所有的主干网都在ImageNet数据集[28]上进行了预训练。为了保证试验的准确性,所有这些模型都使用了包括随机裁剪和随机水平翻转在内的图像增强方法进行训练。
对抗性攻击:本文对白盒攻击和黑盒攻击进行了研究。FGSM[2]和GD- UAP[7]是两种白盒攻击。将异常天气和图像损坏产生的摄像机畸变等驱动环境因素视为黑盒攻击。在FGSM的试验中,在[1/255,2 / 255,4 / 255,8 / 255,12 / 255,16 /255]的范围内对不同的摄动 扰动预算 约束e设置l∞范数攻击。在GD-UAP的试验中,在[5/ 255,10 /255]范围内的扰动预算 约束e上设置了l∞范数攻击。在图像破坏[22]的试验中,不同噪声的5种严重程度都将被测试。
评价指标:平均交集超过联合(mIoU)是语义分割模型评价中最常用的指标。在本文中,对抗性扰动下的mIoU可以看作是鲁棒性的度量。
B. FGSM攻击的试验
图2显示了在Cityscapes数据集上训练的几个最先进的模型在FGSM攻击下的鲁棒性。
在FGSM(ε=[1,2,4,8,12,16])中,DeepLabV3+比其他模型具有更高的mIoU。具有轻量级主干MobileNetv2的DeepLabV3+模型不如具有其他3个主干的DeepLab V3+模型,后者具有更多的参数。很明显,具有Xception65主干的模型在ε≤4的情况下保持了相当大的识别性能,但当扰动预算 约束满足ε≥8时,mIoU迅速下降。然而,这并不意味着具有Xception65主干的DeepLabV3+模型在实际应用中的鲁棒性不好,因为当扰动预算 约束满足ε≥8时,图像的噪声在现实世界中已经变得肉眼可见。
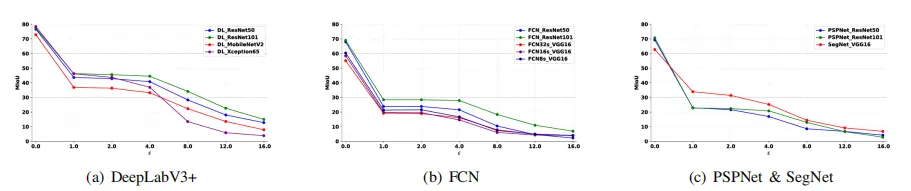
图2:在FGSM攻击下,最先进的模型对城市景观数据集的鲁棒性
在与DeepLabV3+中不同主干的比较试验中,具有ResNet101主干的DeepLabV2+具有最好的鲁棒性。它说明了具有ResNet主干的FCN也比具有VGG16主干的FCN好。SegNet是用上采样 不采样模型构建的,这可能有助于它在FGSM攻击下的鲁棒性。因此,其性能优于具有相同VGG16主干的FCN。一般来说,主干对模型鲁棒性的影响是显著的。由于其残差结构,ResNet是一个稳健的主干,可以融合先前卷积层的特征信息。
C. GD-UAP攻击的试验
图3显示了GD-UAP进攻的试验结果,DeepLabV3+在扰动预算 约束ε=5和ε=10下的mIoU高于其他模型。在DeepLabV3+中使用的主链中,当扰动预算 约束变得更高时,DeepLabV3+与Xception65主链的mIoU迅速降低。在FCN和DeepLabV3+的不同支柱中,ResNet50和ResNet101仍然是提高语义分割模型鲁棒性的主干。具有SPP结构的PSPNet在这次攻击中仍然表现不佳,因此我们推断SPP模块在网络中的作用是集成局部和全局特征以提高预测精度,但它无助于提高分割模型的鲁棒性。DeepLabV3+与MobileNetV2主干在GD-UAP攻击下的性能是非常突出的,其鲁棒性远高于具有其他主干的DeepLabV3+模型。
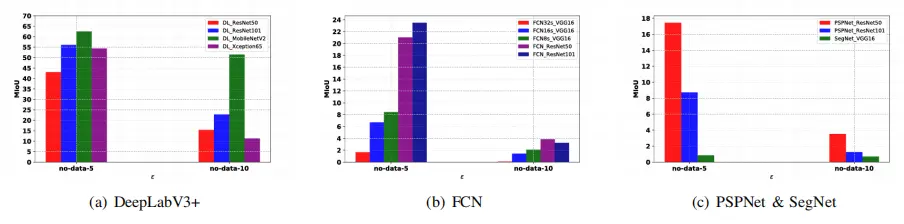
图3:在GD-UAP无数据(无数据)攻击下,最先进的模型在城市景观数据集上的鲁棒性
在之前的工作[29]中,有一种观点表明,ReLU是限定和限制神经网络模型鲁棒性的因素之一。在我们的消融试验中,激活功能ReLU6被整合到MobileNetV2主干中。图4显示,使用ReLU6的MobileNetV2主干的DeepLabV3+的mIoU是使用ReLU的相同主干的Deep LabV3+mIoU的两倍。GD-UAP的有效性在于通过过度激发激活函数来攻击分割模型。然而,ReLU6将激活函数的最大值限制为6,并抑制GD-UAP对模型激活函数的攻击。
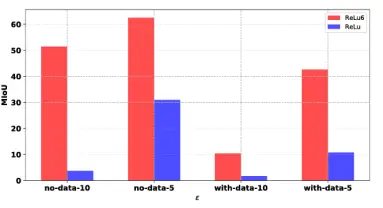
图4:具有不同ReLU和ReLU6函数的基于MobileNetv2主干的DeepLabV3+模型的不同l∞范数GD-UAP扰动的平均mIoU
除了无数据UAP攻击外,GD-UAP还可以使用训练数据集作为先验知识来训练对抗性扰动。通过使用训练数据集,试验结果与无数据模式下的结果相似。图5表明,DeepLabV3+仍然保持着较高的鲁棒性,ResNet是贡献鲁棒性的合适主干。
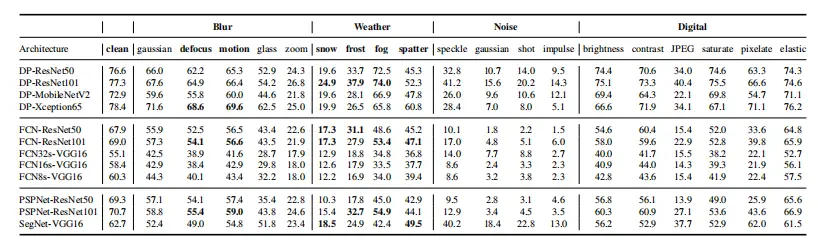
图5:GD-UAP下Cityscapes数据集上最先进模型在数据攻击下的鲁棒性
D. 图像损坏
在图像损坏中提供了19种不同类型的噪声。对于自动驾驶,我们关注异常天气、运动模糊和散焦模糊。其中,异常天气和飞溅是对图像的物理攻击,而运动模糊和散焦模糊是由车辆高速行驶时的相机失真引起的。因此,在试验中,分析这些黑匣子攻击对模型鲁棒性的影响至关重要。
表I:DeepLabV3+和其他模型的不同网络主干的验证集中干净和损坏图像的平均mIoU。每个mIoU在前三个严重级别上取平均值,因为最后两个级别的攻击会严重破坏图像质量。这些自动驾驶损坏类型中的最高mIoU用粗体突出显示。
表I显示,在异常天气(雪、雾、霜、飞溅)的情况下,DeepLabV3+比其他模型更稳健。在DeepLabV3+模型结构组中,具有ResNet主干的模型优于具有Xception65主干和MobileNetV2主干的模型。在FCN组的比较中,具有ResNet主干的模型也优于具有VGG16主干的模型,并且这样的模型的平均mIoU可以超过40%左右。尽管在干净图像下,具有ResNet主干的PSPNet的mIoU高于具有VGG16主干和ResNet主干的FCN的mIoU,但当语义分割模型受到这些黑箱攻击时,其mIoU显著下降,其性能甚至比具有ResNet主链的FCN差,原因是PSPNet学习到的特征是非鲁棒的。在散焦模糊攻击和运动模糊攻击下,DeepLabV3+与其他模型相比表现出较强的鲁棒性,ResNet也是用于语义分割的评估模型组内最健壮的主干。带有Xception主干的DeepLabV3+的性能显示出不同的特性。在模糊攻击中,即使与具有ResNet主干的DeepLabV3+相比,它也能获得更高的mIoU。这可能是因为这两个模糊对模型的干扰较小。
具有Xception主干的DeepLabV3+模型的分割性能在严重程度不高时不会下降太多(严重程度=1,2,3)。只有当严重程度较高(严重程度=5)时,对手才能导致具有Xception主干的DeepLabV3+模型的mIoU显著下降。
E. 讨论
基于上述试验结果,有几个发现很突出,这些发现与模型结构和环境数据扰动对鲁棒性的影响有关。
• 干净测试数据集上语义分割模型的高精度并不总是与对抗性扰动下的鲁棒性相关。在我们的试验中,在干净的测试数据集上具有高mIoU的PSPNet在对抗性扰动下很容易受到攻击。相比之下,具有相同主干的DeepLabV3+模型的性能退化较小,原因可能在于PSPNet学习到的非鲁棒性特征。
• 在我们的评估试验中,具有包含残差结构的主干(如ResNet)的语义分割模型通常比具有其他基于链的VGG主干和轻量级主干(如MobileNetV2)的相同语义分割模型更具鲁棒性。
• 具有Xception65主干的语义分割模型具有很高的分割精度。当l∞-范数扰动约束ε很小时,性能不会下降太多。然而,当扰动约束ε变大时,具有Xception主干的语义分割模型的鲁棒性比具有其他主干的模型差。
•GD-UAP攻击有效性的关键在于过度激活神经元。由于ReLU6函数通过抑制神经元过度激活的现象将其最大输出限制在6的值,因此具有激活函数ReLU6的语义分割模型比具有频繁使用的ReLU函数的模型更具鲁棒性。
•在模拟异常天气的黑盒攻击试验中,具有ResNet101主干的DeepLabV3+模型显示了最佳的鲁棒性性能,为建立符合SOTIF安全性要求的语义分割模型提供了参考。
05 结论
神经网络的脆弱性导致了安全关键型自动驾驶的潜在风险。为了解决分割模型的局限性,我们从两个方面研究了语义分割模型对自动驾驶的鲁棒性:模型层面的内部结构和数据层面的外部对抗性扰动。我们提出了鲁棒性分析框架,包括模型、对抗性攻击以及定性和定量分析。在两种白盒对抗性攻击(FGSM和GDUAP)和由图像破坏产生的黑盒攻击(模拟真实世界中的异常天气和相机失真)下,在具有不同主干的四个语义分割模型(FCN、SegNet、PSPNet和DeepLabV3+)上实现了评估。基于我们的试验结果,对不同对抗性攻击模式下语义分割模型的鲁棒性进行了全面分析,并得出了一些有意义的发现。这项实证工作可能会为自动驾驶中基于深度学习的视觉系统的研发过程提供一些参考。
参考文献


- 下一篇:基于特征鲁棒性增强的多摄像头下车辆识别方法
- 上一篇:智能的可变换性与鲁棒性



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
