




 广告
广告





















































技术揭秘 | 如何构建车载语音识别系统的鲁棒性?

首先需要明白,什么叫鲁棒性?
鲁棒性,其实是英文robust的音译,表示强壮、健壮的意思。而车载语音识别系统的鲁棒性就是指在面对车载环境中的高噪声、重口音、复杂场景和长尾POI输入时,也能保持较好的识别率。
随着语音交互在车载领域的覆盖率不断提升,大部分的用户都体验过车载语音助手带来的轻松驾车体验。
车载语音助手通过整合前端降噪、语音识别、语义理解、人声合成等多项AI能力,读懂用户驾驶时的服务需求。因此咱们只需要动动口,就能操控车载语音助手完成诸如空调控制、语音导航、开天窗、播音乐等一系列动作。
尽管车载语音助手使用起来很简单,但实际上,其系统内部的强鲁棒性无时无刻不在面临着困难挑战,而其中最主要的四大挑战则是:噪音、用户口音、海量POI、场景化。
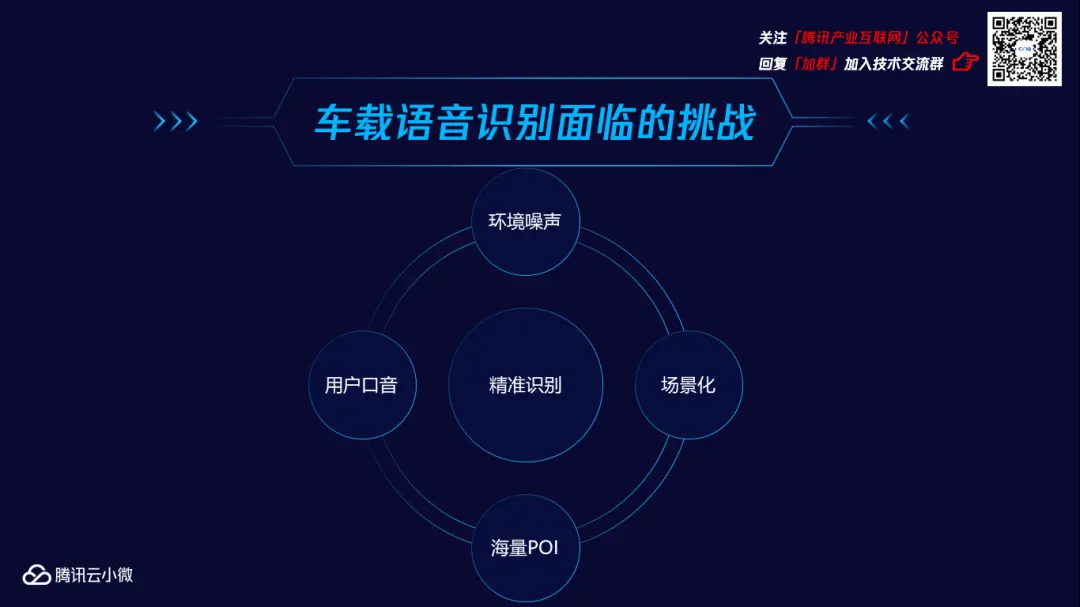
01 环境噪音挑战
大家有没有试过在电风扇旁与朋友打电话?扇叶转动发出的噪音往往会令通话质量变得很差,导致朋友无法听清我们的声音。在车机交互场景中也是如此:如果在车内、车窗旁的环境噪音过大,车载语音助手的识别功能就会被干扰,无法达到最优交互。
而在车机交互系统中,常见的噪音包括了路噪、风噪、空调和音响等不同类型。
02 用户口音挑战
当一个湖南人对着车载语音助手说“我要导航去胡建”,和一个福建人对车载语音助手说“我要导航到福南”,二者所面临的结果可能是一样的:车载语音助手无法进行正确的语音识别。
很明显,在整个语音识别体系中,比噪音更影响语音识别功能的因素,则是用户的口音和方言。
03 海量POI挑战
同时,海量的POI(point of information,信息点)也是干扰语音识别的“绊脚石”。举个简单例子,当你告知车载语音助手,需要导航到棠下,然而,广州天河区和白云区都有一个棠下。更甚,当告知其hongyuan酒店的时候,将会识别出云南大理(宏缘酒店)、广东揭阳(鸿源酒店)和广东东莞(宏远酒店)。
大量的POI,令车载语音助手无法迅速地进行语音识别的准确判断。
04 场景化挑战
不同场景化中用户的个性化需求,也作为影响语音识别功能的因素之一。当你告知车载语音助手一些较为生僻的特殊词汇,这时候它是无法识别的,就像让爸妈听专业的学术报告般,对特殊领域感到一头雾水。
对于语音识别系统也是一样,要求它适应各种领域的特殊用词是存在一定难度的。这便要求车载语音助手必须具备一定的灵活性和可配置性。
在语音识别的整个行业中,对构建其系统强鲁棒性的四个挑战是普遍存在的。当语音识别将人类的声音信号转化为文字或者指令时,用户口音、环境噪声、海量POI以及场景化语音均构成影响识别系统决策的变量,这便尤其考验语音识别系统的基础稳定性。
为此,腾讯云小微团队面对四大影响因素的难题挑战,不断对系统内部的各项AI技术进行迭代优化,目前给出了一份广获行业认可的优质解决方案。
解决方案1——针对环境噪音挑战
面对噪音带来的挑战,腾讯云小微团队采取了与内部、外部供应商合作的开发模式,从车内语音交互场景出发,共同打造了腾讯车载声学前端方案,对噪声进行抑制和回声消除。
除了可以有效抑制环境噪音外,总的来看,腾讯车载声学前端方案还具有以下几个优势:
第一,软件和硬件方案齐备。其中的软件前端方案由腾讯云小微团队与AILab联合打造,全链条均由腾讯自有技术构成。
第二,适用面广。可支持多种mic数量和布局,可覆盖前装和后装、高端和低端等多种车型。
第三,功能完备。可支持AEC、NS、DOA和多音区能力。
第四,接入迅速。腾讯云小微团队制定了声学前端准入的标准化测试流程,加速与第三方声学前端适配过程。
解决方案2——针对用户口音挑战
面对各地区用户口音的挑战,腾讯云小微团队采用了两种方案。
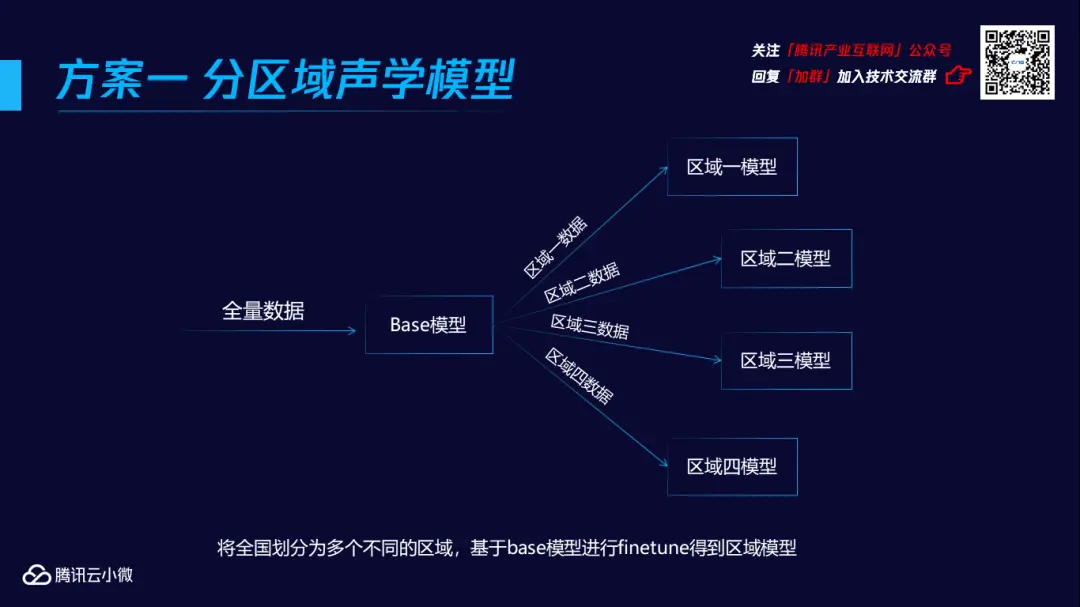
其一,采用了分区域声学模型,将全国划分为多个不同的区域,基于base模型进行finetune得到区域模型。
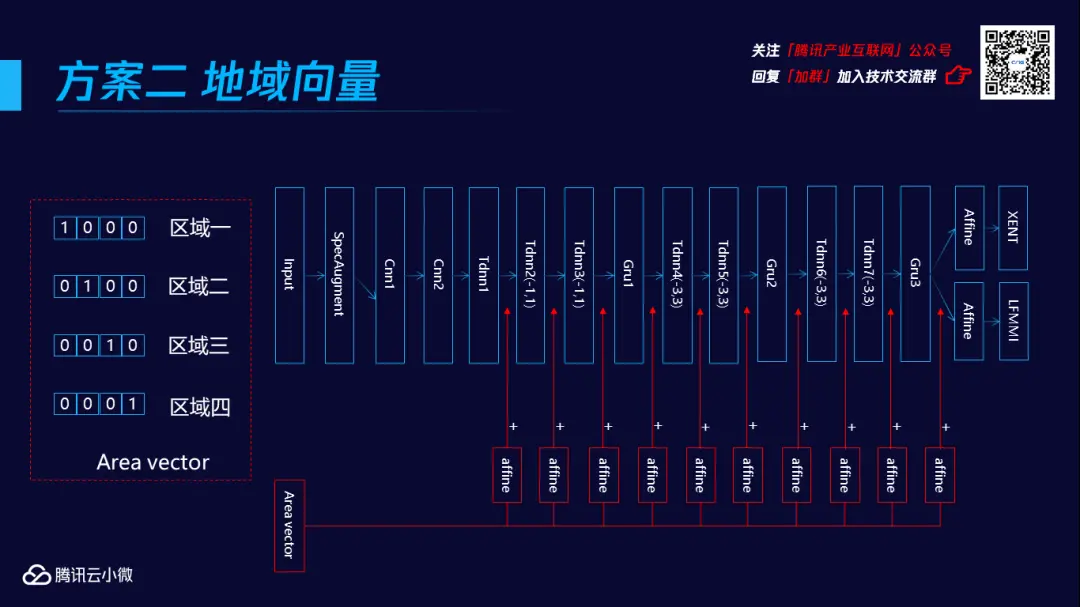
其二,腾讯云小微团队采取了地域向量,根据地域的划分,引入Area vector的向量,这个向量会输入到网络中,在网络训练时便将地域信息引入利用,以此帮助模型更好地进行分类应用。
同时,客户端上的GPS、语音请求与IP信息被解析为地域信息,为两种方案的模型提供解码方向。
关于这两种方案,分地域声学模型的训练和维护相对而言较为复杂,但它属于一个解耦的系统,方便针对某一个地域的模型进行优化;而地域向量声学模型则相对简单,但存在较大的耦合性。从最终效果上看,分地域声学模型的效果稍微更胜一筹,而整体上,两种方案都能获得5%-10%的性能提升。
解决方案3——针对海量POI挑战
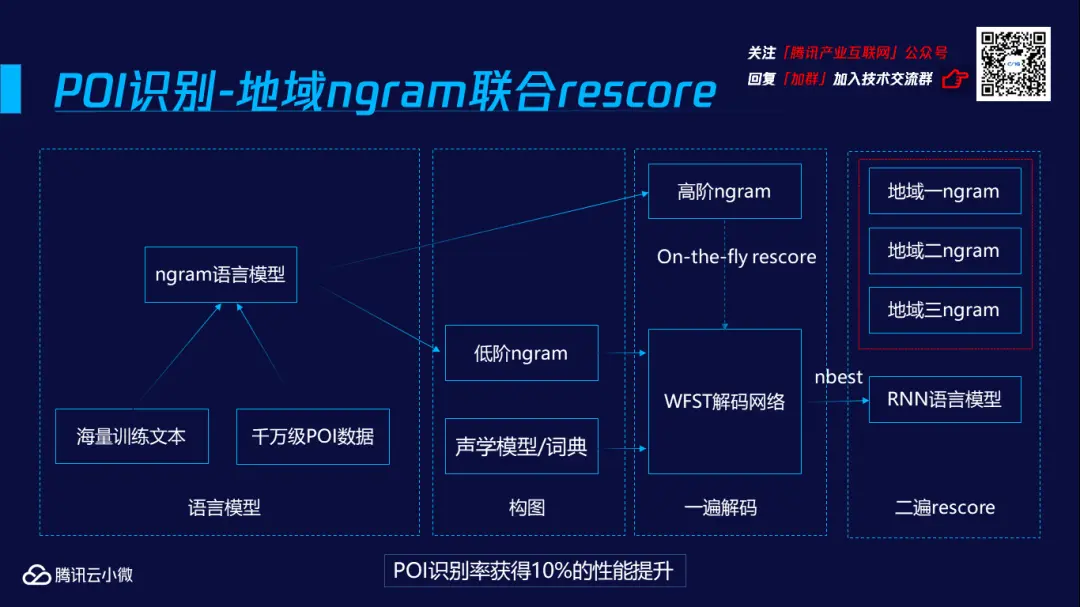
面对海量POI的挑战,腾讯云小微团队引入了两个技术:地域ngram联合rescore技术和长尾POI后处理能力。
例如hongyuan酒店分别在云南大理(宏缘酒店)、广东揭阳(鸿源酒店)和广东东莞(宏远酒店)存在,地域ngram联合rescore技术便可以帮助车载语音助手识别该酒店是位于云南还是广东,而长尾POI后处理能力则是进行了更细腻的划分,协助识别是揭阳还是东莞。
利用海量训练文本和千万级POI数据训练ngram语言模型,将该模型分为低阶ngram和高阶ngram两部分。低阶ngram与声学模型/词典通过构图生成WFST解码网络,除此之外,高阶ngram也会执行on the fly rescore的操作,进一步地提升识别效果,完成一遍解码。在一遍解码获得nbest的识别结果后,还会利用神经网络语言进行二遍rescore,而不同地域ngram的语言模型则在这个模块中联合rescore进行POI识别。地域ngram联合rescore技术能令POI识别率获得10%的性能提升。
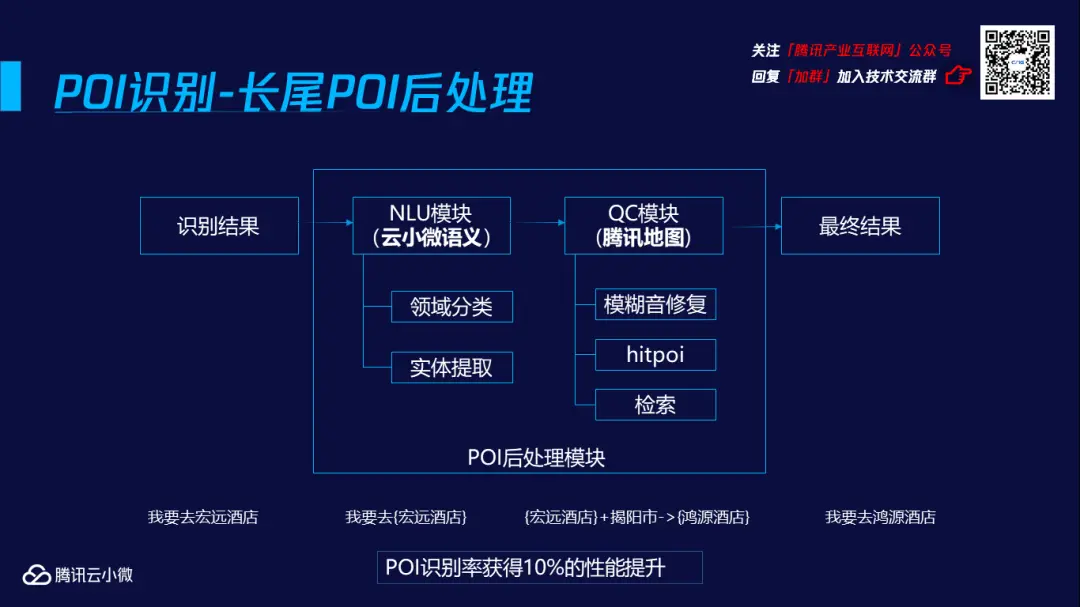
关于长尾POI后处理技术,包含两个大模块,一是云小微语义团队提供的NLU模块,负责领域分类与实体提取;二是腾讯地图提供的QC模块,负责模糊音修复、hitpoi和检索。在搜索hongyuan酒店时,NLU模块会将hongyuan酒店作为实体,与用户所在地一同输送至QC模块,进行模糊音修复和检索,得到最终结果——hongyuan酒店+揭阳市=鸿源酒店(揭阳)。至此,长尾POI后处理技术将POI识别率进行了10%的性能提升。
解决方案4——针对场景化挑战
面对不同场景化的挑战,腾讯云小微团队针对特殊词汇、个性化句式、个性化领域的典型场景化需求,分别提出了三种技术方案——Hotfix增强技术、Grammar增强技术和文本自学习增强技术。
三种增强技术方案满足了不同场景的产品需求,大幅提升场景化的识别结果,可以提供更好的语音交互体验。



编辑推荐




最新资讯
-
Rivian与MAE合作定制电动车测试设备安装项
2025-04-10 14:41
-
重型商用车辆和客车的动力学——操纵性
2025-04-10 14:40
-
新能源汽车VCU、BMS、MCU控制器图解
2025-04-10 14:39
-
陶琳回应电动车辐射高:特斯拉辐射值远低于
2025-04-10 13:14
-
nCode2025版本发布说明
2025-04-10 13:12
