




 广告
广告





















































一文看懂ASAM MDF标准

1. ASAM MDF标准概述
MDF(Measurement Data Format,测量数据格式)是一种二进制文件格式,用于存储记录或计算的数据,以进行后续处理、离线评估或长期存储。该格式已成为测量和校准系统(measurement & calibration)的事实标准,但也在许多其他领域中得到广泛应用。
作为一种紧凑的二进制格式,ASAM MDF提供了对海量测量数据的高效及高性能存储方案。MDF由松散耦合的二进制块组成,以实现灵活且高性能的写入和读取。通过无损重新组织(即排序)数据,可以基于索引快速访问每个样本,分布式数据块甚至可以直接写入排序后的MDF文件。该文件格式允许存储原始测量值和相应的转换公式;因此,原始数据仍然可以被后处理工具正确读取、解释和评估。
自从成为ASAM标准以来,MDF一直与其他ASAM标准(如MCD-2 MC(ASAP2)或ODS)密切配合进行开发。因此,ASAM MDF支持在汽车领域特别需要的特殊数据类型和信息,例如结构(structure)和数组(曲线/地图)、总线事件和同步视频数据等。
除了普通的测量数据和所有必要的元信息以便于解读,MDF还可以在同一文件中存储描述性和可自定义的附加数据。ASAM MDF通过通用的XML片段和一系列新功能(如自定义信号分组、事件或附件)提供灵活的可扩展性。
MDF核心功能包括:
ECU变参数测量
总线数据测量
测量数据存储(Storage)
测量数据归档(Archiving)
2. ASAM MDF标准历程回顾
part 2.1 起源(32bit数据时代)
MDF最初由Vector Informatik GmbH和Robert Bosch GmbH在90年代开发为专用文件格式。它的设计针对于汽车行业,主要用于ECU开发、校准和测试领域。经过多年发展,该格式已经发展成为业界事实上的标准,并得到市场上许多工具的支持,特别是在测量和校准领域。MDF格式得到认可的重要原因是其稳定性和兼容性。
直到MDF 4.0版本之前,该标准并非由ASAM负责维护。
第一个公开版本是1991年发布的MDF 2.0;MDF 3.0在2002年发布。多年来的版本迭代逐渐添加了一些扩展功能。目前的非ASAM版本MDF 3.3仍然完全向后兼容所有的MDF 2.x和3.x版本。
然而,由于在老版本中使用了32位数据类型,专有的MDF 3.x格式的文件大小限制为4 GB。因为1991年刚发布时,无法预见到测量数据和文件大小的快速增长:世纪之交后,涌现出越来越多的要求更新MDF以支持更大的文件大小并满足现今的需求。此外,主要的整车制造商和零部件供应商表示希望将MDF转换为更加通用的行业标准。
part 2.2 ASAM标准(64bit数据时代)
在交由ASAM进行维护后,ASAM于2008年开始对MDF进行修订和标准化,并成立专门的工作组。2009年,ASAM MDF 4.0版本正式发布。

ASAM MDF 4.0克服了先前MDF 3.x版本的大小限制,并提供了一系列新功能,如通过XML的灵活扩展性、自定义信号分组、事件或附件等。然而,由于诸如64位数据类型用于链接的基本变化,MDF 4.x不再与MDF 3.x兼容。
尽管如此,MDF 4.0被行业相当迅速地采用,并得到越来越多工具的支持。ASAM MDF 4.1版本于2012年推出,主要更新了以下内容:
测量数据的压缩
对具有恒定值或可变数据长度的通道进行内存高效存储
存储常见总线系统的总线通信
存储分类结果
存储关于测量环境的附加信息
part 2.3 ASAM MDF 4.2.0
2019年,ASAM发布MDF4.2.0版本,进一步优化了存储数据的读取表现。其中一项重要更新是支持列导向(Column-oriented)数据存储。
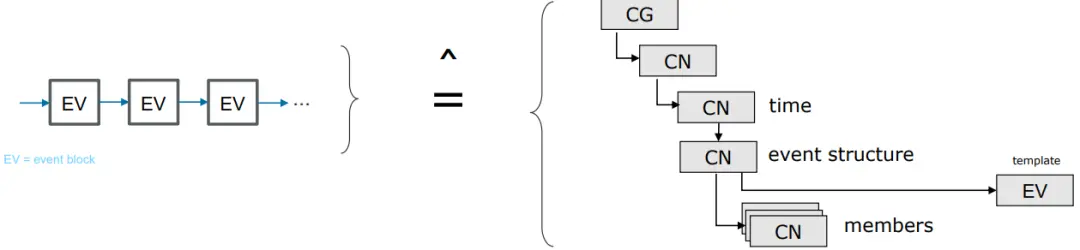
使用列式存储,不会从磁盘中获取用户未请求的信号通道数据。在先前的排序配置中,必须获取通道组中的所有通道数据。
列式存储不适用于直接记录,因为需要提供额外的缓冲资源。
硬核分析
什么是行存储与列存储?
在大多数的OLTP(onLine TransactionProcessor,在线联机事务处理系统)数据库中,存储是以行为导向(row-oriented)风格的,表中的行数据都是挨着存储。文档数据库类似,整个文档一般存储为连续的二进制数据。
以列导向的存储背后的思想很简单:不要将一行中所有的值存在一起,而是将一列中所有值存在一起。如果每一列都存在单独的文件里查询只需要读取和解析那些查询中使用列,这能省下很多工作并提升效率。
行存储与列存储各自的特性?
行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网和智能网联汽车领域,显得犹为重要。



编辑推荐




最新资讯
-
飞书项目落地ASPICE解决方案,助力汽车软件
2025-04-24 09:59
-
驾驶员监控系统DMS合规认证的“中西结合”
2025-04-24 08:23
-
自动驾驶汽车测试关键行人场景生成
2025-04-23 17:12
-
R171.01对DCAS的要求⑧
2025-04-23 17:08
-
迄今为止最先进的版本:imc发布全新imc STU
2025-04-23 17:06
