




 广告
广告





















































Cache基本原理--以TC3xx为例

目录
1.为什么要使用Cache
2.Memory与Cache如何映射
2.1 地址映射概述
2.2 Cache映射模式
3.DCache的数据一致性
4.小结
为什么要使用Cache?为什么在多核工程里要谨慎使用DCache?Cache里的数据、指令是如何与Memory映射?灵魂三连后,软件工程师应该都会有模糊的回答:大概是为了运行更快,减小系统负载。但是再往下深入思考上面问题,我自己发现对于Cache原理的理解比较欠缺,网上资料纷繁复杂。因此,梳理并总结其原理,为后续系统性能优化打下基础。
1. 为什么要使用Cache
大家都知道,当系统负载较大时,首先要检查的就是是否打开ICache,那么从硬件层面Cache在MCU\SOC的哪个位置?
这里首先祭出一张包浆的老图:
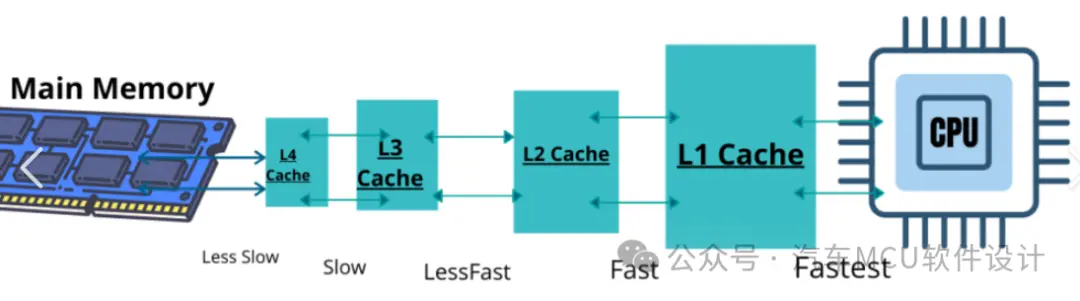
Cache位于CPU和主存之间,分为了L1-Ln Cache,每种cache访问速度有区别;
回归到MCU中,以TC37x为例,Cache分为了PCache(指令缓存)和DCache(数据缓存)。那么为什么加了Cache就会提供系统运行速度呢?
以实际生活场景为例:超市里面的东西很丰富,但是所需要的存储空间很大,而我要去超市买想要的东西,还得走路、选商品、搬回来,这中间耗费的时间和劳动力可想而知;但是因为有了冰箱,一切就方便了许多;不过冰箱容量就那么大,所以会把常用的东西一次性从超市搬过来暂存至冰箱里,下一次我再想用这些物品时从冰箱里拿取,是不是就节省了很多时间?
这里,人是CPU,超市就是主存,冰箱就是Cache,冰箱里放置的常用物品,咱们就可以理解为那些被经常调用的函数、数据等等,这就是Cache的局部性原理之一----时间局部性。
时间局部性:当前正在提取的数据或指令可能很快就需要,因此将数据或指令存储在缓存中,这样可以避免再次在主存中搜索相同的数据。例如代码循环里的数据等。
Cache局部性原理之二 ,即空间局部性---主要是指存储在最近执行的指令附近的所有指令都有很高的执行机会。同时指的是对存储位置相对较近的数据元素(指令)的使用。我们常常听到的Cache Hit就是我从冰箱里拿到想要的东西(对应CPU),而Cache Miss就是冰箱里没有目标东西了,得到超市进货了,但是这个进货原则需要协商:这个进货原则就是Cache替换算法。
好了,关于Cache的基本概念我们以超市、冰箱做类比应该比较容易理解。
不过仔细想想,超市东西这么多,如何保证冰箱里的东西和超市的东西一致呢?这就不得不提分类、编号思想了。
2.Memory与Cache如何映射
以分类编号来思考这个问题,一切迎刃而解。
2.1 地址映射概述
一般来说,主存会以Cache的大小为基本单位划分为多个块,如下图:
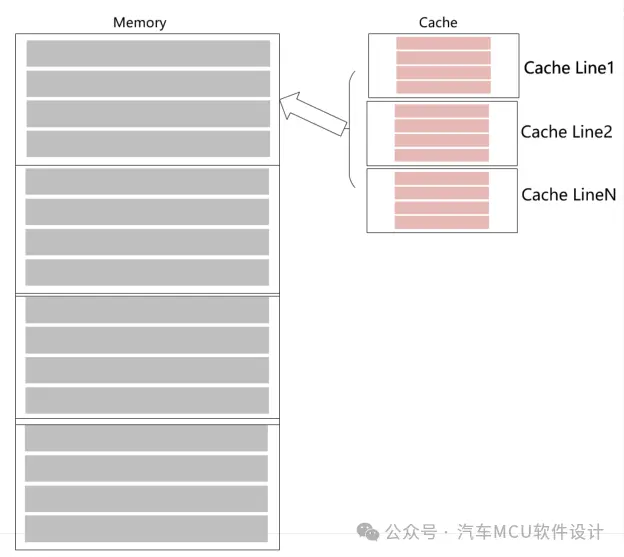
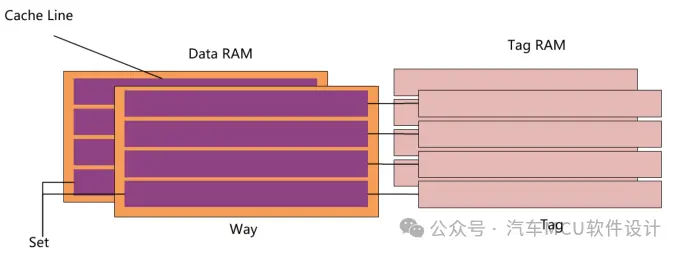
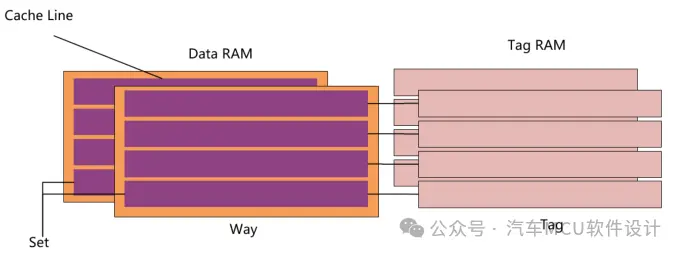
Cache内部组成包含Cache控制器和两块SRAM(Tag RAM、DATA RAM)。
其中Data RAM用于存放数据(指令),其基本单位称为Cache line,例如TC3xx DCache Line大小为256bit(32Bytes)。
根据DCache 16KB,可以算出有多少个Cache Line。那么什么是Tag?这就不得不提到主存地址,一般来讲,主存地址由tag、set/index和offset组成,如下:
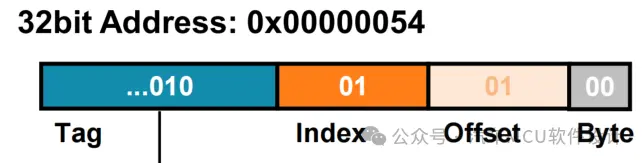
其中Set\Index用于定位Cache中的哪一个Cache Line,Offset用于定位Cache Line中的哪一个Bytes,Tag用于标识请求的是主存哪一个数据块,假设现在Cache Line为256Bits,Cache大小为4KB,Cache Line个数就为4096/32=128,根据上述地址定义,如下图:
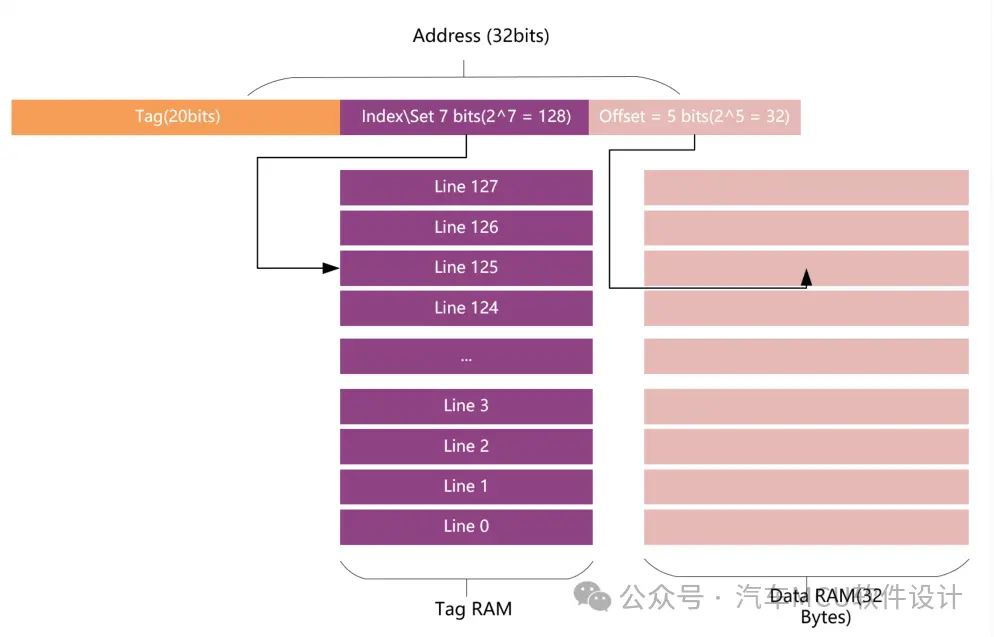
这个概念搞清楚了,我们就能理解TC3xx UserMannul提到的DCache、DTag。紧接着我们来看,memory与Cache的映射方式。
2.2 Cache映射模式
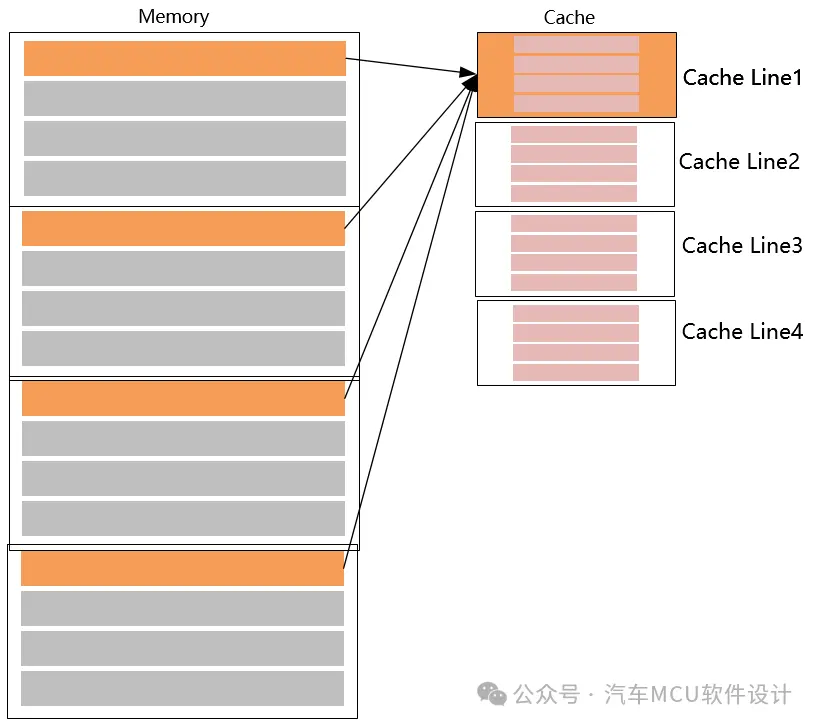
常见的Cache地址映射模式包括直接映射、组相联和全相联。直接映射(Direct Mapping):在直接映射中,每个主存地址只能映射到Cache中的唯一一行。这意味着主存中不同块可能会填充到相同的Cache Line里。如下图:
组相联(Set Associative Mapping) :Cache被划分为多个Set,每个Set包含多个Way的Cache Line。主存地址被映射到某个Set,然后在该Set内进行查找。每个Set内的CacheLine数量通常是2的幂次方,例如2、4、8等。组相联映射通过减少冲突提高了缓存的性能。上面有点晕不要慌,这里就不得不来点术语了。如下图所示:
Way -- 相当于Cache的一页,如上述示例,Cache就有2 WaysSet -- 每个Way里的同一Cache Line组成Set
这里理解了,英飞凌描述的2-way set associative DCache是不是就手拿把攥了。
英飞凌每个CPU都有16K DCache,Cache Line为32Bytes,因此总共有512个Cache Line。那么针对memory地址就可以分为:

我们计算非Tag后的偏移2^14 = 16KB,这也与Cache Size刚好对上。 全相联映射(Fully Associative Mapping): 主存地址可以映射
Cache中的任何一行,而不受限制于特定的组。这意味着任何Cache Line都可以存储任何主存地址的数据。全相联映射通常需要更多的硬件支
持,如标记比较电路,但可以最大程度地减少冲突,提高缓存的命中率。
3. DCache的数据一致性
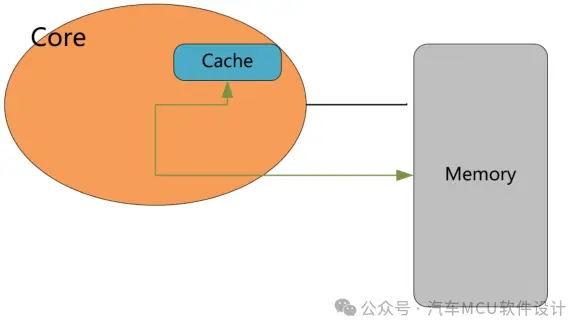
谈到DCache的数据一致性,就不得不先讨论Cache的写策略。常见的Cache写策略分为Write-Through和Write-Back。Write-Through :修改数据时,该修改会同时作用在Cache和Memory中,如下图:
Write-Back:修改数据时,会先发生在Cache里,Memory中的母本更新会等待一些时间:
以英飞凌TC3xx系列为例,我们来看它是如何出现数据一致性问题的(注意TC3xx是Write Back Cache)。

CPU0\1共享LMU0,CPU0和CPU1修改LMU0[3]的值 3->9、LMU0[2]的值 2 -> 8,我们可以看到LMU0里的值确实变为了9,但是思考一下,这时候CPU1去获取LMU0[3],应该是几?当然是Cache里面的3,这里数据就不一致了。
紧接着由于CPU1中的Cache数据改变也反映到了LMU0中,此时可以发现,LMU0[3]变为了3,cpu0的修改出现了丢失了。因为Cache的更新至少得以Cache Line为单位。
那么,如何来避免这些问题呢?翻看TC3xx Aurix 内核手册,可以得到以下几种方式:
使用cachea指令:cachea.wi将写策略强制更新为write-through;cachea.i重刷cache;
使用英飞凌提供的Non-cache地址,例如LMU使用0xB开头;
4. 小结
以上,我们简述了cache的基本原理,从软件工程师角度,了解Cache,知道Cache通常会带来什么好处,引起什么问题,这对我们在系统层级的性能优化是有巨大帮助的。
- 下一篇:自动驾驶地方立法的规范框架与基本思路
- 上一篇:一氧化碳对膜电极性能的影响



 广告
广告  广告
广告
编辑推荐




最新资讯
-
荷兰Zepp氢燃料电池卡车-Europa
2024-12-22 10:13
-
NCACFE -车队油耗经济性报告(2024版)
2024-12-22 10:11
-
R54法规对商用车轮胎的要求(上)
2024-12-22 10:10
-
蔚来ET9数字架构解析
2024-12-22 09:53
-
4G/5G网络新时代的高效紧急呼叫系统NG-eCal
2024-12-20 22:33
 广告
广告 广告
广告
