




 广告
广告





















































在真实道路上使用切换软演员-批评家模型的悬架控制策略

编者按:本文介绍了一种创新方法,利用软演员-评论家 (SAC) 算法在实际道路条件下优化半主动悬架系统的性能。面对多样化的路面状况,包括减速带和普通路段,本研究提出了一种深度强化学习技术,能适应截然不同的奖励环境,最初在仿真环境中得到验证。我们开发的切换学习系统能够即时识别并区分两种道路扰动类型,从而针对性地调整和应用SAC模型。通过对比,我们的切换SAC算法在处理z-车身质量中心定向加速度和俯仰方面超越了先进的传统悬架系统。实验结果证实,经过训练的SAC模型有效降低了z-方向加速度和俯仰角度,与仿真成果相符,显著提升了乘车舒适度和车辆操控性。这一成就已在真实世界测试中得到证实,即在实际道路上对一辆汽车进行SAC训练,其效果超越了传统控制策略,彰显了深度强化学习在车辆动态控制系统中的巨大潜力。
本文译自:
《Suspension Control Strategies Using Switched Soft Actor-Critic Models for Real Roads》
文章来源:
IEEE Transactions on Industrial Electronics, vol. 70, no. 1, pp. 824-832, Jan. 2023
作者:
Hwanmoo Yong, Joohwan Seo, Jaeyoung Kim, Myounghoe Kim, and Jongeun Choi
作者单位:
HwanmooYong、Myounghoe Kim和Jongeun Choi:延世大学机械工程学院,韩国首尔;Joohwan Seo:加州大学伯克利分校机械工程系,伯克利;JaeyoungKim:现代汽车集团研发部,韩国
原文链接:
https://ieeexplore.ieee.org/document/9724132
摘要:在本文中,我们提出了在真实道路上使用软演员-评论家 (SAC)模型为整车中半主动悬架系统的学习和控制策略,其中存在许多具有不同干扰能力的道路剖面(例如,减速带和一般道路)。因此,提出了一种能够使深度强化学习覆盖不同领域的技术,这些领域具有很大不同的奖励函数。这个概念最初是在模拟环境中实现的。我们提出的开关学习系统可以实时连续识别两种不同的道路扰动曲线,以便可以相应地学习和应用适当设计的SAC模型。将所提出的开关SAC算法的结果与先进和传统的基准悬架系统的结果进行了比较。基于结果,所提算法显示z-车身质量中心的定向加速度和俯仰。最后,我们还展示了我们在真实道路上的真实汽车中成功实施的SAC培训系统。经过训练的 SAC 模型优于传统控制器,可降低z-定向加速度和俯仰,与仿真结果相似,与乘坐舒适性和车辆机动性高度相关。
关键词:深度强化学习,整车悬架系统,半主动悬架,软演员-评论家
Ⅰ 引言
车辆悬架系统在确保稳定性、驾驶安全性和乘坐舒适性方面发挥着重要作用。然而,传统的被动悬架通常不能满足这些性能要求。由于参数是固定的,因此无法更改被动悬架系统的动态,这限制了性能预期。被动悬架系统的上述缺点可以通过采用具有可调动态参数的受控悬架来克服[1-2]。主动悬架能够增加和耗散能量,用于各种商用车,以提高乘坐舒适性和稳定性 [3-5]。然而,在车身和轮胎之间配备了额外的执行器,例如液压执行器,导致制造成本增加。与其他类型的受控悬架相比,半主动悬架具有许多优势,因此最近引起了人们的极大关注。半主动悬架的主要优点之一是它们在产品成本和性能之间进行了权衡[6],[7]。
受控悬架研究的主要重点是开发控制策略和算法,以充分利用半主动悬架系统。利用半主动悬挂系统的最流行的控制算法是天钩(SH)框架[8-10]。汽车工业中的SH控制在隔振方面以较低的成本提供公平的车辆性能,即乘坐舒适性,并且易于应用。在基本SH控制[11]的基础上,通过添加最优性和适应性[12]等变体,提出了SH控制策略的许多变体。
模型预测控制(MPC)是另一种先进的控制方案,用于控制整车的半主动悬架系统[13]。使用MPC和额外传感器(例如摄像头和激光位置传感器)的预览控制系统可显著提高乘坐舒适性[14-15]。然而,MPC需要从额外的传感器获得完整的状态信息,这在实践中成本很高[16-17]。在感官测量有限的情况下,可以使用带有积分器的卡尔曼滤波来重建完整状态,尽管这可能会导致状态估计不佳[18-19]。
半主动悬架系统表现出高度非线性特性,例如滞后,这些特性难以建模。这种非线性会严重降低不考虑它们的控制设计的性能。基于神经网络的控制方法在处理非线性问题时具有优势[20],当训练有充分的先验信息时。在[21]中,提出了一种基于动力学的安全深度强化学习(DRL)算法。DRL算法研究的最新进展,如信任区域策略优化[22]、近端策略优化(PPO)[23]和软参与者-批评者(SAC)[24],已经导致DRL在许多其他控制应用中的应用[25-26]。特别是,SAC采用了最大熵公式,大大提高了探索性和鲁棒性[27]。
然而,在实际的道路情况下,有许多道路剖面具有各种干扰力。一般道路会以持续的干扰扰乱系统,减速带可以被视为对系统的脉冲。[1]采用深度确定性策略梯度(DDPG)算法控制单一类型道路扰动下四分之一车的半主动悬架系统。但是,经过训练的 DRL 模型在遇到减速带时预计不会充分表现。这是由于 DRL 模型缺乏对此类脉冲信号的训练。在这种情况下,将 DRL 应用于具有实际道路扰动的悬架系统可能很困难。Doya 等人。[28] 使用强化学习 (RL) 将复杂任务分解为多个域,以解决网格世界问题和非线性非平稳控制任务。
本文的贡献如下。
1)为了解决上述问题,我们提出了用于训练和利用SAC模型的切换算法,这些模型在现实驾驶场景中控制整车的半主动悬架。
2)所提出的脉冲检测器可以实时识别扰动域,以选择相应的SAC模型。这样就可以将正确的 SAC 模型应用于系统。
3)基准仿真研究表明,我们的方法在方向加速度、滚动和俯仰的均方根(rms)值方面与先进和传统控制器(例如MPC、SH和被动悬架)相比是有效的。
4)SAC培训系统在真实道路剖面上成功实施。在真实汽车中训练的SAC模型显示出比传统工业悬架系统更高的性能,就像在仿真环境中一样。
Ⅱ 问题定义
A. 道路扰动与整车模型
根据扰动信号的功率,将道路扰动分为2种类型:以ISO8608表示的具有稳定扰动的非脉冲路面和脉冲路面。
1) ISO8608道路剖面图
具有非脉冲扰动的路面的随机特征已被公认为ISO8608标准。因此,基于[29]创建了ISO8608的道路扰动模型。对于每一集,该算法都会创建一个 B 级道路剖面图。随后,利用车辆在合理范围内随机选择的纵向速度,创建每个轮胎的路况的时序数据。根据 [29] 中 B 类道路的速度限制,假设纵向车速在 范围内。剧集长度选择为20 s,采样时间为0.01 s。用于在空间域中生成随机道路剖面的算法如下[30]:
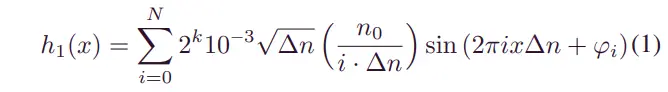
其中 是数据点的数量,是空间采样频率,是参考空间频率,是根据 ISO8608 类选择的,表示随机相位,。
2) 脉冲路面
脉冲路面与ISO8608路面在系统需要恢复的瞬态响应方面有所不同。最常用的减速带是椭球体[31],或椭球体的一部分。椭球形减速带作为脉冲路面的典型案例进行模拟,具体如下:
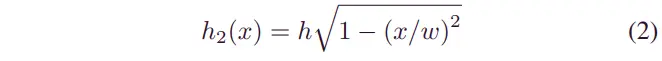
其中和分别表示减速带的高度和宽度。车辆的纵向速度设置为()。为了开发一个鲁棒的DRL模型,分别在()和()的范围内随机选择和。
3)整车模型
我们考虑[19]中的非线性整车悬架模型。由于页数限制,本文省略了模型方程。在整篇文章中, 和分别是重心的z方向位置和速度值。和分别是车身质量中心的滚动和俯仰。和分别是围绕轴和轴的角速度值。 和分别是弹簧质量在位置处的方向位置和速度值。这里,表示弹簧和悬架的位置,即。和分别是簧下质量在位置处的方向位置和速度值。最后,是道路扰动。
然后,在MATLAB和Simulink环境中使用Simscape Multibody Toolbox对整车模型进行建模[32]。
B. 半主动悬架
采用Bingham模型作为半主动悬架静态模型[33]。Bingham 模型通常表示为。其中是悬架在位置的阻尼力,例如,,是动态屈服力,与施加在半主动悬架上的电流有关,是阻尼常数,其中。考虑到 DRL 模型中的动作通常由 给出,我们让
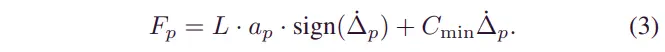
因此,动作可以直接转换为电流值,确保半主动悬架的力满足耗散条件。
C. 带半主动悬架的测试车
我们使用配备半主动悬架和控制器局域网 (CAN) 接口的乘用车设置测试车。我们在测试赛道上驾驶测试车,其路面符合ISO8608标准。测试电路由两部分组成:ISO8608标准中等于A级的软路和ISO8608标准中介于C级和D级之间的崎岖路面。
Ⅲ 求解方案
在本节中,我们将介绍用于解决给定问题的方法。这些方法包括 DRL 算法、用于训练多个 SAC 模型以解决给定问题的切换算法以及硬件实现。
A. RL算法
通常,标准 DRL 算法旨在最大化一系列操作下的预期奖励总和。标准 DRL 算法的目标函数如下:
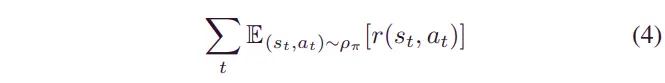
其中表示给定状态下的奖励,操作。表示在给定状态下的期望值和基于策略的操作。
为了为所提出的方法选择合适的DRL算法,我们比较了DRL模型(即SAC、PPO和DDPG算法)在给定问题中的训练效率。选择等式(9)作为奖励函数。将第II-A节中描述的ISO8608路面和整车模型用作仿真环境。从图1中可以看出,SAC模型的平均奖励在DRL算法中是最高的。因此,我们采用了SAC作为所提出的方法。
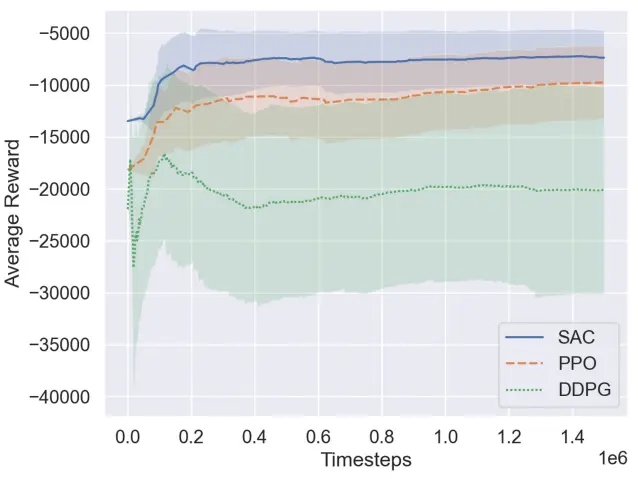
图1. PPO、SAC 和 DDPG 模型的平均奖励图。
与其他 DRL 模型相比,SAC 将策略的熵包含在其目标函数中。SAC 的目标函数如下:
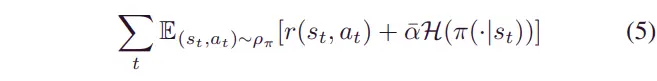
其中表示熵项。温度参数权衡奖励项和熵项之间的重要性。最大熵对象的优点是智能体在训练时会探索更多,因为随着智能体采取的不同操作数量的增加,获得的熵也会增加。利用软贝尔曼方程[34]得到最大熵目标的最优解:
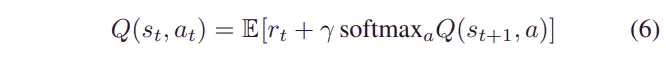
其中,是 函数,用于描述在状态下执行操作后的预期奖励总和。是时间的奖励值,是折扣因子。softmax 函数定义为。
鉴于 SAC 在训练期间更频繁地探索,它不太可能落入局部最优状态。这很重要,因为我们使用的整车环境是随机干扰的。在训练 SAC 模型时,我们使用 0.99 作为折扣因子,64 作为批量大小,3e-4作为学习率,以及一个 (64, 64) 网络,在演员和批评者网络中具有整流线性单元 [35] 激活函数。模型和超参数基于 [36] 中的开源实现。
B. 切换 DRL 训练-实现算法
在本文中,我们提出了用于训练和利用可以处理各种领域的多个 SAC 模型的算法。图2描述了开关SAC算法的基本轮廓。为了确定哪种SAC模型应该起作用,使用了脉冲检测器(算法1)[见图2(a)]。如第II-A节所述,图2中脉冲路和一般路的SAC模型涉及不同的域。随后,其中一个 SAC 模型产生的控制信号被馈送到平台。
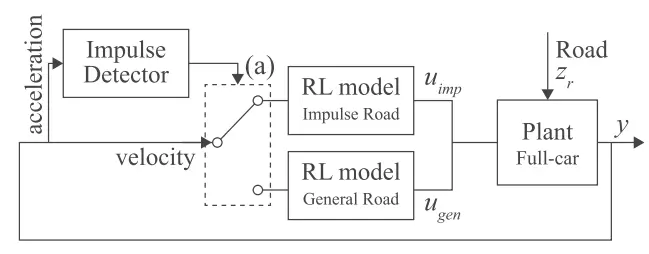
图 2.脉冲检测器对道路扰动进行分类,并将信号发送到开关(a)。和分别是 SAC 模型为脉冲道路剖面和一般道路剖面生成的控制输入。
在II-A节中,我们描述了具有两种不同类型的道路剖面的道路扰动模型,可以根据脉冲信号的大小进行分类。开发了一种脉冲检测算法,用于在实时训练的同时对道路剖面类型进行分类。所提出的脉冲检测算法检测脉冲信号到达系统(进入)和系统恢复到原始状态(退出)的时刻。
应用不同的移动平均过滤器,并为进入和退出情况设置加速度阈值。利用移动平均滤波器和加速度阈值来调整检测算法的灵敏度。监测质心左前点和右前点的加速状态()的平均值()。算法1总结了脉冲检测器的详细算法,变量在表I中列出。
表I.脉冲检测器中的变量

我们算法的主要思想是两种不同的SAC模型处理两种不同类型的路况。SAC车型根据路况进行切换。然而,具有非平滑瞬态响应的开关控制器会导致性能下降和机械损伤,例如疲劳累积[37]。为了提供平滑的瞬态响应,我们采用了停留时间方法,其灵感来自[37]中提出的插值函数,如下所示:
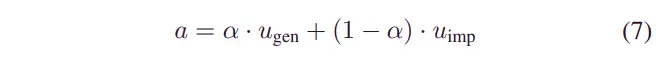
其中,表示 SAC 模型针对一般路况(ISO8608剖面)生成的控制输入,表示 SAC 模型对脉冲路况的控制输入,表示车辆离开脉冲路况所需的时间,表示用于处理开关速度的调谐参数。例如,如果增加,则切换所需的时间会增加,反之亦然。
图3显示了仿真过程中的解释性加速度响应()和道路扰动。随机生成的减速带位于图 3 中的第 7 秒附近。当应用所提出的算法时,观察到三个不同的区域,一个是一般道路区域[见图3(a)和(d)],一个脉冲道路区域[见图3(b)],以及一个瞬态区域[见图3(c)]。在一般道路区域,可以解决ISO8608道路扰动的SAC模型被激活。但是,在脉冲路区域,用于处理脉冲响应的 SAC 模型被激活。这是因为即使脉冲路面已经完成,道路扰动也转移回ISO8608剖面图,但与一般路面的响应相比,系统的响应更高[见图3(a)]。因此,脉冲路面区域的 SAC 模型控制系统,直到脉冲检测器发送指示系统已稳定下来的信号。随后,在瞬态区域,应用驻留时间方法实现控制器之间的平滑过渡。当脉冲信号发生时[在图3(a)和(b)之间],不应用停留时间方法,因为此时对脉冲信号的即时响应很重要。
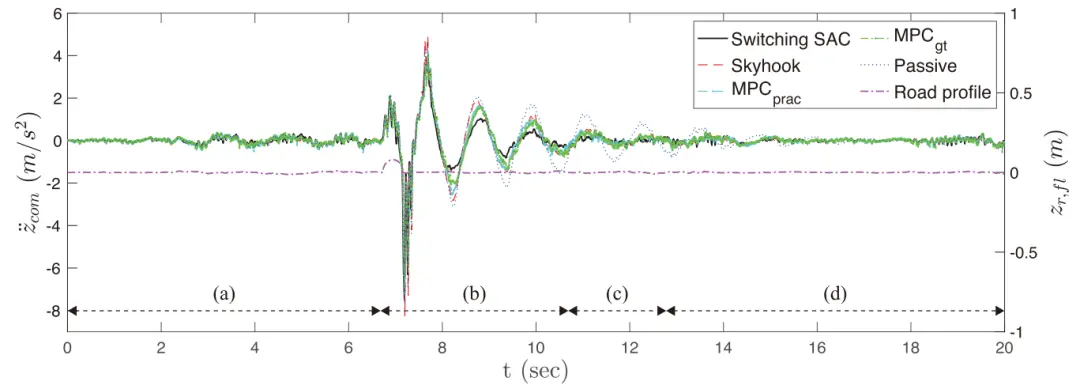
图 3.质心处的加速度响应()和其中一个测试数据集的道路剖面。黑色实线表示使用SAC的算法的加速度响应;洋红色虚线表示道路剖面;黑色虚线表示根据道路扰动和加速响应的切换区域。
SH 控制器用作辅助控制器,而不是同时训练两个 DRL 模型。例如,在一般道路区域训练 DRL 模型时,选择 SH 控制器作为脉冲道路的辅助控制器,反之亦然(见图 4)。这种策略有效地使整个系统在训练期间更加稳定,因为辅助控制器减少了随机初始化的 SAC 代理可能产生的不需要的响应的数量。
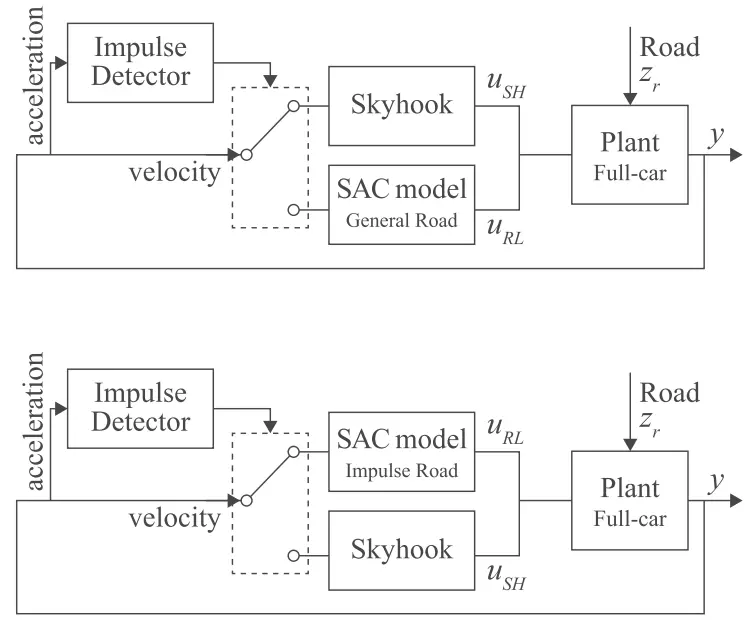
图 4.(a) SH控制器处理一般道路区域,SAC模型处理脉冲道路区域。(b) SH控制器处理脉冲路面区域,SAC模型处理一般区域。在瞬态区域中,生成或的 SH 控制器和 SAC 模型都使用驻留时间方法处理道路区域。
C. 硬件实现
为了确定第IV-A节中提出的具有奖励函数的SAC模型在现实世界中是否有效,我们在真实汽车中实现了SAC框架。乘用轿车中安装了一台带有CAN网关的笔记本电脑,该轿车在每个悬架系统上都配备了半主动悬架和加速度计(见图5)。CAN网关从连接到汽车的传感器接收加速度数据[见图5(a)和(c)]。使用连接到CAN接口的工业积分器重建速度数据。SAC框架将从CAN接口数据流接收的最新数据作为观测数据,并返回动作信息。动作信息通过CAN接口传送到悬架控制器设备,该控制器设备改变了半主动悬架的电流[见图5(b)],从而改变了阻尼力。
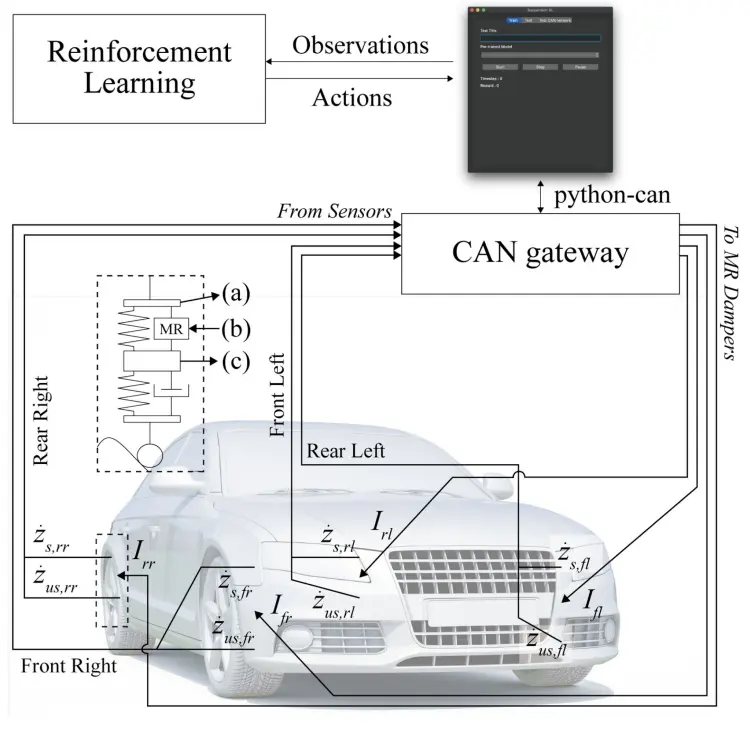
图 5.硬件实现大纲。加速度计安装在每个悬架系统的顶部和底部,如(a)和(c)所述。RL模型生成的动作信号被转换为当前值,并馈送到连接到悬架系统的半主动阻尼器中,如(b)所示。
Ⅳ 实验设置和结果
在本节中,我们将介绍在仿真环境和真实汽车中验证所提出的方法的仿真和实验。在仿真环境中,我们使用 SH 控制器分别训练了两个 SAC 模型,一个用于一般道路区域,另一个用于脉冲道路区域。随后,我们使用经过训练的 SAC 模型测试了一种切换算法。在一辆真实的汽车中,我们实现了所提出的SAC训练方法,并验证了所提出的方法。最后,我们提出了实验结果,并将其与MPC、SH控制器和被动悬架系统的结果进行了比较。
A. 切换 DRL 训练实现算法
如第II节所述,我们使用带有半主动悬架的整车模型设置仿真环境。采用脉冲检测器来切换控制器,用于应对仿真环境中的不同路面。SAC 模型在训练期间单独训练。当针对一般道路区域训练 SAC 模型时,SH 控制器处理脉冲道路区域,反之亦然。在训练阶段之后,使用没有辅助控制器的经过训练的SAC模型。
图4描述了利用SH控制器作为辅助控制器的开关算法。在本例中,分别训练了一般道路的 SAC 模型和脉冲道路的 SAC 模型。当训练一般道路的SAC模型时,脉冲检测器仅在检测到一般道路区域和瞬态道路区域时激活SAC代理[见图4(a)、(c)和(d)]。当 SAC 代理停用时,SH 控制器控制悬架系统。同样,当训练脉冲道路的SAC模型时,脉冲检测器仅在检测到脉冲道路区域和瞬态道路区域时才激活SAC代理[见图4(b)和(c)]。当 SAC 代理停用或检测到瞬态区域时,SH 控制器控制悬架系统。图2给出了未使用SH控制器的开关算法。脉冲检测器决定应激活哪些 SAC 模型。
在训练SAC模型时,弹簧质量处的速度值以及弹簧和非弹簧质量之间的相对速度值被输入神经网络,如下所示:
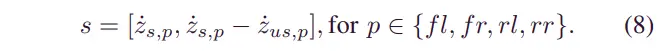
选择这些速度值是为了为训练提供足够的信息,因为传统的 SH 控制器使用相同的状态。
使用不同的奖励函数训练了用于一般和脉冲道路剖面的两个SAC模型。一般道路上 SAC 模型的奖励函数由来自质心四个角的加速度和速度信息组成。一般道路的奖励函数设计如下:
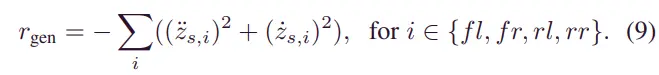
在冲击道路上,SAC 模型的奖励函数由质量中心的颠簸和俯仰加速度信息组成。冲击路的奖励函数设计如下:
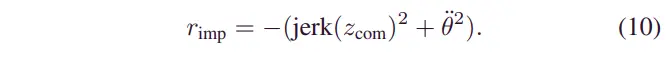
在训练阶段,当最近 100 集(每集由 2000 个时间步长组成)的平均奖励记录最高值时,我们保存了模型的权重。训练完成后,我们选择了模型的最佳权重,该权重记录了最佳的平均奖励。SAC模型被训练了多达1 000 000个时间步长(500集)。
将所提出的SAC开关算法在仿真环境下的均方根结果与、、SH和被动悬架的均方根结果进行了比较,如表II所示。对于基准测试,我们考虑了使用在线优化的MPC [38],这是合适的,因为需要快速采样时间(0.01 s)。所提出的算法和SH中使用了真实值状态。的位置状态值是从对双重积分加速度的卡尔曼滤波中获得的,就像在实际情况下一样。
表Ⅱ 在仿真环境中测量的,和的 RMS 值
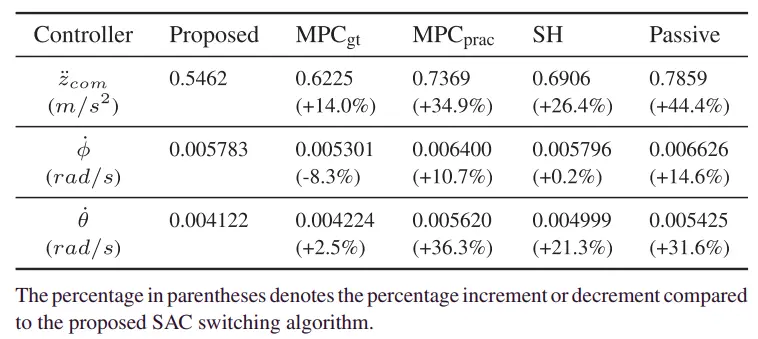
图7(a)–(c)分别给出了,和的功率谱密度(PSD)图。此外,表II总结了在没有切换算法的情况下训练的SAC模型的测试结果。结果验证了单个SAC模型很难同时处理给定的道路扰动曲线,例如脉冲和一般道路。

图 6.位于现代起亚南阳技术研究中心的测试电路。
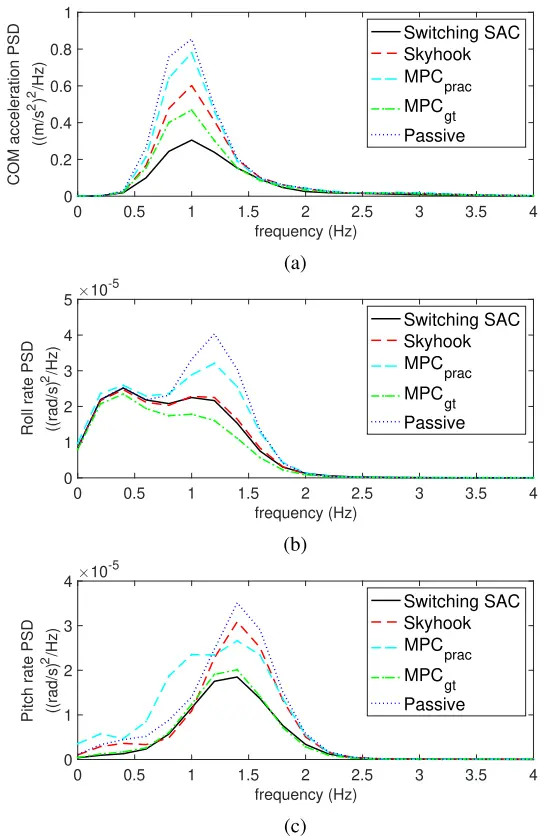
图 7.绘制了 (a) (b)和 (c)的 PSD 结果。
B. 硬件实现
我们设置了一辆带有CAN接口的测试乘用车,如第III-C节所述。在真实汽车中进行实验的主要目的是在真实道路上使用所提出的奖励函数验证 SAC 模型。测试车在韩国京畿道南阳市的现代起亚南阳技术研究中心驾驶测试电路(见图6)进行了测试。测试电路由两部分组成:软路,在ISO8608标准中可列为A,崎岖路面,在ISO8608标准中可列在C和D之间。测试车的速度设置为大约 20 m/s。随后,以类似于仿真环境中的方式收集模型的权重。
将实车中经过训练的SAC模型的结果与SH控制器和被动悬架系统的结果进行了比较,并在图8和表IV中给出。
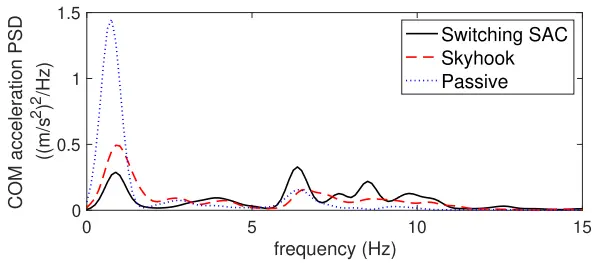
图 8.硬件实现结果的 PSD 图。
Ⅴ 讨论
A. 切换 DRL 训练实现算法
奖励函数的主要目标之一是减少z方向加速度。表 II 给出了,和的 rms 值。与、、SH和被动悬架相比,所提算法的的均方根值显著降低。请注意,在表 II 中,使用了积分位置值,这导致了较差的性能。此外,MPC的性能下降,因为如果没有预览传感器(例如,相机等),基本的预测能力(用于其后退地平线控制)将不复存在。
此外,和的 rms 值也有所减少。图7(a)–(c)中的PSD图显示,SAC算法抑制了低频区域的频率响应。此结果表明所选的奖励函数和 是合适的。如图4所示,所提出的SAC开关DRL算法在响应方面优于SH控制器和无源悬架系统。
相反,使用或的单个 SAC 模型未能在第 II-A 节中描述的真实道路干扰上进行训练。这是因为一般道路和冲动道路之间的力量差异。在训练 SAC 模型时,使用奖励函数来衡量其性能。然而,当一个大的脉冲撞击动力学时,状态变量(例如加速度或颠簸的大小)会迅速增加。因此,无论智能体在一般道路上是否表现良好,奖励函数的输出都会变成更高的负数。
我们还训练了两个没有切换算法的 SAC 模型:一个用于仅在一般道路 () 上训练的奖励函数 () 的一般道路,另一个用于仅在冲动道路上训练的具有奖励函数 () 的脉冲道路 ().采用了用于测试所提出算法的相同测试道路。表III中给出的结果表明,在没有切换算法的情况下训练的SAC模型在给定的道路扰动曲线上未能优于其他控制器。在单一类型的道路上训练的 SAC 模型成功地在训练的同一领域表现良好。但是,它们在混合域上失败了。这是因为 SAC 预计仅在训练它的域或类似域上表现良好。此外,这意味着使用适用于特定路况的单个奖励函数训练的单个 SAC 模型不足以处理混合路况。
所提出的切换算法的目的是分离域。因此,可以根据SAC模型的动作以及它们从适当环境中接收到的响应来训练SAC模型。随后,在处理具有不同条件的多个域时,可以使用多个 SAC 模型。
注1:由于我们将SAC模型的动作映射到耗散区域,因此无论动作如何,整个(开关)系统都是稳定的[39],[40]。通常,使用通用DRL算法的控制系统的稳定性可以通过[41]和[42]中建议的方法进行研究。
B. 硬件实现
表IV中列出了质心处方向加速度的均方根值。结果表明,SAC智能体使用所提出的奖励函数()降低了重心的方向加速度这与乘坐舒适性高度相关。然而,与其他基准控制策略相比,记录了真实汽车中质心滚动的最大均方根值。这可能是因为外力通过连接到悬架系统的臂直接影响车身。悬架不太可能将这些力的影响降到最低。
图 8 中的 PSD 表明,SAC 代理降低了低频的功率,这表明区域低于 5 Hz,而高频区域的功率由于水床效应而更高。但是,的总均方根值会随着 PSD 中的第一个峰值显著降低而降低。该峰值包含响应信号的大部分功率。
据我们所知,这是第一次在真实汽车中实施用于悬架控制的 DRL 模型。实车实验结果表明,所实现的SAC模型使用与仿真相同的奖励函数(),在仿真环境中的性能符合预期。这也意味着模拟中的知识实际上可以转移到现实世界中。
然而,本文未验证脉冲路面的SAC模型和所提出的切换算法,因为这些方法的训练需要一个包括一般路面和脉冲路面的测试电路,如第II-A节所述。我们期望在未来用真实汽车训练脉冲路面的SAC模型,并验证所提出的切换算法。此外,我们还将从 SH 控制器收集非策略数据,以便进行更有效的培训。真实汽车中可能存在的另一个问题是执行器死区[43]。在未来与真实汽车相关的研究中,我们将进一步探索 DRL 如何控制带有死区的执行器。
Ⅵ 结论
在本文中,我们提出了切换算法,以在感官测量有限的真实道路上使用 SAC 模型来控制半主动悬架系统。SAC模型使用不同的奖励函数进行训练,以涵盖两个干扰域:一般道路(ISO8608标准)和减速带。该概念首先在仿真中实现,结果表明所提出的算法能够在现实驾驶场景下控制悬架系统。与先进和传统的工业基准悬架控制器相比,结果表明,所提出的切换算法降低了方向加速度和车身质量中心的俯仰。最后,我们成功地在一辆真实的汽车上实施了SAC培训系统。在硬件实验中,我们发现经过训练的SAC模型在真实汽车中优于传统的工业悬架控制策略。但是,由于合作公司的日程安排有限,在实车中实施的SAC训练系统仅在一般路面上进行训练,因此我们将来将训练具有不同路面的实车。我们在仿真测试和实车测试中的结果表明,基于从仿真环境中获得的知识,DRL可以应用于现实世界。
参考文献








编辑推荐




最新资讯
-
国内最大汽车创作者大会开幕,懂车帝投入5
2025-04-27 13:18
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
