




 广告
广告





















































理想如何解决自动驾驶系统的学习和测试?

自动驾驶驾驶的汽车,如果想上路的话,要像人一样,需要经过考试,也就是闭环仿真。业界做法无非有三种:仿真、重建和生成。

本文重点介绍下理想的自动驾驶的闭环仿真系统。
01. 闭环仿真的三种路线
第一种是3D仿真,其实就是把一堆3D的资产或者3D的模板,通过人工编辑排版,然后生成场景,最后通过游戏引擎渲染出来。但是有两大问题,一是渲染出来的场景非常假,二是效率低非常低,用大量的人工参与,没办法满足自动驾驶的快速迭代需求。

二是,真实数据的重建。理想将大量的真实数据通过NeRF(神经辐射场)或者3DGS(3D高斯溅射)技术自动化的重建出来,它的整体效率肯定比3D仿真要快得多的多,光照、材质、行为这些都跟真实的是一样的。
但是也有个问题,当自动驾驶的系统接入做闭环仿真的时候,如果本车跟原来的车行为差异比较大,视角变化很大,新视角下会出现模糊拖影的现象,也没办法完全满足自动驾驶的需求。

第三种是生成,例如比较火最近sora就是利用Diffusion(扩散模型)技术,然后加上prompt形成各种各样的场景。但这个所谓的世界模型或者生成模型,最大的问题是它没有真正的理解世界,所以它存在很多不符合规律的这种幻觉问题,也没办法完全满足自动驾驶的需求。
这些都是业界现成的方案,但都不太能满足对智能驾驶考试的需求。
02. 理想的选择:重建+生成
理想最终采用的是一个重建+生成结合的世界模型,取长补短,将他们的优点结合在一起。
以下是架构图。
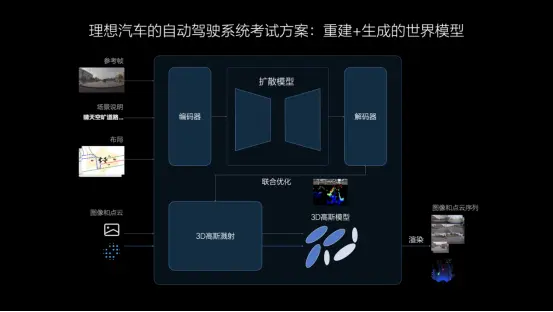
该架构可以分成上下两部分,下面其实是一个GS(高斯溅射)重建的过程,上面其实是利用真实数据的先验,给出了Layout(布局)做约束,然后再加上prompt,再给一些参考图片,生成新的视角。
这样的架构有两个好处,一是重建出来的3D的世界,即使转换新视角,也不会出现之前模糊的问题。
二是,上面生成的部分它可以独立的运行。有了Layout的先验,再加上这种reference(参考帧)的图片,再加上prompt,可以生成很多符合真实世界规律,但是没见过的场景,泛化性也会更好。
简单说,就是有两种的测试和考试的题,一种题是用重建出来的是真题,一种是用生成出来的,是模拟题。
03. 重建和生成方法
理想方面表示,他们重建的整个核心思想是先把一个视频的动态和静态进行分离,静态的背景先用3DGS(3D高斯溅射)算法进行建模,建成一个完整的背景资产。

再将动态拿出来也进行重建,进行新视角生成,让它变成一个360度的一个新的资产,将这两者进行结合,就形成一个新的3D物理世界。

在这个世界中,人工可以控制里面任何元素了,可以左移右移、左偏右偏都可以做。
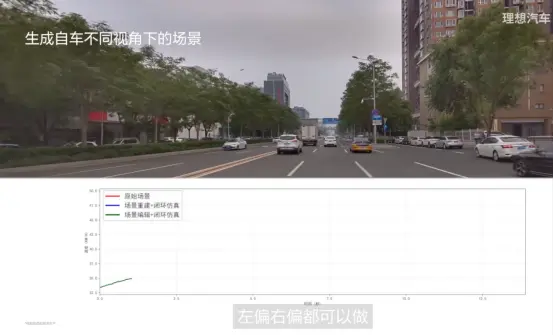
同时,还可以修改这些功能人物的位置和轨迹,就具备一定泛化能力来测试自动驾驶系统。生成模型相比于重建来说,它是有更好的泛化性。

在这里,可以人为控制着里面的天气、时间、车流等等各种各样的信息,让它生成各种各样不同的场景来考验模型的泛化能力。通过在这样的无限的环境中,对自动驾驶进行学习和考试,来保证交付的软件高效安全和舒适。
- 下一篇:浅析汽车低压线束的三维设计与应用
- 上一篇:“镀银挡风玻璃信号无忧”整车无线通信检测






最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
