




 广告
广告





















































NVIDIA Spectrum-X 助力 DDN A³I 打造 AI 存储以太网 RDMA 性能新标杆

为了能够从数据中获得所需的洞察力,企业和组织需要创建、分析和保存海量的数据。想要快速利用业务中的数据转换技术和经营模式,企业信息数据需要贯通大数据、混合云以及 AI 等先进的数据分析平台,从而实现创新并带来商业价值。
DDN A³I 面向企业提供一种全新架构的存储解决方案,使企业可以引入 PB 级别的业务数据信息,并且能够进行实时高速的数据处理,直接面对数十/百个传统业务 GB 或者 TB 级别的汇聚数据流。这将使企业可以从容面对数据智能化转型过程中,以 EB 或 PB 为单位的数据挑战,进而能够做出快速有效的决策,从而快速推动企业的业务向前发展。
DDN A³I 的联合解决方案是与 NVIDIA 的 DPU 和 GPU 进行的资格认证、基准测试和优化的集合体。能为生成式 AI、推理、训练、AI 软件架构套件以及多 GPU 节点 HPC 并发集群等提供可预测的性能,容量和能力。通过 A³I 优化的参考架构可以把存储设备潜在的最大性能通过由 NVIDIA SN5600 交换机和 BlueField-3 构成的 Spectrum-X AI 以太网平台直接暴露给上层应用程序,参与数据交付和存储的每一层硬件和软件均经过优化,以实现迅速、低延时响应和可靠的访问。
NVIDIA Spectrum-4 SN5600 交换机是业界首款面向 AI 以太网打造 51.2T 超大转发容量的交换机,具备业界超低的转发时延并支持多达 256 个 200GE 端口,可以极大的简化 AI 集群南北向存储网络架构并降低部署成本,同时结合 NVIDIA 最新一代 DPU 产品 BlueField-3,可以在通过 Lossless RoCE 网络构建超高性能 AI 存储网络的基础上实现多种虚拟化应用的卸载,将控制面和存储面整合到一个网络中,简化 AI 集群网络的部署,为客户创造更多价值。
1. DDN A³I 解决方案参考架构
DDN A³I 作为一种高性能的并行数据存储解决方案,可以帮助用户更快速地获得所需的计算或分析结果,管理快速扩展的数据和基础架构,同时确保数据安全性并降低总体存储成本。
DDN A³I 中的参考架构是在与 NVIDIA 密切合作中设计、开发和优化的成果。将用于驱动全球最大超级计算机的先进技术,整合成一款易于部署和管理的 HGX 系统解决方案。被证明能够最大限度地提升在 HGX 系统上处理大规模 AI 任务、分析海量数据和进行高性能计算(HPC)等工作负载的效益。
以下是 DDN A³I 参考架构的领先功能特性:
1.1 DDN A³I 技术特性简介
共享并发式架构: DDN A³I 共享式并行架构和客户端协议建立多个并行数据路径,从驱动器延伸至在 HGX 系统中运行的容器化应用程序,利用 DDN 的真正端到端并行能力,数据以高吞吐量、低延迟和巨量的事务并发传送。
Multi-Rail 多轨网络:DDN A³I 多轨网络功能可实现 HGX 系统上多个网络接口的流量性能归并,从而在无需 Channel group 或 Bonding 等交换机配置的情况下,实现更快的数据传输汇聚能力。支持最新一代的 NVIDIA Quantum InfiniBand 和 Spectrum-X RoCE 以太网技术,在应用程序、计算服务器和存储设备之间提供了高带宽和低延迟的数据传输。
DDN A³I 热数据节点:DDN Hot Nodes 是一款强大的软件增强功能,使得在 HGX 系统中可以将 NVME 设备用作只读操作的本地缓存。这种方法显著提高了应用程序的性能,特别是在特定工作流程中多次访问数据集时发生。本地缓存的使用有效地消除了重复的网络数据交换和共享存储的压力。
NVIDIA 系统中的应用容器可与 DDN 并行文件系统实现高性能直通连接。这带来了显著的应用性能提升,使得容器应用能够直接与 DDN 并行文件系统进行低延迟、高吞吐量的并行数据访问。此外,多个容器之间共享单一主机级存储连接的限制也随之消失。DDN 的容器内文件系统挂载功能通过一个通用的 Wrapper 在运行时添加,无需对应用或容器进行任何修改。
智能客户端的优势:智能客户端了解数据的本地性,通过查询元数据服务器确定数据位置,从而提高单一 IO 的并发度读获取优化性能。客户端在元数据缓存中,可处理多个任务,包括元数据请求,从而实现可扩展的性能。
用户可见性和管理:系统提供基于 Web 的仪表板(Insight),用于监控和管理基础设施,显示关于电源供应健康、容量消耗等的信息。
1.2 DDN A³I 存储网络参考配置
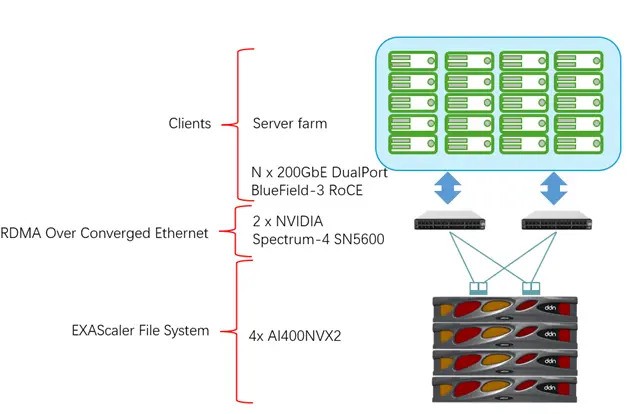
在设计 AI 系统整体架构时,会涉及多种网络类型。而存储网络负责为 AI400X2T 和 GPU 计算节点,管理节点之间提供数据连接,该网络对上层 AI/HPC 应用的数据吞吐,低延迟和扩展能力发挥重要的作用。有了充分发挥网络优化的低延时效果,DDN 会要求存储网络设置为 RDMA over Converged Ethernet(RoCE)模式,使得节点之间的数据交换,跨越系统网络数据传输的中间环节,直接进入内存直接访问。
NVIDIA Spectrum-4 SN5600 交换机是一款高性能 RoCE 网络交换机,提供高达 51.2Tbps 的转发能力。在 2U 空间内采用 64 个 OSFP 端口提供 128 个 400GbE 端口或者 256 个 200GbE 端口。

在NVIDIA SuperPOD 的参考架构中,使用两台冗余的 SN5600 即可实现 4 个 SU 的 SuperPOD 与 DDN storage 的数据中心级别无阻塞网络连接。
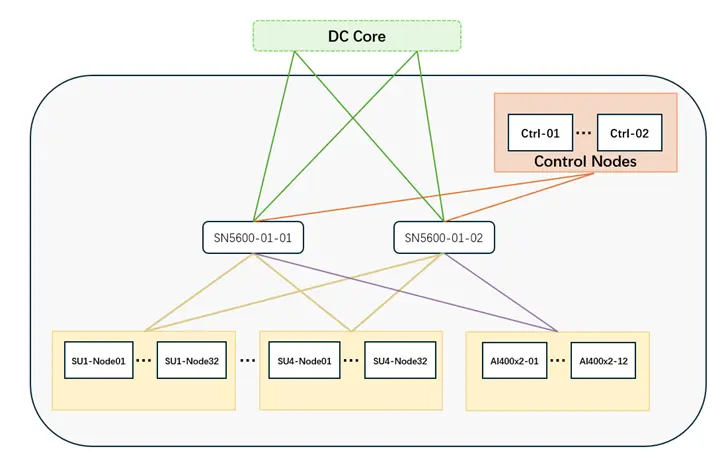
2. DDN AI400X2T & NVIDIA SN5600 性能验证
2.1 验证环境简介
本次验证环境由一台 DDN AI400X2 Turbo,一台 NVIDIA Spectrum-4 SN5600,6 台服务器构成。用于测试的服务器部署 NVIDIA BlueField-3 通过 RoCE(RDMA over Converged Ethernet)模式挂接到 AI400X2 Turbo 存储设备。
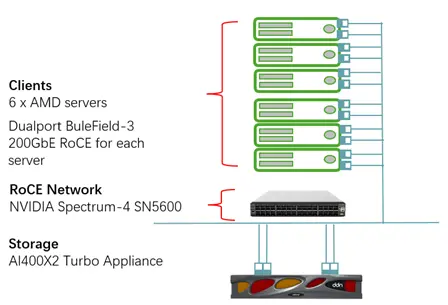
2.2 验证性能结果
性能测试用于证明 DDN AI400X2T 和 NVIDIA Spectrum-4 SN5600 进行低延时网络连接的环境中,存储和存储网络的数据流量可以达到 AI400X2 Turbo 的最高带宽峰值。验证的性能测试工具使用的是开源的 FIO 性能测试工具,通过模拟普通系统工作负载产生的 I/O 数据流来测量 AI400X2 Turbo/NVIDIA SN5600 的性能峰值。
FIO 的性能压力参数设置如下:
-
Direct=1
-
ioengine=libaio
-
rw=randread/randwrite
-
Numjobs=64
性能测试分别按照 1,2,4,6 个 server 客户端同时连接到 AI400X2 Turbo,模拟多用户并发访问的数据压力向 AI400X2T 发起 IO 请求。
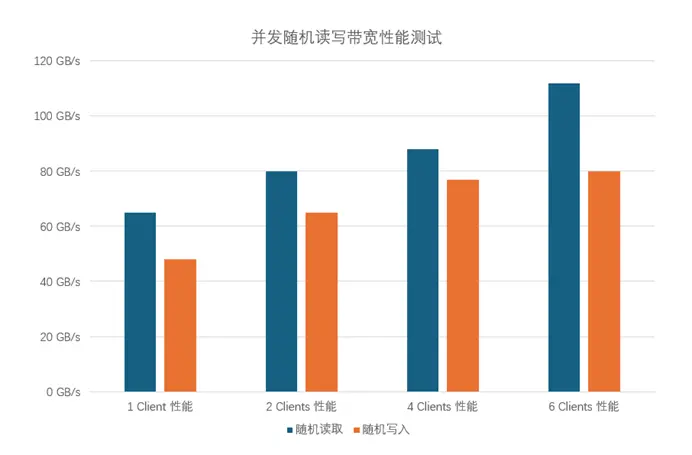
从上面数据可以看出,单个 Client 节点压力,采用 NVIDIA Spectrum-X 平台的 AI400X2 Turbo 可以提供高达 65GBps 随机读和接近 50GBps 随机写的能力,保障 AI 场景内任意节点具备超高的数据访问能力,同时多节点并发数据访问的前提下,凭借 NVIDIA Spectrum-X 无损网络及 AI400X2 Turbo 优秀的存储能力,提供了 115GBps 随机读和 80GBps 随机写的超高性能。
3. 成功案例
3.1 商业背景
某海外智算云公司为亚太地区和东南亚企业提供基于 AI 模型的机器学习、推理、视频渲染编解码等 GPU 算力云服务,满足亚太地区客户的人工智能计算需求。公司旨在提供 AI 智算的端到端解决方案,帮助企业和个人更有效、更快捷地利用人工智能的基础设施。其服务涵盖了当前最流行的行业领域应用和 framework,例如生成式 AI、新材料、基因工程、无人驾驶、游戏、图像处理、智能制造以及虚拟现实等。
3.2 业务挑战
随着在东南亚越来越多企业和研究机构开始运用 AI 智算服务,数据中心数据量不断增长,同时算力资源需求也随之膨胀。提升智算资源的周转频率,合理规划智算资源分配,才能满足用户高质量的 SLA,达成 GPU 算力成本竞争力的规模化效应,提升智算性能和资源效率优化效果,并非通过简单的叠加计算资源和增加并行计算能力可以得到。
从不同 AI framework 运行整个生命周期角度进行观察,每个 epoch 在不同阶段会不同程度地依赖 OS Kernel、存储、网络、文件系统等非 GPU 算力资源,尤其在系统中存在多并发 Epoch 时,不同资源争用导致的瓶颈相互叠加,使得智算资源的实际运行效果无法达到期望的叠加效果。
3.3 解决方案
DDN A³I 提供给客户基于 AI 智算全链路优化的存储和网络解决方案如下:
· DDN A³I 采用分布式文件系统架构消除系统热点数据,大量减少并发访问征用锁冲突。消除在多AI training 场景下的 checkpoint 等待时间。
· DDN 通过 Multi Rail 网络并行技术,使得数据访问数据传输不再局限于一个端口的带宽流量,大大减少 epoch 的 First iteration 资源占用时间窗口。
· DDN 全 NVMe 的 Hot node 技术,把前端计算节点本地缓存与后端 A3I 存储性能集成,使得 dataset 的反复读取速度大幅提升,减少网络流量带来的网络阻塞和等待。
· NVIDIA 的加速以太网技术,通过 RoCE(RDMA over Converged Ethernet)实现远程的计算节点的内存访问模式,降低了网络通信延时,增加了网络带宽,提升了网络数据交换效率。
· SN5600 交换机采用 Spine-Leaf 架构,具有高可扩展性,可以满足未来客户数据中心扩建、增配等发展规划。
3.4 性能验证
为了智算云客户提供对应的 SLA 和 QoS,验证 DDN A³I 解决方案为客户的大型智算集群所提供的性能支撑能力,在 DDN AI400X2 储系统部署优化完成后,现场对并行文件系统进行了基于 IOPS 和 GBps 的性能测试。通过 14 个 server 并行连接 AI400X2 存储,模拟 14 个客户端同时启用 64 个并发进程,对存储发起随机读、随机写请求的场景下,测试结果如下:
|
测试类型 |
并发客户端数量 |
性能 |
|
随机读取 |
14 |
12.7 MIOPS |
|
随机写入 |
14 |
2.4 MIOPS |
|
顺序读取 |
14 |
360 GBps |
|
顺序写入 |
14 |
264 GBps |
总结
展望未来,随着 AI 技术的不断发展,AI 集群规模不断变大,各种人工智能的应用对高性能存储的要求将会变得更加苛刻,新的 AI 数据中心不仅需要高性能的AI计算网络来提供高性能的东西向通信,同时也需要高性能的 AI 存储网络来确保南北向的通信性能。
DDN AI400X2 Turbo 结合 NVIDIA Spectrum-X 以太网平台面对这一趋势,提供了高性能、低延迟和高吞吐量的网络存储方案满足万卡规模 AI 集群的数据访问能力。这必将会成为 AI 应用的基石,推动 AI 技术的进一步发展和应用,从而带来更大的经济和社会效益。



编辑推荐




最新资讯
-
推荐性国家标准《乘/商用车电子机械制动卡
2025-04-30 11:13
-
载荷分解
2025-04-30 10:46
-
布雷博在上海开设亚洲首个灵感实验室
2025-04-30 10:25
-
组分性能对锂离子电池卷芯挤压力学响应的影
2025-04-30 09:00
-
美国发布自动驾驶新框架,放宽报告要求+扩
2025-04-30 08:59
