




 广告
广告





















































基于结构化的Informer模型的自动驾驶轨迹预测

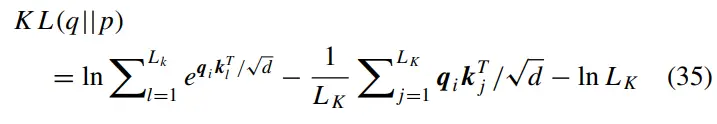
忽略常数项,查询向量的稀疏度测量定义为:
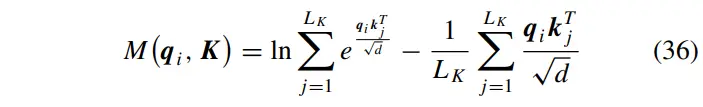
其中第一项是除以所有值的对数和,第二项是它们的算术平均值。如果得到一个更大的掩模矩阵,它就有一个更离散的自注意力分布,这意味着它更有可能包含主点积对。为了进一步简化稀疏度度量的计算,可以简化式(36)。对于,当时,下列不等式成立。参考文献[28]中给出了更详细的推导。

因此,更简化的掩模矩阵的稀疏度测量计算为:
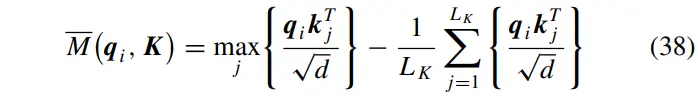
掩模矩阵用来过滤掉更有意义的。所选的个数设为,其中为调整因子。根据每个对应的掩模矩阵,将其编号为,从高到低依次选择。通过此操作,可以将查询向量重新采样到。因此,在计算自注意力时,计算点积的内存使用量从变为,这对于降低长序列时间序列预测问题的计算复杂度有重要意义。在多头视角下,每个头部都会生成不同的稀疏查询键对,因此多头ProbSparse自注意函数可由下式求得:
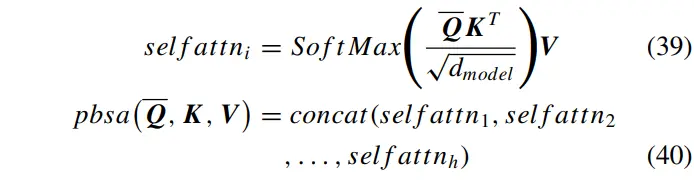
此外,根据预测器,输出序列在第次已知,而序列不太可能在实际预测之后的第次得到。为了反映这一特性,在训练过程中应该部分掩盖对解码器的真实序列。因此,在解码器的自注意力计算中加入了掩蔽机制,以覆盖部分点积注意力。对于解码器,只需将式(39)和(40)重写为:
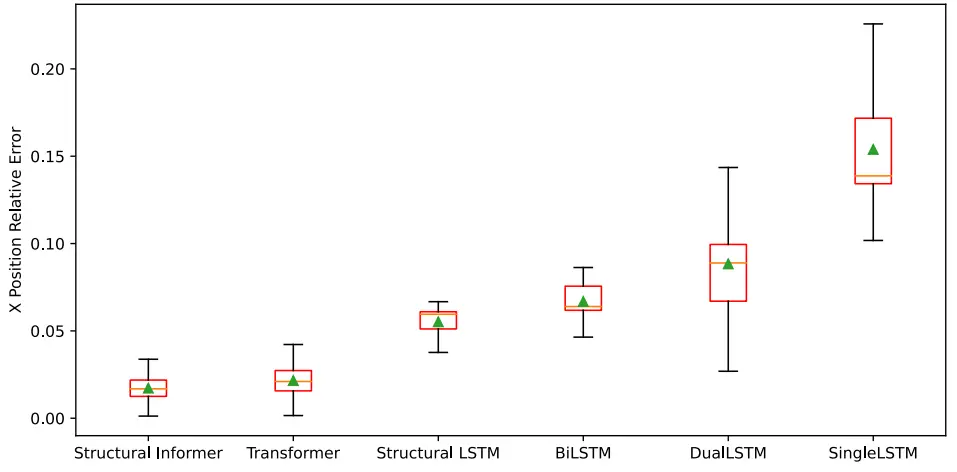
其中为采样后的掩模矩阵。,其中:
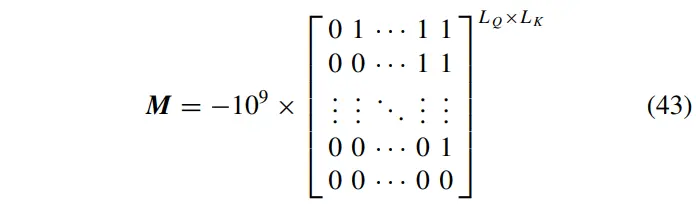
这个上三角矩阵可以掩盖未来节点对当前节点的影响。由于在ProbSparse自注意机制中对查询向量进行了重采样,因此对掩模矩阵也需要进行相应的操作。因为是从推导出来的,所以根据在中的分布,从中抽样得到 。
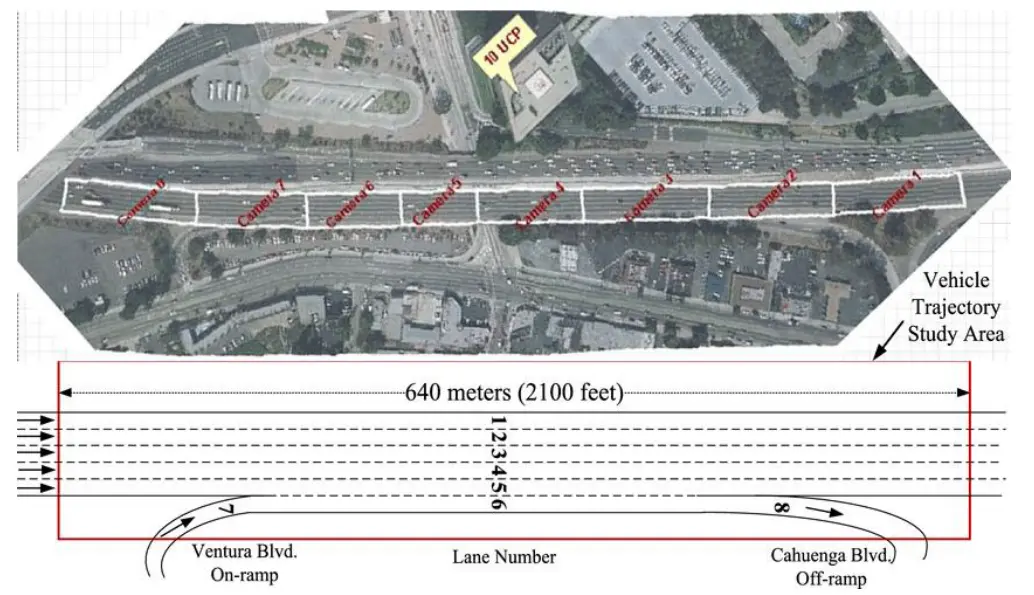
图 8 数据收集时的高速公路鸟瞰图
D.训练模型
为了获得目标车辆更好的预测精度,选择均方根误差(RMSE)作为解码器输出,的损失函数:
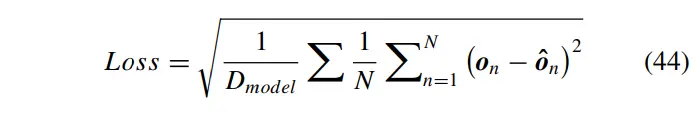
其中,为输出序列的维数,为真值序列。在每个时间步长计算损失,通过反向传播算法更新所有全连接层和注意力层的权重,以最小化损失。






最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
