




 广告
广告





















































基于结构化的Informer模型的自动驾驶轨迹预测

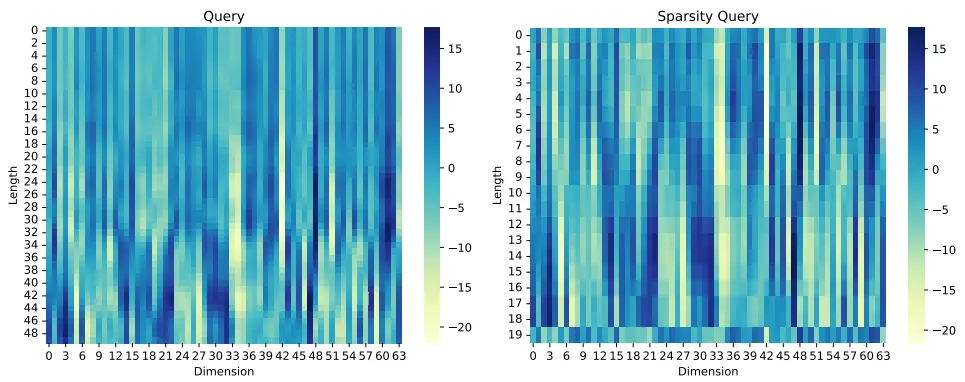
a)分布; b)分布
图 11 查询向量稀疏度测量过程
3)多头注意力:图12描述了通过式(32)计算的多头注意力。该图展示了与历史轨迹相关的某个预测轨迹的四头注意力分布。纵轴和横轴分别表示历史轨迹和预测轨迹的节点,图中的点表示注意力值。注意力分布表明,多头注意力机制可以计算和提取预测轨迹和历史轨迹之间的联系。例如图中历史轨迹的近13点和28点附近的注意力值总是较大,说明这些点和附近的点对目标车辆未来的轨迹有着较大的影响。因此,在训练过程中,网络不断地为这些位置附近的点分配更大的权重。这种权重分配的差异表明历史轨迹的每个点与预测轨迹有不同的联系。通过提取这些连接,本文采用的多头注意力机制可以使网络更加关注历史轨迹中的特定点,从而提高预测的准确性。
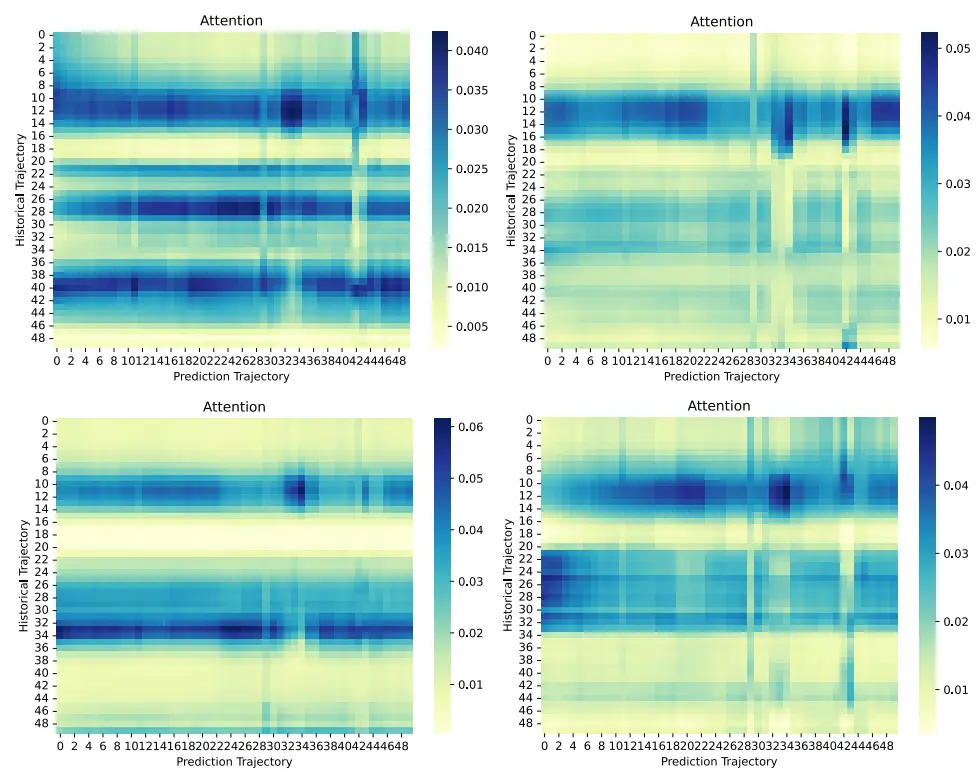
图 12 多头注意力分布
例如,图中历史轨迹中的近13点和28点附近总是具有较大的关注值,这表明这些点和附近的点对TV的未来轨迹具有重大影响。因此,在训练过程中,网络会不断为这些位置附近的点分配更大的权重。权重分配的这种差异意味着历史轨迹的每个点与预测轨迹具有不同的连接。通过提取这种连接,本文采用的多头注意机制可以使网络更多地关注历史轨迹中的特定点,从而提高预测的准确性。
B.轨迹预测精度分析
表II和III分别列出了结构化的Informer模型和参考模型的FPE和APE值。如在LSTF过程中观察到的,预测精度随着预测时间的增加而劣化,这由最终仿真结果证实。然而,与参考模型相比,所提出的结构化Informer模型表现出更优越的性能。纵向和横向FPE以及APE在每个预测时间都达到最小值。即使在第5秒时,结构化Informer模型的纵向和横向FPE分别为2.93%和2.33%,而纵向和横向APE分别为1.39%和1.21%。结构化Informer模型在网络结构方面增强了Transformer。图13可视化了Informer和Transformer下随机选择的四辆车的完整轨迹的预测比较。如图所示,通过对结构化Informer在预测精度上与Transformer的比较,验证了这种改进的有效性。此外,所提出的结构化Informer模型在预测精度方面显着优于传统的基于LSTM的模型。
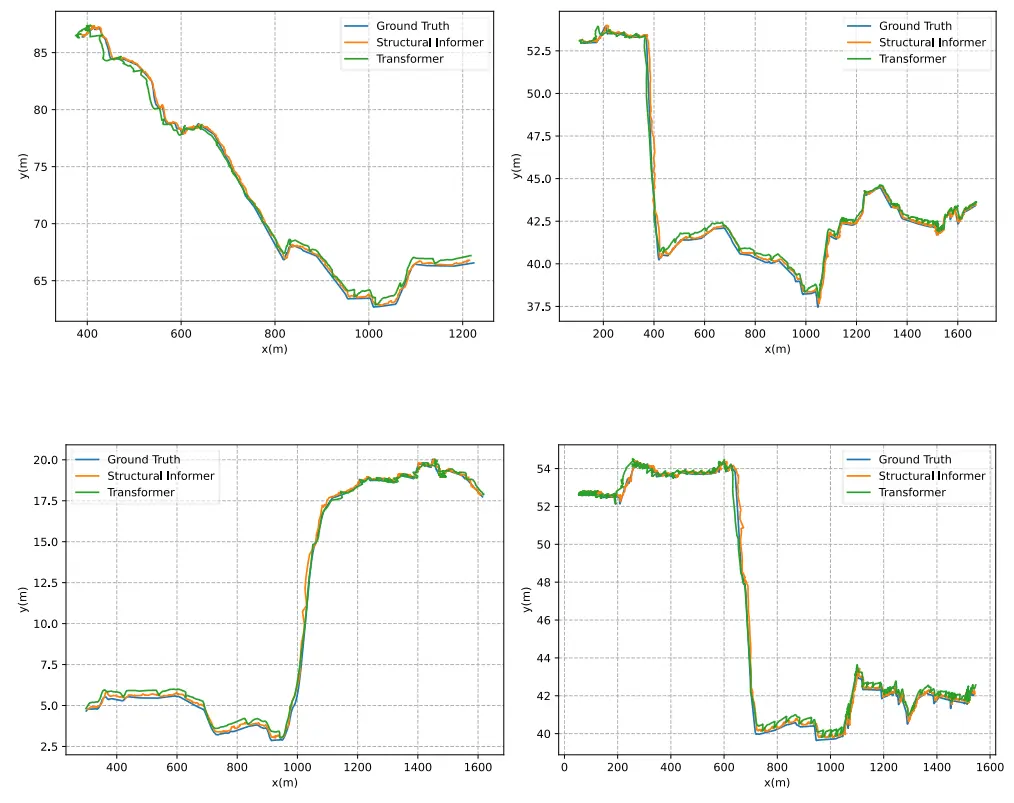
图 13 轨迹预测可视化






最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
