




 广告
广告





















































从感知、规划来看特斯拉 FSD自动驾驶为何全球瑶瑶领先

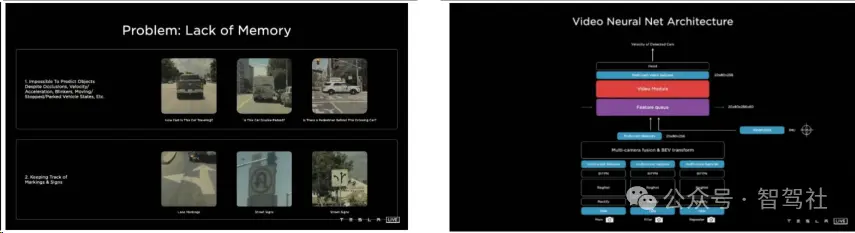
特斯拉在自动驾驶领域的早期技术方案中,首先在二维图像空间完成对环境的感知,然后将这些二维图像信息投射到三维向量空间中。由于摄像头捕捉到的数据本质上是二维的,与实际的三维物理世界存在差异,因此要实现完全自动驾驶,必须将这些二维数据转换到三维空间中去。在这一过程中,特斯拉面临了巨大的挑战,尤其是在对每个像素深度信息的精确预测上,以及对于被遮挡区域的预测上。当物体被多个摄像头捕捉,且没有单个摄像头能完整捕捉到物体时,就难以实现对这些信息的准确融合,进而影响到对物体的准确预测。
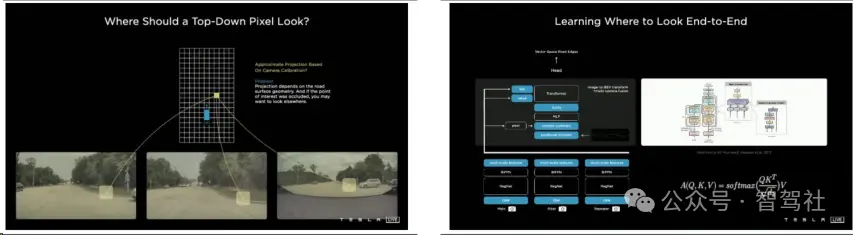
为了解决这一问题,特斯拉采用了BEV(Bird's Eye View)+ Transformer架构,将二维图像转化为三维感知信息。特斯拉坚持使用纯视觉数据来计算深度信息,在网络结构中引入了BEV空间转换层,以增强网络的空间理解能力。特斯拉采用了“前融合”方案,直接将车身多个摄像头获得的视频数据进行融合,并用同一套神经网络进行训练,从而实现从二维图像空间到三维向量空间的特征变换。Transformer神经网络在这个过程中起到了核心作用,通过自注意力机制和多头注意力模块,将图像特征转换为键和值,然后通过模型自行检索需要的特征用于预测,实现对车辆周围环境的准确感知。此外,特斯拉还引入了虚拟标准摄像头来校准图像,消除外参误差,确保数据的一致性。
 图像空间预测投射到向量空间后出现较大偏差 单相机检测无法解决物体横跨多相机的问题
图像空间预测投射到向量空间后出现较大偏差 单相机检测无法解决物体横跨多相机的问题
特斯拉的FSD技术通过采用BEV+Transformer架构,实现了从2D图像到3D感知的转变。这一转变的核心在于将摄像头捕获的二维图像数据转换为三维空间的深度信息,从而为自动驾驶提供精确的环境感知。特斯拉没有依赖激光雷达或毫米波雷达等传统传感器,而是坚持使用纯视觉数据来计算深度信息。在网络结构中,特斯拉引入了BEV空间转换层,这有助于构建网络的空间理解能力,并通过前融合方案将多个摄像头的视频数据直接融合,使用同一套神经网络进行训练,实现从二维图像空间到三维向量空间的特征变换。Transformer神经网络在这个过程中起到了核心作用,通过自注意力机制和多头注意力模块,将图像特征转换为键和值,然后通过模型自行检索需要的特征用于预测,实现对车辆周围环境的准确感知。这种方法不仅提高了感知的准确性,还增强了系统对于复杂环境的适应能力,包括处理遮挡和动态场景的能力 。
此外,特斯拉的FSD技术还包括了先进的规划模块,该模块采用交互搜索框架,通过任务分解的方式对一系列可能的行驶轨迹进行研究,实现对规划方案的实时评估。这种全栈自研的算法使得特斯拉能够以低成本的感知硬件实现高阶智能驾驶能力,并快速优化迭代自动驾驶算法。通过这种方式,特斯拉的FSD技术在算法端、算力端、数据端和硬件端展现出强大的整合能力,为实现完全自动驾驶提供了坚实的技术基础 。
 BEV 视角融合了多个摄像头的视频数据 Transformer 是实现二维到三维变换的核心
BEV 视角融合了多个摄像头的视频数据 Transformer 是实现二维到三维变换的核心
特斯拉在自动驾驶的感知框架中加入了一层虚拟标准摄像头,用以消除由于摄像头安装外参差异导致的微小数据偏差。这一过程涉及将每辆车采集到的图像数据通过去畸变、旋转等方式处理,然后统一映射到同一套虚拟标准摄像头坐标中。这样的校准(Rectify)确保了数据的一致性,为神经网络的训练提供了标准化的数据输入。通过这种方法,特斯拉能够提高感知系统的准确性和鲁棒性,确保自动驾驶系统在不同车辆和条件下都能可靠地工作。
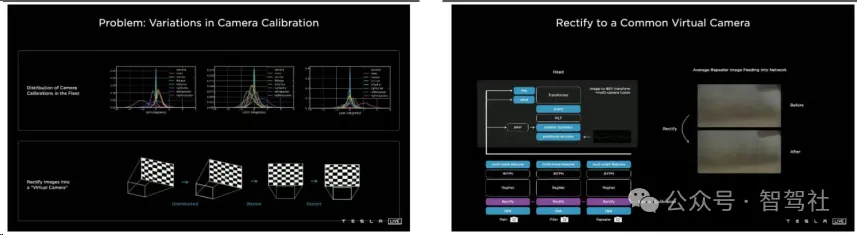 通过图像校准解决摄像头采集数据偏差问题 加入虚拟标准摄像头以校准图像数据偏差
通过图像校准解决摄像头采集数据偏差问题 加入虚拟标准摄像头以校准图像数据偏差
特斯拉在其自动驾驶技术中引入了时空序列特征层,这一创新显著提升了环境感知的准确性。在采用BEV(Bird's Eye View,鸟瞰图)+ Transformer架构后,感知网络已经具备了对三维空间的感知能力。然而,这仅仅局限于对瞬时图像片段的感知,无法捕捉到动态世界中的时序变化。为了解决这一局限,特斯拉通过引入时空序列特征层,赋予了感知网络类似于人类司机的短时记忆能力。这种能力使得网络不仅能够根据当前时刻的感知信息做出判断,还能够依据一段时间内的数据特征,推演出当前场景下可能发生的各种结果。这样的技术升级,让特斯拉的自动驾驶系统在处理动态场景时更为精准和可靠,大大增强了其在复杂交通环境中的适应性和预测能力。
感知网络仍是对瞬时图像片段进行感知 特斯拉引入时空序列特征层
特斯拉在其自动驾驶技术中引入了时空序列特征层,这一创新显著提升了环境感知的准确性。该层主要包括特征队列模块(Feature Queue),它由时序特征队列和空间特征队列两部分组成。时序特征队列负责缓存随时间变化的特征,每过27ms就会将一个特征加入队列,这有助于稳定感知结果的输出。例如,在运动过程中发生的目标遮挡情况下,模型可以利用目标被遮挡前的特征来预测感知结果。而空间特征队列则负责缓存随空间变化的特征,每当车辆行驶一定固定距离,就会将一个特征加入队列。这在需要长时间静止等待的场景下尤为重要,如等红绿灯时,由于时序特征队列中的特征会因时间的流逝而出队丢失,空间特征队列则能够记住一段距离之前路面的箭头或是路边的标牌等交通标志信息,从而确保自动驾驶系统在这些场景下依然能够准确感知环境 。
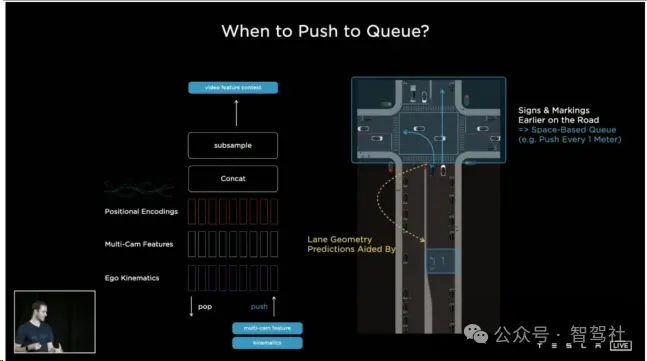 特征序列模块可以缓存时序与空间特征
特征序列模块可以缓存时序与空间特征
特斯拉在其自动驾驶技术中引入了视频模块(Video Queue),这一模块的核心是空间RNN模块(Spatial RNN Module),它通过循环神经网络(RNN)结构来整合时序信息。在这个模块中,车辆的运动状态在二维平面上被映射为一个二维网格的隐状态(Hidden State)。随着车辆的前进,只有与当前视野相关的网格部分会被更新,这样的设计允许系统只更新与车辆当前位置和运动状态相关的环境信息。此外,该模块的隐状态可以包含多个通道,每个通道负责跟踪道路的不同特征,如道路中心线、边缘、标线等,使得系统能够同时处理多种类型的环境信息。空间RNN模块可以根据当前的能见度选择性地更新隐藏状态,如果某个区域被其他车辆遮挡,系统可以选择不更新那个区域的状态,直到能见度恢复。这种设计显著提升了感知系统对于时序遮挡的鲁棒性,以及对距离和目标移动速度估计的准确性。
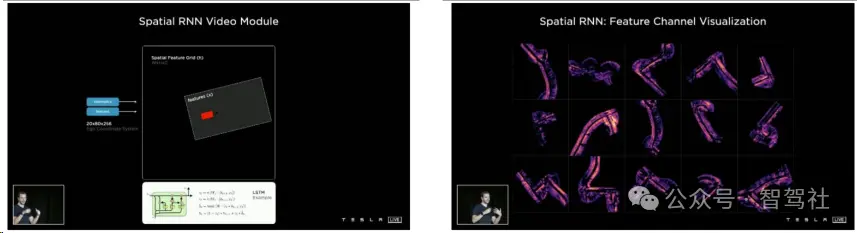 隐状态可组织成二维网格 空间 RNN 的隐状态可包含多个通道
隐状态可组织成二维网格 空间 RNN 的隐状态可包含多个通道
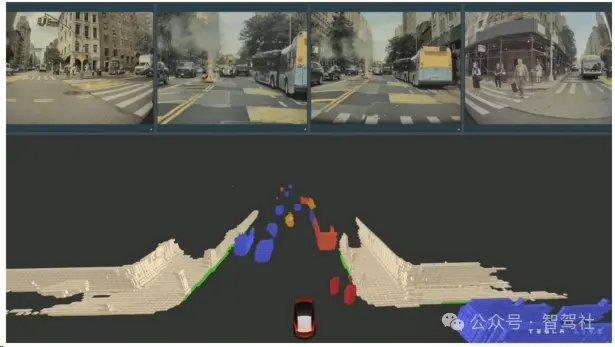
特斯拉的Occupancy Network是对HydraNets架构的重要改进,它能够直接在向量空间产生体积占用,从而更有效地表达长尾障碍物。传统的3D物体检测方法对于常见障碍物如车辆、行人较为有效,但对于变形障碍物、异形障碍物以及未知类别的障碍物,如挂车、翻倒的车辆或路上的石子等,这些方法的准确性和适用性有限。Occupancy Network通过判断3D空间中每个体素网格是否被占用,提供了一种全新的表达方式,能够预测和识别这些难以用传统方法捕捉的障碍物。
Occupancy Network的算法受到机器人领域中occupancy grid mapping的启发,将3D空间划分为大小一致的体素网格,并判断每个网格是否被占用。该网络以摄像头产生的视频流为输入,直接在向量空间产生单一统一的体积占用,预测车辆周围3D位置的占用概率。与传统的目标检测网络相比,Occupancy Network能够精准识别物体的运动状态差异,例如能够捕捉到一辆两节的公交车中,一节已经启动而另一节还处于静止状态的细微差别。这种能力对于传统的目标检测网络来说是非常复杂的。Occupancy Network的处理速度极快,能够在10毫秒内更新对周围环境的感知,并提供物体尺寸的近似估计,支持动态及静态场景的全面预测,具有低延迟和低内存占用的特点 。






最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
