




 广告
广告





















































一文读懂自动驾驶世界模型

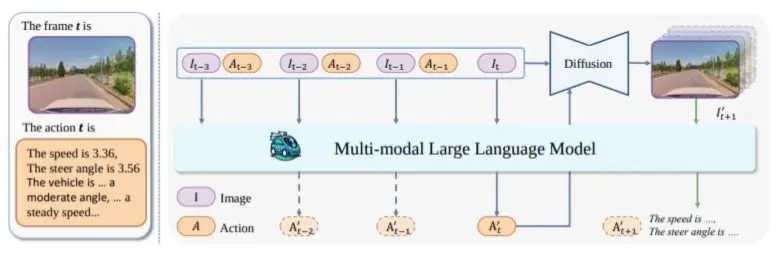
DriveDreamer [64] 同样专注于驾驶场景生成,但与GAIA-1不同的是,它是在nuScenes数据集 [92] 上进行训练的。它的模型输入包含了更多元素,如高清地图和三维框,这使得对驾驶场景生成具有更精确的控制和更深的理解,从而提高了视频生成的质量。此外,DriveDreamer还可以生成未来的驾驶动作及其对应的预测场景,有助于决策制定。
ADriver-I采用当前视频帧和历史视觉-动作对作为多模态大型语言模型 (MLLM) [93] [94] 和视频隐变量扩散模型 (VDM) [95] 的输入。MLLM以自回归的方式输出控制信号,这些信号作为VDM预测后续视频输出的提示。通过连续的预测循环,ADriver-I实现了在预测世界中的无限驾驶。在ADriver-I中,世界模型与MLLM的结合显著提高了预测和决策的可解释性,并且也表明了将世界模型作为基础模型与其他模型相结合的可行性。
受到大型语言模型成功的启发,WorldDreamer [79] 将世界建模视为一项无监督视觉序列建模挑战。它利用空间时间注意转换器 (STPT) 来集中注意力于时空窗口内的局部区域。这种集中注意力的方式促进了视觉信号的动态学习并加速了训练过程的收敛。尽管WorldDreamer是一个通用的视频生成模型,但它在生成自动驾驶视频方面表现出了卓越的性能。
除了视觉信息之外,驾驶场景还包括大量重要的物理数据。MUVO [76] 利用世界模型框架来预测和生成驾驶场景,并将激光雷达点云和视觉输入相结合来预测未来的视频、点云和三维占用网格。这种综合的方法显著提升了预测质量和生成结果。特别是,三维占用网格的结果可以直接应用于下游任务。更进一步,OccWorld [78] 和Think2Drive [83] 直接利用三维占用信息作为系统输入来预测周围环境的变化并规划自动驾驶车辆的动作。很明显,随着研究的进展,自动驾驶领域中用于场景生成的世界模型研究正逐渐向多模态方法发展。世界模型已经展现出了处理多模态信息的强大能力。
6. 世界模型在强化学习中的应用与进展
这一章节主要介绍了强化学习中的世界模型(World Models)及其应用。世界模型是一种基于神经网络的模型,可以将环境的状态、动作和奖励之间的关系建模,并用于控制智能体的行为。世界模型的应用包括自主驾驶、游戏AI等领域。
在该章节中,作者列举了多个使用世界模型进行强化学习的研究案例,如“Mastering Atari with Discrete World Models”、“Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving”等。这些研究都取得了很好的效果,证明了世界模型在强化学习中的重要性。还介绍了一些世界模型的具体实现方法,如“Dyna”、“Reinforcement Learning with Continuous State and Action Spaces Using a Convolutional World Model”等。这些方法都是基于深度学习技术的,通过不断优化模型参数来提高模型的性能。总之,世界模型是强化学习领域的一个重要分支,其应用前景广阔,未来还有很大的发展空间。
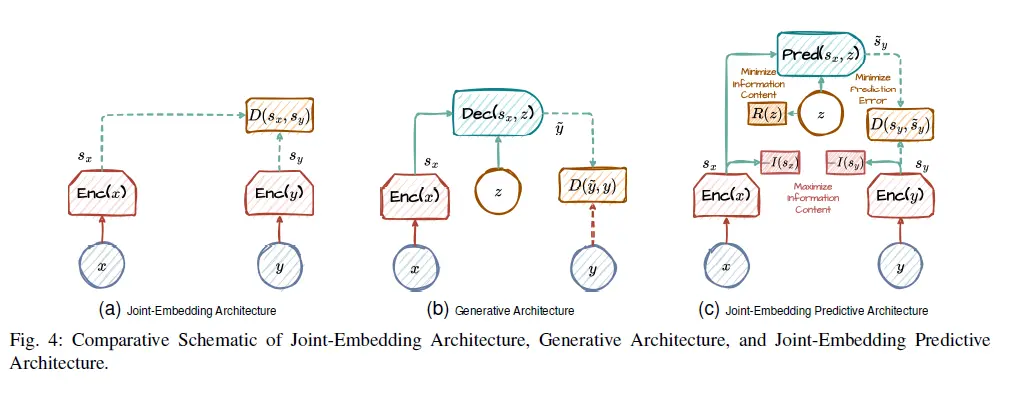
为了应对这一挑战,提出了多种策略,从通过引入温度变量来增加不确定性[31],到采用结构化的框架,如循环状态空间模型 (RSSM) ,和联合嵌入预测架构 (JEPA) 。这些方法力求在预测的精确性和灵活性之间找到最佳平衡。此外,利用Top-k采样并从基于卷积神经网络 (CNN) 的模型转向变换器架构,如变换器状态空间模型 (TSSM) 或空间时间块状变换器 (STPT),已经在通过更好地逼近现实世界的复杂性和不确定性来提高模型性能方面显示出潜力。这些解决方案力求使世界模型的输出更加接近现实世界可能的发展情况。这种一致性至关重要,因为与游戏环境相比,现实世界有着更广泛的影响因素和对未来结果更大的随机性。过度依赖最高概率的预测可能会导致长期预测中的重复循环。相反,预测中过度的随机性可能导致与现实严重偏离的荒谬未来。
特别是在世界模型研究中最常使用的两种核心结构是RSSM和JEPA:
循环状态空间模型 (RSSM) 是Dreamer系列世界模型中的核心模型之一,旨在实现在潜在空间中的纯前向预测。这种创新结构使模型能够在潜在状态空间中进行预测,其中过渡模型中的随机路径和确定性路径都发挥着关键作用,从而成功地进行规划。
下图展示了跨越三个时间步骤的潜在动力学模型的示意图。这些模型最初观测两个时间步骤,然后预测第三个。在这里,随机变量(圆形)和确定性变量(方形)在模型架构内部相互作用——实线表示生成过程,而虚线则代表推断路径。图3a中的初始确定性推断方法揭示了其局限性,由于其固定性质,无法捕获多样化的潜在未来。相反,图3b中的完全随机方法在时间步骤间的信息保留方面存在问题,因为其本质上具有不确定性。
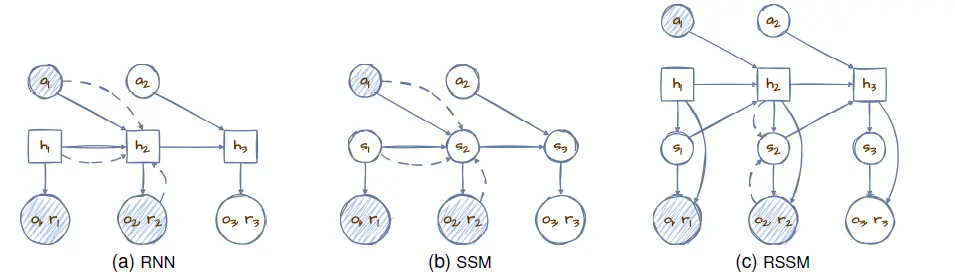
RSSM的创新之处在于它在图3c中战略性地将状态分解为随机和确定性成分,有效地利用了确定性元素的预测稳定性以及随机元素的适应潜力。这种混合结构保证了强大的学习和预测能力,既适应了现实世界的不可预测性,又保持了信息的连续性。通过结合RNN的优势与状态空间模型 (SSM) [54] 的灵活性,RSSM为世界模型建立了一个全面的框架,增强了它们在保持精确性和适应性的同时预测未来状态的能力。
7. 自动驾驶技术的发展与挑战
这一章节主要介绍了自动驾驶领域的研究进展和应用现状。其中提到了许多与自动驾驶相关的技术和算法,如3D场景理解、世界模型等,并列举了一些相关论文的摘要。此外,还讨论了自动驾驶技术在智能交通系统中的作用以及面临的挑战和问题,例如数据隐私保护、道德伦理等方面的问题。最后,文章提出了一些未来的研究方向和发展趋势,包括跨模态感知、多任务学习等。
(1) 驾驶场景生成
在自动驾驶领域的数据获取面临着诸多挑战,包括与数据收集和标注相关的高昂成本、法律限制以及安全考量。世界模型通过自我监督学习范式提供了一种有前景的解决方案,它能够从大量的未标记数据中提取有价值的见解,从而以成本效益高的方式增强模型性能。世界模型在驾驶场景生成中的应用尤其值得注意,因为它促进了多样化且真实的驾驶环境的创建。这种能力显著丰富了训练数据集,使自动驾驶系统具备了应对罕见和复杂驾驶情景的稳健性 。
GAIA-1 代表了一种新颖的自主生成式人工智能模型,能够利用视频、文本和动作输入来创建逼真的驾驶视频。通过Wayve在英国城市广泛的真实世界驾驶数据进行训练,GAIA-1学会了理解一些现实世界的规则和驾驶情景中的关键概念,包括不同类型的车辆、行人、建筑物和基础设施。它可以根据几秒钟的视频输入预测并生成后续的驾驶情景。值得注意的是,生成的未来驾驶情景并不紧密地依赖于提示视频,而是基于GAIA-1对世界规则的理解。GAIA-1的核心采用了自回归变换网络,根据输入的图像、文本和动作令牌预测即将出现的图像令牌,然后将这些预测解码回像素空间。
GAIA-1可以预测多个潜在的未来,并根据提示(例如改变天气、场景、交通参与者、车辆动作)生成多样化的视频或特定的驾驶情景,甚至包括超出其训练集的动作和场景(例如强行驶入人行道)。这展示了它理解并推断不在其训练集中的驾驶概念的能力,同时也证明了它的反事实推理能力。在现实世界中,由于风险性,很难获取这类驾驶行为的数据。驾驶场景生成允许进行模拟测试,丰富数据组成,增强系统在复杂情景下的能力,并更好地评估现有的驾驶模型。
此外,GAIA-1能够生成连贯的动作,并有效地捕捉三维几何结构的视角影响,展现了其对上下文信息和物理规则的理解。结合其展示出的反事实推理能力,可以说GAIA-1在自动驾驶的世界模型方面达到了很高的成就水平,无论是在抽象概念的理解还是因果推理方面。



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
