




 广告
广告





















































基础模型在推进自动驾驶汽车中的前瞻性作用

编者按:该期刊论文围绕基础模型(Foundation Model, FM)在自动驾驶技术中的应用展开,论文深入探讨了基础模型在自动驾驶技术中的多种应用,具体分析并总结了基于大语言模型、视觉语言模型和世界模型对自动驾驶的增强作用,并相应提出了当前面临的挑战以及潜在的研究方向,以期帮助读者更全面地理解当前基础模型在自动驾驶领域的应用现状。
本文译自:
《Prospective Role of Foundation Models in Advancing Autonomous Vehicles》
文章来源:
Research 16 Jul 2024 Vol 7 Article ID: 0399
作者:
Jianhua Wu1; Bingzhao Gao1,2; Jincheng Gao1; Jianhao Yu1; Hongqing Chu1*;Qiankun Yu3; Xun Gong4; Yi Chang4; H. Eric Tseng5; Hong Chen6,7*; and Jie Chen2,7.
作者单位:
1.School of Automotive Studies, Tongji University, Shanghai 201804, China; 2. Frontiers Science Center for Intelligent Autonomous Systems, Tongji University, Shanghai 201210, China; 3. SAIC Intelligent Technology, Shanghai 201805, China; 4. College of Artificial Intelligence, Jilin University, Changchun 130012, China; 5. Research and Advanced Engineering, Ford Motor Company, Dearborn, MI 48124, USA; 6. College of Electronic and Information Engineering, Tongji University, Shanghai 201804, China; 7. National Key Laboratory of Autonomous Intelligent Unmanned Systems, Shanghai 201210, China.
原文链接:
https://doi.org/10.34133/research.0399
摘要:随着人工智能的发展和深度学习的突破,大型基础模型(FMs),如GPT、Sora等,在包括自然语言处理和计算机视觉在内的许多领域都取得了显著成果。FMs在自动驾驶中的应用具有相当大的前景。例如,它们可以有助于增强场景理解和推理。通过对丰富的语言和视觉数据进行预训练,FMs可以理解和解释驾驶场景中的各种元素,并提供认知推理,为驾驶决策和规划给出语言和行动指令。此外,FMs可以基于对驾驶场景的理解来增强数据,以提供长尾分布中的罕见场景,这些在常规驾驶和数据采集过程中难以覆盖性挖掘。这种增强可以随后进一步提高自动驾驶系统准确性和可靠性。FMs应用潜力的另一个证明是世界模型,以DREAMER系列为例,它展示了理解物理定律和动力学的能力。在自监督学习范式下,从海量数据中学习,世界模型可以生成看不见但可信的驾驶环境,促进道路使用者行为预测的增强和驾驶策略的离线训练。在本文中,我们综合了FMs在自动驾驶中的应用和未来趋势。通过利用FMs的强大功能,我们努力解决自动驾驶中长尾分布的潜在问题,从而提高该领域的整体安全性。
1 引言
自动驾驶作为人工智能中最具挑战性的任务之一,受到了广泛关注。传统的自动驾驶系统采用模块化开发策略[1,2],即感知、预测和规划被分别开发并集成到车辆中。然而,模块之间传输的信息是有限的,并且存在信息缺失。此外,传播过程中存在累积误差,模块化传输的计算效率相对较低。这些因素共同导致模型性能不佳。为了进一步减少误差并提高计算效率,近年来,研究人员尝试以端到端的方式训练模型[3,4]。端到端意味着模型直接从传感器数据中获取输入,然后直接为车辆输出控制决策。虽然已经取得了一些进展,但这些模型仍然主要依靠人工标记数据的监督学习(SL)由于现实世界中驾驶场景的千变万化,仅用有限的标记数据覆盖所有潜在的情况具有挑战性,这导致模型泛化能力较差,难以适应复杂多变的现实世界极端情况。
近年来,基础模型(FMs)的出现为解决这一差距提供了新的思路。FMs通常被认为是在不同数据上训练的大规模机器学习模型,能够应用于各种下游任务,这可能不一定与其原始训练目标直接相关。该术语由斯坦福大学于2021年8月提出,称为“在广泛数据上训练的任何模型(通常使用大规模的自我监督),可以通过微调适应到广泛的下游任务”[5]。FMs的应用领域包括自然语言处理(Natural Language Processing,NLP)和计算机视觉(Computer Vision,CV),极具代表性的如BERT[6]和GPT-4[7],以及Sora[8]等。大多数FMs是基于一些经典网络架构构建的,例如,BERT和GPT-4是Transformer[9],Sora是基于DiffusionTransformer[10]。
与传统深度学习不同,FMs可以通过自监督预训练直接从海量未标记数据(如视频、图像、自然语言等)中学习,从而获得更强的泛化能力和涌现能力(被认为已经出现在大语言模型[LLM]中)。基于此,在使用少量监督数据进行微调后,FMs可以快速适配并迁移到自动驾驶等下游任务中。凭借自监督预训练赋予的强大理解、推理和泛化能力,FMs有望打破传统模型的瓶颈,使自动驾驶系统能够更好地理解和适应复杂的交通环境,从而提供更安全、更可靠的自动驾驶体验。
1.1. 涌现能力
基础模型(FMs)的一大重要特征是涌现,Bommasani等人[5]将FMs的涌现特征或涌现能力描述为“如果能力不存在于较小的模型中,而是存在于较大的模型中,那么它就是涌现的”。例如,语言模型(LM)对下游任务多样化的适应性,这是一种与初始训练没有直接联系的新行为,随着模型扩展超过一个未明确的阈值时突然出现,转变为LLM[11]。
目前,FMs的涌现能力主要体现在大语言模型(Large Language Model, LLM)领域,在图1[12]中可以看出,随着模型大小、数据集大小以及用于训练的计算浮点数的增加,LLM的损耗减小,为进行大规模模型训练提供了支持,图2[11]表明,当模型的参数量达到一定水平时,LLM的能力将得到质的飞跃,在不同的任务中表现出涌现能力。

图1 扩展定律
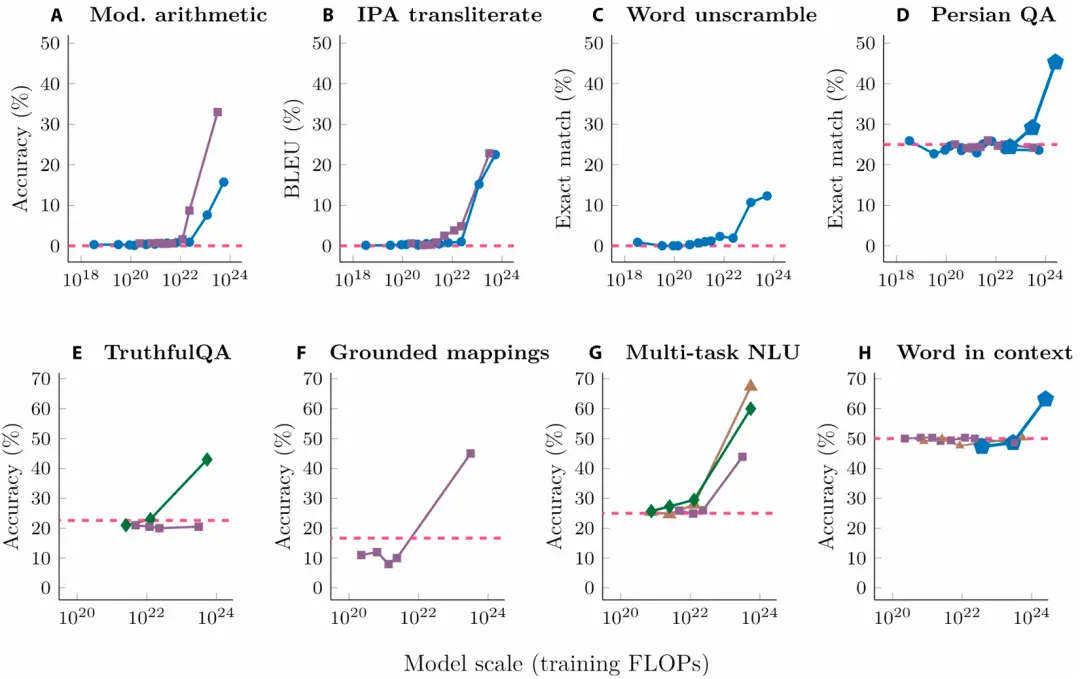
图2 LLM 的涌现能力[11]。(A)至(H)代表不同的下游任务。(A) 三位数加减法和两位数乘法;(B) 国际音标转写;(C) 恢复乱码单词;(D) 波斯语答题;(E) 如实回答问题;(F) 映射概念域。(G) 大规模多任务语言理解;(H) 上下文词汇语义理解;每个点都是一个单独的 LLM,虚线代表随机表现。
LLM的涌现能力在上下文学习(In Context Learning,ICL)[11,13]中得到了很好的体现,严格来说,它可以被视为提示学习的子类。上下文学习能力是LLM在特定上下文环境中学习的能力,主要思想是来自于类比中学习[14]。ICL或提示学习使LLM在特定上下文中获得优异的性能,而无需参数调整。
一种特殊类型的ICL是思想链(Chain-of-Thought, CoT)。用户可以将复杂的问题分解为一系列推理步骤作为LLM的输入。这样,LLM可以执行复杂的推理任务[15]。紧急能力在LLM中很常见;目前还没有令人信服的解释为什么这些能力会以这样的方式出现。
Park等人[16]引入了模拟真实人类行为的生成代理,基于预输入设置执行日常活动,并以自然语言存储日常记忆。作者将生成代理连接到LLM,创建了一个拥有25个智能代理的小社会,用LLM检索记忆,并利用其涌现能力来规划智能代理的行为。在实验中,智能代理除了行为之外,还出现了越来越多的社会行为,充分展示了LLM的智能涌现。
1.2. 预训练
FMs的实现基于迁移学习和规模化[5],迁移学习的思想[17,18]是将在一个任务中学习到的知识应用到另一个任务中,在深度学习中,迁移学习分预训练和微调两个阶段,FMs用海量数据进行预训练,得到预训练模型后,选择特定的数据集进行微调,以适应不同的下游任务。
预训练是FMs获得涌现能力的基础。通过对海量数据进行预训练,FMs可以获得基本的理解和生成能力。预训练任务包括监督学习(Supervised Learning,SL)、自监督学习(self-supervised learning,SSL)等[19]。早期的预训练依赖于SL,尤其是在CV中。为了满足神经网络的训练需求,构建了一些大规模的监督数据集,如ImageNet[20]。然而,SL也有一些缺点,即需要大规模的数据标注。随着模型大小和参数量的逐渐增加,SL的缺点变得更加明显。在NLP中,由于文本标注的难度远大于图像标注,SSL因其不需要标注的特点逐渐受到学者们的青睐。
1.2.1.自监督学习
SSL允许为后续任务学习未标记数据中的特征表示。SSL的显着特点是它们不需要手动标记标签,而是从未标记的数据样本中自动生成标签。
SSL通常涉及2个主要过程[21]:(a)自监督训练阶段:训练模型以解决设计的辅助任务,并在此阶段根据数据属性自动生成伪标签,旨在让模型学习数据的通用表示。(b)下游任务应用阶段:经过自监督训练后,模型学习到的知识可以进一步用于实际的下游任务(Downstream tasks)。下游任务使用SL方法,其中包括语义分割[22]、目标检测[23]、情感分析[24]。由于自监督训练,模型在下游任务中的泛化能力和收敛速度将大大提高。
SSL方法一般分为3类[25]:基于生成的方法(Generative-based)、基于对比的方法(Contrastive-based)和基于对抗的方法(Adversarial-based)。基于生成的方法:它首先使用编码器对输入数据进行编码,然后使用解码器重新获得数据的原始形式。模型通过最小化误差来学习。基于生成的方法包括自回归模型(Auto-regressive models)、自编码模型(Auto-encoding models)等[26]。基于对比的方法:它通过辅助任务构造正负样本,通过比较与正负样本的相似度来学习。这样的方法包括SimCLR[27]等。基于对抗的方法:这种方法由一个生成器和一个鉴别器组成。生成器负责生成假样本,而鉴别器适用于区分这些假样本和真实样本[25],一个典型的例子是生成对抗网络(GANs)[28]。
1.2.2.SSL的辅助任务
辅助任务也可以称为自监督任务,因为它们依赖数据本身来生成标签。这些任务是旨在使模型学习与特定任务相关的表示,从而更好地处理下游任务。
在CV中,根据数据属性设计辅助任务的方法主要有4大类[21]:基于生成的方法,基于上下文的方法,基于自由语义标签的方法和跨模态的方法。其中,基于生成的方法主要涉及图像或视频生成任务[29,30];基于上下文的辅助任务主要是利用图像或视频的上下文特征设计的,如上下文相似性、空间结构、时间结构等[31-33];在基于自由语义标签的辅助任务中,利用自动生成的语义标签训练网络[34];而基于跨模态的辅助任务需要考虑视觉和语音等多种模态[35]。
在NLP中,最常见的辅助任务包括[36]中心和邻近词预测(Center and neighbor word prediction)、下一个和邻近句预测(Next and neighbor sentence prediction)、自回归语言建模(Autoregressive Language Modeling)、句子排列(Sentence Permutation)、掩码语言建模(Masked Language Modeling)等。其中,Word2Vec[37]模型使用中心词预测作为辅助任务,而BERT模型使用下一个句子预测和掩码语言建模作为辅助任务。这些模型被训练来学习语料库的表达式并应用于下游任务。
1.3. 微调
微调是基于已经训练好的模型对特定任务进行进一步训练的过程,以使其适应任务的特定数据和要求。通常,已经在大规模数据上预训练作为基础模型,然后在特定任务上进行微调以提高性能。目前,在LLM领域,微调方法包括2种主要方法:指令调整和对齐调整[38]。
指令微调旨在对指令描述的一组数据集上的预训练模型进行微调[39]。指令微调一般包括2个阶段。首先,需要收集或创建指令格式化的实例。然后,使用这些实例对模型进行微调。指令微调允许LLM在以前未见过的任务上表现出强大的泛化能力。经过预训练和微调后得到的模型在大多数情况下都能很好地工作;然而,可能会出现一些特殊情况。例如,在LLM的情况下,训练后的模型可能会出现伪造虚假信息或保留来自语料库的有偏见的信息。为了避免这样的问题,提出了人类对齐微调的概念。目标是使模型的行为符合人类的期望[40]。与指令微调相比,这种对齐需要考虑完全不同的标准。
GPT系列是典型的FM,它的训练过程同样也包括预训练和微调两阶段,以ChatGPT为例,ChatGPT的预训练过程采用自监督预训练[41],给定无监督语料库,使用标准语言建模方法优化其最大似然估计(MLE),GPT使用了多层Transformer解码器架构[42],从而产生预训练模型。
ChatGPT的微调阶段由以下3个步骤组成[40],首先,对获得的预训练模型进行监督微调(Supervised fine-tuning,SFT);其次,收集比较数据以训练奖励模型(Reward Model, RM);以及第三,利用近端策略优化(PPO)算法对SFT模型进行微调,使奖励最大化[43],后两个步骤加在一起就是利用人类反馈的强化学习(RLHF)[44]。
1.4. FMs在自动驾驶中的应用
自动驾驶的最终目标是实现能够完全替代人类驾驶的驾驶系统,而评价的基本标准是像人类驾驶员一样驾驶,这对自动驾驶模型的推理能力提出了非常高的要求。我们可以看到,基于大规模数据学习的FMs具有强大的推理和泛化能力,在自动驾驶中具有巨大的潜力。在为自动驾驶赋能中,可以利用FMs增强场景理解,给出语言引导的命令,生成驾驶动作。此外,还可以通过强大的生成能力来增强FMs,用于数据增强,包括扩展现有的自动驾驶数据集和直接生成驾驶场景。特别是,世界模型(FMs的一种)可以学习物理世界的内部运作,并预测未来的驾驶场景,这对自动驾驶具有实质性的重要意义。
因此,有必要对FMs在自动驾驶中的应用进行全面审查。本文对此进行了回顾。
-
在“有监督的端到端自动驾驶”部分,提供了最新有监督的端到端自动驾驶的简要概述,以便读者更好地了解背景。
-
“基于语言和视觉模型的类人驾驶”部分回顾了语言和视觉FMs在增强自动驾驶方面的应用。
-
“基于世界模型的自动驾驶预测”部分回顾了世界模型在自动驾驶领域探索中的应用。
-
“基于基础模型的数据增强”部分回顾了FMs在数据增强中的应用。
在上述概述的基础上,“结论和未来方向”部分介绍了使用FMs增强自动驾驶的挑战和未来方向。
2 有监督的端到端自动驾驶
自动驾驶研究中“预训练+微调”的研究思路不仅在引入大型模型后才出现,而是已经被研究了很长时间。用一个更熟悉的术语来说,就是端到端自动驾驶。在过去的几年里,一些学者已经通过各种方式对预训练骨干进行了优化,包括Transformer架构和SSL方法。注意,这里的预训练骨干是指将每个模态输入转换为下游任务(如目标检测、轨迹预测、决策规划等)可用的特征表示的模型。基于Transformer架构开发端到端框架也进行了许多研究尝试,取得了优异的成果。因此,为了更全面地总结底层模型在自动驾驶中的应用,我们认为有必要介绍基于预训练骨干网的端到端自动驾驶相关研究。在本节中,我们总结了关于端到端自动驾驶解决方案的预训练骨干网的最新研究。这些方法的流程在图3中简要说明。
2.1. 预训练Backbone
在端到端建模中,从原始数据中提取低级信息的特征在一定程度上决定了后续模型性能的潜力,优秀的预训练Backbone可以赋予模型更强大的特征学习能力。
ResNet[45]和VGGNet[46]等预训练卷积网络是端到端模型中使用最广泛的视觉特征提取骨干。这些预训练网络经常被训练为利用目标检测或分割作为提取广义特征信息的任务,它们的竞争性能已经在许多工作中得到验证。ViT[47]首先将transformer架构应用于图像处理,并取得了出色的分类结果。Transformer以其更简单的架构和更快的推理速度,具有处理大规模数据的优化算法的优势。自注意力机制非常适合处理时间序列数据。它能够对环境中物体的时间运动轨迹进行建模和预测,有利于融合来自多个来源的异构数据,如LiDAR点云、图像、地图等。
以LSS[48]、BEVDet[49]、BEVformer[50]、BEVerse[51]等为代表的另一类预训练骨干网,通过提取环绕摄像头拍摄的图像并通过模型学习将其转换为鸟瞰图(BEV)特征,将局部图像特征从二维(2D)视点索引到3D空间,从而扩展了可用性。近年来,BEV因其能够更准确地描述驾驶场景而引起了广泛的兴趣,利用预训练Backbone输出等BEV特征的研究不仅限于相机,多模态感知的提取和融合以BEVFusion[52]为代表的BEV特征进一步为自动驾驶系统提供了更广阔的视野。然而,需要指出的是,尽管transformer架构带来了巨大的性能增强,但这种Backbone仍然使用SL方法构建预训练模型,这些方法依赖于海量标记数据,数据质量也极大地影响了模型的最终结果。
在相机和点云处理域中,一些工作通过无监督或SSL方法实现预训练Backbone。Wu等[53]提出了PPGeo模型,该模型使用大量未标记的驾驶视频分2个阶段完成视觉编码器的预训练,并且可以适应不同的下游端到端自动驾驶任务。Sautier等[54]提出了BEVContrast,用于汽车LiDAR点云上3D Backbone的自监督,它定义了BEV平面中2D单元级别的对比度,保留了PointContrast[55]中的简单性,同时在下游驾驶任务中保持了良好的性能。特别是,虽然“掩码+还原”的SSL方法也被认为是建模世界的有效方式,Yang等[56]提出了Unipad,它是基于SSL方法实现的,用于掩码自动编码和3D渲染。这些多模态数据的一部分被随机键出来进行掩码并转换到体素空间,其中RGB或深度预测结果通过渲染技术在这样的3D空间中生成,其余的原始图像被用作SL的生成数据。该方法的灵活性使得能够很好地集成到2D和3D框架中以及下游任务,如深度估计、目标检测、分割,以及在模型上进行微调和训练的许多其他任务表现出色。

图3 带有预训练Backbone的端到端监督式自动驾驶系统。多模态传感信息被输入到预训练Backbone以提取特征,然后进入由各种方法构建的自动驾驶算法框架,以实现规划/控制等任务,从而完成端到端自动驾驶任务。
2.2. 有监督的端到端自动驾驶模型
端到端自动驾驶建模的早期工作主要基于各种类型的深度神经网络,通过模仿学习[57-61]或强化学习[62-64]的方法构建,陈等[3]的工作从方法论的角度分析了端到端自动驾驶面临的关键挑战,指出了用Transformer等基础模型为端到端自动驾驶赋能的未来趋势,一些学者尝试用Transformer构建端到端自动驾驶系统,得到了不错的效果。例如,已经有Transfuser[65,66]、NEAT(端到端自动驾驶的神经注意力领域)[67]、Scene Transformer[68]、PlanT[69]、Gatform[70]、FusionAD[71]、UniAD[72]、VAD(高效自动驾驶的矢量化场景表示)[73]、GenAD[74]以及许多基于Transformer架构开发的端到端框架。
Chitta等人[65,66]提出了Transfuser,它将来自LiDAR的RGB图像和BEV视图作为输入,使用多个Transformer融合特征图,并通过单层门控循环单元(GRU)网络预测接下来4步的轨迹点,随后通过纵向和横向比例-积分-微分(PIDs)来控制车辆运行。NEAT[67]进一步将BEV场景映射到轨迹点和语义信息,然后使用中间注意力图压缩高维图像特征,这使得模型可以专注于驾驶相关区域,忽略驾驶任务无关的信息。Renz等人[69]提出的PlanT使用简单的对象级表示(车辆和道路)作为Transformer编码器的输入,并将周围车辆的速度预测作为次要任务来预测未来的航路点轨迹。Hu等人[72]提出的UniAD增强了解码器的设计,并实现了将全栈自动驾驶任务整合到一个统一的框架中,以提高自动驾驶性能,尽管每个任务仍然依赖不同的子网络。这项工作还获得了CVPR 2023最佳论文奖,这表明了对端到端自动驾驶范式的学术认可。然而,这些模型往往需要密集的计算。为此,江等人[73]提出了一种方法,将驾驶场景完全向量化,并学习实例级结构信息,以提高计算效率。与之前的模块化端到端规划相比,Zheng等人[74]提出了一种生成式端到端,将自动驾驶建模为轨迹生成。
而且,Wang等人[75]提出的Drive Anywhere不仅实现了端到端的多模态自动驾驶还与LLM相结合,能够基于可通过图像和文本查询的表示提供驾驶决策。Dong等人[76]生成的基于图像的动作命令和解释,并通过构建基于Transformer的特征提取模型进行解释。Jin等人[77]提出了ADAPT模型,通过端到端模型直接输出带有推理语言描述的车辆控制信号。这是第一个基于动作感知transformer的驾驶动作字幕架构。它在完成驾驶控制任务的同时,添加了自然语言叙述,以指导自动驾驶控制模块的决策和行动过程。它还帮助用户时刻获取车辆的状态和周围环境,并更好地了解自动驾驶系统所采取行动的基础,提高了决策的可解释性。从中我们亦可窥见Transformer架构在增强端到端驾驶决策可解释性方面的潜力。
3 基于语言和视觉模型的类人驾驶
随着LLMs BERT、GPT-4和Llama[78];视觉语言模型(VLMs)CLIP[79]、ALIGN[80]和BLIP-2[81];和多模态大语言模型(M-LLMs)GPT-4V[82]、LLaVA[83]和Gemini[84]以及其他FM的显著研究进展,其强大的推理能力被认为为实现人工通用智能迎来了新的曙光[85],对社会的方方面面产生了显著而深远的影响。在自动驾驶中,语言和视觉等FMs也显示出巨大的潜力,有望提高自动驾驶模型对驾驶场景的理解和推理能力,为自动驾驶实现类人驾驶。
我们介绍了基于语言和视觉FMs来增强自动驾驶系统对驾驶场景理解,以及推理给出语言引导指令和动作指令的相关研究,如图4所示。关于增强对驾驶场景理解的相关工作在“驾驶场景理解”部分介绍,关于给出语言引导指令的推理在“语言引导指令”部分介绍,关于推理生成驾驶动作在“动作生成”部分介绍。
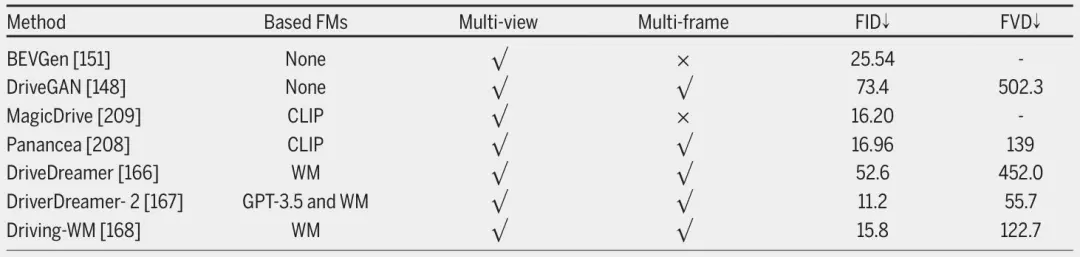
图4 利用 FMs 增强自动驾驶,其中 FMs指的是大语言模型和视觉语言模型。FMs可以学习感知信息,并利用其强大的理解驾驶场景和推理能力,给出语言指令和驾驶操作,从而增强自动驾驶。
3.1. 驾驶场景理解
Vasudevan等人[86]的研究发现,通过获取言语描述和凝视估计可以有效增强模型对场景的理解和对物体的定位能力。Li等人[87]提出了一种生成高级语义信息的图像字幕模型,以提高其对交通场景的理解。他们的工作验证了语言和视觉特征可以有效增强对驾驶场景的理解。
Sriram等人[88]提出了一种将语义分割结果与自然语言命令相结合的自主导航框架。在CARLA模拟器和KITTI数据集[89]中验证了自然语言命令作为汽车驱动的有效性。Elhafsi等人[90]通过将观察到的视觉信息转换为自然语言描述并将其传递给LLM,利用其强大的推理能力来识别语义异常。在VLM应用的背景下,Chen等人[91]将图像和文本特征转移到基于CLIP的3D点云网络中,以增强模型对3D场景的理解。Romero 等[92]基于CLIP的扩展模型VIVA[93]构建了一个视频分析系统,旨在通过利用VLM的强大理解来提高查询精度。Tian等人[94]采用VLM来描述和分析驾驶场景,从而增强了对驾驶场景的理解。除了直接对场景数据的理解增强,也有学者探索了对感知特征进行增强。Pan等人[95]设计了Ego-car提示,以使用CLIP中的LM来增强获得的BEV特征。Dewangan等人[96]提出了一种增强BEV地图的方法,通过VLMs(Blip-2[81]、Minigpt-4[97]和Instructblip[98])检测BEV中每个对象的特征,并通过语言表征来获得语言增强的BEV地图。然而,现有的VLM受限于2D域,缺乏空间感知和长时间域外推的能力。为了解决这个问题,Zhou等人[99]提出了一个模型,即Embodied Language Model(ELM),它增强了对长时间域和跨空间驾驶场景的理解。这是通过使用不同的预训练数据和选择自适应Token来实现的。
3.2. 语言引导指令
在这里,我们回顾了通过FMs给出语言指令的研究,主要是描述性指令,如“前方红灯,你应该减速”、“前方路口,请注意行人”等。Ding等人[100]使用视觉编码器对视频数据进行编码,然后将视频数据输入到LLM中,生成相应的驾驶场景描述和建议。特别是,这项工作还提出了一种方法,使高分辨率特征图和获得的高分辨率信息融合到M-LLM中,以进一步增强模型的识别、解释和定位能力。Fu等人[101]探索了利用LLM像人类一样理解驾驶环境的潜力,利用LLaMA-Adapter[102]描述场景数据,然后通过GPT-3.5给出语言命令。Wen等人[103]提出了DiLu,这是一种基于先前工作的知识驱动范式,可以基于常识性知识做出决策并积累经验。文章特别指出,DiLu具备指导真实世界数据的经验获取能力,具有自动驾驶系统实际部署的潜力。为了进一步提高基于LLM的自动驾驶的安全性,Wang等人[104]使用基于MPC的验证器对轨迹规划进行评估并提供反馈,然后融合提示学习,使LLM能够进行上下文安全学习,这从整体上提高了自动驾驶的安全性和可靠性。为了丰富数据输入以获得更准确的场景信息,Wang等人[105]利用多模型LLM使自动驾驶系统能够获得语言命令。同时,针对语言命令和车辆控制命令之间的差距,本工作对决策状态进行了对齐操作。
前面提到的工作更多的是在数据集和仿真环境的背景下进行的,在实车测试方面已经有了一些探索性的工作,Wayve提出了LINGO-1[106],一种基于视觉-语言-行动的大模型的自动驾驶交互大模型,其中模型可以自我解读,并在驾驶时进行视觉回答,它引入了人类驾驶体验,可以通过自然语言描述解释驾驶场景中的各种因果要素,以类人理解的方式获取驾驶场景中的特征信息,学习并给出交互式语言命令。Cui等人[107]创新性地将LLM置于云端,输入人类命令,并利用LLM的推理能力生成执行代码。然而,该工作存在延迟问题,在自动驾驶的实时性能要求方面有改进的空间。
当前研究中将LLM纳入自动驾驶系统的流程如图4所示,主要通过场景理解、高级语义决策和轨迹规划来实现。在本节中,我们总结了高级决策应用,并认为研究过程有一些相似之处。为了更清楚地说明它们是如何工作的,我们使用最近的典型研究工作DriveMLM[105]作为示例在图5中进一步说明。
DriveMLM通过使用M-LLM模拟模块化自动驾驶系统的行为规划模块,该模块基于处理后的感知信息和命令要求,在逼真的模拟器中执行闭环自动驾驶。DriveMLM还生成其驾驶决策的自然语言解释,从而增加系统的透明度和可信度。
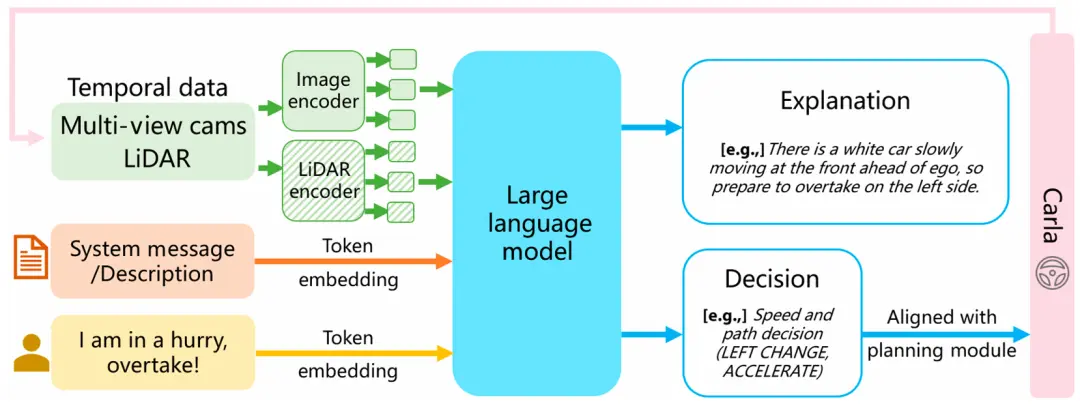
图5 关于LLM在自动驾驶系统决策中的应用,图中显示了一个典型架构,参考DriveMLM [105]。
3.3. 动作生成
正如“语言引导指令”部分所描述的,学术界和工业界已经尝试将GPT语言知识嵌入到自动驾驶决策中,以语言指令的形式增强自动驾驶的性能,以促进FMs在自动驾驶中的应用。早在FMs在LLM领域取得突破之前,就有一些工作试图通过类似的研究思路来提高自动驾驶的性能。例如,Casas等人[108]提出的MP3框架使用高层语义信息作为决策训练指导,这些信息与感知数据一起构成输入,以构建算法来实现运动预测。
语言大模型在自动驾驶领域的应用研究方兴未艾,GPT系列作为transformer架构目前最为成功的变体,或许能够在多个层面为提升综合表现带来新的突破。从语言知识层面来看,LLM是FMs代表;然而,语言描述和推理并不是自动驾驶系统直接应用的。考虑到大模型有望真正部署在车端,最终需要落在规划或控制指令上;即FMs最终应该从动作状态层面赋能自动驾驶。尽管如此,如何将语言决策量化为自动驾驶系统可用的动作命令,如规划和控制,仍然面临着巨大的挑战。一些学者已经进行了初步探索,但仍有很大的发展空间。此外,一些学者探索了通过类似GPT的方法构建自动驾驶模型,该方法直接输出基于LLM的轨迹甚至控制命令。在表1中,我们简要概述了一些代表性工作。
表1 利用 LLM 生成自动驾驶规划和控制的工作
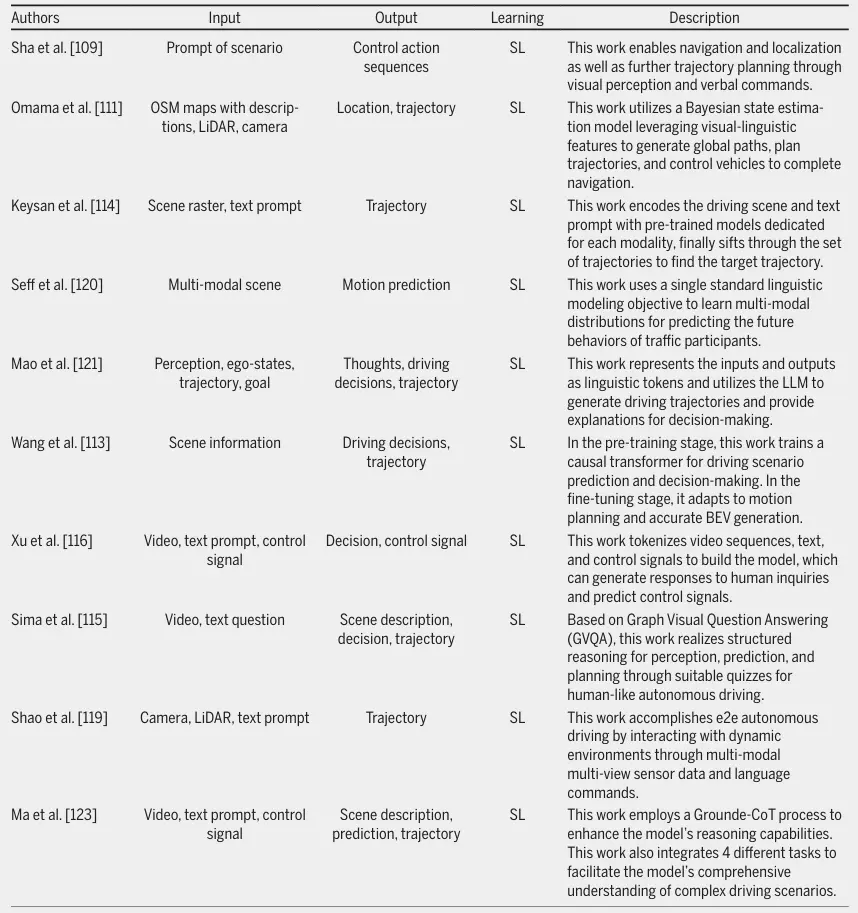
Sha等人[109]提出了LanguageMPC,它采用GPT-3.5作为需要人类常识理解的复杂自动驾驶场景的决策模块。通过设计认知路径来实现LLM中集成推理的,Sha等人提出了将LLM决策转化为可操作的驾驶控制命令的算法,从而提高了车辆处理复杂驾驶行为的能力。Jain等人[110]的研究对明确的语言命令借助视觉感知实现导航定位并进一步规划轨迹。Omama等人[111]构建了一种名为ALT-Pilot的基于多模态地图的导航和定位方法,该方法可用于导航到任意目的地,而无需高清LiDAR地图,证明了现成的视觉LMs可用于构建语言增强的地形地图。Pan等人[95]在训练阶段提出了VLP方法,以提高具有LLM强大推理能力的自动驾驶系统视觉感知和运动规划的上下文推理,并在开环端到端运动规划任务中取得了优异的性能。
一些学者还尝试通过类似GPT的方法直接构建自动驾驶模型,即利用LLM构建端到端的自动驾驶规划器,直接输出预测轨迹、路径规划甚至控制命令,旨在有效提高自动驾驶模型对未知驾驶场景的泛化能力。
Pallagani等人[112]构建了Plansformer,它既是一个LLM,也是一个规划器,显示了从多种规划任务中展现了大语言模型微调后作为规划器的巨大潜力。Wang等人[113]构建了BEVGPT模型,该模型将道路上当前环境信息作为输入,然后输出一个序列,其中包括未来的车辆决策指令和自动驾驶车辆可以遵循的空间路径。
一些工作[114-119]将文本提示和道路上当前环境的信息作为输入,然后输出文本响应或解释,以及包括未来车辆决策指令和自动驾驶车辆可以遵循的空间路径的序列。其中,Cui等人[117]利用GPT-4输入自然语言描述和环境感知数据,使LLM直接输出驾驶决策和操作命令。此外,他们在参考文献[118]中对高速公路超车和变道场景进行了实验。[118]比较了LLM提供的具有不同提示的驾驶决策,研究表明链式思维提示有助于LLM做出更好的驾驶决策。
一些学者也尝试了不同的想法。Seff等人[120]提出了MotionLM,它将运动预测作为语言建模任务,通过将连续轨迹表示为运动tokens的离散序列来学习多模态分布,利用单一标准语言建模目标来预测路网参与者的未来行为。Mao等人[121]提出了GPT-Driver模型,通过将规划者的输入和输出表示为语言标记,并利用LLM通过坐标位置的语言描述来生成驾驶轨迹,从而将运动规划任务重新表述为语言建模问题。此外 ,他们[122]提出了Agent Driver,它利用LLM引入了可通过函数调用访问的通用工具库,用于常识的认知记忆和用于决策的经验知识,以及能够进行CoT推理、任务规划、运动规划和自我反思的推理机器,以实现更细致入微的、类似人类的自动驾驶方法。Ma等人[123]提出了Dolphins,它能够执行诸如理解场景、行为预测和轨迹规划等任务。这项工作证明了视觉LM能够全面理解复杂和开放世界长尾驾驶场景,解决一系列自动驾驶任务的能力,以及包括上下文学习、无梯度的即时适应和反思性错误恢复在内的紧急类似人类的能力。
考虑到视觉语言模型(VLM)的规模挑战,Chen等人[124]基于数字矢量模态比图像数据更紧凑的想法,将矢量化2D场景表示与预训练的LLM融合,以提高LLM对综合驾驶情况的解释和推理能力,给出场景解释和车辆控制命令。Tian等人[94]提出DriveVLM,它通过CoT机制,不仅能够生成图像序列中呈现的场景的描述和分析,以做出驾驶决策指导,还可以进一步实现与传统自动驾驶流程相结合的轨迹规划。所提出的工作还为VLM在空间推理和计算方面固有的挑战提供了可能的解决方案,实现了现有自动驾驶方法和基于大型模型的方法之间的有效过渡。
与上一个小节一样,对于LLM应用于自动驾驶系统轨迹规划直接生成的研究工作,我们以图6中最近的一项典型研究工作LMDrive[119]为例,希望能更清楚地说明它是如何工作的。LMDrive基于Carla模拟器,模型训练由预训练和命令微调2个阶段组成。在预训练阶段,预测头被添加到视觉编码器中以执行预训练任务。预训练完成后,预测头被丢弃,视觉编码器被冻结。在指令微调阶段,为每个行驶段配置导航指令和通知指令,通过LLaMA指令编码的时间序列对视觉tokens进行处理,并与文本令牌一起输入到LLM中,得到预测tokens。2-MLP适配器之后,输出的是汽车未来轨迹的规划和指令是否完成的标志,规划的轨迹通过横向和纵向PID控制器完成闭环仿真。
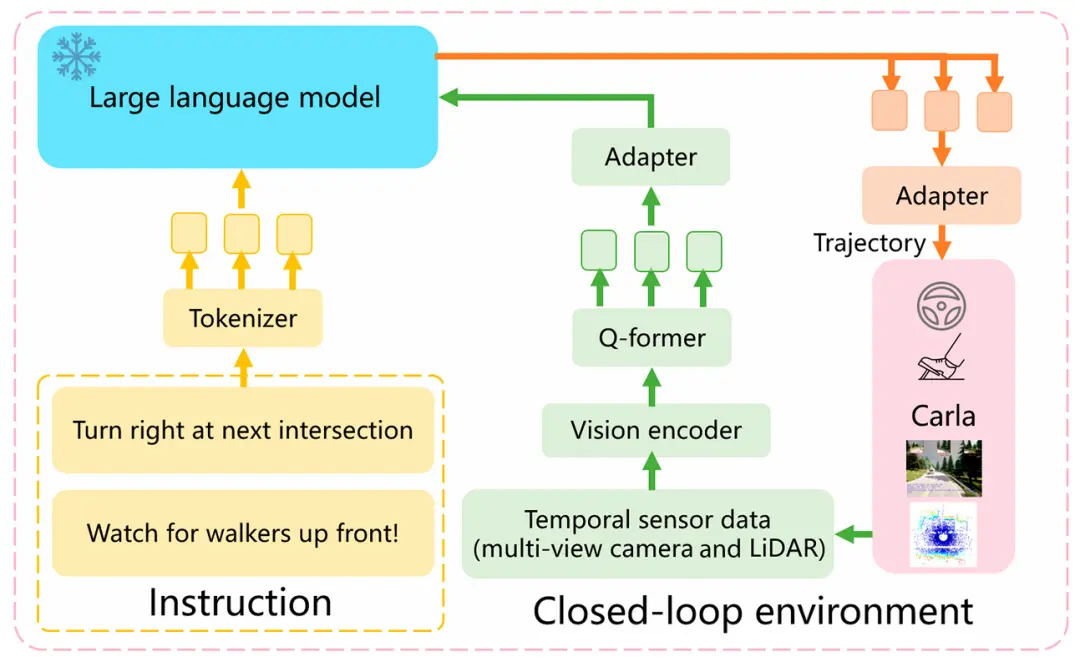
图6 关于 LLM 在自动驾驶系统规划中的应用,图中显示了一个典型架构,参考LMDrive [119]。
这种类型的研究思路比单纯的知识嵌入制作自动驾驶模型更接近人类驾驶。随着大模型的发展,也许有潜力成为未来的主要发展方向之一。运动规划作为智能机器人领域的基本主题之一[125],通过LLM将语言决策量化为自动驾驶系统可用的规划甚至控制等动作指令意义非凡,例如通过LLM为自动驾驶系统提供规划甚至控制。然而,应该注意的是,由于大模型本身未解决的陷阱,这些新框架在可靠性方面也存在问题,如“幻觉”(LLM可能会生成与来源或事实信息相冲突的内容)。关于大型模型本身的问题以及自动驾驶中继承的挑战的具体细节将在“结论和未来方向”部分详细讨论
4 基于世界模型的自动驾驶预测
世界模型(World models,WMs)是指世界的心理模型。它可以被解释为一种人工智能模型,包含对其运行的环境的整体理解或表示。这种模型能够模拟环境以做出预测或决策。在最近的文献[126,127]中,“世界模型”一词已在与强化学习联系中被提及。这一概念在自动驾驶中也获得了关注,因为它能够理解和阐明驾驶环境的动态,下文将详细介绍。LeCun[128]在他的立场文件中指出,人类和动物的学习能力可能植根于他们学习世界模型的能力,使他们能够内化和理解世界是如何运作的。他指出,人类和动物已经展示出一种能力,即通过观察少量事件,无论与手头的任务相关还是无关,就能获得关于世界运行的大量背景知识。世界模型的思想可以追溯到Dyna,由Sutton[129]在1991年提出,观察世界的状态并相应地采取适当的行动与世界进行交互学习[130]。Dyna本质上是监督条件下的强化学习形式。之后,研究人员也进行了许多尝试。Ha和Schmidhuber [126]试图通过利用无监督方法——变分自编码器(VAE)对输入特征进行编码,并利用循环神经网络(RNN)来学习状态的演变。Hafner等人[131]提出了循环状态空间模型(RSSM),该模型结合强化学习实现了融合随机性和确定性的多步预测。基于RSSM架构,Hafner等人相继提出了DreamerV1[132]、DreamerV2[133]、DreamerV3[134],在隐式变量中学习实现图像预测生成。Gao等人[135]考虑到隐式中存在冗余信息,通过提出语义屏蔽循环世界模型(SEM2)来扩展Dreamer系列的框架,学习相关驱动状态。Hu等人[136]去除了预测奖励,提出了一种基于模型的模仿学习(MILE)方法来预测未来状态。
可以看出,世界模型与强化学习、模仿学习和深度生成模型高度相关。然而,在强化学习和模仿学习中利用世界模型一般需要标记数据,所提到的SEM2和MILE方法都是在监督范式内进行的。也有人尝试基于标记数据的局限性将强化学习和无监督学习(UL)结合起来[137,138]。由于与SSL的密切关系,深度生成模型越来越受欢迎,该领域的研究人员进行了许多尝试。下面,我们将主要回顾生成世界模型在自动驾驶中的探索性应用;流程如图7所示,“深度生成模型”部分介绍了各类深度生成模型的原理及其在生成驱动场景中的应用,“生成方法”部分介绍了生成世界模型在自动驾驶中的应用,“非生成方法”部分将介绍一类非生成方法。

图7 利用世界模型增强自动驾驶。世界模型首先通过观察交通环境学习内在演变规律,然后通过连接适应不同驾驶任务的不同解码器来增强自动驾驶功能。
4.1. 深度生成模型
深度生成模型通常包括VAEs[139,140]、生成对抗网络(GANs)[28,141]、流模型[142,143]和自回归模型(ARs)[144-146]。
VAEs结合了自编码器和概率图形模型的思想来学习底层数据结构和生成新样本。Rempe等人[147]使用VAE学习交通场景的先验分布,并模拟事故多发场景的生成。GANs由生成器和判别器组成,它们利用对抗性训练相互竞争和增强,最终实现生成逼真样本的目标。Kim等人[148]使用GAN模型观察未标记视频帧的序列及其关联的动作对,以模拟动态交通环境。流模型通过一系列可逆变换,将简单的先验分布转换为复杂的后验分布,从而生成相似的数据样本。Kumar等人[149]使用流模型实现多帧视频预测。ARs是一类序列分析方法,基于序列数据之间的自相关性,描述现在和过去的关系,模型参数的估计通常是利用最小二乘法和最大似然估计来完成的。例如,GPT使用最大似然估计进行模型参数训练。Feng等人[150]实现了基于自回归迭代的车辆未来轨迹的生成。Swerdlow等人[151]实现了基于自回归transformer的街景图像生成。扩散模型是一种典型的自回归方法,它从纯噪声数据中学习逐步去噪的过程。扩散模型凭借其强大的生成性能,是当前深度生成模型中的新SOTA。[152-154]等工作证明了扩散模型具有很强的理解复杂场景的能力,视频扩散模型可以生成更高质量的视频。[155,156]等工作利用扩散模型生成了复杂多样的驾驶场景。
4.2. 生成式方法
基于深度生成模型的强大能力,利用深度生成模型作为世界模型来学习驾驶场景以增强自动驾驶已成为一种流行趋势,以下部分将回顾利用深度生成模型作为世界模型,在自动驾驶中的应用。在表2中,我们提供了一些代表性工作的简要概述。
表2 利用世界模型进行预测的工作

4.2.1.基于点云的模型
Zhang 等人[157]在Maskgit[158]的基础之上,并将其重构(recast)为离散扩散模型,用于点云预测。该方法利用VQ-VAE[159]对观测数据进行标记化,以进行无标签学习。Karlsson 等人[160]使用分层VAE构建世界模型,使用潜在变量预测和对抗建模生成伪完整状态,将部分观察与伪完整观测值匹配以预测未来的状态,并在KITTI-360[161]数据集上对其进行评估。特别的,它利用预训练的基于视觉的语义分割模型从原始图像中进行推断。Bogdoll 等人[162]构建了多模态自动驾驶生成式世界模型MUVO,利用原始图像和LiDAR数据来学习世界的几何表示。该模式以动作为条件,实现了3D占用预测,并可直接应用于下游任务(如规划)。类似地,Zheng等人[163]使用VQ-VAE来标记3D占用场景,并构建3D占用空间来学习可以预测自我意识车辆运动和驾驶场景演变的世界模型。为了获得更细粒度的场景信息,Min等人[164]使用的未标记image-LiDAR来预训练,以构建可以生成4D几何占用的世界模型。
4.2.2.基于图像的模型
为解决预测驾驶场景未来变化的难题,Wayve提出了一种生成世界模型GAIA-1[165]。GAIA-1使用transformer作为世界模型来学习并预测输入视频、文本和动作信号的下一个状态,然后生成逼真的驾驶场景。对于视频流的学习,GAIA-1采用了SSL,可以学习规模化的数据而获得全面的环境理解。Wang 等人[166]设计了一个2阶段训练策略。首先,采用扩散模型来学习驾驶场景并获得对结构化交通的理解。然后利用视频预测任务构建了一个世界模型——DriveDreamer。值得注意的是,通过整合历史驾驶行为,这种方法能够生成未来的驾驶动作。Zhao等人[167]通过结合LLM,在DriveDreamer框架之上构建了DriveDreamer-2,根据用户描述,LLM生成相应的Agent轨迹,以及HDMap信息可控地生成驾驶视频。Wang等人[168]通过联合建模未来的多视图和多帧来生成驾驶视频。这种方法大大提高了生成结果的一致性,并在此基础上生成了端到端的运动规划。
在业内,在2023年CVPR自动驾驶研讨会上,特斯拉研究员Ashok Elluswamy介绍了他们在利用生成式大模型生成未来驾驶场景方面的工作[169]。在演示中看到,特斯拉生成式大模型生成的视频与从真实车辆中捕获的视频非常接近。它还可以生成类似标注的语义信息,表明该模型也具有一些语义层面的理解和推理能力。特斯拉将他们的工作命名为“Learning a General World Model”,可以看出他们的理解是构建一个通用的世界模型。通过从真实车辆中采集的大量视频数据中学习,特斯拉意在为自动驾驶构建一个大型FM,它可以理解世界的动态演变。
4.2.3.视频预测
视觉是人类获取有关世界信息的最直接和最有效的手段之一,因为图像数据中包含的特征信息极其丰富。之前的众多工作[132-134,138,170]都通过世界模型完成了图像生成的任务,证明了世界模型对图像数据具有良好的理解和推理能力。然而,这些主要集中在图像生成上,在能够更好地体现世界动态演变的视频预测任务中仍然有所欠缺。视频预测任务需要对世界演化有更深入的理解,也需要对下游任务有更强的指导意义。在研究工作[160,165]中,它们都有效地预测了生成的未来交通场景,其中SSL可能是关键。之前的工作也对此进行了探索。Wichers等人[171利用原始图像]训练了一个模型,并提出了一种结合低级像素空间和高级特征空间(如,地标)的分层长期视频预测方法,与工作[134]相比,实现了更长时间的视频预测。Endo等人[172]在SSL范式下构建了一个模型,用于从单帧图像中预测未来的交通场景以预测未来。Voleti等人[173]基于具有概率条件分数的去噪扩散模型,通过随机屏蔽未标记的过去帧或未来帧来训练模型,这允许逐块自回归生成任意长度的视频。Finn等人[174]提出了在无监督条件下与世界进行物理交互,并通过预测前一帧像素运动的分布来实现视频预测。Micheli等人[175]验证了利用自回归Transformer作为世界模型的有效性,并通过SSL训练参数来实现游戏图像的预测。Wu等人[176]构建了一个以对象为中心的世界模型,以学习对象之间复杂的时空交互,并生成高视觉质量的未来预测。
受到LLM的启发,Wang等人[177]将世界建模视为无监督的视觉序列建模。使用VQ-GAN将视觉输入映射为离散的标记[178],然后使用时空转换器预测掩码tokens,以学习其中的物理演变规律,从而获得在各种场景下生成视频的能力。类似于LLM的tokens,OpenAI研究人员将视觉数据转换为patches,以提出视频生成模型Sora。为了解决视觉数据的高维性,他们将视觉数据压缩到一个较低维的潜在空间中,然后在这个潜在空间中进行扩散生成,然后将这个表示映射回像素空间,实现视频生成。通过从互联网规模的数据中学习,Sora实现了视频域中的scaling law,Sora可以基于不同的提示生成连贯的高清视频。同年,谷歌提出了一种生成式交互模型Genie[179],使用未标记的互联网游戏视频进行训练。特别是,Genie提出了一种潜在动作模型来推断每一帧之间的潜在动作,并通过训练构建了潜在动作的码本。使用时用户选择初始帧和指定的潜在动作,并自回归生成未来帧。随着模型大小和批量大小的增加,Genie也出现了scaling result。相比之下,Sora旨在生成具有高保真、可变持续时间和分辨率的视频内容。虽然视频质量不如Sora先进,但Genie针对构建生成式交互环境进行了优化,用户可以在其中逐帧操作以生成视频。
前面的研究证明了世界模型在增强自动驾驶方面是有效的。世界模型可以直接嵌入到自动驾驶模型中,以完成各种驾驶任务。此外,还探索了学习从大规模视觉数据构建通用世界模型,如Sora和Genie。这些FMs可以用于数据生成(将在“基于基础模型的数据增强”部分讨论)。此外,基于FMs的泛化能力,它们可以用于执行大量下游任务,甚至可以用于模拟世界。
4.3. 非生成式方法
与生成式世界模型相比,LeCun[128]通过提出基于能量模型(Energy-based Model)的联合提取和预测架构(Joint Extraction and Prediction Architecture,JEPA)来阐述世界模型的不同概念。这是一种非生成式的自监督架构,因为它不直接从输入x预测输出y,而是将x编码为sx以预测表示空间中的sy,如图8所示。这有一个优点,即它不必预测关于y的所有信息,并且可以消除不相关的细节。

图 8 生成法与非生成法的结构比较 [184]。(A) 生成式架构通过解码器网络,以附加变量 z(可能是潜在变量)为条件,从兼容信号 x 重构信号 y;(B) 联合嵌入式预测架构通过预测器网络,以附加变量 z(可能是潜在变量)为条件,从兼容信号 x 预测信号 y 的嵌入。
JEPA架构自提出以来,以优异的性能被几位学者应用于不同领域。在计算机视觉领域中,Skenderi等人[180]提出了Graph-JEPA,这是一种用于图域的JEPA模型。它将输入图划分为子图,然后预测目标子图在上下文子图中的表示。Graph-JEPA在图分类和回归问题上都获得了优异的性能。在音频领域,Fei等人[181]提出了A-JEPA,它将掩码建模原理应用于音频。经过实验验证,A-JEPA已被证明在语音和音频分类任务中表现良好。Sun等人提出了JEP-KD[182],它采用先进的知识蒸馏方法来增强视觉语音识别(Visual Speech Recognition,VSR)的有效性,缩小其与自动语音识别(Automatic Speech Recognition, ASR)之间的性能差距。
在CV领域,Bardes等人[183]提出了MC-JEPA,它采用JEPA架构和SSL方法来实现光流和内容特征的共同学习,从而从视频中学习动态内容特征。从视频来看,MC-JEPA在各种任务中表现良好,包括光流估计以及图像和视频的分割。meta[184]提出了I-JEPA,用于学习高度语义的图像表示,而无需依赖于手动数据增强。将I-JEPA与Vision Transformers结合使用,在各种任务中产生了强大的下游性能,包括线性分类、物体计数和深度预测。meta在I-JEPA的基础上,提出V-JEPA[185]将JEPA应用于视频领域。该方法将掩码预测与JEPA架构相结合,训练了一系列以特征预测为SSL目标的V-JEPA模型。实验结果表明,这些模型在一系列CV下游任务中表现出优异的性能,包括动作识别、动作分类和目标分类。
迄今为止,以JEPA为代表的非生成式模型虽然并没有在自动驾驶领域得到直接的应用,但却存在巨大的潜力。首先,非生成世界模型不是在像素空间中预测视频,而是在潜在空间中进行特征预测。这消除了许多不相关的细节。例如,在自动驾驶的场景预测任务中,我们对当前道路上其他交通参与者的未来运动更感兴趣。此外,对于不在自动驾驶车辆当前道路上的其他车辆,例如,比如说旁边与当前道路平行的高架上的其他车辆,我们不考虑它们未来的运动轨迹。JEPA模型消除了这些不相关的细节,并降低了问题的复杂性。此外,V-JEPA已经展示了它在视频中学习特征的能力。通过分析足够多的驾驶视频,预计V-JEPA将广泛用于生成驾驶场景和预测未来环境状态等任务。
5 基于基础模型的数据增强
随着深度学习的不断发展,以预训练和微调为基础架构的FMs的性能正在提高。FMs正在引领从规则驱动的转变数据驱动的学习范式。数据作为模型学习的一个关键方面的重要性是显而易见的。大量数据被用于自动驾驶模型的训练过程,以促进模型在不同驾驶场景下的理解和决策能力。然而,现实数据的收集是一个费时费力的过程,因此数据增强对于提高自动驾驶模型的泛化能力至关重要。
数据增强的实现需要考虑两个方面:一方面,如何获取大规模数据,使反馈到自动驾驶系统的数据具有多样性和广泛性,另一方面,如何获取尽可能多的高质量数据,使用于训练和测试自动驾驶模型的数据具有准确性和可靠性,相关工作也大致选择了两个方向来增强自动驾驶数据,一是丰富现有数据集的数据内容,增强驾驶场景的数据特征,二是通过仿真生成多层次的驾驶场景。下面将对基于FMs增强数据的相关工作进行综述,在“自动驾驶数据集的扩展”部分,我们描述了扩展数据集的相关工作,在“驾驶场景的生成”部分,我们描述了生成驾驶场景的相关工作。表3简要概述了一些代表性工作。
表3 有关数据增强的工作
5.1. 扩展自动驾驶数据集
现有的自动驾驶数据集大多是通过记录传感器数据,然后对数据进行标注来获得的。这样获得的数据的特征通常是低级的,更多地存在于数字表示层面,对于自动驾驶场景的视觉空间特征表征来说是不够的。自然语言描述被视为增强场景表示的有效方式[79];Flickr30k[186]、RefCOCO[187]、RefCOCOg[188]和CLEVR-Ref[189]使用简洁的自然语言描述来确定图像中相应的视觉区域。Talk2Car[190]融合了图像、雷达和激光雷达数据,构建了第一个包含自动驾驶汽车自然语言命令的对象引用数据集。然而,Talk2Car数据集一次只允许引用一个对象。CityFlow-NL[191]通过自然语言描述构建了用于多目标跟踪的数据集,ReferKITTI[192]通过在相应任务中利用语言查询实现了对任意目标跟踪的预测。
FMs在其高级语义理解、推理和解释能力下,为丰富和扩展自动驾驶数据集提供了新思路。Qian等人[193]通过语言模型编码问题描述,并与传感器数据进行特征融合获取回答,创建了3D多视图驾驶场景下的自动驾驶视觉问答数据集NuScenes-QA,在语言提示的使用方面取得了重大进展。Wu等人[194]在NuScenes-QA的基础上进行了拓展,通过语言元素采集、组合,再调用LLM生成描述构建了数据集Nuprompt。该数据集提供更精细的匹配3D实例和每个提示,这有助于更准确地表征自动驾驶仪图像中的物体。Sima等人[115]考虑到交通要素的相互作用,通过用BLIP-2扩展nuScenes数据集[195]构建了Graph Visual Question Answering,可以更好地阐明对象之间的逻辑依赖关系和驾驶任务的层次结构。除了直接扩展增强的自主数据集,一些学者还整合了LLM的CoT能力和视觉模型的跨模态能力,构建了一个自动标注系统OpenAnnotate3D[196],可用于多模态3D数据。通过利用基础模型的高级理解、推理和解释能力来扩展数据集,有助于更好地评估自动驾驶系统的可解释性和控制性,从而提高自动驾驶系统的安全性和可靠性。一些代表性工作的比较如表4所示。
表4 扩展数据集的比较,“-"表示无法获得

5.2. 生成驾驶场景
驾驶场景的多样性对于自动驾驶来说具有相当重要的意义,自动驾驶模型要获得更好的泛化能力,必须学习种类繁多的场景。然而,现实情况是驾驶场景符合长尾分布(在其中很大一部分观察或实例集中在分布的尾部,远离中心或均值。)自动驾驶车辆的“长尾问题”是,自动驾驶车辆能够处理所经常遇到的正常场景,但面对一些罕见或极端情况下的边缘场景应对不佳或无法应对。为了解决长尾问题,关键是获得尽可能多的极端情况。尽管如此,将收集限制在真实场景中是低效的。例如,在边缘场景挖掘的工作CODA[197]中,100万数据中只有1,057个有效数据。
鉴于上述情况,大规模和高质量驾驶场景数据的生成需要主动生成大量驾驶场景的能力。传统方法可以分为两大类:基于规则的和数据驱动的。基于规则的方法[198-201]需要使用预定义的规则,不足以表征复杂环境,模拟的环境较为简单,并且表现出有限的泛化能力。相比之下,数据驱动方法[202-205]利用驾驶数据来训练模型,使其能够不断学习和适应。然而,数据驱动方法通常需要大量标记数据进行训练,阻碍了驾驶场景生成的进一步发展。此外,这种方法可控性不强,不适合自定义生成。最近,FMs取得了巨大的成功,通过FMs生成更高质量的驾驶场景也引起了重要的研究关注。一方面,基于FMs强大的理解和推理能力,可以增强数据生成的多样性和准确性。另一方面,可以设计不同的提示进行可控生成。
5.2.1.基于LLMs和VLMs
针对一些长尾场景永远无法在多视角镜头中收集的事实,Yang等人[206]融合了语言提示、BEV sketch和多视角噪声来设计一个两阶段生成网络BEVControl,用于合成逼真的街道场景图像。尽管如此,BEVControl不足以对前景和背景细节信息进行建模。为了解决获得大规模BEV表示的困难,Li等人[207]开发了一个时空一致的扩散框架DrivingDiffsion,以自回归生成由3D布局控制的逼真多视图视频。通过将本地提示输入引入视觉模型,可以有效地增强生成数据的质量。对于可控生成,Wen等人[208]集成了语言提示、图像条件和BEV序列,设计了一个可控模块,以提高驾驶场景生成的可控性。Gao等人[209]通过将文本提示与相机位姿、道路地图和对象框融合控制相结合来设计3D几何控制,以生成多样化的道路场景。
基于LLMs和VLMs强大的理解和推理能力,将其直接嵌入或引导模型生成驾驶场景也成为研究热点。Marathe等人[210]通过提示利用VLM有效地生成了包含16个极端天气的数据集。尽管如此,由于数据选择中存在预选定现象,该模型存在一些扩展约束。Chen等人[124]通过对强化学习智能体收集的控制命令和LLM生成的问题答案进行配对直接构建一个新的数据,实现了数字矢量模态与自然语言的结合。Zhong等人[211]提出了一种基于场景级扩散的语言引导交通仿真模型CTG++,可以生成符合指令的、逼真、可控的交通场景。Wang等人[75]利用自然语言描述作为概念表述与LLM集成,通过利用其强大的常识推理能力来丰富生成场景的复杂性。人类驾驶员的行为也是驾驶场景的重要组成部分,jin 等人[212]一种基于LLM的城市环境中的生成式驾驶代理模拟框架SurrealDriver,通过分析和学习真实驾驶数据,SurrealDriver可以捕捉驾驶员的行为模式和决策过程,并生成与真实驾驶中相似的行为序列。
5.2.2.基于世界模型
为了实现驾驶场景的可控性生成,Wang等人[166]结合文本提示和结构化交通约束,用文本描述来引导像素点的生成。为了获得更准确的动态信息,Wang 等人[168]将驾驶动作融入可控架构,利用文本描述、布局和自我动作来控制视频生成。然而,这些方法引入了更多的结构信息,这限制了模型的交互性。为了解决这个问题,Zhao等人[167]提出了一种将LLM与世界模型相结合的新颖方法。这种方法涉及使用LLM将用户查询转换为代理的轨迹,然后用于生成HDMap,再引导驾驶视频的生成。
利用驾驶场景的FMs可以实现高效和准确的可控性生成。这将能够为模型提供多样化的训练数据,这对于提高自动驾驶系统的泛化能力很重要。一些代表性工作的比较如表5所示。此外,生成的驾驶场景可用于评估不同的自动驾驶模型,以测试和验证其性能。当然,我们也应该能够看到,随着Sora和Genia等各种大规模FMs的出现,自动驾驶视频的生成提供了新的潜在思路。模型不限于驾驶领域,而是可以利用从通用视频领域训练中获得的模型用于迁移学习。虽然目前该领域的技术还不完善,但我们相信,未来随着相关技术的突破,我们甚至可以利用它们生成我们需要的各种驾驶场景,真正学习一个模拟世界的世界模型。
表5 nuScenes 数据集的视频生成性能,-"表示不可获得。FID 指示器和 FVD 指示器分别提供图像和视频质量的反馈。
6 结论和未来方向
本文对FMs在自动驾驶领域的应用做了较为全面的综述。在“基于语言和视觉模型的类人驾驶”部分,详细总结了LLMs和VLMs等基础模型应用于自动驾驶的最新工作。在“基于世界模型的自动驾驶预测”部分,我们展示了世界模型在自动驾驶领域的探索性应用。在“基于基础模型的数据增强”部分,详细介绍了FMs数据增强的最新工作。总体而言,FMs可以在增强数据和优化模型方面有效地辅助自动驾驶。
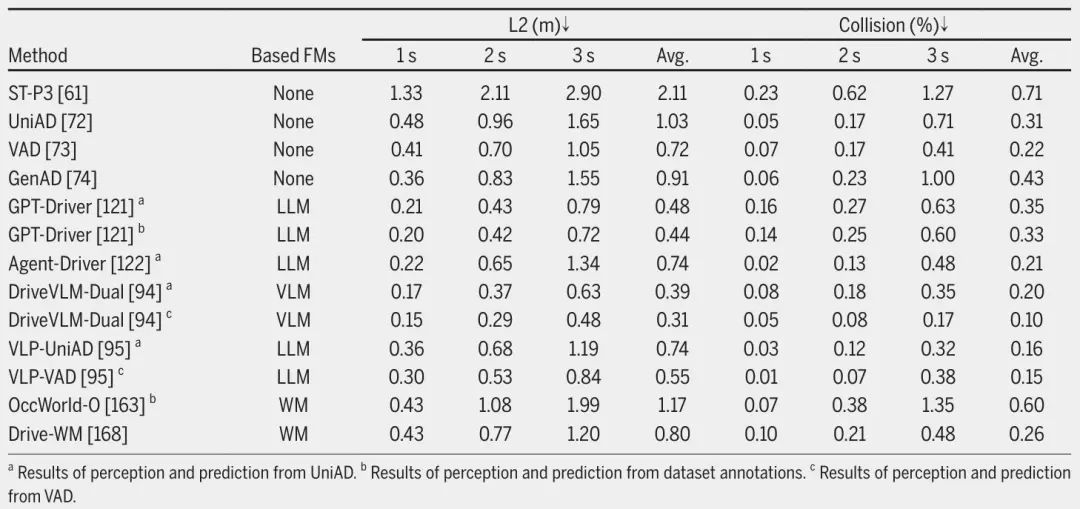
为了评估FMs在自动驾驶中的有效性,我们在表6中比较了不同的FMs和传统方法在运动规划中的有效性。由于LLM和VLM的相对成熟,可以观察到基于它们的增强自动驾驶的方法总体上得到了改进。相比之下,基于WMs的方法仍在进一步探索中,发表的工作相对较少。尽管如此,通过前面的分析,我们也可以看到世界模型擅长学习物理世界的演变规律,在增强自动驾驶方面有巨大潜力。
表6 nuScenes 验证数据集上的运动规划性能
挑战和未来方向. 尽管如此,从以前的研究中可以明显看出,基于FMs的自动驾驶技术还不够成熟。这种现象可以归因于几个因素。FMs存在幻觉问题[213,214],以及学习视频这一高维连续模式仍然存在局限性。此外,还应考虑推理延迟[215,216]引起的部署问题以及潜在的伦理影响和社会影响。
幻觉. 幻觉错误问题在自动驾驶中主要表现为的误识别,如目标检测错误,可能造成严重的安全事故。幻觉问题的产生主要是由于数据集样本有限或模型受到不平衡或噪声数据的影响,需要利用扩展数据和对抗性训练来增强稳定性和泛化能力。
实际部署. 如前所述,当前关于自动驾驶中的FM的大多数研究都是基于开源数据集实验[95,121]或仿真环境中的闭环实验[105,119],这对于实时性的考虑是不够的。此外,一些研究[215,216]强调大型模型具有一定的推理延迟,这可能会导致自动驾驶应用中的重大安全问题。为了进一步探索FM对于自动驾驶中实时应用的有效性,我们进行了一项实验[217]。我们使用低秩自适应(LoRA)[218]来微调LLaMA-7B[78],微调的LLM可以推理生成驾驶语言命令。为了验证其在驾驶场景下的实时性能,我们分别在单个GPU A800和单个GPU 3080上进行推理,生成6个tokens所需的时间分别为0.9秒和1.2秒,有效验证了FM的车端部署是可能的。同时,Tian等人的DriveVLM[94]工作也在NVIDIA Orin平台上实现了二级部署推理,进一步支持了车载FM的可行性。未来,随着边缘计算和车载计算能力的提升[219],可能会逐步走向向车端、路端和云端的混合部署模式过渡,进一步提高实时响应能力和隐私保护水平。
AI 对齐. FMs深入到包括自动驾驶在内的各个行业是一个主要趋势。尽管如此,随着相关研究的继续,人类社会面临的风险也在继续。先进AI系统表现出不良行为(例如欺骗)是一个令人担忧的原因,尤其是在自动驾驶这种直接关系到人身安全的领域领域,需要认真讨论和思考。对此,已经提出了AI Alignment并得到发展。AI Alignment的目标是使AI系统的行为与人类的意图和价值观保持一致。这种方法侧重于AI系统的目标,而不是它们的能力[220]。AI Alignment有助于先进AI系统在各个领域实施时的风险可控、操作稳健性、人类伦理性和可解释性[221],这是一个庞大的涉及众多AI相关领域的研究体系。由于本文集中在自动驾驶领域,并没有深入研究风险原因和解决方案的细节,我们在此不再进一步阐述。在自动驾驶领域,需要注意的是,在推动FMs应用的同时,研究人员必须在AI Alignment的指导下建立合理的技术伦理。这包括关注算法公平、数据隐私、系统安全和人机关系等问题。此外,促进技术发展和社会价值观的统一以避免潜在的伦理和社会风险至关重要。
视觉涌现能力. FMs随着模型的扩大出现涌现能力,并在NLP方面取得了成功。然而,在自动驾驶的背景下,由于有限的可用数据和扩展的上下文长度问题,这方面的研究面临着额外的开放性挑战。这些挑战导致对宏观驾驶场景的理解不足,从而使该领域的长期规划复杂化。驾驶视频是一种高维连续模态,数据量极大(与文本数据相比要大几个数量级)。因此,训练视觉大模型需要更宏观的场景分布,来嵌入足够的视频帧来推理复杂的动态场景,这需要更强大的网络结构和训练策略来学习这些信息。Bai等人[222]在最近的一项研究中提出了一种两阶段方法,其中图像被转换为离散的tokens以获得“视觉句子”,然后进行自回归预测,类似于LM[13]的标准方法。另一个有希望的解决方案可能在于世界模型 ,正如“基于世界模型的自动驾驶预测”部分所述,世界模型可以通过观察少量与任务相关或不相关的事件来学习世界的内在进化规律。然而,世界模型在探索性应用中也有一定的局限性,在探索性应用中,模型预测结果的不确定性,以及学习什么样的数据可以捕获世界运作的内在规律仍值得进一步探索。
综上所述,虽然将FMs应用于自动驾驶有许多挑战需要解决,但其潜力已经开始显现,未来我们将继续监测FMs应用于自动驾驶的进展。
参考文献



















责编丨高炳钊



编辑推荐




最新资讯
-
飞书项目落地ASPICE解决方案,助力汽车软件
2025-04-24 09:59
-
驾驶员监控系统DMS合规认证的“中西结合”
2025-04-24 08:23
-
自动驾驶汽车测试关键行人场景生成
2025-04-23 17:12
-
R171.01对DCAS的要求⑧
2025-04-23 17:08
-
迄今为止最先进的版本:imc发布全新imc STU
2025-04-23 17:06
