




 广告
广告





















































多模态大模型最新论文介绍

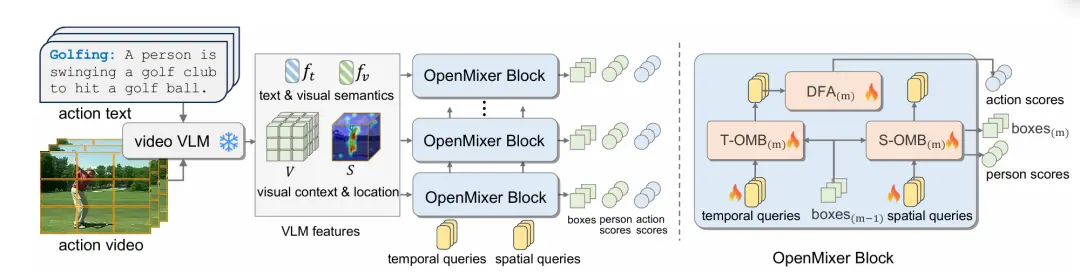
内容介绍:动作检测旨在在视频中从空间和时间上检测(识别和定位)人类动作。现有方法主要关注闭集设置,即在一个固定动作类别的视频集上训练并测试动作检测器。然而,在开放世界中,测试视频不可避免地会超出训练的动作类别,因此这种受限的设置并不可行。在本文中,我们解决了实际且具挑战性的开放词汇动作检测(OVAD)问题。该问题的目标是在使用固定动作类别集训练模型的同时,检测测试视频中的任何动作。为了实现这种开放词汇的能力,我们提出了一种新方法OpenMixer,该方法利用基于查询的检测变换器(DETR)系列中大型视觉语言模型(VLM)的固有语义和可定位性。具体而言,OpenMixer由空间和时间OpenMixer块(S-OMB和T-OMB)以及动态融合对齐(DFA)模块组成。这三个组件共同利用了预训练VLM的强大泛化能力和DETR设计的端到端学习能力。此外,我们在各种设置下建立了OVAD基准,实验结果表明,OpenMixer在检测已见和未见动作方面均优于基线方法。在https://github.com/Cogito2012/OpenMixer上发布了代码、模型和数据集划分。
本文研究了开放词汇动作检测(OVAD)问题,旨在通过固定动作类别集训练的模型检测测试视频中的任何动作。为解决此问题,提出了OpenMixer方法,该方法结合了大型视觉语言模型(VLM)的语义和可定位性,以及基于查询的检测变换器(DETR)的设计。OpenMixer由空间和时间块以及动态融合对齐模块组成,实现了强大的泛化能力和端到端学习能力。实验结果表明,OpenMixer在检测已见和未见动作方面均优于基线方法,相关代码和数据集已公开发布。
2.Large Vision-Language Models for Remote Sensing Visual Question Answering
Authors: Surasakdi Siripong, Apirak Chaiyapan, Thanakorn Phonchai
https://arxiv.org/abs/2411.10857
内容介绍:本文提出了一种新颖的远程遥感视觉问答(RSVQA)方法,该任务旨在解析复杂卫星图像以回答自然语言问题,颇具挑战性。传统方法通常依赖于独立的视觉特征提取器和语言处理模型,这不仅计算量大,而且处理开放式问题的能力有限。新方法则利用生成式大型视觉-语言模型(LVLM)来简化RSVQA流程,包含两个训练步骤:域自适应预训练和基于提示的微调。该方法使LVLM能够根据视觉和文本输入生成自然语言答案,无需预定义答案类别。在RSVQAxBEN数据集上的评估显示,该方法性能优于最先进的基线方法。此外,人工评估表明,该方法生成的答案更准确、更相关、更流畅。研究结果彰显了生成式LVLM在推动遥感分析领域发展方面的潜力。
3.VidComposition: Can MLLMs Analyze Compositions in Compiled Videos?
Authors: Yunlong Tang, Junjia Guo, Hang Hua, Susan Liang, Mingqian Feng, Xinyang Li, Rui Mao, Chao Huang, Jing Bi, Zeliang Zhang, Pooyan Fazli, Chenliang Xu
https://arxiv.org/abs/2411.10979
内容介绍:随着多模态大型语言模型(MLLMs)的发展,多模态理解能力取得了显著进步,尤其是在视频内容分析方面。然而,现有的MLLMs评估基准主要关注抽象视频理解,缺乏对视频构成理解能力的详细评估,即未能细致评估模型如何理解高度编译的视频中视觉元素的组合与交互。为此,我们推出了VidComposition这一新基准,它使用精心挑选的编译视频和电影级别的注释,专门用于评估MLLMs的视频构成理解能力。VidComposition包含982个视频和1706个多项选择题,涵盖摄像机运动、角度、镜头大小、叙事结构、角色动作和情感等多种构成方面。我们对33个开源和专有MLLMs的全面评估显示,人类与模型的能力之间存在显著差距,这凸显了当前MLLMs在理解复杂编译视频构成方面的局限性,并为进一步改进提供了方向。

4. BanglaDialecto: An End-to-End AI-Powered Regional Speech Standardization
Authors: Md. Nazmus Sadat Samin, Jawad Ibn Ahad, Tanjila Ahmed Medha, Fuad Rahman, Mohammad Ruhul Amin, Nabeel Mohammed, Shafin Rahman
https://arxiv.org/abs/2411.10879
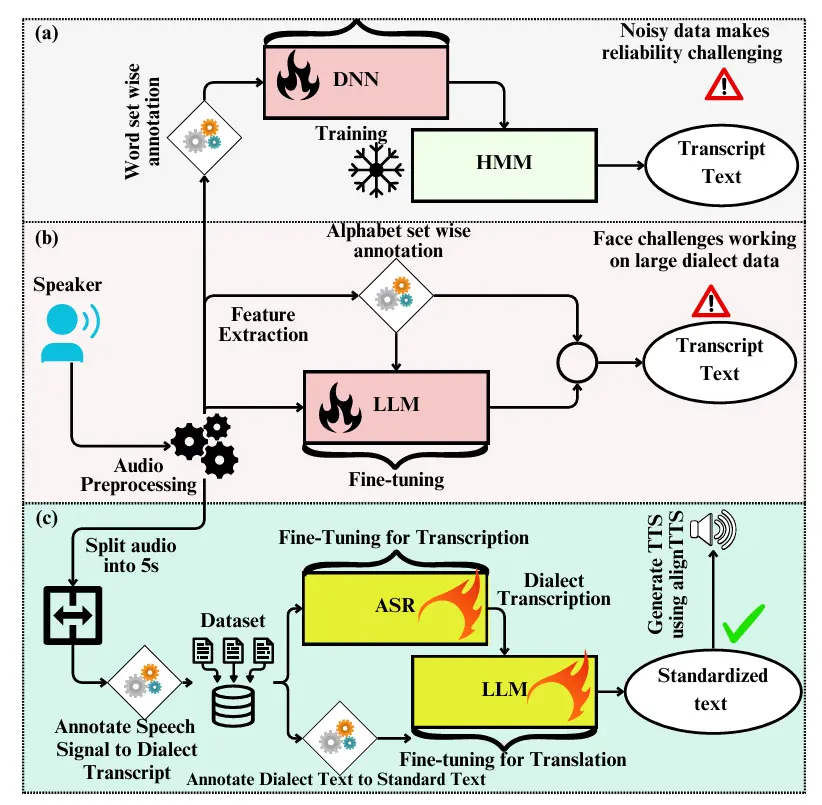
内容介绍:本研究致力于识别孟加拉国方言,并将多样化的孟加拉语口音转换为标准化的正式孟加拉语。方言,即特定地区使用的语言变体,通过语音、发音和词汇来区分,且其细微变化还受到地理位置、教育程度和社会经济地位的影响。为确保有效沟通、教育一致性、技术获取、经济机遇,并尊重文化多样性的同时保护语言资源,方言标准化至关重要。孟加拉语作为全球第五大使用人数的语言,拥有约55种方言,被1.6亿人使用,因此,解决孟加拉方言问题对于开发包容性沟通工具至关重要。然而,由于缺乏全面的数据集和处理多样方言的挑战,相关研究有限。随着多语言大型语言模型(mLLMs)的发展,解决方言自动语音识别(ASR)和机器翻译(MT)挑战的新机遇已经出现。本研究提出了一种将诺阿哈利方言语音转换为标准孟加拉语语音的端到端流程,包括构建包含方言语音信号的大规模多样化数据集,以定制ASR和mLLM中的微调过程,用于将方言语音转录为方言文本,再将方言文本翻译为标准孟加拉语文本。实验表明,微调后的Whisper ASR模型实现了0.8%的字符错误率(CER)和1.5%的词错率(WER),而BanglaT5模型在方言到标准文本的翻译中获得了41.6%的BLEU分数。我们利用AlignTTS文本到语音(TTS)模型完成了方言标准化的端到端流程。该研究为不同方言的应用奠定了基础,并为未来孟加拉方言标准化的研究开辟了道路。
5. LHRS-Bot-Nova: Improved Multimodal Large Language Model for Remote Sensing Vision-Language Interpretation
Authors: Zhenshi Li, Dilxat Muhtar, Feng Gu, Xueliang Zhang, Pengfeng Xiao, Guangjun He, Xiaoxiang Zhu
https://arxiv.org/abs/2411.09301
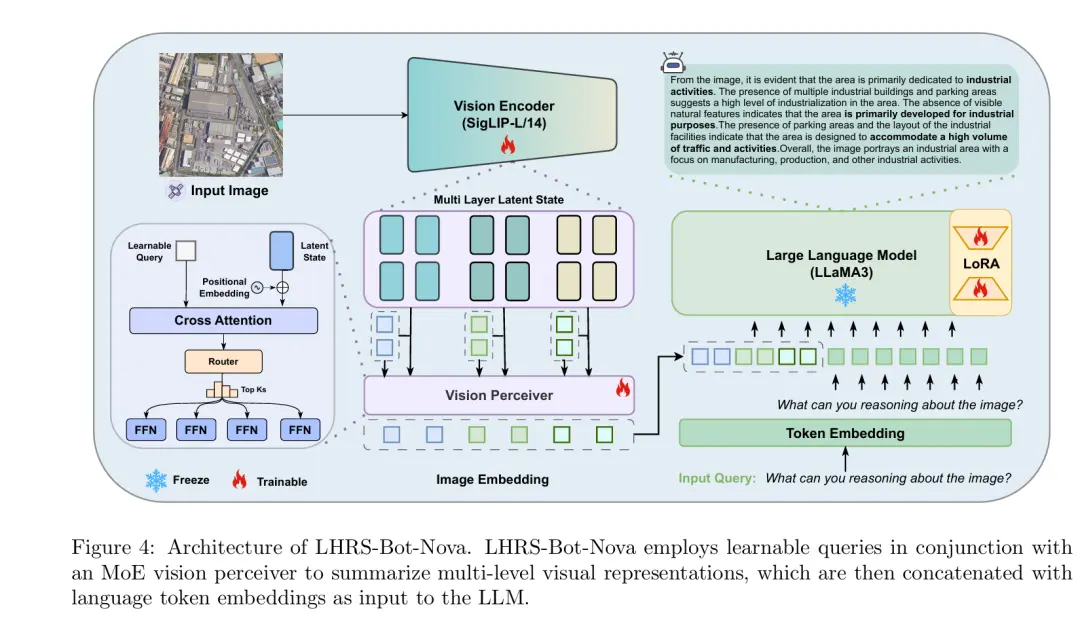
内容介绍:多模态大型语言模型(Multimodal Large Language Models, MLLMs)的出现,在提升观测系统的效率和便捷性方面展现出了巨大潜力。这些模型不仅能够参与人类般的对话,还可以作为理解和处理图像的统一平台,遵循多样化的指令并提供深入见解。本研究中,我们介绍了一款专为理解遥感(Remote Sensing, RS)图像而设计的MLLM——\MODELNAME。这款模型旨在依据人类指令出色完成一系列RS理解任务。\MODELNAME配备了增强型视觉编码器和创新性的桥接层,实现了高效的视觉信息压缩及更好的语言与视觉对齐。为了进一步加强面向RS的视觉-语言对齐,我们提出了一套大规模的RS图像-描述数据集,该数据集是通过特征引导下的图像重描述生成的。此外,我们还引入了一个特别设计用于提高空间识别能力的指令数据集。
大量的实验验证了\MODELNAME在各种RS图像理解任务中的卓越表现。我们还使用复杂的选择题评估基准来测试不同MLLM在复杂RS感知和指令执行方面的性能,为未来的模型选择和发展提供了可靠的指南。所有数据、代码和模型将在GitHub页面上公开(https://github.com/NJU-LHRS/LHRS-Bot)。
- 下一篇:端到端专题:DDPG 基础算法与方法论介绍
- 上一篇:建科股份收购苏州赛宝



编辑推荐



最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
