




 广告
广告





















































Waymo端到端自动驾驶:OpenEMMA

多模态大语言模型(MLLMs)自问世以来,在众多实际应用领域产生了重大影响,尤其是在自动驾驶(AD)方面。这些模型能够处理复杂的视觉数据,并对细致的驾驶场景进行推理,为端到端的自动驾驶系统开创了新的范式。然而,由于现有的微调方法需要大量的资源——包括强大的计算能力、大规模的数据集和大量的资金——开发端到端的自动驾驶模型进展较为缓慢。
受到最近在推理计算方面进展的启发,Texas A&M University等团队提出了OpenEMMA,这是一个基于MLLMs的开源端到端框架。通过引入链式思维(Chain-of-Thought)推理过程,OpenEMMA在利用多种不同的MLLMs时,相较于基准模型实现了显著的改进。此外,OpenEMMA在各种具有挑战性的驾驶场景中展示了其有效性、泛化能力和鲁棒性,为自动驾驶提供了一种更高效且有效的方法。
为了应对类似EMMA这样的闭源模型的局限性,我们引入了OpenEMMA——一个开源的端到端自动驾驶(AD)框架。该框架旨在使用公开可用的工具和模型来复制EMMA的核心功能,从而实现这些先进技术的民主化,为更广泛的研究和发展提供平台。
与EMMA相似,OpenEMMA以面向前方的摄像头图像和文本形式的历史自车状态作为输入。驾驶任务被构架为视觉问答(VQA)问题,通过链式思维(Chain-of-Thought)推理引导模型生成关于关键物体的详细描述、行为洞察以及元驾驶决策。这些决策由模型直接推断得出,为路径点生成提供了必要的背景信息。
针对多模态大语言模型(MLLMs)在目标检测任务上的已知局限性,OpenEMMA集成了一个特别优化用于3D边界框预测的微调版YOLO,显著提高了检测精度。此外,利用MLLMs预先存在的世界知识,OpenEMMA能够为诸如场景理解等感知任务产生可解释的、人类可读的输出,从而增强了透明度和易用性。
整个处理流程和支持的任务如图1所示。通过这种方式,OpenEMMA不仅提升了自动驾驶系统的性能,还促进了社区内的协作和创新。
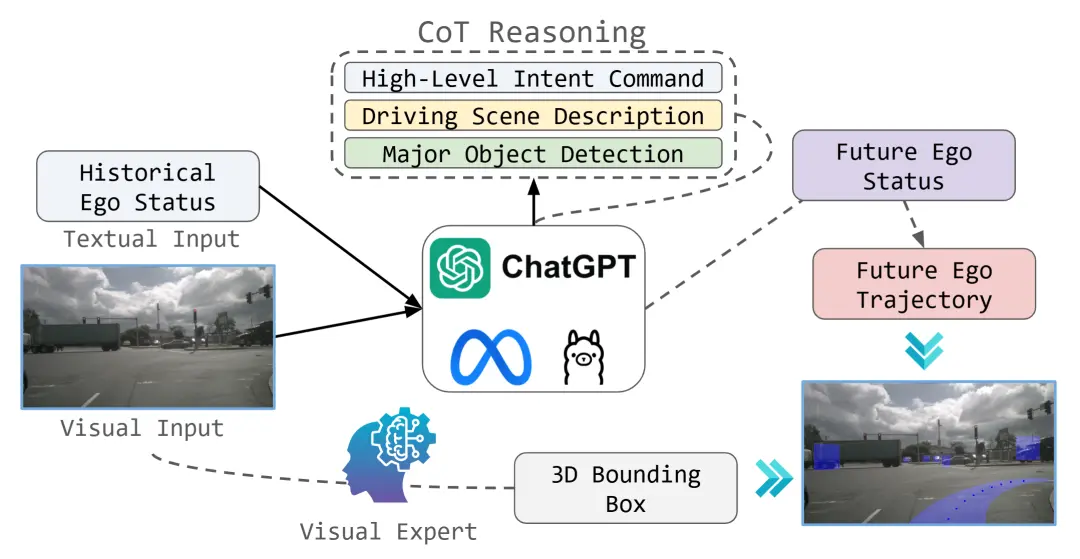
团队开发了OpenEMMA,这是一个基于预训练的多模态大语言模型(MLLMs)L的计算高效的端到端自动驾驶(AD)系统。如图1所示,OpenEMMA通过将历史驾驶状态T和视觉驾驶场景I作为输入,来预测未来的行驶轨迹P,并同时检测交通参与者。
具体来说,OpenEMMA利用了预训练的MLLMs的强大能力,这些模型已经学习了大量的世界知识和模式识别技能。在给定当前车辆周围的视觉信息(例如,来自摄像头的图像)和过去一段时间内的驾驶状态(例如,速度、方向、位置等)后,OpenEMMA能够:
1. 预测未来轨迹:根据过去的驾驶行为和当前的视觉场景,预测车辆接下来可能的行驶路径。
2. 检测交通参与者:识别并分类道路上的其他对象,如行人、自行车、其他车辆等,这对于确保安全驾驶至关重要。
3. 做出决策:使用链式思维(Chain-of-Thought)推理过程,对复杂的驾驶情况进行分析,从而为车辆提供必要的操作指导,比如加速、减速或转向。
OpenEMMA的设计旨在提高自动驾驶系统的效率和性能,同时保持较低的计算资源需求,使其更易于部署和广泛应用。此外,作为一个开源项目,它促进了社区内的协作和创新,推动了自动驾驶技术的进步。
利用预训练的多模态大语言模型(MLLMs)的强大能力,我们将链式思维(Chain-of-Thought)推理过程整合到端到端的轨迹规划过程中,采用与基于指令的方法。由于MLLMs是用人类可解释的知识进行训练的,我们促使这些模型生成同样具有人类可解释性的知识。
不同于以往直接在局部坐标中生成轨迹的预测方法,我们生成了两个中间表示:速度向量和曲率向量。其中:
速度向量表示车辆速度的大小,反映了驾驶者应踩油门的程度。
曲率向量表示车辆的转向率,对应于驾驶者转动方向盘的角度。
这种设计旨在反映人类驾驶行为的本质:速度决定了油门的力度,而曲率则决定了方向盘的转动程度。通过这种方式,OpenEMMA不仅能够提供更贴近人类驾驶习惯的决策,还能确保其输出易于理解和解释,从而提高了系统的透明度和可信度。此外,这种方法有助于增强自动驾驶系统的安全性和可靠性,因为它使系统的行为更加直观,便于人类驾驶员理解和信任。具体公式如下图所示:

这种方法通过将轨迹生成任务分解为人类可解释的组件,提供了一个稳健且易于理解的规划路径,模拟了驾驶过程。具体分为以下几个阶段:
阶段1:推理
在第一阶段,我们利用驾驶场景的前置摄像头图像以及自车过去5秒的历史数据(包括速度和曲率)作为输入到预训练的多模态大语言模型(MLLMs)。随后,我们设计特定任务的提示来引导MLLMs对当前自车驾驶场景进行全面推理,具体来说,推理过程涵盖以下三个方面:
1. 意图指令 (Intent Command)
明确表达 自车基于当前场景的预期动作,例如:
继续沿车道行驶、左转、右转或直行。
是否应保持当前速度、减速或加速。
这些意图指令为后续轨迹规划提供了清晰的方向,并确保了驾驶决策的一致性和安全性。
2. 场景描述 (Scene Description)
简洁描述当前驾驶场景,根据交通信号灯状态、其他车辆或行人的动态以及车道标记进行说明。例如:
“前方红灯亮起,左右两侧无车辆,行人正在通过右侧人行横道。”
“前方绿灯通行,左侧车辆准备并入本车道。”
这有助于系统全面理解当前环境,为准确的驾驶决策提供依据。
3. 主要对象 (Major Objects)
识别道路使用者,即自车驾驶员应注意的对象,明确他们在驾驶场景图像中的位置。对于每个道路使用者,提供简短描述其当前行为,并解释其存在对自车决策过程的重要性。例如:
行人:“位于右侧人行横道上,正向左穿越马路。重要性:需要减速以确保行人安全通过。”
车辆:左侧一辆轿车正在加速准备并入本车道。重要性:需注意避让,可能需要调整速度或车道。”
通过这种方式,OpenEMMA不仅能够生成详细的驾驶意图和场景描述,还能识别关键的道路使用者及其行为,从而为自动驾驶系统提供更加精准和安全的决策支持。这种方法模仿了人类驾驶员的思考过程,提高了系统的透明度和可解释性,增强了其应对复杂驾驶情境的能力。
阶段2:预测
通过结合链式思维(Chain-of-Thought)推理过程和自车的历史状态,促使多模态大语言模型(MLLMs)生成未来 T 秒内的速度 S和曲率 C(共 2T 个轨迹点),这些预测随后被整合以计算最终的轨迹 T。
2.2 视觉专家增强的目标检测
在自动驾驶(AD)中,一个关键任务是检测道路上物体的3D边界框。我们发现,现成的预训练多模态大语言模型(MLLMs)由于空间推理能力的限制,难以提供高质量的检测结果。为了克服这一挑战,在不额外微调MLLM的情况下实现高精度的检测,我们将一个外部的视觉专业模型集成到OpenEMMA中,有效解决了检测任务。
我们的OpenEMMA专注于使用前置摄像头进行目标检测,并处理单帧数据,而不是连续帧序列。这将任务置于单目相机基于的3D目标检测范围内。该领域的研究一般分为两类:深度辅助方法[27–29]和仅图像方法[30–33]。深度辅助方法通过预测深度信息来辅助检测,而仅图像方法则完全依赖RGB数据进行直接预测。在这些方法中,我们选择了YOLO3D[30],因为它结合了可靠的准确性、高质量的开源实现以及轻量级架构,使得高效微调和实际集成成为可能。
YOLO3D 方法概述
YOLO3D 是一种两阶段的3D目标检测方法,它强制执行2D-3D边界框一致性约束。具体来说,它假设每个3D边界框紧密包含在其对应的2D边界框内。该方法首先预测2D边界框,然后估计每个检测到物体的3D尺寸和局部方向。3D边界框的七个参数——中心位置、尺寸和偏航角 ——根据2D边界框和3D估计联合计算得出。
这种方法不仅提高了目标检测的准确性和鲁棒性,还确保了系统能够快速适应新的驾驶环境,从而增强了OpenEMMA的整体性能和可靠性。
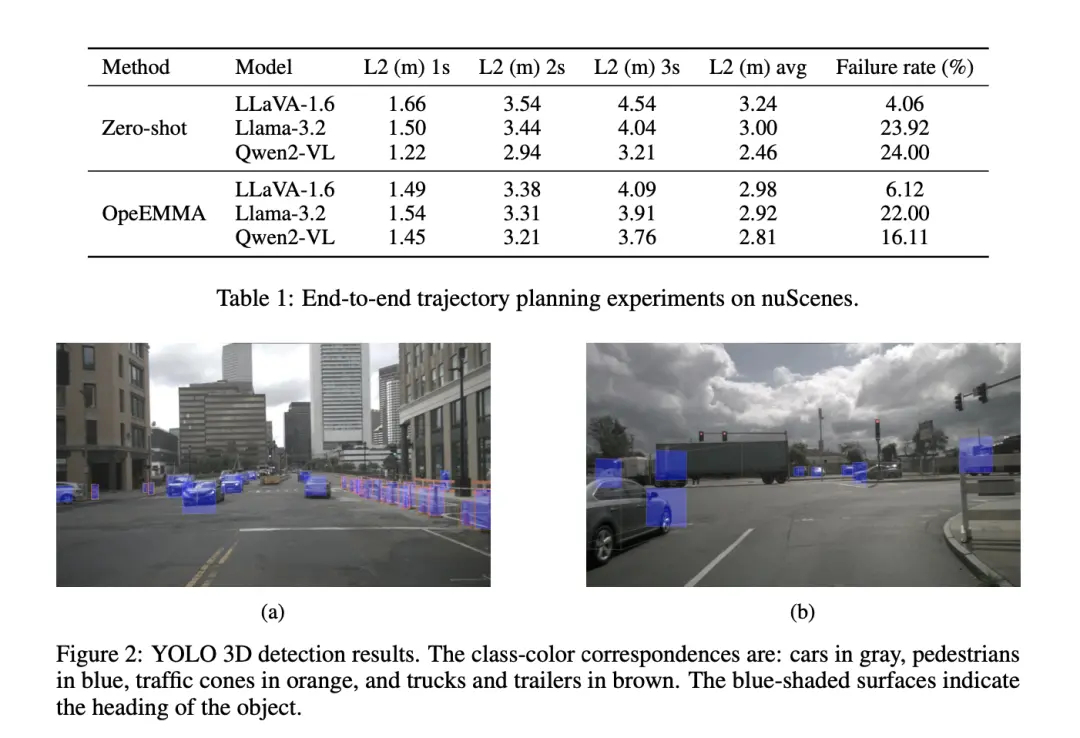
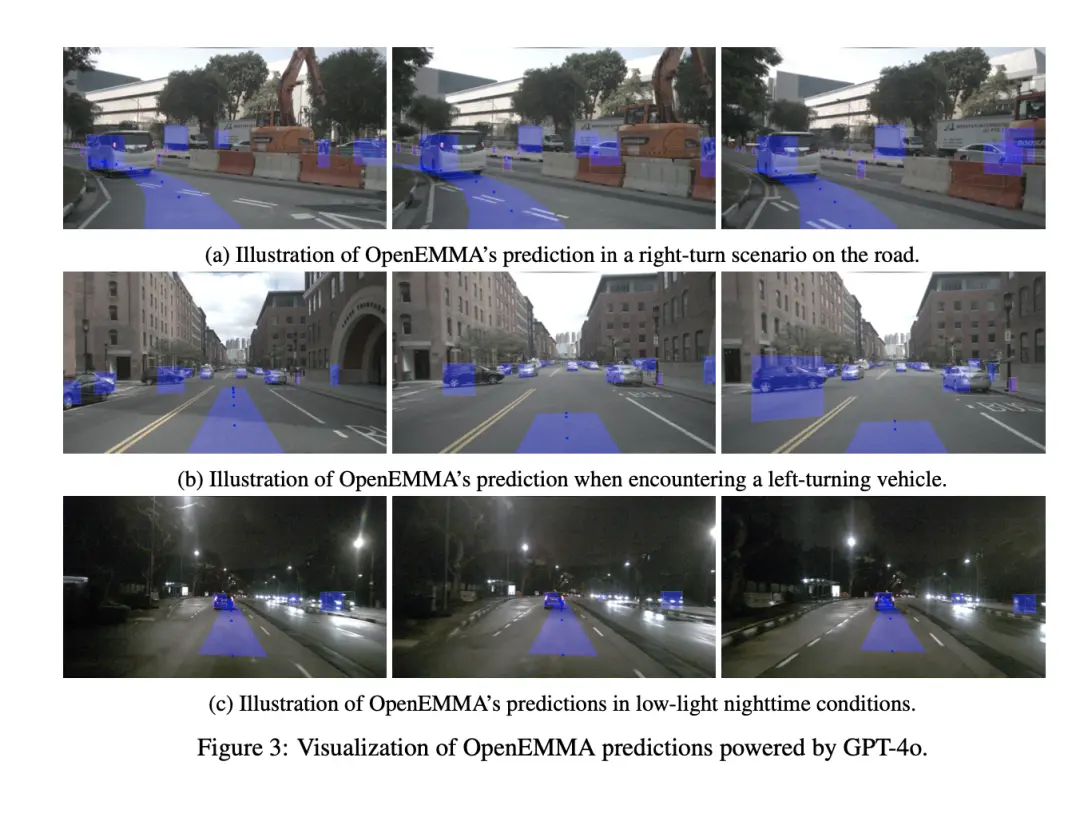
在本文中,我们提出了OpenEMMA——一个基于多模态大语言模型(MLLMs)构建的开源、计算高效的端到端自动驾驶框架。通过利用自车的历史数据和前置摄像头捕捉的图像,OpenEMMA采用链式思维(Chain-of-Thought)推理过程来预测自车未来的速度和曲率,并将这些预测整合到轨迹规划过程中。
此外,通过集成一个微调后的外部视觉专业模型,OpenEMMA实现了对道路上3D物体的精确检测。该框架不仅展示了相对于零样本基线模型的显著改进,还证明了其在各种具有挑战性的驾驶场景中的有效性、泛化能力和鲁棒性。OpenEMMA的关键特点包括:
高效推理:结合历史驾驶数据和实时视觉输入,使用链式思维推理生成未来行驶参数。
精准检测:通过集成专门优化的视觉模型,提高了3D物体检测的精度。
性能提升:相较于零样本基线模型,OpenEMMA在多个关键指标上表现出显著进步。
广泛应用:适用于多种复杂驾驶环境,展现了强大的适应性和可靠性。
总之,OpenEMMA为自动驾驶技术提供了一种创新且高效的方法,推动了该领域的进一步发展。



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
