




 广告
广告





















































详解智能座舱芯片算力评估

为了用硬件实现这种乘加的计算关系,谷歌 TPU(张量处理单元,NPU 的一种)给出的 系统架构框图如图 5 所示。
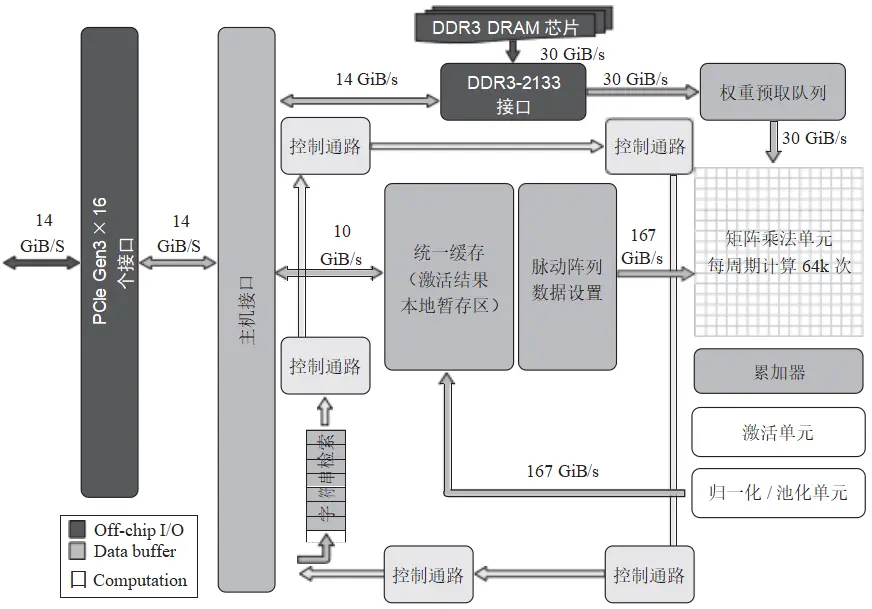
图 5 谷歌第 1 代 TPU 架构框图
从图 5 中,我们可以看到谷歌的 TPU 设计思路。
TPU 指令通过 PCIe 接口从主机(CPU)发送至 TPU 的指令缓冲区。同时,NPU 会从主存储器中读取已训练好的权重参数,并将这些数据送往矩阵乘法单元进行乘法运算。由于运算量庞大,此处的数据带宽高达 30GB/s ,以满足高速数据传输的需求。
矩阵乘法单元是 TPU 的核心组件,它包含 256×256 个乘加单元,能够对 8 位整型数进行乘加运算。每次乘加运算的结果会暂存于矩阵单元下方的累加器(Accumulator)中。 这个矩阵乘法单元的运算能力非常强大,每个周期可以输出多达 64000 个计算结果。
累加器负责处理加法运算的结果。这些结果在经过激活函数处理后,会被传输到归一化 / 池化单元进行进一步处理,并最终存储在统一缓存中。如果需要,这些中间结果还会通过脉动阵列再次进入矩阵乘法单元,参与下一轮的运算。
最终的计算结果会通过 PCIe 接口传送回主机,从而完成整个计算过程。这种高效的数据处理和传输机制使得 TPU 在处理大规模矩阵运算时具有出色的性能表现。
2. NPU 特性需求
因此,一个典型的 NPU,如果需要支持 CNN 和 RNN ,应该具备以下特点。
硬件架构:NPU 的硬件架构必须高效且灵活,能够同时满足 CNN 和 RNN 的计算需求。这意味着它不仅要支持卷积运算、池化运算、激活函数等 CNN 常用的操作,还要能够处理 RNN 特有的长序列记忆和时间维度信息传递。
流管理:为了有效处理图像和文本等多种类型的数据流,NPU 需要具备先进的数据流管理能力。这包括高效的内存管理和数据调度策略,以确保各种类型的数据能顺畅地进行计算和传输。优化后的数据流管理不仅能提升处理速度,还能降低功耗和延迟。
并行计算能力:为了应对复杂的计算任务,NPU 需要具备强大的并行计算能力。这包括支持多线程、多核心的计算方式,以便同时处理多个计算任务,从而提高整体计算效率。通过并行计算,NPU 能更快速地完成大规模数据处理和分析任务。
混合精度计算:在保证计算精度的前提下,为了提高计算效率,NPU 应采用混合精度计算技术。这意味着在某些场景下,可以使用低精度的整数运算来加速计算过程,而在需要高精度的场合则使用浮点运算。这种灵活的计算方式能在保持精度的同时,最大限度地提高计算速度。
数据类型优化:为了进一步提升计算效率,NPU 还应采用数据类型优化策略。例如, 可以使用定点数代替浮点数进行计算,或者使用较低精度的数据类型来替代高精度数据类型。这些优化措施能有效减少计算时间和功耗,使 NPU 在处理各种任务时更加高效和节能。
NPU 中与并行计算紧密相关的核心组件是计算单元。这些计算单元专门负责执行神经网络的各类计算任务,如卷积、激活函数处理、池化等关键操作。计算单元通常由多个 PE (Processing Element,处理单元)构成,每个 PE 都独立负责处理一部分计算任务,从而实现任务的并行处理。
在 NPU 的架构中,PE 被视为最基本的计算单元。每个 PE 能够完成单个神经元或神经元小组的计算操作,这种设计有助于提高计算的并行性和效率。为了协调各个 PE 之间的工作,它们之间通过互联网络( Interconnect Network)进行高效的数据传输和协作。这种网络确保了数据能够在不同的 PE 之间快速流动,从而支持复杂的神经网络计算任务的完成。
由于 PE 在 NPU 中扮演着至关重要的角色,其性能和数量直接决定了 NPU 的整体计算能力和处理效率。换句话说,一个具备高性能计算单元的 NPU 将能够更快速地处理神经网络任务,提升整体的系统性能。
4.2 NPU 性能评估标准
在许多 NPU 的设计实现中,PE 经常被称为 MAC(即乘加单元)。因为神经网络的基本计算过程涉及权重与输入的乘积以及这些乘积结果的累加。具体来说,每个神经元的输出是其 输入与相应权重的乘积之和,再加上一个偏置项,最后可能还会经过一个激活函数。在这个过程中,乘法和加法是两种最基本的数学运算。
NPU 的算力单位被称为TOPS(TeraOperationsPerSecond),它表示每秒可以执行的万亿次操作,是衡量NPU性能的重要指标。由于NPU的计算单元采用并行计算的方式,理论上来说,我们只需要使用乘加单元的数目,再与NPU的时钟频率相乘,就可以得到单位时间内的操作次数,也就计算出了TOPS的值。
在评估 TOPS 时,还需要考虑操作类型和操作精度。
操作类型:在神经网络计算中,常见的操作包括矩阵乘法、加法、激活函数等。这些操作在计算复杂度和资源需求上有所不同。例如,矩阵乘法可能涉及大量的乘法和加 法操作,而激活函数主要是比较和逻辑操作。
操作精度:操作精度对计算资源和时间的影响也很大。整型(如 Int8 、Int16 )和浮点型(如 FP32 、FP16)数据在计算速度、内存占用和精度方面各有优劣。 一般来说,较低精度的数据类型计算速度更快,但可能牺牲一定的准确性。
现在,我们以谷歌的 TPU 芯片为例,尝试计算它的算力标准。
1 )在谷歌 TPU 的矩阵乘法单元中,含有 256×256 个乘加单元,因此它有 64000 个 MAC 单元。
2)每个 MAC 单元在一个周期内将完成 1 次乘法和 1 次加法运算,计为 2 次操作。
3 )假设谷歌 TPU 的执行时钟频率为 1GHz,那么每秒的计算次数是 2 ×64000 × 1GHz。 要转换为 TOPS,还需要将这个数值转换为“万亿”,因此,需要除以1012。
4)在执行精度上,假设推理模型按 INT8( 8 位整型)类型的精度来计算,刚好与 TPU 的 矩阵乘法单元精度相同,因此 TPU 的算力公式为:
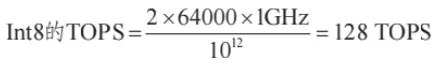
5)如果推理模型按 FP16( 16 位浮点数)类型的精度来计算,由于每个 MAC 单元能处理的数据量从 8bit 改为 16bit,因此需要 2 个 MAC 才能执行 1 次计算,总计算次数将减少一半。TPU 的算力公式为:
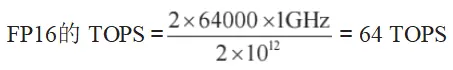
#05主存储器性评估
在 SoC 的性能评估中,存储器性能是一个至关重要的环节。在基于冯 ·诺伊曼架构的计算机体系中,所有的指令和数据都存储在存储器中,因此存储器的访问速度对计算机整体性能有着显著影响。举例来说,根据 CPU 的五级流水线体系,CPU 首先需要从存储器中取指令,然后取数据,最后将计算结果写回存储器。如果存储器的访问速度过慢,CPU 流水线中的指令周期将不得不与存储器的访问速度相匹配,这会大大降低计算机的整体性能。这就像水桶理论所揭示的道理一样,水桶的容量取决于最短的那块木板,而存储器的性能往往就是影响 SoC 整体性能的“短板”。因此,在 SoC 设计和性能评估中,必须充分重视存储器的性能优化。
5.1 主存储器架构原理
计算机中存储器的设计问题可以归纳为三个主要方面:容量、速度和价格。程序员往往期望存储器具有大容量、高速度和低成本,然而,实际上这三个要素往往是相互矛盾的,难以实现完美的平衡。这 3 个要素之间的关系可描述为:
存取时间越短,则平均每位的存储单元对应的存储器成本越大。
存储容量越大,平均每位对应的存储器成本越小。
存储容量越大,存取时间就越长。
现代计算机系统通常采用层次化的存储结构(如缓存、主存、辅存等),以便在不同层次上平衡容量、速度和成本。这种层次化的设计允许系统在保持足够性能的同时,也能提供足够大的存储容量。
1. 存储器层次结构
根据计算机系统结构原理,智能座舱 SoC 的架构体系中有可能使用到的存储器类型如表8 所示。
表8 座舱 SoC 所使用的存储器类型



编辑推荐




最新资讯
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
