




 广告
广告





















































自动驾驶中基于深度学习的雷达与视觉融合用于三维物体检测的综述

表二 当前配备摄像头和雷达装置的驾驶数据集
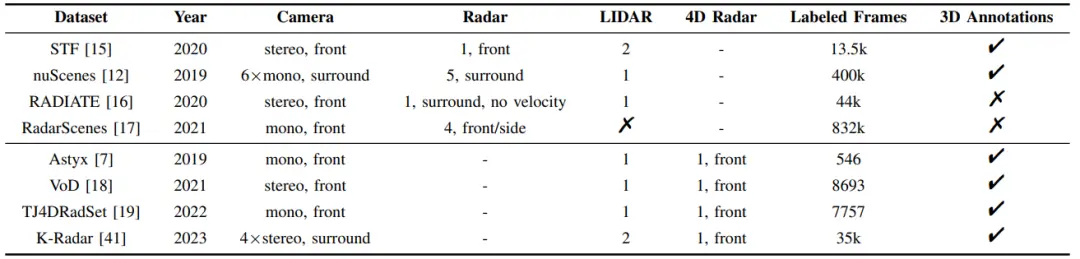
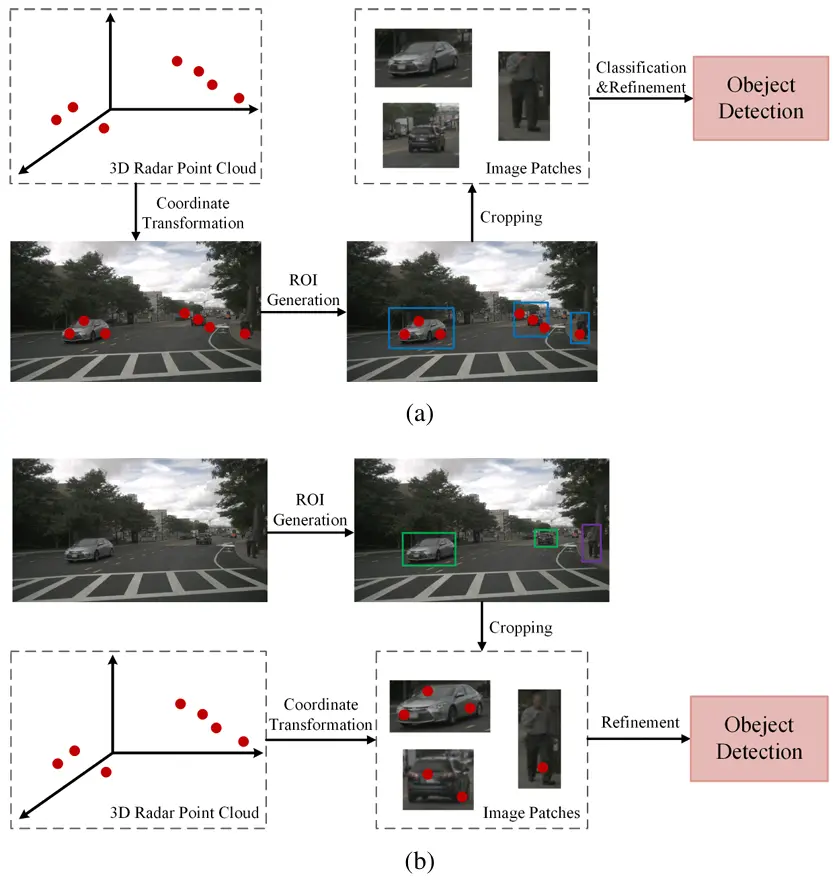
图 3.基于投资回报率的雷达视觉融合框架((a):雷达生成的感兴趣区域;(b): 视觉生成的感兴趣区域)
B. 端到端融合
端到端融合策略同时处理来自摄像头和雷达的数据。通过在一个统一的框架内整合两种模态的特征,并利用它们的互补优势,感知性能变得更加稳健。这种方法是目前最突出的融合管道之一。端到端RV融合的基本框架如图4所示。我们进一步将这种方法分为两个部分:基于 3D包围框预测和基于鸟瞰图(BEV)。
a) 基于 3D 边界框预测:得益于成熟的现代 2D 检测技术的发展,许多自动驾驶融合框架直接纳入单独的输入分支,用于将雷达数据处理到先进的 2D 检测网络 中,并在网络中间融合雷达特征与图像特征。例如,[34] 为 SSD 检测框架添加了用于雷达输入数据的额外分支, 而[13]和[35]基于 YOLO 系列网络扩展了输入通道,以同时提取图像和雷达特征。CRF-Net [36]采用 VGG16 作为模型骨干,利用辅助分支提取雷达特征在不同级别上。毫无疑问,实现3D物体检测任务的最简单方法是移植现有的成熟2D计算机视觉框架,并将其移植到3D检测头上,这在实践中确实如此。在3D物体检测发展的早期阶段,研究人员专注于利用各种卷积神经网络(CNNs)同时从图像和雷达数据中提取特征。然而,与 2D物体检测不同,3D物体检测模型需要在三维空间中回归3D包围框,包括长度、宽度和高度信息。在[37]中,使用3D区域提议网络基于相机图像和雷达图像生成提议。GRIF Net[3]预先定义了不同高度和大小的3D锚点框,并将它们投影到相机透视视图和雷达鸟瞰视图上。然后,它利用3D区域提议网络(RPN)生成3D提议。然而,这两 种方法并没有有效地利用相机特征和雷达特征之间的相关性。它们只是直接从两个传感器的特征和连接融合特征中学习3D包围框的参数。最近,注意力机制的引入进一步提高了计算机视觉模型的性能。为了解决雷达和相机特征之间的几何对应关系的不确定性,作者在[47]中提出了一 种光线约束的交叉注意力机制,以更好地利用雷达距离测量来改善相机深度预测。SparseFusion3D [48]基于 DETR3D [49]的架构,通过使用雷达点初始化对象查询,并将从对象查询解码出的3D参考点投影到图像空间以提取图像特征。总体而言,基于3D框预测的方法从2D目标检测网络中的许多优秀思想中汲取了灵感。然而,预测3D框需要估计与三维空间密切相关的更多参数,这往往 需要更多的计算资源和更复杂的算法。
图 4. 一般端到端的 RV 融合框架
b) 基于鸟瞰视图(BEV)的:最近,由于其能够提供全景和无遮挡的感知视角,鸟瞰视图感知方案在三维物体检测中逐渐占据主导地位。基于鸟瞰视图的方法将物体检测简化为从顶向下的二维图像操作,使得能够利用计算机视觉领域的丰富技术和算法,同时也提高了计算效率 。许多研究考虑利用具有强大深度感知的雷达检测来协助将图像特征从透视视图转换为鸟瞰视图。在[39]中,作者利用预测的深度分布将图像特征提升到三维空间,并利用雷达深度先验和雷达鸟瞰视图占用率引导的雷达鸟瞰视图占用率沿着高度通道将它们与图像鸟瞰视图特征连接起来。 然后,通过一个可变形交叉注意力模块,他们自适应地融合图像鸟瞰视图特征和雷达鸟瞰视图特征,以处理嘈杂和模糊的雷达点。这项工作利用雷达的深度感知优势来补充单目深度估计网络。然而,它依赖于两个并行且独立的视 图变换,这不可避免地导致来自两种模态的 BEV 特征在 空间上不一致。RCM-Fusin [38]采用 BEVFormer [14]作为 基准,并通过可变形自注意力机制[51]从雷达 BEV 特征 图中提取雷达位置信息创建了一个优化的 BEV 查询,从而整合了来自两种模态的特征以实现隐式视图变换。在 [50]中,作者使用交叉注意力将柱状特征与来自雷达点云的稀疏深度编码与相应的深度缺失图像列相关联,以在透视视图中生成统一的几何感知特征。然后,他们使用从雷达 BEV 特征计算出的雷达加权深度一致性来细化初始的 BEV 查询,解决了特征不一致或关联的问题。这些方法中的关键挑战在于如何利用雷达点的深度信息来改进透视视图特征中对深度的感知,以及如何处理图像和雷达 BEV 特征之间的空间不一致性。HVDetFusion [40]是一个 两阶段检测框架。在第一阶段,它利用估计的深度将图像特征从二维空间转换到三维空间。然后,它使用第一个检测头获得初步检测结果,并将其作为先验信息来优化初始 雷达数据中的误检。随后,它将雷达检测与图像检测相结合,并利用第二个检测头输出融合检测结果。这是目前在 nuScenes 排行榜上雷达-摄像头融合三维目标检测的最先进方法。
Ⅳ 4D雷达在自动驾驶系统中的应用
随着雷达技术的进步,4D 雷达解决了传统雷达在缺乏高度信息方面的不足,这引起了研究人员的关注,并逐渐探索如何在自动驾驶汽车中应用它。在[18]中,作者将 之前用于激光雷达三维数据的点柱应用于四维雷达数据, 以进行多类道路使用者检测。MVFAN [42]是一个用于三 维物体检测的端到端和单阶段框架,利用雷达特征辅助骨干网络来充分挖掘有价值的四维雷达数据。RCFusion [43] 在统一的 BEV 空间下实现了摄像头和四维雷达特征的融合,引入了一个雷达柱状网络来生成雷达伪图像。然后, 使用名为 IAM 的融合模块自适应地融合这两种 BEV 特征类型。此外 在目标检测方面,也有利用4D雷达进行其他自动驾驶任务的研究。CenterRadarNet[44]是一个使用4D雷达的联合3D目标检测和跟踪框架,包括一个单阶段3D目标检测器和在线重识别(re-ID)跟踪器。4DRVO-Net[45] 是一种将摄像头和4D雷达信息集成起来的4D雷达视觉里程计方法。它涉及设计一个自适应4D雷达-摄像头融合模块(A-RCFM),该模块根据4D雷达点特征自动选择图像特征。[46]中提出的方法将图像和4D雷达点云融合用于度量密集深度估计。总之,4D雷达点云作为 一种比传统3D雷达更稳健的传感器数据,具有更高的密度和与LiDAR相比的额外多普勒信息,值得进一步探索。然而,与3D雷达类似,4D雷达点云仍然相对稀疏。建立4D雷达点云和图像之间的准确关联和特征交互仍然是一个重大挑战。
Ⅴ 未来趋势
通过本文的回顾与分析,我们认为在自动驾驶的背景下,房车的融合感知具有以下发展趋势:
a) 端到端自主驾驶:端到端自主驾驶直接将原始传 感器数据作为输入,并将感知、路径规划、控制和决策等任务集成到单个神经网络中进行学习。它直接输出控制车辆行为所需的指令,而无需手动设计复杂的中间表示或处理步骤。这项技术消除了传统自主驾驶系统中的复杂模块结构,简化了系统的设计和实现过程。此外,由于它能够自动发现传感器数据中的复杂模式和特征,它能够更好地理解环境并做出更准确的决策。
b) 4D雷达的应用:随着4D毫米波雷达技术的进步, 它正朝着更高的分辨率和更远的探测范围发展。由于其成本优势,未来它可能会在一些大规模生产的智能汽车中取代传统的雷达和激光雷达。这带来了4D雷达和视觉之间更简洁和高效的融合解决方案的需求。研究中的挑战和趋势包括如何深度整合两种异构多模态数据源,以及如何在保持精度的前提下提高感知系统 的实时性能。
c) 协同感知:协同感知是指多个自动驾驶车辆交换信息并合作,共同感知周围环境并做出决策的过程。这一创新感知概念使路上的车辆能够实现实时和全面的环境感知。它不仅提高了自动驾驶系统的安全性和可靠性,还优化了整个交通系统的效率,与智能交通发展的要求无缝对接。
Ⅵ 结论
感知作为自动驾驶系统中的三个关键模块之一,在处理来自多个传感器的信息以及提取其他两个模块 (控制和决策)所需的相关环境数据方面发挥着至关 重要的作用。作为量产车辆中最常见的低成本传感器, 摄像头和雷达具有丰富的语义信息和全天候运行特性,它们的互补优势可以实现相对理想的感知性能。在本文中,我们首先分析了几种传感器的优缺点,然后介绍了现有的公开数据集,这些数据集同时包含了雷达和摄像头,包括最新的4D雷达数据集。然后我们详细回顾了基于RV融合的3D目标检测的现状。基于深度学习的3D目标检测技术分为两种策略:基于ROI和端到端。为了跟上最新的技术,我们介绍了4D雷达在自动驾驶行业中的最新应用。最后,我们分析了自动驾驶 RV融合感知发展的可能趋势,以供读者参考。






最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
