




 广告
广告





















































鱼眼相机在自动驾驶环境感知的应用和挑战

A. 数据集
构建汽车领域的数据集成本高昂且耗时 [156],目前这是鱼眼感知研究进展的主要瓶颈。在表 II 中,我们总结了已发布的鱼眼相机数据集。“木景”(WoodScape)是一个利用四个鱼眼相机围绕本车进行 360 度感知的综合性数据集。它旨在对当前仅提供窄视场角图像的汽车数据集进行补充。其中,“KITTI”[157] 是一个具有不同类型任务的开创性数据集。它是首个全面的鱼眼汽车数据集,能够详细评估诸如鱼眼图像分割、目标检测以及运动分割等计算机视觉算法 [158]。环视数据集 “木景” 的合成变体是 “合成木景”(SynWoodScape)[139]。它弥补并扩展了 “木景” 的许多不足之处。“木景” 的作者们无法收集像素级光流和深度的真实标注信息,因为无法同时使用四个相机对不同帧进行采样。这意味着在 “合成木景” 中可以设想的多相机算法无法在 “木景” 中实现。
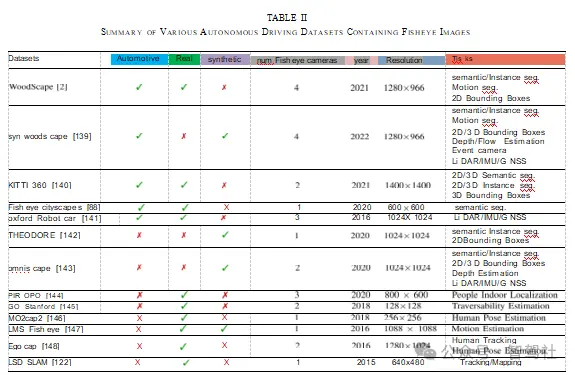
它包含来自合成数据集的 8 万张带有标注的图像。
“KITTI 360°” 是一个郊区数据集,具有更广泛的输入模态、大量的语义实例标注以及精确的定位信息,有助于视觉、计算和机器人领域的研究。与 “木景”(WoodScape)相比,“KITTI 360°” 的不同之处在于它提供了时间上连贯的语义实例标注、三维激光扫描以及用于透视图像和全向图像推理的三维标注。“鱼眼城市景观”(FisheyeCityScapes)[88] 提出了一种 7 自由度扩展,这是一种虚拟鱼眼数据增强方法。该方法利用径向畸变模型将直线数据集转换为鱼眼数据集,它合成了由处于不同方向、位置和焦距值的相机所拍摄的鱼眼图像,极大地提高了鱼眼语义分割的泛化性能。“牛津机器人汽车”(Oxford RobotCar)[141] 是一个大规模数据集,侧重于自动驾驶车辆的长期自主性。定位和地图构建是该数据集的主要任务,它使得针对自动驾驶车辆和移动机器人的持续学习研究成为可能。
“西奥多”(THEODORE)[142] 是一个用于室内场景的大型非汽车合成数据集,包含 10 万张高分辨率、16 类不同的俯视鱼眼图像。为了创建该数据集,他们构建了一个包含客厅、各种人物角色以及室内纹理的三维虚拟环境。除了记录来自虚拟环境的鱼眼图像外,作者们还为语义分割、实例掩码以及用于目标检测的边界框构建了标注信息。“全景观”(OmniScape)数据集包含安装在摩托车上的两个前置鱼眼图像和折反射立体 RGB 图像,同时还记录了语义分割、深度序列以及通过速度、角速度、加速度和方向体现的车辆动力学信息。它还包含超过 1 万帧由《侠盗猎车手 5》(GTA V)和《卡拉》(CARLA)记录的数据,这些数据也可扩展到其他模拟器中。在 “皮罗波”(PIROPO)(使用透视和全向相机拍摄的室内人员)项目中,利用全向相机和透视相机在两个不同房间里记录了图像序列。这些序列展示了处于不同状态(如行走、站立和坐着)的人员情况。其真实标注信息是以点为基础的,并且同时提供了有标注和无标注的序列(场景中的每个人都由其头部中心的一个点来表示),总共可获取超过 10 万张有标注的图像帧。
“斯坦福行走”(Go Stanford)[145] 数据集包含来自 25 个以上室内环境的大约 24 小时的视频。该实验侧重于利用鱼眼图像对室内可通行性进行估计。“Mo2Cap2”[146] 数据集用于在各种不受约束的日常活动中估计以自身为中心的人体三维姿态。该数据集旨在解决在现实世界无约束场景下进行诸如行走、骑自行车、做饭、体育运动以及办公室工作等各种活动时的移动三维姿态估计难题。体育运动、动画制作、医疗保健动作识别、运动控制以及性能分析等领域都能从这些三维姿态中受益。“LMS 鱼眼”(LMS Fisheye)[147] 数据集旨在为研究人员提供视频序列,以便开发和测试为鱼眼相机开发的运动估计算法,它同时提供了由布兰德(Blender)生成的合成序列以及由鱼眼相机记录的实际序列。
“自我捕捉”(EgoCap)[148] 是一个无标记、以自身为中心的实时动作捕捉数据集,用于通过安装在头盔上的轻型立体对鱼眼相机进行全身骨骼姿态估计。
或是虚拟现实头戴设备 —— 光学内入法。“LSD - SLAM”[122] 数据集源自一种新的实时单目同时定位与地图构建(SLAM)方法。它是完全直接的(即,它不使用关键点 / 特征),并且能够在笔记本电脑上实时创建大规模的半稠密地图。研究人员可以使用这个数据集来开展跟踪(直接图像对齐)和建图(逐像素距离滤波)方面的工作,它能直接实现一个统一的全向模型,该模型能够对视场角大于 180° 的中心成像设备进行建模。
B. 研究方向
畸变感知卷积神经网络(CNNs):卷积神经网络(CNNs)会自然地利用图像网格中的平移不变性,而在鱼眼图像中,由于空间变化的畸变,这种平移不变性被打破了。已经有人提出了球形卷积神经网络(Spherical CNNs)[93][159],它们可直接用于球形径向畸变模型。然而,汽车镜头更为复杂,球形模型并不适用。将球形卷积神经网络推广到更复杂的鱼眼流形表面会是一个有趣的研究方向。核变换网络(Kernel Transformer Networks)[95] 能有效地将卷积算子从透视投影转换到全向图像的等距柱状投影,它更适合推广到鱼眼图像上。
处理时间变化:正如我们之前所讨论的,由于径向畸变导致外观变化更大,鱼眼相机的目标探测器的样本复杂度有所增加。对于时间相关任务来说,这一情况更为严重,因为这些任务需要在两帧图像之间匹配特征,而这两帧图像可能存在两种不同的畸变。例如,在鱼眼相机的情况下,目标跟踪和重识别的难度显著增加。跟踪一个从静态相机左侧移动到右侧的行人,就需要处理因径向畸变而产生的较大外观变化。同样,对于一个静止的行人,相机的水平和垂直运动也会导致较大的变化。对于像跟踪这类的点特征对应问题来说,这也是一个挑战。一种解决方案可能是将径向畸变明确地嵌入到特征向量中,以便在匹配时加以利用。
鸟瞰视角感知:在自动驾驶中,将图像上的检测结果提升到三维空间是至关重要的。通常是通过逆透视映射(IPM)[160] 来实现这一点的,该方法假定地面是平坦的。也可以通过使用深度估计或与三维传感器进行融合来增强这一效果 [161]。近来有一种趋势是在网络中隐式地使用逆透视映射,直接输出三维结果 [162][163]。通常是通过使用一个可学习的校正层来转换抽象的编码器特征,以此作为在输入层面执行逆透视映射的替代方法来实现的。由于卷积神经网络拥有更多的上下文信息,而且可学习的变换可以更加灵活,所以这种方法比逐像素的逆透视映射效果更好 [163]。对于针孔相机而言,逆透视映射是一种线性变换,设计编码器特征的空间变换器相对容易。然而,对于鱼眼相机来说,逆透视映射是一个复杂的非线性算子,直接在鸟瞰视角空间中输出结果仍然是一个有待解决的问题。
多相机建模:目前大多数环视相机方面的工作都是将四个相机中的每一个独立对待,并执行感知算法。或许可以
更理想的模型,所有四个环绕视野相机联合。首先,它将帮助检测通过两个或三个摄像头(前、左、后)可见的大型车辆(如运输卡车)。其次,它消除了对在多个摄像机中看到的物体的重新识别(见图10)和对单个检测的后处理,形成了像车道模型一样的统一输出。多摄像机模型将更有效地聚合信息,产生更最优的输出。[164]开发了一种经典的几何方法,将多个相机视为单个相机。然而,最近有一些工作,利用多个摄像机作为输入到一个单一的感知模型[163],[165]。他们利用了针孔相机与最小的重叠视野。为环绕视图相机建模明显更具挑战性。

图15。近场和远场前摄像机图像形成不对称立体对。
近场与远场相机的统一建模:下一代自动驾驶系统的一种典型配置包含使用四个环视相机实现近场的 360 度全覆盖,以及六个远场相机(一个前置、一个后置、两侧各两个)[166]。正如在第三章 B 节所讨论的那样,它们有着截然不同的视场角和探测范围。因此,要对所有相机进行统一建模(这是对上述多相机建模的拓展)是颇具挑战性的。图 15 展示了车辆前部区域的近场和远场图像。它们构成了一对非对称立体像对,在此情况下,相较于存在根本性模糊问题、更具挑战性的单目深度估计,深度能够更容易地被计算出来。目前,还没有同时包含近场和远场相机的公开数据集来助力这项研究。



编辑推荐




最新资讯
-
风噪测试在电动汽车时代的关键作用
2025-04-29 11:34
-
汉航车辆性能测试系列之操纵稳定性测试--汉
2025-04-29 11:09
-
新能源汽车热管理系统验证体系PITMS正式发
2025-04-29 11:09
-
试验载荷谱采集
2025-04-29 11:07
-
APx500 软件演示模式 (Demo Mode) 竟有这些
2025-04-29 08:37
