




 广告
广告





















































一文带你了解自动驾驶数据合成的发展现状

作者 | 鲁大师
出品 | 汽车电子与软件
本文围绕AI与数据合成在自动驾驶领域的应用展开,全面探讨了数据合成产业的各个方面,包括数据合成产业概览、基于世界模型的数据合成技术、合成数据的产生原因、商业模式以及优势与挑战,还对市场进行了分析,并介绍了相关产品方案和技术架构,为深入了解该领域提供了丰富信息。
01、数据合成产业概览
1、自动驾驶数据合成产生的原因
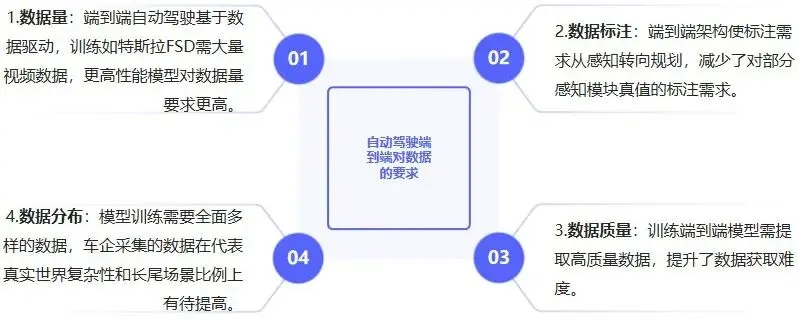
1. 真实数据采集的挑战:包括成本高昂、长尾场景稀缺、隐私与法律风险、地域局限性等问题。
2. 算法训练与迭代的需求:真实数据在适配硬件、标注成本和误差、强化学习等方面存在局限性,合成数据可弥补这些不足。同时,合成数据有助于降低成本、打破数据垄断、促进跨领域协作,缓解自动驾驶公司商业化和行业竞争压力。
3. L4/L5级自动驾驶研发、生成式AI技术进步、政策强制要求以及合成数据在成本效率方面的优势,共同推动市场发展。
2、宏观市场分析
合成数据是人工合成的数据,涵盖多种类型,当前企业使用以文本、图像和表数据为主。Gartner预测其在大模型训练数据中的占比将大幅提升。马斯克也指出合成数据对补充AI训练数据的重要性。
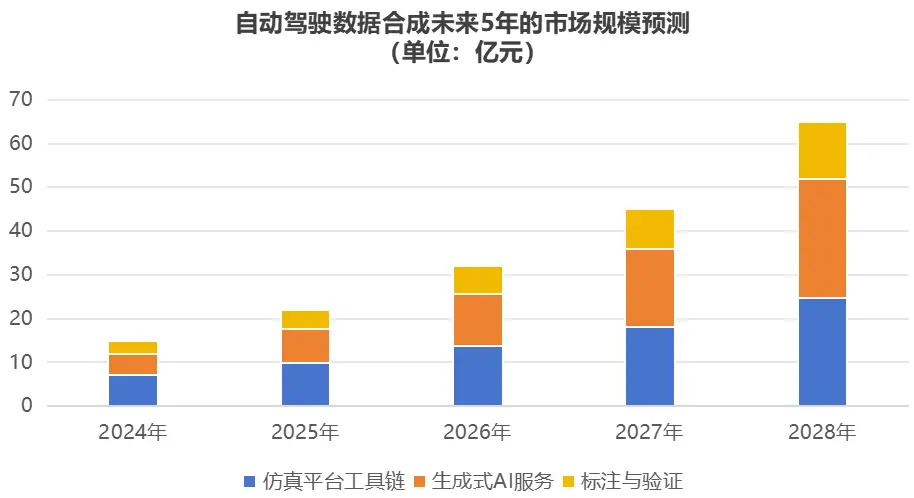
从市场来看,合成数据市场正呈现出快速增长的态势。技术需求爆发、政策强制要求以及成本效率优势成为关键驱动因素。L4/L5级自动驾驶研发加速,需覆盖超100亿公里虚拟测试里程;生成式AI提升合成数据质量,缩小了虚拟与现实之间的差距;中国和欧盟的相关政策也推动了合成数据在自动驾驶领域的应用。
细分市场中,仿真平台工具链初期主导市场,但增速放缓,未来增长点在于物理引擎精度提升;生成式AI服务增速最快,主要应用于长尾场景生成;标注与验证服务需求稳定,因为合成数据仍需与真实数据混合训练,并进行标注验证一致性。
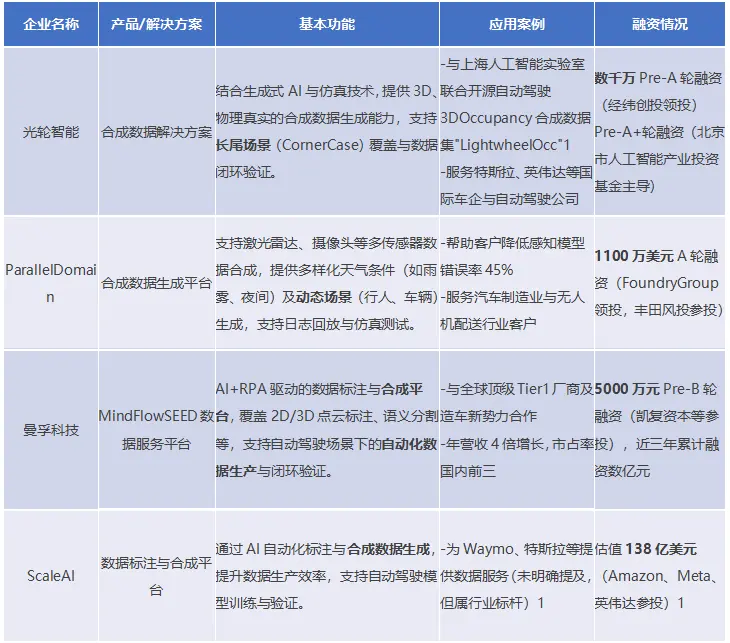
众多企业在自动驾驶数据合成领域积极布局。光轮智能结合生成式AI与仿真技术,提供高仿真3D合成数据;卓印智能的Simulaix合成数据支持文生图片、视频等多种数据类型生成,并带有标注;ParallelDomain的合成数据生成平台支持多传感器数据合成和多样化场景模拟;曼孚科技的MindFlowSEED数据服务平台实现了AI+RPA驱动的数据标注与合成;ScaleAI通过AI自动化标注与合成数据生成,提升数据生产效率。这些企业的产品和服务各具特色,推动了数据合成技术在自动驾驶领域的广泛应用。
数据合成企业产品对比
02、基于世界模型的数据合成技术
1、技术架构的核心逻辑
自动驾驶数据合成的终极目标,是用虚拟数据构建一个可模拟真实驾驶场景的“数字孪生世界”。基于世界模型的技术架构正是这一目标的实现载体,其核心逻辑可概括为:通过多模态数据建模→构建动态世界模型→驱动生成式算法→输出高保真合成数据。
我们可以用一张简化的架构图来直观呈现其核心模块:

2、数据输入层
自动驾驶场景的复杂性,决定了数据输入必须覆盖视觉、雷达、文本、地图等多维度信息:
视觉与雷达数据
摄像头图像:采集道路纹理、车辆外观、行人姿态等视觉特征(如 1920×1080 像素的 RGB 图像)。
激光雷达点云:提供三维空间坐标与反射强度数据(如 16 线 / 64 线激光雷达的点云序列)。
案例:Waymo 的无人车每秒可收集约 2000 帧图像和 150 万点云数据,这些数据为世界模型提供了最底层的物理表征。
语义与规则数据
高精地图:包含车道线、交通标志、红绿灯位置等静态语义(如百度 Apollo 的高精地图精度达厘米级)。
交通规则文本:如“红灯停、绿灯行”“禁止超车区域” 等逻辑约束,通过 NLP 技术解析为模型可理解的规则向量。
时序动态数据
IMU 惯性数据:记录车辆加速度、角速度等运动状态,用于构建时间序列的动态关联。
历史轨迹数据:包含车辆、行人的历史移动路径,用于训练模型对“未来行为” 的预测能力。
3、世界模型构建层
世界模型是整个架构的“大脑”,其核心任务是将多模态数据转化为对世界运行规律的数学描述。这一过程包含三大关键能力:
1)跨模态语义对齐
技术实现:通过 CLIP、ALBEF 等跨模态模型,将图像中的视觉特征(如 “红色轿车”)与文本中的语义标签(如 “Car, Red, Sedan”)映射到同一向量空间。
案例:特斯拉的 HydraNets 模型可同时处理图像、雷达和导航数据,实现 “看到红灯” 与 “停车规则” 的语义关联。
2)时空动态建模
时间维度:利用 TransformerEncoder 捕捉长时序依赖(如车辆变道前 3 秒的转向灯信号与后续轨迹的关联)。
空间维度:基于物理引擎(如 CARLA 模拟器)模拟车辆动力学(如制动距离与车速的关系)、行人运动学(如突然横穿马路的加速度模型)。
公式示例:车辆跟驰模型中的加速度公式:\(a_n(t+T) = \lambda \left( v_n^*(t) - v_n(t) \right)\) (\(v_n^*(t)\)为期望速度,\(\lambda\)为反应系数,体现驾驶员行为的时间延迟)
3)场景语义抽象
分层建模:将场景分解为“静态元素”(道路、建筑)、“动态主体”(车辆、行人)、“事件逻辑”(交通规则、交互行为)三层结构。
知识图谱应用:构建包含“车辆 - 行人 - 信号灯” 关系的知识图谱,如 “行人闯红灯→车辆紧急制动” 的因果链,确保合成场景的逻辑自洽。
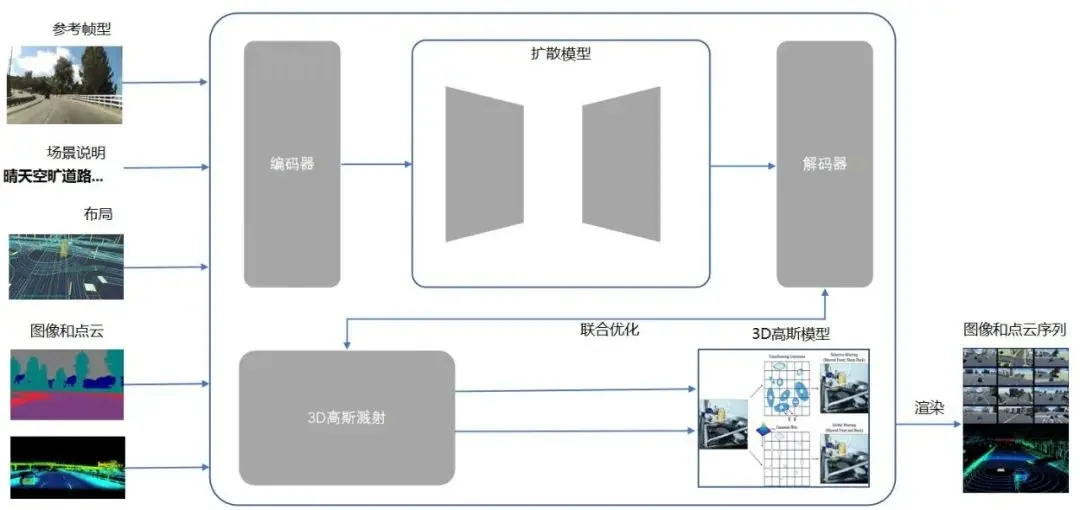
4、生成式模型驱动层
在世界模型提供的“虚拟世界” 基础上,生成式模型负责高效产出符合需求的合成数据。根据任务类型,可分为三类核心算法:
1)图像 / 视频生成
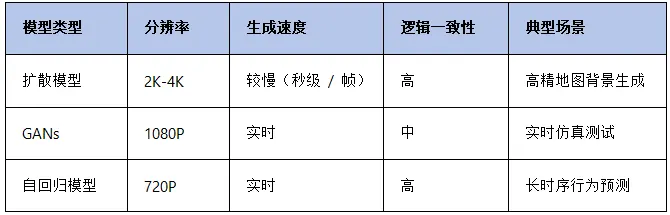
扩散模型(Diffusion Models)
代表技术:NVIDIA 的 GauGAN2,可根据语义掩码生成逼真街景(如 “左侧有公交车站的双向车道”)。
优势:生成图像分辨率高(可达 2048×1024),支持局部细节控制(如调整某辆车的颜色)。
对抗生成网络(GANs)
典型应用:Unity 的 Barracuda 框架,实时生成虚拟测试场景,用于自动驾驶算法的闭环验证。
局限性:生成数据可能存在“模式崩溃”(如重复生成相似车辆姿态),需结合世界模型的约束避免。
2)时序序列生成
自回归模型(Autoregressive Models)
技术实现:基于 Transformer 的 Decoder 结构,逐帧生成视频序列(如车辆从直行到左转的连续动作)。
关键参数:时间步长(通常为 0.1 秒 / 帧)、动作空间离散化(如方向盘转角 ±30° 范围内的 100 个离散值)。
3)缘场景增强
条件生成模型:通过输入“极端天气”“施工路段” 等条件标签,强制模型生成罕见场景。
案例:Waymo 的 “雨天 + 夜间 + 拥堵” 三重条件合成数据,可使算法在该场景下的避障成功率提升 47%。
主流生成式模型性能差异
5、数据输出与评估层
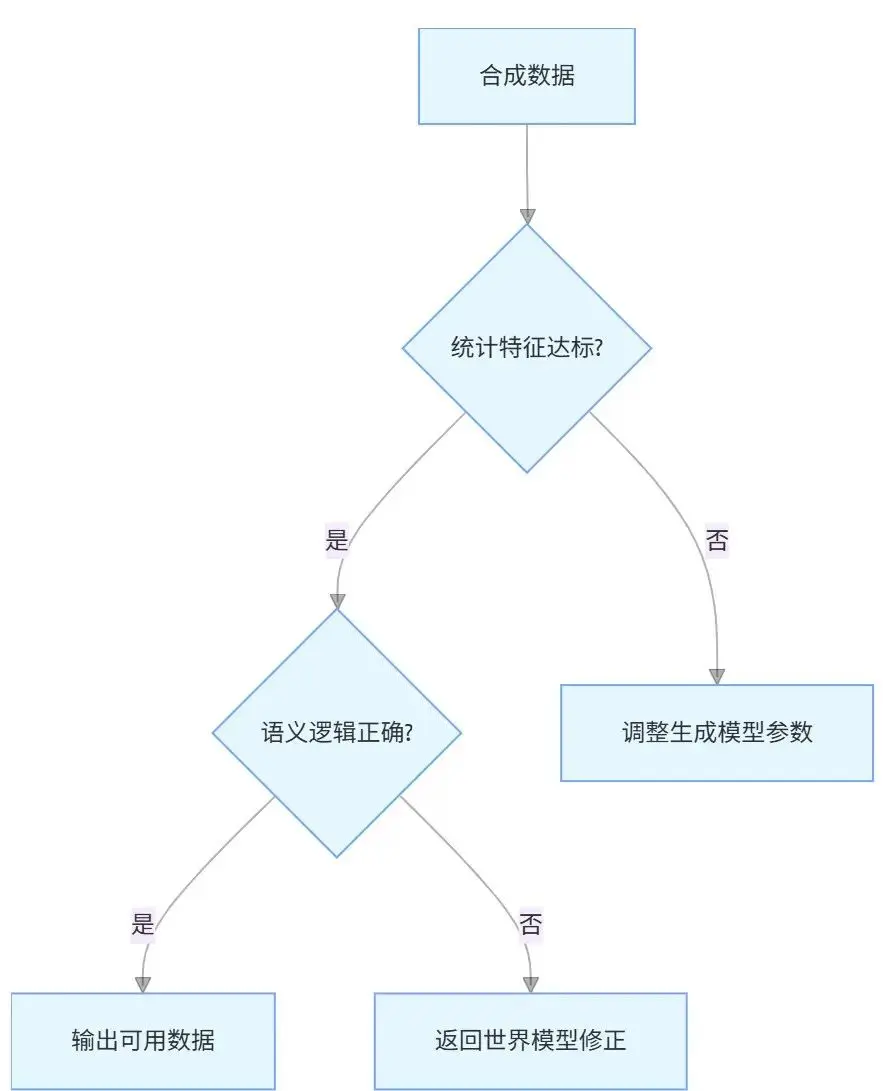
合成数据需通过三重校验才能投入使用:
1)统计特征对齐
指标:计算合成数据与真实数据的像素分布 KL 散度、点云密度 Wasserstein 距离,要求差异小于 15%。
工具:TensorFlow Probability 库,自动生成分布对比直方图。
2)语义一致性校验
规则引擎:基于交通法规知识图谱,检查“红灯时车辆是否停止”“行人是否在斑马线上” 等逻辑。
案例:某合成场景中出现“车辆在禁止左转路口转弯”,被规则引擎自动标记为无效数据。
3)跨模态一致性校验
时间戳对齐:确保图像帧与雷达点云的时间差小于 50ms。
传感器融合校验:通过多传感器联合标定算法,验证合成数据中“图像中的车辆位置” 与 “雷达点云坐标” 的误差小于 0.5 米。
数据评估与反馈机制
6、目前开源的世界模型
自动驾驶开源世界模型
开源厂家
代码地址
模型简介
主要功能
清华&北航:OccSora
https://gitcode.com/gh_mirrors/oc/OccSora
https://github.com/wzzheng/OccSora
基于扩散模型,通过引入四维场景标记器来获取紧凑的时空表示,并利用扩散转换器在给定轨迹提示下生成高质量的4D占用视频
能够生成具有真实3D布局和时间一致性的16秒视频
清华大学:OccWorld
https://github.com/wzzheng/OccWorld
借鉴了类似 GPT 的架构,通过时空生成 Transformer 预测未来的场景和车辆轨迹,从而实现对动态场景的建模和规划
加州大学:CarDreamer
https://github.com/ucd-dare/CarDreamer
这是第一个专门为开发基于 WM 的自动驾驶算法而设计的开源学习平台。它包括三个关键组件:1)世界模型骨干:CarDreamer 集成了某些最先进的 WM,简化了 RL 算法的再现。骨干与其它部分解耦,并使用标准 Gym 接口进行通信,以便用户可以轻松集成和测试他们自己的算法。2)内置任务:CarDreamer 提供了一套高度可配置的驾驶任务,这些任务与 Gym 接口兼容,并配备了经验优化的奖励函数。 3) 任务开发套件:本套件简化了驾驶任务的创建,使定义交通流和车辆路线变得容易,并自动收集多模式观测数据。
专注于提供一个开放的学习平台,支持研究人员开发和测试复杂的自动驾驶算法
CarFormer
https://github.com/Shamdan17/CarFormer
一种自回归Transformer,既可以驾驶也可以作为世界模型,预测未来状态。
Doe-1
项目地址:https://wzzheng.net/Doe
源码链接:https:/github.com/wzzheng/LDM
以端到端统一的方式自动生成感知、预测和规划标记。
百度:BEVWorld
https://github.com/zympsyche/BevWorld
通过整合鸟瞰图(BEV)潜在空间和多模态传感器输入(如LiDAR和图像数据),构建一个能够进行未来预测和环境理解的模型。
适用于长尾数据生成、闭环仿真测试以及对抗样本处理,具有物理规律理解和零样本探索的能力
WorldDreamer
https://github.com/JeffWang987/WorldDreamer
通用世界模型
DrivingWorld
https://github.com/YvanYin/DrivingWorld
GPT风格的自动驾驶世界模型
Drive-WM
https://github.com/BraveGroup/Drive-WM.git
结合了条件图像生成、条件视频生成等技术,并使用了开源项目diffusers来支持模型训练和推理
通过世界模型技术实现对自动驾驶车辆未来行为的精准预测和高效规划
https://blog.csdn.net/gitblog_00595/article/details/142199134
DriveDreamer-2
https://github.com/f1yfisher/DriveDreamer2
该模型基于 DriveDreamer 框架,并集成了大型语言模型(LLM)来生成用户定义的驾驶视频
仅使用文本提示作为输入的交通仿真管道,可用于生成用于驾驶视频生成的各种交通条件。
DriveDreamer4D
https://github.com/GigaAI-research/DriveDreamer4D
将世界模型作为数据生成器,通过结合真实驾驶数据生成新的轨迹视频,从而显著提升自动驾驶场景的时空一致性和渲染质量
03、应用场景
涵盖长尾场景覆盖与数据增强、智驾功能出海适配、预期功能安全验证、特殊场景仿真与行业扩展、数据隐私与合规性保障等多个方面。

1、边缘场景训练
合成数据可以用于构建低概率、高风险的边缘场景,如复杂交通、恶劣天气等。这些场景的数据采集难度较大,但通过合成数据技术,可以增加训练样本的多样性和泛化能力,帮助主机厂加速模型训练,解决预期功能安全问题。
2、海外交通场景
面对海外市场数据安全和隐私保护的需求,合成数据可以生成高逼真度的交通标志牌、停车场等场景,同时保护用户隐私。这有助于海外消费者无缝体验自动驾驶。
3、自动驾驶国家课题
合成数据被应用于北京大学牵头的“面向自动驾驶场景的高真实感数据合成”研究课题,通过多模态数据标注的高逼真度合成场景数据集,推动视觉大模型和高速脉冲视觉模型算法的研究和应用。
4、违章与事故场景
合成数据可以用于路侧感知算法的训练,生成真实城市道路的高分辨率网路还原数据集,作为真实路侧数据的补充,提高算法的准确性和鲁棒性。
5、智能交通管理
通过合成数据模拟各种交通场景,帮助交通管理部门优化交通流量控制、事件响应等。
6、自动驾驶算法训练和测试
合成数据可以覆盖各种极端场景和边缘案例,提升算法的鲁棒性。例如,特斯拉、英伟达、Waymo、百度和蔚来等公司已经布局了世界领先的自动驾驶模型前瞻研发。
7、多模态传感器数据合成
在自动驾驶出租车(Robotaxi)等场景中,合成数据技术可以用于多模态传感器数据的合成,优化自动驾驶系统的训练与优化。
8、生成式AI和世界模型
利用生成式AI和世界模型等先进人工智能技术生成高质量的合成数据,有效缓解数据短缺难题,提升算法模型的可靠性。这些技术可以生成文本、图片、视频等不同类型的数据,并快速提取大量未标记数据中的有价值信息。
9、自动驾驶数据平台
自主驾驶数据平台负责收集和管理来自不同传感器的数据,如激光雷达、摄像头和传感器融合数据。通过合成数据生成技术,研发团队可以快速生成多样化的场景,应对各种天气、时间和交通状况,显著降低测试成本。
04、商业模式&客户群体
在数据闭环领域,传统玩家和新型玩家的商业模式存在显著差异。传统玩家在数据闭环领域专注自身发展,服务独立不连续;新型玩家构建数据闭环新生态,推动向合作伙伴关系转变,实现利益共享、风险共担。以下是详细的对比分析。
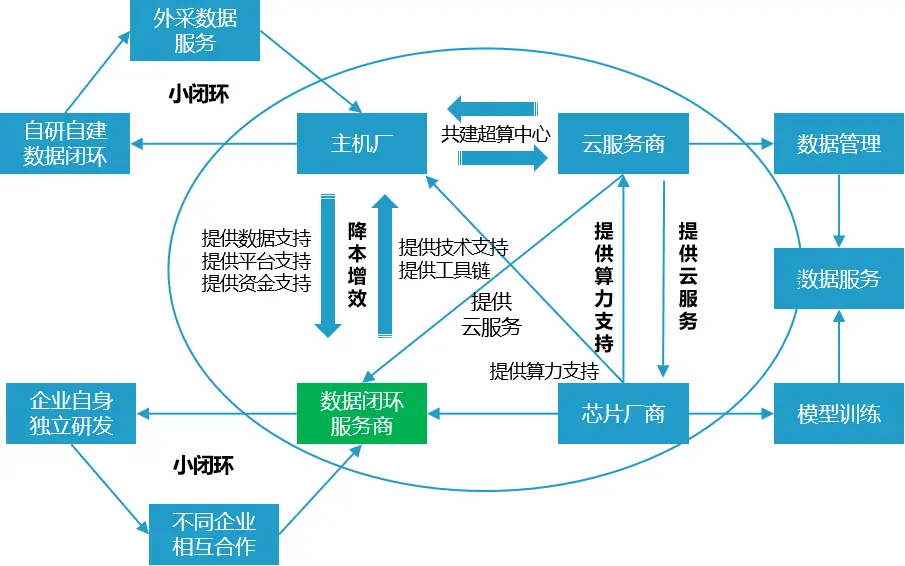
1、传统玩家的商业模式
1)基于买卖关系:
传统玩家在数据闭环领域的策略主要基于买卖双方的交易关系,专注于自身技术和产品的发展。
他们通常依赖于供应商提供的数据服务和主机厂所需要的数据服务,这些服务往往是线性的、独立不连续的。
2)技术与产品发展:
传统玩家更注重自身技术和产品的研发,而不是全面参与数据闭环的各个环节。
他们可能选择完全外采或部分核心外采、部分自研的方式,以降低研发风险和成本。
3)资源和资金限制:
由于资源和资金的限制,传统玩家在面对快速变化的市场时,可能需要迅速做出决策。
2、新型玩家的商业模式
1)合作伙伴关系
新型玩家通过构建数据闭环新生态,推动了从单一的买卖关系向合作伙伴关系的转变。
这种模式下,供应商、主机厂以及其他合作伙伴共同承担风险,共享利益,有助于资源、技术和市场信息的共享。
2)全栈自研与核心模块自研
新型玩家更倾向于全栈自研或核心模块自研,以实现技术上的突破和话语权。
例如,特斯拉就是全栈自研的典型代表,其数据闭环工具链已经实现了数据采集、预处理、回传、处理、仿真、部署、OTA等多个环节,并自研芯片并DOJO超算中心用来处理这些数据。
3)快速响应市场变化
新型玩家能够快速响应市场变化,迅速做出决策,以适应智驾技术的迭代和市场的变化。
4)创新能力和个性化需求
新型玩家通常具有较高的创新能力,能够满足个性化需求,并且具备一体化管理的能力。
传统玩家和新型玩家在数据闭环领域的商业模式有以下主要区别:
合作模式:传统玩家依赖于买卖关系,而新型玩家则转向合作伙伴关系。
技术投入:传统玩家更注重自身技术和产品的研发,而新型玩家则倾向于全栈自研或核心模块自研。
市场响应:新型玩家能够更快地响应市场变化,适应技术迭代。
这些差异反映了不同玩家在面对智驾技术和市场变化时的不同策略和优势。
05、优势与挑战
在自动驾驶领域,合成数据作为一种新兴的数据资源,具有显著的优势和挑战。以下是基于我搜索到的资料对合成数据在自动驾驶领域中的优势和挑战的详细分析:
1、优势
1. 采集成本低:
合成数据通过算法生成,无需实际收集大量真实数据,从而大大降低了数据采集的成本。这对于自动驾驶这种需要大量高质量图像数据的领域尤为重要。
2. 自带标注:
合成数据通常在生成过程中自带标注信息,这减少了后续标注工作的复杂性和成本,提高了数据处理的效率。
3. 跨平台通用性强:
合成数据可以在不同的平台和系统中使用,具有良好的通用性,这使得其在不同场景下的应用更加灵活。
4. 针对性补充潜在危险场景和边缘场景:
合成数据可以有针对性地生成潜在危险场景和边缘场景,如恶劣天气、复杂路况和突发事故等,从而完善长尾场景库,提升模型的鲁棒性和可靠性。
5. 加速研发周期:
通过生成大量高质量的合成数据,AI模型可以在更短的时间内完成训练,并在某些特定场景下的表现甚至优于仅依赖真实数据的模型。
6. 保护隐私:
合成数据避免了真实数据中的隐私问题,特别是在涉及个人隐私和敏感信息的情况下,合成数据提供了一种安全的数据来源。
2、挑战
1. 缺乏现实世界的混沌与复杂性:
合成环境可能无法完全复制现实世界中的复杂性和混沌性,这可能导致模型在实际应用中的适应性和准确性受到质疑。
2. 生成质量的控制:
虽然合成数据可以生成大量样本,但如何确保生成数据的质量和真实性仍然是一个挑战。生成的数据需要足够接近真实世界,以确保模型的训练效果。
3. 技术门槛高:
生成高质量合成数据需要先进的技术和算法支持,如生成式AI、GANs(生成对抗网络)等。这些技术的开发和维护需要较高的成本和技术门槛。
4. 法律和伦理问题:
在某些情况下,合成数据的使用可能涉及法律和伦理问题,特别是在涉及隐私保护和数据安全方面。需要确保合成数据的生成和使用符合相关法律法规。
合成数据在自动驾驶领域具有显著的优势,包括低成本、自带标注、跨平台通用性强、针对性补充潜在危险场景和边缘场景、加速研发周期以及保护隐私等。然而,合成数据也面临一些挑战,如缺乏现实世界的混沌与复杂性、生成质量的控制、技术门槛高以及法律和伦理问题。
展望未来,自动驾驶数据合成技术将持续创新发展。随着技术的不断进步,合成数据的质量和真实感将进一步提升,更加接近真实世界数据。同时,数据合成技术与其他新兴技术的融合也将更加紧密,如与区块链技术结合,进一步保障数据的安全性和可信度;与边缘计算技术结合,实现更高效的数据处理和应用。此外,随着自动驾驶技术的普及,数据合成技术的应用场景也将不断拓展,不仅局限于车辆自动驾驶,还将延伸到智能交通系统的各个环节,为构建更加智能、高效、安全的未来交通体系提供强大支持。



编辑推荐




最新资讯
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
-
天检新能力VOL.95 | 乘员晕车仿生测试能力
2025-04-25 10:14
