




 广告
广告





















































汽车数据采集与分析
2018-05-15 09:49:09· 来源:智车科技

汽车数据采集可以分为两大类,一类是驾驶者行为数据采集,另一类是深度学习视觉训练数据采集。数据采集必然是有选择性的,最简单也最普遍的一类机器学习算法就是分类(classification)。
汽车数据采集可以分为两大类,一类是驾驶者行为数据采集,另一类是深度学习视觉训练数据采集。数据采集必然是有选择性的,最简单也最普遍的一类机器学习算法就是分类(classification)。
对于分类,输入的训练数据有特征(feature),有标签(label)。所谓的学习,其本质就是找到特征和标签间的关系(mapping)。这样当有特征而无标签的未知数据输入时,我们就可以通过已有的关系得到未知数据标签。如果所有训练数据都有标签,则为有监督学习(supervised learning)。如果数据没有标签,显然就是无监督学习(unsupervisedlearning)了,也即聚类(clustering)。聚类学习目前处于起步阶段,与分类学习比简直是天壤之别,即便不需要标注,但是也需要特征,某种意义上也可以说不是绝对意义的无监督学习。
驾驶者行为数据,这是评价ADAS系统最客观的方法,根据此数据分析可以得出ADAS系统是否对驾驶安全有提升,是否有价值。最知名的则是由美国策略性公路研究计划 (The second StrategicHighway Research Program, SHRP 2) 中的自然驾驶研究计划 (Naturalistic Driving Study,NDS)。行驶于弗吉尼亚州北部(NorthernVirginia) 及华盛顿哥伦比亚特区 (Washington, D.C.) 中之 100 辆被选定的机动车辆为记录对象,且为了能够记录驾驶人实际的驾驶情况,其计划执行单位并没有针对被选驾驶人举办关于此研究计划的说明会。这些实验是在无干扰,无实验人员出现,日常驾驶状态下进行的。此计划总共为期两年,其总共搜集 2000000 车行里程 (vehicle miles) 及 43000 小时的行驶数据。其中,总共记录828 笔事故及几近事故资料,其中包含 68 件碰撞(crash) 及 760 件几近碰撞(near-crash)。
2012年NDS项目扩展到中国,上海同济大学、通用汽车和弗吉尼亚理工大学三方合作,在2012年12月开始,于2015年12月结束,按计划采集90名中国驾驶员的日常驾驶行为数据,每辆车均配备Mobileye的C2-270(FCW)和SHRP2 NextGen数据采集系统。总共5辆车,分别是2辆君越,2辆科鲁兹,1辆卡迪拉克DTS。每位实验者驾驶实验车辆2个月,第一个月开启Mobileye,第二个月关闭。SHRP2 NextGen数据采集系统包括车辆数据总线接口,三轴加速度计,可跟踪9个目标的毫米波雷达,温度与湿度传感器,GPS定位系统,四路摄像头,这四路分别是驾驶者面部,车辆前方,车辆后方,驾驶员手部。采集频率从10-100Hz不等。需要指出,没有厂家开放CAN总线,OBD根本拿不到什么有价值的数据。 据说SHRP2 NextGen 由日本富士通设计并制造,使用了高性能FPGA。

上图为装载了SHARP2 NextGen的车辆后备箱,需要指出这是2008年的设计,换到今日,体积可以大幅度缩小。
截至到2015年7月,上海的NDS研究共采集了55名驾驶员,大约13万公里的驾驶数据。选择19名典型驾驶员数据分析,共4573次出行,累计公里数为60689公里。其中32797采集自Mobileye关闭阶段,27892公里采集自Mobileye开启阶段。驾驶员年龄分布在28-61岁之间,平均年龄40.9岁,驾龄在1-16年之间,平均驾龄6.6年。
研究结论表明FCW对驾驶员行为并未有明显改变,只是略微降低了驾驶员跟车的反应时间。光线晴好的情况下,略微降低了130毫秒,反应时间变短,只是稍微加速了交通流的速度。
欧洲也有类似的项目,名字为EuroFOT,主要在西班牙和德国开展,包括商用车。德国车队有200辆车,包括60辆MAN卡车,100辆福特轿车和40辆大众轿车。福特车辆均配备了FCW和ACC。MAN则配备了CSW(Curve Speed Warning)和LDW。大众则配备了ACC和LDW。主要研究ACC、LDW、CSW、FCW对驾驶员的影响。西班牙由CTAG(Centre Technologique de l'Automobile deGalice)主导,共40辆车,主要研究巡航控制和速度控制对驾驶员的影响。CTAG自己开发了Can数据采集器。
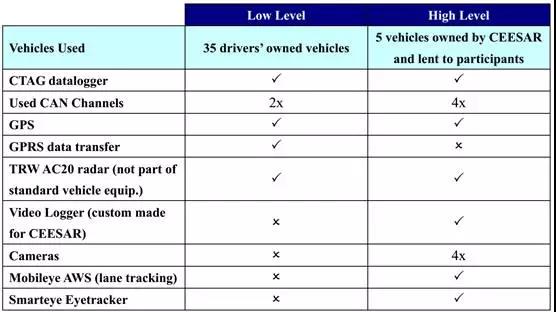
西班牙的40辆车中35辆装配低级采集设备,5辆装配高级采集设备。
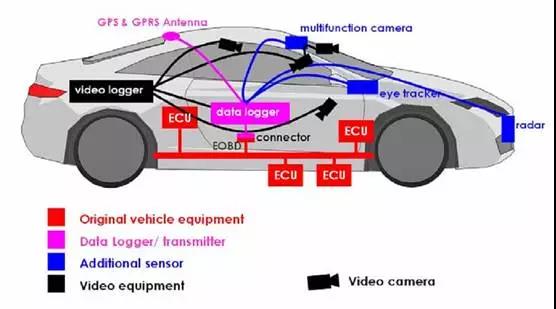
上图为高级采集设备,包括1个红外摄像头、4个摄像头和1个天合的AC20毫米波雷达。红外摄像头是个眼球轨迹跟踪器。4个摄像头,分别对应脚下、脸部、前方和手部。至于研究成果,目前还未透露。
再有一类驾驶者行为数据采集是为了深度学习训练数据用的,试图让机器学习人类的驾驶技能,最早美国波音公司曾对其研究,论文为 A Survey of Robot Learning from Demonstration,提出LFD。后来美国陆军实验室资助CMU开发,主要研究者是David Silver, J. Andrew Bagnell 和 AnthonyStentz,这篇论文的名字为Learning Autonomous Driving Styles and Maneuversfrom Expert Demonstration 进一步发展LFD,最后就是英伟达的端到端深度学习。
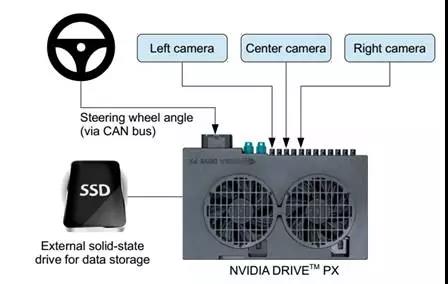
训练数据包括从视频中采样得到的单帧视频,以及对应的方向控制命令(1/r)。只用驾驶员操作的数据训练远远不够;网络模型还需要学习如何纠正错误的操作,否则汽车就会慢慢偏离公路了。于是,训练数据额外补充了大量图像,包括汽车从车道中心的各种偏移和转弯。
两个特定的偏离中心的图像可以从左和右两台相机得到。摄像机之间的其它偏离以及所有的旋转都靠临近摄像机的视角变换来仿真。精确的视角转换需要具备3D场景的知识,而这套系统却不具备这些知识,因此假设所有低于地平线的点都在地平面上,所有地平线以上的点都在无限远处,以此来近似地估计视角变换。在平坦的地区这种方法没问题,但是对于更完整的渲染,会造成地面上物体的扭曲,比如汽车、树木和建筑等。英伟达认为这些扭曲对网络模型训练并无大碍。方向控制会根据变换后的图像迅速得到修正,使得汽车能在两秒之内回到正确的位置和方向。
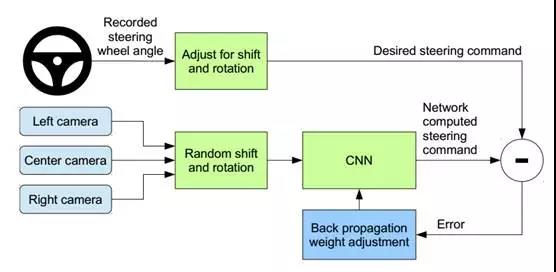
图像输入到CNN网络计算方向控制命令。预测的方向控制命令与理想的控制命令相比较,然后调整CNN模型的权值使得预测值尽可能接近理想值。权值调整是由机器学习库Torch 7的后向传播算法完成。
日本人将这个系统扩展,单靠摄像头根本不可靠,激光雷达是少不了的。日本自动驾驶联盟SIP-AURAS将开发驾驶者行为数据库的任务交给了日本JARI,日本汽车研究院。
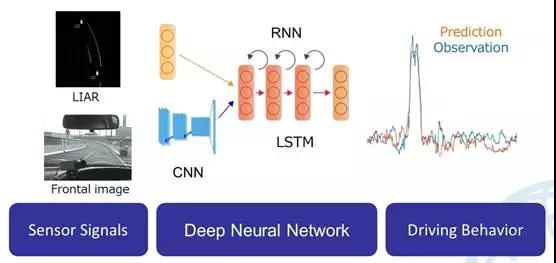
这套系统也可以用来研究驾驶者行为,也可以用来做训练数据。
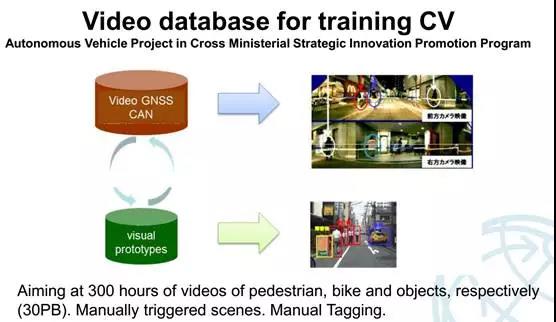
日本汽车研究院与名古屋大学合作,计划使用30辆车在日本全国采集数据。
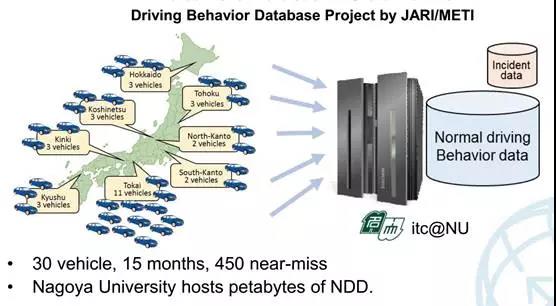
日本的数据采集系统不仅有激光雷达,还有眼球与面部轨迹,还有心跳次数。

上图为数据采集车。

激光雷达原始数据庞大,每秒大约300MB,转换为JPEG格式的图像后每秒大约3MB。
搜集深度学习训练数据做图形识别最典型的莫过于KITTI。德国卡尔斯鲁厄理工学院和芝加哥丰田技术研究所联合建立的一个算法评测平台KITTI,成为目前国际上公开的最大的自动驾驶场景下的计算机视觉算法评测数据集。有2012和2015两个版本。其他比较知名的还有,Cityscapes,奔驰联合德国老牌工科大学达姆施塔特工业大学、普朗克研究院、德累斯顿工业大学做的;剑桥大学的CamVid,牛津大学的Oxford RobotCar,斯坦福大学的ImageNet,英国利兹大学、苏黎世工学院、爱丁堡大学、微软剑桥研究院、牛津大学联合推出的Pascal VOC,Leuven大学的Leuven,美国Middlebury大学的Middlebury。
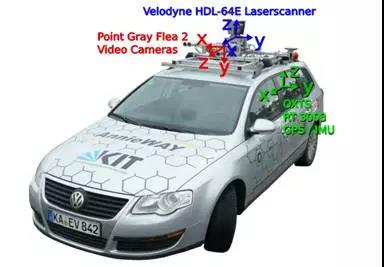
KITTY采集车配置:
• 2 ×PointGray Flea2 灰度摄像头 (FL2-14S3M-C),140万像素, 1/2” Sony ICX267 CCD
• 2 ×PointGray Flea2 彩色摄像头 (FL2-14S3C-C), 140万像素, 1/2” Sony ICX267 CCD
• 4 × EdmundOptics lenses, 4mm, opening angle ∼ 90◦,vertical opening angle of region of interest(ROI) ∼ 35◦
• 1 × Velodyne HDL-64E rotating 3D laser scanner,10 Hz,64 beams, 0.09 degree angular resolution, 2 cm distance accuracy,collecting ∼ 1.3 million points/second, field ofview: 360◦ horizontal, 26.8◦ vertical, range: 120 m
• 1 × OXTS RT3003 inertial andGPS navigation system,6 axis, 100 Hz, L1/L2 RTK, resolution: 0.02m / 0.1◦
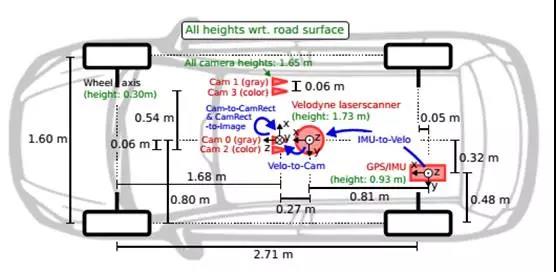
上图为传感器布局
采集车的双目摄像头基线长54厘米,车载电脑为英特尔至强的X5650 Cpu,RAID 5 4TB硬盘。采集时间是2011年的9月底和10月初,总共大约5天,总数据集大约180GB(要做大规模商业化应用至少要有PB级的训练数据),2015年做了扩展。主要内容如下,分训练和测试数据。

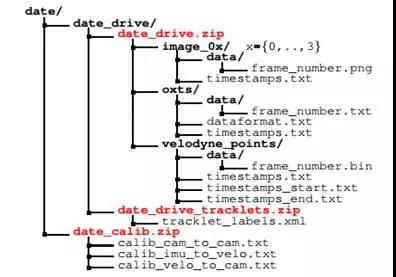
上图为Kitti数据格式
为了生成3D地面真实信息,我们雇佣了一组注释员,并要求他们以3D边界框的形式将轨迹分配给对象,如汽车,货车,卡车,电车,行人和骑车人。与大多数现有的基准不同,我们不依赖于在线众包来执行标签。为此,我们创建了一个特殊用途的标签工具,它显示3Dlaser点以及相机图像,以提高注释的质量。与大多数数据集不同,Kitti没有采用众包的形式来手工标注,而是自己基于激光雷达开发了自动标注工具。
Cityscape没有公布其采集车的照片,其采集车没有采用激光雷达,只用了一个基线为22厘米的200万像素级的双目摄像头,使用安森美的AR0331传感器,拥有HDR高动态范围,且是在车内部,而不是在车外面。输出16比特的线性色彩。没有使用IMU,只有一个GPS。总共25000张图像,其中人工选择了5000张前景突出,视差明显的图像做精细标注。20000张前景不突出,驾驶者20米内图像,采用了LabelMe的自动标注软件,做了简易标注。
搜集训练数据再做标注,需要耗费巨大的人力,例如在自然语言处理(NLP)中,Penn Chinese Treebank 在2年里只完成了4000句话的标签。要知道玩深度学习计算机视觉的人可都是热门人才,月薪动辄好几万。即便做最没技术含量的手工标注,也是人工费用不低。牛津大学搞了一套基于弱监督的学习系统。在实际应用中的学习问题往往以混合形式出现,如多标记多示例、半监督多标记、弱标记多标记等,像光线对图像质量影响很大,人工标注也不可能每帧图像都标得非常好。针对监督信息不完整或不明确对象的学习问题统称为弱监督学习,弱监督学习可以看作是有多个标记的数据集合,次集合可以是空集,单个元素,或是多个元素的。
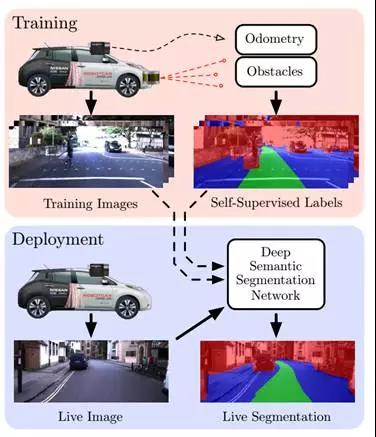
这套系统输入图像,输出的是语义化分割的图像,提供驾驶路径建议,也就是Free Space。这套系统在一辆日产聆风上安装了一个Point Grey Bumblebee XB3双目摄像头,输入精度为640*256,车两侧各装一个Sick LD-MRS 4线激光雷达(估计是经费不足,应该用Velodyne的16线或32线激光雷达)。
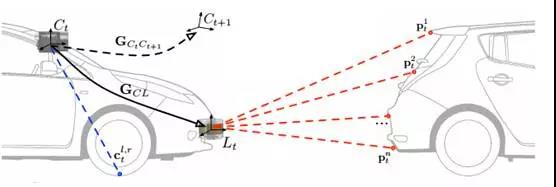
使用前文波音和CMU所提出的LFD方法制造出建议路径标签,然后将激光雷达数据与路径叠加,激光雷达可以精确探知障碍物,再加上LFD,两者合作增加了可靠性。

经过训练后得到一个数学模型后,可以只用一个单目摄像头即可实现准确探测Free Space和障碍物探测,不过光线不好的情况还是无解,激光雷达是无人驾驶绝对需要的。
对于分类,输入的训练数据有特征(feature),有标签(label)。所谓的学习,其本质就是找到特征和标签间的关系(mapping)。这样当有特征而无标签的未知数据输入时,我们就可以通过已有的关系得到未知数据标签。如果所有训练数据都有标签,则为有监督学习(supervised learning)。如果数据没有标签,显然就是无监督学习(unsupervisedlearning)了,也即聚类(clustering)。聚类学习目前处于起步阶段,与分类学习比简直是天壤之别,即便不需要标注,但是也需要特征,某种意义上也可以说不是绝对意义的无监督学习。
驾驶者行为数据,这是评价ADAS系统最客观的方法,根据此数据分析可以得出ADAS系统是否对驾驶安全有提升,是否有价值。最知名的则是由美国策略性公路研究计划 (The second StrategicHighway Research Program, SHRP 2) 中的自然驾驶研究计划 (Naturalistic Driving Study,NDS)。行驶于弗吉尼亚州北部(NorthernVirginia) 及华盛顿哥伦比亚特区 (Washington, D.C.) 中之 100 辆被选定的机动车辆为记录对象,且为了能够记录驾驶人实际的驾驶情况,其计划执行单位并没有针对被选驾驶人举办关于此研究计划的说明会。这些实验是在无干扰,无实验人员出现,日常驾驶状态下进行的。此计划总共为期两年,其总共搜集 2000000 车行里程 (vehicle miles) 及 43000 小时的行驶数据。其中,总共记录828 笔事故及几近事故资料,其中包含 68 件碰撞(crash) 及 760 件几近碰撞(near-crash)。
2012年NDS项目扩展到中国,上海同济大学、通用汽车和弗吉尼亚理工大学三方合作,在2012年12月开始,于2015年12月结束,按计划采集90名中国驾驶员的日常驾驶行为数据,每辆车均配备Mobileye的C2-270(FCW)和SHRP2 NextGen数据采集系统。总共5辆车,分别是2辆君越,2辆科鲁兹,1辆卡迪拉克DTS。每位实验者驾驶实验车辆2个月,第一个月开启Mobileye,第二个月关闭。SHRP2 NextGen数据采集系统包括车辆数据总线接口,三轴加速度计,可跟踪9个目标的毫米波雷达,温度与湿度传感器,GPS定位系统,四路摄像头,这四路分别是驾驶者面部,车辆前方,车辆后方,驾驶员手部。采集频率从10-100Hz不等。需要指出,没有厂家开放CAN总线,OBD根本拿不到什么有价值的数据。 据说SHRP2 NextGen 由日本富士通设计并制造,使用了高性能FPGA。
上图为装载了SHARP2 NextGen的车辆后备箱,需要指出这是2008年的设计,换到今日,体积可以大幅度缩小。
截至到2015年7月,上海的NDS研究共采集了55名驾驶员,大约13万公里的驾驶数据。选择19名典型驾驶员数据分析,共4573次出行,累计公里数为60689公里。其中32797采集自Mobileye关闭阶段,27892公里采集自Mobileye开启阶段。驾驶员年龄分布在28-61岁之间,平均年龄40.9岁,驾龄在1-16年之间,平均驾龄6.6年。
研究结论表明FCW对驾驶员行为并未有明显改变,只是略微降低了驾驶员跟车的反应时间。光线晴好的情况下,略微降低了130毫秒,反应时间变短,只是稍微加速了交通流的速度。
欧洲也有类似的项目,名字为EuroFOT,主要在西班牙和德国开展,包括商用车。德国车队有200辆车,包括60辆MAN卡车,100辆福特轿车和40辆大众轿车。福特车辆均配备了FCW和ACC。MAN则配备了CSW(Curve Speed Warning)和LDW。大众则配备了ACC和LDW。主要研究ACC、LDW、CSW、FCW对驾驶员的影响。西班牙由CTAG(Centre Technologique de l'Automobile deGalice)主导,共40辆车,主要研究巡航控制和速度控制对驾驶员的影响。CTAG自己开发了Can数据采集器。
西班牙的40辆车中35辆装配低级采集设备,5辆装配高级采集设备。
上图为高级采集设备,包括1个红外摄像头、4个摄像头和1个天合的AC20毫米波雷达。红外摄像头是个眼球轨迹跟踪器。4个摄像头,分别对应脚下、脸部、前方和手部。至于研究成果,目前还未透露。
再有一类驾驶者行为数据采集是为了深度学习训练数据用的,试图让机器学习人类的驾驶技能,最早美国波音公司曾对其研究,论文为 A Survey of Robot Learning from Demonstration,提出LFD。后来美国陆军实验室资助CMU开发,主要研究者是David Silver, J. Andrew Bagnell 和 AnthonyStentz,这篇论文的名字为Learning Autonomous Driving Styles and Maneuversfrom Expert Demonstration 进一步发展LFD,最后就是英伟达的端到端深度学习。
训练数据包括从视频中采样得到的单帧视频,以及对应的方向控制命令(1/r)。只用驾驶员操作的数据训练远远不够;网络模型还需要学习如何纠正错误的操作,否则汽车就会慢慢偏离公路了。于是,训练数据额外补充了大量图像,包括汽车从车道中心的各种偏移和转弯。
两个特定的偏离中心的图像可以从左和右两台相机得到。摄像机之间的其它偏离以及所有的旋转都靠临近摄像机的视角变换来仿真。精确的视角转换需要具备3D场景的知识,而这套系统却不具备这些知识,因此假设所有低于地平线的点都在地平面上,所有地平线以上的点都在无限远处,以此来近似地估计视角变换。在平坦的地区这种方法没问题,但是对于更完整的渲染,会造成地面上物体的扭曲,比如汽车、树木和建筑等。英伟达认为这些扭曲对网络模型训练并无大碍。方向控制会根据变换后的图像迅速得到修正,使得汽车能在两秒之内回到正确的位置和方向。
图像输入到CNN网络计算方向控制命令。预测的方向控制命令与理想的控制命令相比较,然后调整CNN模型的权值使得预测值尽可能接近理想值。权值调整是由机器学习库Torch 7的后向传播算法完成。
日本人将这个系统扩展,单靠摄像头根本不可靠,激光雷达是少不了的。日本自动驾驶联盟SIP-AURAS将开发驾驶者行为数据库的任务交给了日本JARI,日本汽车研究院。
这套系统也可以用来研究驾驶者行为,也可以用来做训练数据。
日本汽车研究院与名古屋大学合作,计划使用30辆车在日本全国采集数据。
日本的数据采集系统不仅有激光雷达,还有眼球与面部轨迹,还有心跳次数。
上图为数据采集车。
激光雷达原始数据庞大,每秒大约300MB,转换为JPEG格式的图像后每秒大约3MB。
搜集深度学习训练数据做图形识别最典型的莫过于KITTI。德国卡尔斯鲁厄理工学院和芝加哥丰田技术研究所联合建立的一个算法评测平台KITTI,成为目前国际上公开的最大的自动驾驶场景下的计算机视觉算法评测数据集。有2012和2015两个版本。其他比较知名的还有,Cityscapes,奔驰联合德国老牌工科大学达姆施塔特工业大学、普朗克研究院、德累斯顿工业大学做的;剑桥大学的CamVid,牛津大学的Oxford RobotCar,斯坦福大学的ImageNet,英国利兹大学、苏黎世工学院、爱丁堡大学、微软剑桥研究院、牛津大学联合推出的Pascal VOC,Leuven大学的Leuven,美国Middlebury大学的Middlebury。
KITTY采集车配置:
• 2 ×PointGray Flea2 灰度摄像头 (FL2-14S3M-C),140万像素, 1/2” Sony ICX267 CCD
• 2 ×PointGray Flea2 彩色摄像头 (FL2-14S3C-C), 140万像素, 1/2” Sony ICX267 CCD
• 4 × EdmundOptics lenses, 4mm, opening angle ∼ 90◦,vertical opening angle of region of interest(ROI) ∼ 35◦
• 1 × Velodyne HDL-64E rotating 3D laser scanner,10 Hz,64 beams, 0.09 degree angular resolution, 2 cm distance accuracy,collecting ∼ 1.3 million points/second, field ofview: 360◦ horizontal, 26.8◦ vertical, range: 120 m
• 1 × OXTS RT3003 inertial andGPS navigation system,6 axis, 100 Hz, L1/L2 RTK, resolution: 0.02m / 0.1◦
上图为传感器布局
采集车的双目摄像头基线长54厘米,车载电脑为英特尔至强的X5650 Cpu,RAID 5 4TB硬盘。采集时间是2011年的9月底和10月初,总共大约5天,总数据集大约180GB(要做大规模商业化应用至少要有PB级的训练数据),2015年做了扩展。主要内容如下,分训练和测试数据。
上图为Kitti数据格式
为了生成3D地面真实信息,我们雇佣了一组注释员,并要求他们以3D边界框的形式将轨迹分配给对象,如汽车,货车,卡车,电车,行人和骑车人。与大多数现有的基准不同,我们不依赖于在线众包来执行标签。为此,我们创建了一个特殊用途的标签工具,它显示3Dlaser点以及相机图像,以提高注释的质量。与大多数数据集不同,Kitti没有采用众包的形式来手工标注,而是自己基于激光雷达开发了自动标注工具。
Cityscape没有公布其采集车的照片,其采集车没有采用激光雷达,只用了一个基线为22厘米的200万像素级的双目摄像头,使用安森美的AR0331传感器,拥有HDR高动态范围,且是在车内部,而不是在车外面。输出16比特的线性色彩。没有使用IMU,只有一个GPS。总共25000张图像,其中人工选择了5000张前景突出,视差明显的图像做精细标注。20000张前景不突出,驾驶者20米内图像,采用了LabelMe的自动标注软件,做了简易标注。
搜集训练数据再做标注,需要耗费巨大的人力,例如在自然语言处理(NLP)中,Penn Chinese Treebank 在2年里只完成了4000句话的标签。要知道玩深度学习计算机视觉的人可都是热门人才,月薪动辄好几万。即便做最没技术含量的手工标注,也是人工费用不低。牛津大学搞了一套基于弱监督的学习系统。在实际应用中的学习问题往往以混合形式出现,如多标记多示例、半监督多标记、弱标记多标记等,像光线对图像质量影响很大,人工标注也不可能每帧图像都标得非常好。针对监督信息不完整或不明确对象的学习问题统称为弱监督学习,弱监督学习可以看作是有多个标记的数据集合,次集合可以是空集,单个元素,或是多个元素的。
这套系统输入图像,输出的是语义化分割的图像,提供驾驶路径建议,也就是Free Space。这套系统在一辆日产聆风上安装了一个Point Grey Bumblebee XB3双目摄像头,输入精度为640*256,车两侧各装一个Sick LD-MRS 4线激光雷达(估计是经费不足,应该用Velodyne的16线或32线激光雷达)。
使用前文波音和CMU所提出的LFD方法制造出建议路径标签,然后将激光雷达数据与路径叠加,激光雷达可以精确探知障碍物,再加上LFD,两者合作增加了可靠性。
经过训练后得到一个数学模型后,可以只用一个单目摄像头即可实现准确探测Free Space和障碍物探测,不过光线不好的情况还是无解,激光雷达是无人驾驶绝对需要的。



编辑推荐




最新资讯
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
