




 广告
广告





















































IEEE IV2018论文:基于多异构数据集的卷积网络街道场景语义分割
2018-07-12 15:42:15· 来源:智车科技

我们提出了一种带有分层分类器的卷积网络,可针对每个像素进行语义分割,能够在多个异构数据集上进行训练并可开发它们的语义层次结构。
摘要:我们提出了一种带有分层分类器的卷积网络,可针对每个像素进行语义分割,能够在多个异构数据集上进行训练并可开发它们的语义层次结构。我们的网络是第一个同时在智能交通工具领域的三个不同数据集(即Cityscapes,GTSDB和Mapillary Vistas)上训练的网络,并且能够处理不同的细节语义级别、类别不平衡和不同的注释类型,即密集的每像素和稀疏的边界框标签。我们通过与平面,非等级分类器进行比较来评估我们的分层方法,并且我们显示Cityscapes类的平均像素精度为13.0%,Vistas类为2.4%,GTSDB类为32.3%。对于在GPU上运行的108个类,我们在520 x 706的分辨率下实现了17 fps的推理速率。
作者:Panagiotis Meletis and Gijs Dubbelman
第一节,介绍:
随着深度学习技术的发展,按照像素分类提出的分割任务在过去几年中取得了很大进展[2],语义分类成为自动驾驶汽车感知子系统中的一项关键任务。然而,两个关键挑战仍然需要解决:1)尽可能多地利用各种训练数据; 2)将可识别类的数量从几十个增加到几乎任何场景可以包含的内容。
在这项工作中,为了解决这两个挑战,我们积极采取措施并提出一种方法,利用具有不同类和注释类型的多个异构数据集,来训练一个完全卷积网络进行每个像素语义分割。这种方法有助于更好地使用可用数据集,从而减少注释工作量,并增加可识别的类的数量。我们在高度自动驾驶(HAD)环境中使用的数据集是Cityscapes[3],Mapillary Vistas [4]和GTSDB [5]。
第一个挑战,即对具有不同注释的语义分段的训练,在先前的工作[6][7]中一般会通过外部组件到网络中进行处理,以便生成伪的每个像素基础事实。相比之下,我们的方法是自包含的,使用网络自身的输出来细化不兼容的、多样的注释以进行监督。
第二个挑战,即增加可识别类的数量,可以通过两种方式来完成: 1 )用额外(子)类(例如[8] )继续按像素注释现有数据集;2 )仅对新(子)类使用现有辅助数据集。第一种方法对于大数据集来说可能非常昂贵,并且是不必要的,因为存在大量具有细粒度(子)类的数据集(例如交通标志类型、汽车模型、行人)。
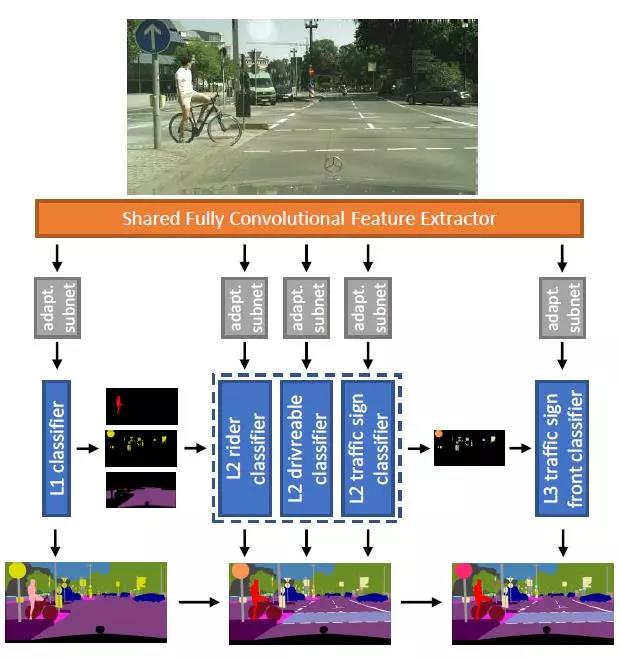
图1.我们在推理过程中的层次分类卷积网络。输入图像被转换为共享特征表示,其通过适配子网连接到分类器的层次结构。Level-1分类器输出对图像的每个像素的预测,而每个后续分类器仅推断其自己的一组类。将所有级别的输出进行组合,形成最终的细粒度每像素分割。
在我们的工作中,我们研究的是第二种方法。为此,数据集的异质性(即不同的标签空间和注释类型)对于将它们与传统的“平面”(即非分层的)分类器组合提出了挑战。因此,我们建议使用分层分类器,它明确地利用数据集之间的语义关系,并与平面分类器进行比较。我们的层次结构与[9][10]相当,但它提供的可扩展性不同。
在第二节,我们描述了我们的分层方法所解决的确切挑战。一个例子是Cityscapes和GTSDB的综合培训。在这种情况下,所有GTSDB类都是Cityscapes中交通标志类的子类。在传统的平面分类器中直接结合两个数据集的类的简单方法是不可行的,因为一个交通标志像素不能根据它来自的数据集有不同的标签。这给平面分类器的端到端训练和推理带来了挑战,而我们的分级分类方案可以解决这些挑战。
第三节我们提供了一般分层方法的基本原理;第四节我们提供了实施的细节;在第五节,我们演示了使用三个异构数据集的层次分类器的性能增益,而不是使用平面的、非层次的分类器。此外,我们展示了使用我们提出的方法可对公共特征表示进行多数据集训练可以提高所有数据集的性能,而不管它们的结构差异如何。
综上所述,本研究对每个像素语义分割的贡献如下:
一种对数据集进行组合训练的方法,该数据集具有分离但语义相连的标签空间。
分层分类器的模块化体系结构,可以取代现代卷积网络中的分类阶段。
我们的系统实施可供研究界[11]使用。此外,我们为GTSDB交通标志子类提供了Cityscapes数据集的每个像素注释,我们将其用于验证目的,但不需要进行训练。在本文中,我们将此数据集称为Cityscapes Extended。
第二节,来自多个数据集训练的挑战
由于数据集的结构差异,对多个数据集的端到端监督训练可能面临许多挑战。其中最重要的挑战可分为以下几类:
语义层面的细节:每个数据集都标有一组语义类。在朴素平面分类方法中,分类器的输出将是来自所有数据集的类的联合。一个数据集中的类的语义很可能包含在另一个数据集的类的语义中。如果这些类被放置在相同的级别上,就像在平面分类器中一样,则会发生监督冲突,因为属于同一语义类的一些像素将被标记为不同的类。
对于我们的三个数据集来说,这一挑战出现在三种情况下: 1 ) Cityscapes将其道路等级定义为“汽车通常行驶的部分地面”,包括车道标记、自行车道、坑洼等。在Vistas中,除了道路类之外,这些细粒度的子类被单独标记,导致标签的语义细节层次的冲突。2)Cityscapes和Vistas包含一个高级交通标志类,而GTSDB有43个交通标志子类。3)Cityscapes只有一个骑手类,而Vistas区分三个不同的骑手子类。如图2所示,引入标签层次结构有效地解决了这一挑战,将在第三节A部分中更详细地讨论。
注释类型:根据定义,语义分割是每个像素的问题,因此必须在像素级提供监督。不幸的是,许多现有数据集具有边界框或每个图像注释,这对于每个像素训练是不兼容的。使它们兼容的直接方法是将这些注释转换为掩码。然而,这些掩码将包括不属于感兴趣对象的像素,例如,边界框可能包含许多非相关的背景像素,这些像素将被分配给前台类。最终,在训练期间,对网络的监督将从错误标记的像素流出,导致权重混乱。
在我们的例子中,Cityscapes和Vistas有每个像素注释,但GTSDB只有边界框注释。为了将GTSDB包含在训练中,我们提出了一种新的层次损失,它在第三节的D部分中提供,统一处理来自不同注释类型的监督。
训练样本不平衡:批量训练受到类别不平衡的影响,特别是当每批次的例子有限时。在我们的例子中,我们面临着强大的数据集内和数据集间的不平衡。数据集之间的不平衡是由于注释像素的巨大差异造成的,例如,以103的顺序(详见表一)。相同数据集的类之间的不平衡在街道场景数据集中是常见的,因为大多数像素都属于大型表面的类,比如道路和建筑物。我们的方法通过在相同的分类器中放置具有相似的示例顺序的类来处理不平衡,因此所有类具有更大的概率在同一批次中表示。这种策略非常有益,如第五节的E部分有所展示。
第三节,利用语义层次结构培养和推断异构数据集
在本节中,我们描述了针对任意数量的异构数据集的一般分层分类方法的组件。这些组件为第二节的挑战提供了解决方案,并为每一个组件提供了我们所选择的数据集的具体情况。我们目前的实验,详见第五节,是基于使用3个数据集的具有3级层次结构的实现。第四节中提供了此实现的细节。
A.标签空间的语义层次结构
多个数据集训练需要为所有选定的数据集提供一个公共标签空间。我们建议将单独的标签空间合并到公共空间中,其中包含来自所有数据集的标签,通过分层的方式合并到标签的语义树中。这种方法通过引入必要的父节点或中间节点和/或现有标签的分组来解决标签语义定义中的任何冲突。
图2描绘了使用本文三个选定数据集的所有标签的3级层次结构。第二节中介绍了将这三个标签空间组合起来所带来的挑战,解决办法如下: 1)引入了一个新的高级驱动类来解决Cityscapes和Vistas道路类语义冲突,2)增加了一类超级交通标志和一个中间节点,用于区分Vistas和前方交通标志,3)引入了一个骑手超类,包括Cityscapes骑手类和3 Vistas骑手子类。
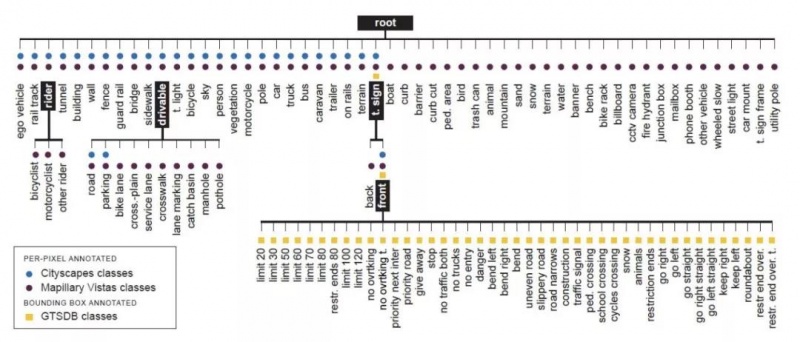
图2.三级语义标签层次结构,结合了来自Cityscapes,Mapillary Vistas和GTSDB数据集的108个类。标记为黑色的类别对应于图1的L1,L2和L3分类器。
标签的语义层次结构引起相应的分类器层次结构。每个分类器都对一个节点的子标签进行分类,并且对整个分类器树进行训练,以一种端到端、完全卷积的方式对共享的特性表示进行训练。
B .卷积网络体系结构
所提出的网络架构(例如,参见图1)包括用于计算密集的共享表示的完全卷积特征提取器和一组分类器,每个分类器对应于语义层次的内部类节点。每个分类器都可以与层次结构中一级向下的分类器连接,以便将其预测传递给推理和注释类型独立训练,如第三节中C\D部分所述。每个分类器之前可以有一个浅适应网络,它使共同表征、深度和接受域适应分类器的需要。这使网络设计人员有机会为每个分类器选择不同的特性维度和接受域。例如,区别交通标志比较容易[12],因为与高级别区别相比,需要较少的特征,如道路对人行道和灌木丛对树木[ 3 ]。根据分类器的对象平均大小,将不同的视图字段应用到不同的分类器上具有一定的灵活性,可以或多或少的实现上下文聚合,例如,交通标志通常比建筑物或汽车更小。
C.推理:分层决策规则
在softmax分类器树中,以分层方式按像素进行推断。为自己的一组像素集p∈Pj和一组类Cj= {0,1….}每个分类器j计算类概率的每个像素的归一化向量σj,p,以及输出每像素的决定
yj,p^=argmaxiσij,p,这里yj,p^∈Cj。这一组每个分类器都必须为此做出决定的Pj,由其父代根据自己的决定生成。来自可用的标签集{y^j,p}j∈J,输入的每个像素都标有所需的细节,其中J是为这个特定像素生成决策的分类器。
D.训练:等级分类损失
如第二节所述,许多数据集的注释类型与语义分割所需的每个像素监督是不兼容的。我们提出的方法是使用统一的方法处理不兼容的注释,不需要外部组件,如[6][7],并且对系统的计算负荷可以忽略不计。处理各种基本事实的灵活性与根分类器上的类的唯一约束交换,应该具有每个像素注释的示例。任何其他级别的注释可以是任何类型的,甚至可以是混合的。
我们提出了分级分类损失,它将监视与像素级的注释类型分离开来。每个分类器j在所有标记像素Pj=Pj1 +PJ2上训练,所述标记像素对应于标签层级中的其相应节点。使用标准的单热交叉熵损失训练具有每个像素注释的像素Pj1。为了实现这一点,我们的方法在训练过程中使用父分类器的在线、每个像素的决定,来细化伪每个像素的标签。该过程如图3所示。首先,将不兼容的注释转换为每个像素伪地面实况。
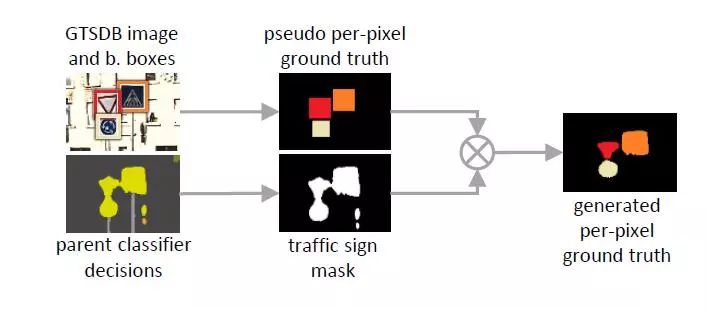
图3.训练期间的在线程序,用于从边界框标签生成每像素地面实况。
然后,在每个训练步骤中,父分类器的决定与该伪基础事实相交,以产生用于监督的每像素地面实况。
两种损失都按照分类器累积到所谓的等级损失:

其中|·|是像素集的基数,并且yj,p∈Cj为分类器j选择对应于像素p的地真类的σ元素。最后,收集所有分类器的损失并用不同的超参数j加权,以获得最小化的总目标:
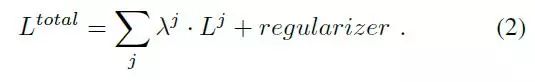
第四节,具有CITYSCAPES,MAPILLARYVISTAS和GTSDB的的三级标签层次结构
在本节中,我们概述了实现细节,以提高我们实验的可重复性。
卷积网络架构:网络如图1所示。特征提取器由ResNet- 50架构[ 13 ]的特征层和1 x1卷积层(具有ReLU和批处理规范化)组成,以将特征维数减少到256。使用扩张的卷积,输入上的步幅从32减小到8。该表示具有深度256,空间维度1/8的输入,并在5个分支中共享。每个分支都有一个额外的瓶颈模块[ 13 ],并以一个softmax分类器结束,该分类器包括一个混合上采样模块。我们选择每个分类器适配子网的特征维度和视野对于所有分支是相同的。在实验了不同的上行采样技术(分步卷积、双线性、卷积)后,我们得出结论,通过混合上采样获得最佳性能和减少伪像,其中包括一个2x2可学习的分数跨度卷积层,然后是双线性上采样以达到输入维度。
实施细节:我们使用Tensorflow[14]和Titan X(Pascal架构)GPU进行训练和推理。由于内存有限,我们将批量大小设置为4(Cityscapes:Vistas:GTSDB = 1:2:1),将训练尺寸设置为512x706(Vistas图像的平均值缩放到较小的Cityscapes维度)。在训练期间,按照原长宽比缩小图像,然后随机裁剪。该网络针对17个Vistas时期(早期停止)进行训练,,随机梯度下降,动量为0.9,L2权重正则化,衰减为0.00017,初始学习率为0.01,三次减半,批量标准化和指数移动平均衰减均设为0.9。将Eq的超参数λj分别选择为1.0、0.1和0.1,分别用于三个层次的层次结构。作为推论,我们目前达到17 fps的帧速率,即每帧58毫秒。
第五节,评价
我们进行以下实验来评估我们的分级分类方法:
1 )平面分类基线:设置用于单数据集和多数据集训练的平面分类器基线。
2 )三个异构数据集的分层分类: 演示了我们的完整方法在三个异构数据集(Cityscapes、GTSDB、Vistas )上进行组合训练的好处,这些数据集具有不相交的标签空间和不同的注释类型。
3)Cityscapes Extended上的分层与平面分类:通过在具有两级标签空间的每像素注释Cityscapes Extended数据集上隔离它来验证我们的分层方法对极不平衡类的有效性。
A.数据集
我们总结了表I中使用的数据集。接下来,我们将描述实验所需的额外注释。请注意,这些注释仅用于验证目的,而不用于训练网络。
1)用交通标志类标记城市景观:我们使用GTSDB的43个交通标志类扩展了Cityscapes的标签空间。Cityscapes只提供每个像素的交通标志注释,而不区分实例。我们设计了一种基于8邻域距离的自动分割算法,用于分离地面真实交通标志遮罩中连接的交通标志实例,并设计了一个GUI应用程序,提出了用于标注的图像区域。我们把原来的和新的注释打包成Cityscapes Extended的名字。该数据集分别包含列车中的2778个和380个交通标志以及验证拆分。
2)用每个像素标签标注GTSDB:只有在涉及平面分类器的特定实验中,我们才使用交通标志形状(圆形、三角形、六边形)将GTSDB边界框注释转换为精细的每个像素注释。这个程序对于交通标志的面内旋转可能是有问题的,但是在数据集检查之后,我们观察到只有很少的面内旋转存在。
表一
数据集统计。图像包含训练和验证拆分。在括号中显示了被评估的类的数量。

表二
对每个像素注释数据集的平面分类性能基线。
B.度量和评估惯例
我们使用多类平均像素精度(mPA)和联合的平均交叉点(mIoU),它们与自动驾驶相关,它们代表了先进的地方和地区的标准,遵循了[ 15 ]中给出的定义。对于Cityscapes,我们报告了27个课程的结果(官方基准测试中的19个和Vistas中常见的8个)。对于交通标志类,我们评估满足两种条件的43个交通标志的子集:1 )在GTSDB训练集中具有少于103个像素。2) GTSDB和Cityscapes扩展验证集的像素都小于103像素。请注意,我们选择了103像素的限值,因为它比Cityscapes中最少代表的类要小2个数量级。对于Vistas,我们报告关于官方65级基准的结果。最后,我们每隔一个时期评估模型的性能,并报告最近两次运行的平均值。
本文介绍了一种新的公平比较评价的协议,该协议仅适用于第五节的C部分的实验,该实验是在两个数据集上训练平面分类器。它解决了高级别交通符号类与交通符号子类相同级别的语义冲突(第二节)。交通标志像素的判定是正确的:1)如果正确标注了任何交通标志子类, 2)如果它被标记为交通标志,第二个最可能的选择是正确的交通标志子类。为清楚起见,我们不将此评估方案用于分层分类器,而仅用于扁平分类器。
C.平面分类的基线
在表二中,我们为传统的平面分类方法设置了相同和跨数据集的基线,使用第四节中描述的实现细节中相同的输入维度和批量大小,为了能够与表三的分层结果进行公平比较。在第1 – 3列中,我们在三个数据集上独立训练三个模型,并为表一的评估类提供结果。在第4栏中,我们提供了联合训练Cityscapes和GTSDB的Cityscapes Extended交叉数据集结果。
为了进行公平的比较,第3和第4列的模型是通过GTSDB数据集的生成的每个像素注释来训练的(详细细节请参见第五节A2部分)。由于每个图像的训练像素数量有限,因此43类GTSDB的训练不会收敛,因此我们将未标记的像素作为额外的类包括在内,以解决此问题。可以观察到,Cityscapes和GTSDB的同时训练未能在Cityscapes Extended的交通标志类别上获得令人满意的跨数据集结果。
表三
4种数据集中完全分层分类方法的表现。

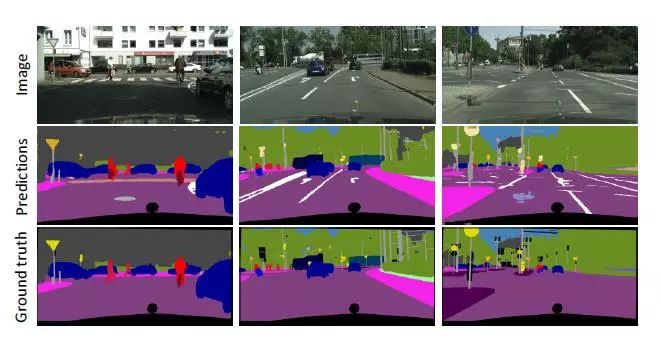
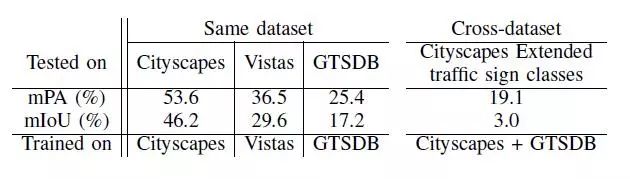
图4.Cityscapes val拆分图像示例。网络预测包括来自层次结构的L1-L3级别的决策。请注意,地面实况仅包括一个交通标志超类(黄色)且没有道路属性标记。
D. 3个异构数据集的层次分类
该实验评估了我们在三个异构数据集(Cityscapes,Mapillary Vistas和GTSDB)上的完整层次分类方法。在表三中,我们提供了关于模型训练的三个数据集的验证分割的评估结果(第1-3列)和Cityscapes Extended(第4列)上的交通标志子类的结果,这在训练期间未使用。在图4、5、6中描述了定性结果。
对于所有数据集,通过比较表二第1-3列和表三第1-3列,我们实现了平均PA(在+ 2.4%至+ 32.3%范围内)和IoU(在+ 2.3%至+ 24.3%范围内)的显着性能提升。通过比较表二第4列和表三第4列,我们还观察到交通标志子类的交叉数据集性能的增加。值得注意的是,该模型未经过Cityscapes Extended交通标志类别的任何示例训练,平均PA增加10.6%仅仅是由于我们的分层多数据集训练方案的结果。我们得出结论,当数据集具有不同的类,不同的注释类型以及数据集内和数据集之间的不平衡时,层次分类对于组合的异构数据集训练非常有利。
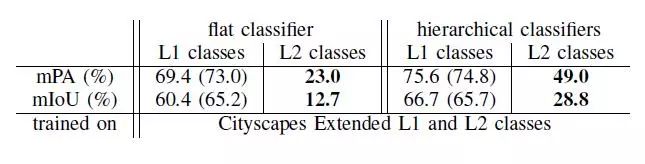
E. Cityscapes Extended的层次分类与平面分类
在本实验中,我们使用每像素注释和两级标签空间评估Cityscapes Extended上的层次分类方法。我们的目标是将我们的方法隔离在一个数据集中,以显示它在高度不平衡的数据集中对平面分类的有效性。我们使用512 x 1024输入尺寸,批量为2。
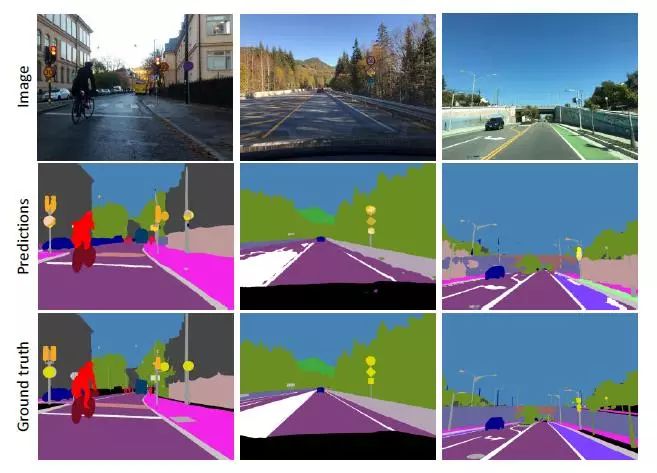
图5.Mapillary Vistas验证分割图像示例。网络预测包括来自层次结构的L1-L3级别的决策。请注意,基本事实不包括交通标志子类。
图6.GTSDB测试分割图像示例。网络预测包括来自层次结构的L1-L3级别的决策。请注意,基本事实仅包括交通标志边界框,因为其余像素未标记。
从表IV中,我们观察到相对于平面分类器的mPA(+ 26.0%)和mIoU(+ 16.1%)层次分类显着增加了L2类(即GTSDB交通标志子类),而对于L1类(即Cityscapes类) mPA和IoU的增幅均超过+ 6%。
我们得出的结论是,即使是在单个数据集中使用每个像素的注释,分层分类对于类的不平衡是稳健的,因为它在每个级别的类中都有相同的示例顺序。
表四
在Cityscapes Extended上的平面与建议的分级分类性能。(在括号内表现为交通标志L1类)。
第六节,结论与未来工作
在本论文中,我们考虑了对三个异构但语义相连的数据集进行同时训练的挑战,以解决每个像素的语义分割问题。主要动机是最大限度地重用资源(数据集和计算)并消除人类标记工作。为了实现这一点,我们利用数据集标签之间的语义关系来构建分类器的层次结构,并介绍相应的分层训练和推理规则。我们最终的网络可以将一个输入图像从8个高级的街道场景类别中分成108个类。结果表明,采用层次分类方法进行多异构数据集训练具有明显的优越性。在未来的工作中,我们将扩展我们的成果,包括更多具有更多不同特征的数据集,以展示我们方法的可扩展性。
【REFERENCES】
[1] J. Janai, F. G¨uney, A. Behl, and A.Geiger, “Computer vision for autonomous vehicles: Problems, datasets andstate-of-the-art,” CoRR, vol. abs/1704.05519, 2017.
[2] B. Zhao, J. Feng, X. Wu, and S. Yan, “Asurvey on deep learningbased fine-grained object classification and semanticsegmentation,” International Journal of Automation and Computing, vol. 14, no.2, pp. 119–135, Apr 2017.
[3] M. Cordts, M. Omran, S. Ramos, T. Rehfeld,M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapesdataset for semantic urban scene understanding,” in Proc. of the IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2016.
[4] G. Neuhold, T. Ollmann, S. R. Bul`o,and P. Kontschieder, “The mapillary vistas dataset for semantic understandingof street scenes,” in Proceedings of the International Conference on ComputerVision (ICCV), Venice, Italy, 2017, pp. 22–29.
[5] S. Houben, J. Stallkamp, J. Salmen, M.Schlipsing, and C. Igel, “Detection of traffic signs in real-world images: The german traffic signdetection benchmark,” in Neural Networks (IJCNN). IEEE, 2013.
[6] L. Ye, Z. Liu, and Y. Wang, “LearningSemantic Segmentation with Diverse Supervision,” arXiv preprintarXiv:1802.00509, Feb. 2018.
[7] G. Papandreou, L.-C. Chen, K. P. Murphy,and A. L. Yuille, “Weaklyand semi-supervised learning of a deep convolutionalnetwork for semantic image segmentation,” in Computer Vision (ICCV), 2015 IEEE InternationalConference on. IEEE, 2015, pp. 1742–1750.
[8] A. Petrovai, A. D. Costea, and S. Nedevschi,“Semi-automatic image annotation of street scenes,” in Intelligent VehiclesSymposium (IV), 2017 IEEE. IEEE, 2017, pp. 448–455.
[9] J. Zhou, Z. Zhou, and L. Zhang, “Hierarchicalsemantic classification and attribute relations analysis with clothing regiondetection,” in Advanced Multimedia and Ubiquitous Engineering. Springer, 2016.
[10] X. Mao, S. Hijazi, R. Casas, P. Kaul,R. Kumar, and C. Rowen, “Hierarchical cnn for traffic sign recognition,” in IntelligentVehicles Symposium (IV), 2016 IEEE. IEEE, 2016, pp. 130–135.
[11] “Full implementation code for training,evaluation and inference, and the extra annotated datasets will be madepublicly available at
https://github.com/pmeletis/hierarchical-semantic-segmentation.”
[12] D. Ciregan, U. Meier, and J. Schmidhuber,“Multi-column deep neural networks for image classification,” in ComputerVision and Pattern Recognition (CVPR). IEEE, 2012, pp. 3642–3649.
[13] K. He, X. Zhang, S. Ren, and J. Sun,“Deep residual learning for image recognition,” in Proceedings of the IEEEconference on computer vision and pattern recognition, 2016, pp. 770–778.
[14] M. Abadi, A. Agarwal, P. Barham, E.Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al.,“Tensorflow: Largescale machine learning on heterogeneous distributed systems,”arXiv preprint arXiv:1603.04467, 2016.
[15] A. Garcia-Garcia, S. Orts-Escolano, S.Oprea, V. Villena-Martinez, and J. Garcia-Rodriguez, “A review on deep learningtechniques applied to semantic segmentation,” arXiv preprint arXiv:1704.06857,2017.
作者:Panagiotis Meletis and Gijs Dubbelman
第一节,介绍:
随着深度学习技术的发展,按照像素分类提出的分割任务在过去几年中取得了很大进展[2],语义分类成为自动驾驶汽车感知子系统中的一项关键任务。然而,两个关键挑战仍然需要解决:1)尽可能多地利用各种训练数据; 2)将可识别类的数量从几十个增加到几乎任何场景可以包含的内容。
在这项工作中,为了解决这两个挑战,我们积极采取措施并提出一种方法,利用具有不同类和注释类型的多个异构数据集,来训练一个完全卷积网络进行每个像素语义分割。这种方法有助于更好地使用可用数据集,从而减少注释工作量,并增加可识别的类的数量。我们在高度自动驾驶(HAD)环境中使用的数据集是Cityscapes[3],Mapillary Vistas [4]和GTSDB [5]。
第一个挑战,即对具有不同注释的语义分段的训练,在先前的工作[6][7]中一般会通过外部组件到网络中进行处理,以便生成伪的每个像素基础事实。相比之下,我们的方法是自包含的,使用网络自身的输出来细化不兼容的、多样的注释以进行监督。
第二个挑战,即增加可识别类的数量,可以通过两种方式来完成: 1 )用额外(子)类(例如[8] )继续按像素注释现有数据集;2 )仅对新(子)类使用现有辅助数据集。第一种方法对于大数据集来说可能非常昂贵,并且是不必要的,因为存在大量具有细粒度(子)类的数据集(例如交通标志类型、汽车模型、行人)。
图1.我们在推理过程中的层次分类卷积网络。输入图像被转换为共享特征表示,其通过适配子网连接到分类器的层次结构。Level-1分类器输出对图像的每个像素的预测,而每个后续分类器仅推断其自己的一组类。将所有级别的输出进行组合,形成最终的细粒度每像素分割。
在我们的工作中,我们研究的是第二种方法。为此,数据集的异质性(即不同的标签空间和注释类型)对于将它们与传统的“平面”(即非分层的)分类器组合提出了挑战。因此,我们建议使用分层分类器,它明确地利用数据集之间的语义关系,并与平面分类器进行比较。我们的层次结构与[9][10]相当,但它提供的可扩展性不同。
在第二节,我们描述了我们的分层方法所解决的确切挑战。一个例子是Cityscapes和GTSDB的综合培训。在这种情况下,所有GTSDB类都是Cityscapes中交通标志类的子类。在传统的平面分类器中直接结合两个数据集的类的简单方法是不可行的,因为一个交通标志像素不能根据它来自的数据集有不同的标签。这给平面分类器的端到端训练和推理带来了挑战,而我们的分级分类方案可以解决这些挑战。
第三节我们提供了一般分层方法的基本原理;第四节我们提供了实施的细节;在第五节,我们演示了使用三个异构数据集的层次分类器的性能增益,而不是使用平面的、非层次的分类器。此外,我们展示了使用我们提出的方法可对公共特征表示进行多数据集训练可以提高所有数据集的性能,而不管它们的结构差异如何。
综上所述,本研究对每个像素语义分割的贡献如下:
一种对数据集进行组合训练的方法,该数据集具有分离但语义相连的标签空间。
分层分类器的模块化体系结构,可以取代现代卷积网络中的分类阶段。
我们的系统实施可供研究界[11]使用。此外,我们为GTSDB交通标志子类提供了Cityscapes数据集的每个像素注释,我们将其用于验证目的,但不需要进行训练。在本文中,我们将此数据集称为Cityscapes Extended。
第二节,来自多个数据集训练的挑战
由于数据集的结构差异,对多个数据集的端到端监督训练可能面临许多挑战。其中最重要的挑战可分为以下几类:
语义层面的细节:每个数据集都标有一组语义类。在朴素平面分类方法中,分类器的输出将是来自所有数据集的类的联合。一个数据集中的类的语义很可能包含在另一个数据集的类的语义中。如果这些类被放置在相同的级别上,就像在平面分类器中一样,则会发生监督冲突,因为属于同一语义类的一些像素将被标记为不同的类。
对于我们的三个数据集来说,这一挑战出现在三种情况下: 1 ) Cityscapes将其道路等级定义为“汽车通常行驶的部分地面”,包括车道标记、自行车道、坑洼等。在Vistas中,除了道路类之外,这些细粒度的子类被单独标记,导致标签的语义细节层次的冲突。2)Cityscapes和Vistas包含一个高级交通标志类,而GTSDB有43个交通标志子类。3)Cityscapes只有一个骑手类,而Vistas区分三个不同的骑手子类。如图2所示,引入标签层次结构有效地解决了这一挑战,将在第三节A部分中更详细地讨论。
注释类型:根据定义,语义分割是每个像素的问题,因此必须在像素级提供监督。不幸的是,许多现有数据集具有边界框或每个图像注释,这对于每个像素训练是不兼容的。使它们兼容的直接方法是将这些注释转换为掩码。然而,这些掩码将包括不属于感兴趣对象的像素,例如,边界框可能包含许多非相关的背景像素,这些像素将被分配给前台类。最终,在训练期间,对网络的监督将从错误标记的像素流出,导致权重混乱。
在我们的例子中,Cityscapes和Vistas有每个像素注释,但GTSDB只有边界框注释。为了将GTSDB包含在训练中,我们提出了一种新的层次损失,它在第三节的D部分中提供,统一处理来自不同注释类型的监督。
训练样本不平衡:批量训练受到类别不平衡的影响,特别是当每批次的例子有限时。在我们的例子中,我们面临着强大的数据集内和数据集间的不平衡。数据集之间的不平衡是由于注释像素的巨大差异造成的,例如,以103的顺序(详见表一)。相同数据集的类之间的不平衡在街道场景数据集中是常见的,因为大多数像素都属于大型表面的类,比如道路和建筑物。我们的方法通过在相同的分类器中放置具有相似的示例顺序的类来处理不平衡,因此所有类具有更大的概率在同一批次中表示。这种策略非常有益,如第五节的E部分有所展示。
第三节,利用语义层次结构培养和推断异构数据集
在本节中,我们描述了针对任意数量的异构数据集的一般分层分类方法的组件。这些组件为第二节的挑战提供了解决方案,并为每一个组件提供了我们所选择的数据集的具体情况。我们目前的实验,详见第五节,是基于使用3个数据集的具有3级层次结构的实现。第四节中提供了此实现的细节。
A.标签空间的语义层次结构
多个数据集训练需要为所有选定的数据集提供一个公共标签空间。我们建议将单独的标签空间合并到公共空间中,其中包含来自所有数据集的标签,通过分层的方式合并到标签的语义树中。这种方法通过引入必要的父节点或中间节点和/或现有标签的分组来解决标签语义定义中的任何冲突。
图2描绘了使用本文三个选定数据集的所有标签的3级层次结构。第二节中介绍了将这三个标签空间组合起来所带来的挑战,解决办法如下: 1)引入了一个新的高级驱动类来解决Cityscapes和Vistas道路类语义冲突,2)增加了一类超级交通标志和一个中间节点,用于区分Vistas和前方交通标志,3)引入了一个骑手超类,包括Cityscapes骑手类和3 Vistas骑手子类。
图2.三级语义标签层次结构,结合了来自Cityscapes,Mapillary Vistas和GTSDB数据集的108个类。标记为黑色的类别对应于图1的L1,L2和L3分类器。
标签的语义层次结构引起相应的分类器层次结构。每个分类器都对一个节点的子标签进行分类,并且对整个分类器树进行训练,以一种端到端、完全卷积的方式对共享的特性表示进行训练。
B .卷积网络体系结构
所提出的网络架构(例如,参见图1)包括用于计算密集的共享表示的完全卷积特征提取器和一组分类器,每个分类器对应于语义层次的内部类节点。每个分类器都可以与层次结构中一级向下的分类器连接,以便将其预测传递给推理和注释类型独立训练,如第三节中C\D部分所述。每个分类器之前可以有一个浅适应网络,它使共同表征、深度和接受域适应分类器的需要。这使网络设计人员有机会为每个分类器选择不同的特性维度和接受域。例如,区别交通标志比较容易[12],因为与高级别区别相比,需要较少的特征,如道路对人行道和灌木丛对树木[ 3 ]。根据分类器的对象平均大小,将不同的视图字段应用到不同的分类器上具有一定的灵活性,可以或多或少的实现上下文聚合,例如,交通标志通常比建筑物或汽车更小。
C.推理:分层决策规则
在softmax分类器树中,以分层方式按像素进行推断。为自己的一组像素集p∈Pj和一组类Cj= {0,1….}每个分类器j计算类概率的每个像素的归一化向量σj,p,以及输出每像素的决定
yj,p^=argmaxiσij,p,这里yj,p^∈Cj。这一组每个分类器都必须为此做出决定的Pj,由其父代根据自己的决定生成。来自可用的标签集{y^j,p}j∈J,输入的每个像素都标有所需的细节,其中J是为这个特定像素生成决策的分类器。
D.训练:等级分类损失
如第二节所述,许多数据集的注释类型与语义分割所需的每个像素监督是不兼容的。我们提出的方法是使用统一的方法处理不兼容的注释,不需要外部组件,如[6][7],并且对系统的计算负荷可以忽略不计。处理各种基本事实的灵活性与根分类器上的类的唯一约束交换,应该具有每个像素注释的示例。任何其他级别的注释可以是任何类型的,甚至可以是混合的。
我们提出了分级分类损失,它将监视与像素级的注释类型分离开来。每个分类器j在所有标记像素Pj=Pj1 +PJ2上训练,所述标记像素对应于标签层级中的其相应节点。使用标准的单热交叉熵损失训练具有每个像素注释的像素Pj1。为了实现这一点,我们的方法在训练过程中使用父分类器的在线、每个像素的决定,来细化伪每个像素的标签。该过程如图3所示。首先,将不兼容的注释转换为每个像素伪地面实况。
图3.训练期间的在线程序,用于从边界框标签生成每像素地面实况。
然后,在每个训练步骤中,父分类器的决定与该伪基础事实相交,以产生用于监督的每像素地面实况。
两种损失都按照分类器累积到所谓的等级损失:
其中|·|是像素集的基数,并且yj,p∈Cj为分类器j选择对应于像素p的地真类的σ元素。最后,收集所有分类器的损失并用不同的超参数j加权,以获得最小化的总目标:
第四节,具有CITYSCAPES,MAPILLARYVISTAS和GTSDB的的三级标签层次结构
在本节中,我们概述了实现细节,以提高我们实验的可重复性。
卷积网络架构:网络如图1所示。特征提取器由ResNet- 50架构[ 13 ]的特征层和1 x1卷积层(具有ReLU和批处理规范化)组成,以将特征维数减少到256。使用扩张的卷积,输入上的步幅从32减小到8。该表示具有深度256,空间维度1/8的输入,并在5个分支中共享。每个分支都有一个额外的瓶颈模块[ 13 ],并以一个softmax分类器结束,该分类器包括一个混合上采样模块。我们选择每个分类器适配子网的特征维度和视野对于所有分支是相同的。在实验了不同的上行采样技术(分步卷积、双线性、卷积)后,我们得出结论,通过混合上采样获得最佳性能和减少伪像,其中包括一个2x2可学习的分数跨度卷积层,然后是双线性上采样以达到输入维度。
实施细节:我们使用Tensorflow[14]和Titan X(Pascal架构)GPU进行训练和推理。由于内存有限,我们将批量大小设置为4(Cityscapes:Vistas:GTSDB = 1:2:1),将训练尺寸设置为512x706(Vistas图像的平均值缩放到较小的Cityscapes维度)。在训练期间,按照原长宽比缩小图像,然后随机裁剪。该网络针对17个Vistas时期(早期停止)进行训练,,随机梯度下降,动量为0.9,L2权重正则化,衰减为0.00017,初始学习率为0.01,三次减半,批量标准化和指数移动平均衰减均设为0.9。将Eq的超参数λj分别选择为1.0、0.1和0.1,分别用于三个层次的层次结构。作为推论,我们目前达到17 fps的帧速率,即每帧58毫秒。
第五节,评价
我们进行以下实验来评估我们的分级分类方法:
1 )平面分类基线:设置用于单数据集和多数据集训练的平面分类器基线。
2 )三个异构数据集的分层分类: 演示了我们的完整方法在三个异构数据集(Cityscapes、GTSDB、Vistas )上进行组合训练的好处,这些数据集具有不相交的标签空间和不同的注释类型。
3)Cityscapes Extended上的分层与平面分类:通过在具有两级标签空间的每像素注释Cityscapes Extended数据集上隔离它来验证我们的分层方法对极不平衡类的有效性。
A.数据集
我们总结了表I中使用的数据集。接下来,我们将描述实验所需的额外注释。请注意,这些注释仅用于验证目的,而不用于训练网络。
1)用交通标志类标记城市景观:我们使用GTSDB的43个交通标志类扩展了Cityscapes的标签空间。Cityscapes只提供每个像素的交通标志注释,而不区分实例。我们设计了一种基于8邻域距离的自动分割算法,用于分离地面真实交通标志遮罩中连接的交通标志实例,并设计了一个GUI应用程序,提出了用于标注的图像区域。我们把原来的和新的注释打包成Cityscapes Extended的名字。该数据集分别包含列车中的2778个和380个交通标志以及验证拆分。
2)用每个像素标签标注GTSDB:只有在涉及平面分类器的特定实验中,我们才使用交通标志形状(圆形、三角形、六边形)将GTSDB边界框注释转换为精细的每个像素注释。这个程序对于交通标志的面内旋转可能是有问题的,但是在数据集检查之后,我们观察到只有很少的面内旋转存在。
表一
数据集统计。图像包含训练和验证拆分。在括号中显示了被评估的类的数量。
表二
对每个像素注释数据集的平面分类性能基线。
B.度量和评估惯例
我们使用多类平均像素精度(mPA)和联合的平均交叉点(mIoU),它们与自动驾驶相关,它们代表了先进的地方和地区的标准,遵循了[ 15 ]中给出的定义。对于Cityscapes,我们报告了27个课程的结果(官方基准测试中的19个和Vistas中常见的8个)。对于交通标志类,我们评估满足两种条件的43个交通标志的子集:1 )在GTSDB训练集中具有少于103个像素。2) GTSDB和Cityscapes扩展验证集的像素都小于103像素。请注意,我们选择了103像素的限值,因为它比Cityscapes中最少代表的类要小2个数量级。对于Vistas,我们报告关于官方65级基准的结果。最后,我们每隔一个时期评估模型的性能,并报告最近两次运行的平均值。
本文介绍了一种新的公平比较评价的协议,该协议仅适用于第五节的C部分的实验,该实验是在两个数据集上训练平面分类器。它解决了高级别交通符号类与交通符号子类相同级别的语义冲突(第二节)。交通标志像素的判定是正确的:1)如果正确标注了任何交通标志子类, 2)如果它被标记为交通标志,第二个最可能的选择是正确的交通标志子类。为清楚起见,我们不将此评估方案用于分层分类器,而仅用于扁平分类器。
C.平面分类的基线
在表二中,我们为传统的平面分类方法设置了相同和跨数据集的基线,使用第四节中描述的实现细节中相同的输入维度和批量大小,为了能够与表三的分层结果进行公平比较。在第1 – 3列中,我们在三个数据集上独立训练三个模型,并为表一的评估类提供结果。在第4栏中,我们提供了联合训练Cityscapes和GTSDB的Cityscapes Extended交叉数据集结果。
为了进行公平的比较,第3和第4列的模型是通过GTSDB数据集的生成的每个像素注释来训练的(详细细节请参见第五节A2部分)。由于每个图像的训练像素数量有限,因此43类GTSDB的训练不会收敛,因此我们将未标记的像素作为额外的类包括在内,以解决此问题。可以观察到,Cityscapes和GTSDB的同时训练未能在Cityscapes Extended的交通标志类别上获得令人满意的跨数据集结果。
表三
4种数据集中完全分层分类方法的表现。
图4.Cityscapes val拆分图像示例。网络预测包括来自层次结构的L1-L3级别的决策。请注意,地面实况仅包括一个交通标志超类(黄色)且没有道路属性标记。
D. 3个异构数据集的层次分类
该实验评估了我们在三个异构数据集(Cityscapes,Mapillary Vistas和GTSDB)上的完整层次分类方法。在表三中,我们提供了关于模型训练的三个数据集的验证分割的评估结果(第1-3列)和Cityscapes Extended(第4列)上的交通标志子类的结果,这在训练期间未使用。在图4、5、6中描述了定性结果。
对于所有数据集,通过比较表二第1-3列和表三第1-3列,我们实现了平均PA(在+ 2.4%至+ 32.3%范围内)和IoU(在+ 2.3%至+ 24.3%范围内)的显着性能提升。通过比较表二第4列和表三第4列,我们还观察到交通标志子类的交叉数据集性能的增加。值得注意的是,该模型未经过Cityscapes Extended交通标志类别的任何示例训练,平均PA增加10.6%仅仅是由于我们的分层多数据集训练方案的结果。我们得出结论,当数据集具有不同的类,不同的注释类型以及数据集内和数据集之间的不平衡时,层次分类对于组合的异构数据集训练非常有利。
E. Cityscapes Extended的层次分类与平面分类
在本实验中,我们使用每像素注释和两级标签空间评估Cityscapes Extended上的层次分类方法。我们的目标是将我们的方法隔离在一个数据集中,以显示它在高度不平衡的数据集中对平面分类的有效性。我们使用512 x 1024输入尺寸,批量为2。
图5.Mapillary Vistas验证分割图像示例。网络预测包括来自层次结构的L1-L3级别的决策。请注意,基本事实不包括交通标志子类。
图6.GTSDB测试分割图像示例。网络预测包括来自层次结构的L1-L3级别的决策。请注意,基本事实仅包括交通标志边界框,因为其余像素未标记。
从表IV中,我们观察到相对于平面分类器的mPA(+ 26.0%)和mIoU(+ 16.1%)层次分类显着增加了L2类(即GTSDB交通标志子类),而对于L1类(即Cityscapes类) mPA和IoU的增幅均超过+ 6%。
我们得出的结论是,即使是在单个数据集中使用每个像素的注释,分层分类对于类的不平衡是稳健的,因为它在每个级别的类中都有相同的示例顺序。
表四
在Cityscapes Extended上的平面与建议的分级分类性能。(在括号内表现为交通标志L1类)。
第六节,结论与未来工作
在本论文中,我们考虑了对三个异构但语义相连的数据集进行同时训练的挑战,以解决每个像素的语义分割问题。主要动机是最大限度地重用资源(数据集和计算)并消除人类标记工作。为了实现这一点,我们利用数据集标签之间的语义关系来构建分类器的层次结构,并介绍相应的分层训练和推理规则。我们最终的网络可以将一个输入图像从8个高级的街道场景类别中分成108个类。结果表明,采用层次分类方法进行多异构数据集训练具有明显的优越性。在未来的工作中,我们将扩展我们的成果,包括更多具有更多不同特征的数据集,以展示我们方法的可扩展性。
【REFERENCES】
[1] J. Janai, F. G¨uney, A. Behl, and A.Geiger, “Computer vision for autonomous vehicles: Problems, datasets andstate-of-the-art,” CoRR, vol. abs/1704.05519, 2017.
[2] B. Zhao, J. Feng, X. Wu, and S. Yan, “Asurvey on deep learningbased fine-grained object classification and semanticsegmentation,” International Journal of Automation and Computing, vol. 14, no.2, pp. 119–135, Apr 2017.
[3] M. Cordts, M. Omran, S. Ramos, T. Rehfeld,M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapesdataset for semantic urban scene understanding,” in Proc. of the IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2016.
[4] G. Neuhold, T. Ollmann, S. R. Bul`o,and P. Kontschieder, “The mapillary vistas dataset for semantic understandingof street scenes,” in Proceedings of the International Conference on ComputerVision (ICCV), Venice, Italy, 2017, pp. 22–29.
[5] S. Houben, J. Stallkamp, J. Salmen, M.Schlipsing, and C. Igel, “Detection of traffic signs in real-world images: The german traffic signdetection benchmark,” in Neural Networks (IJCNN). IEEE, 2013.
[6] L. Ye, Z. Liu, and Y. Wang, “LearningSemantic Segmentation with Diverse Supervision,” arXiv preprintarXiv:1802.00509, Feb. 2018.
[7] G. Papandreou, L.-C. Chen, K. P. Murphy,and A. L. Yuille, “Weaklyand semi-supervised learning of a deep convolutionalnetwork for semantic image segmentation,” in Computer Vision (ICCV), 2015 IEEE InternationalConference on. IEEE, 2015, pp. 1742–1750.
[8] A. Petrovai, A. D. Costea, and S. Nedevschi,“Semi-automatic image annotation of street scenes,” in Intelligent VehiclesSymposium (IV), 2017 IEEE. IEEE, 2017, pp. 448–455.
[9] J. Zhou, Z. Zhou, and L. Zhang, “Hierarchicalsemantic classification and attribute relations analysis with clothing regiondetection,” in Advanced Multimedia and Ubiquitous Engineering. Springer, 2016.
[10] X. Mao, S. Hijazi, R. Casas, P. Kaul,R. Kumar, and C. Rowen, “Hierarchical cnn for traffic sign recognition,” in IntelligentVehicles Symposium (IV), 2016 IEEE. IEEE, 2016, pp. 130–135.
[11] “Full implementation code for training,evaluation and inference, and the extra annotated datasets will be madepublicly available at
https://github.com/pmeletis/hierarchical-semantic-segmentation.”
[12] D. Ciregan, U. Meier, and J. Schmidhuber,“Multi-column deep neural networks for image classification,” in ComputerVision and Pattern Recognition (CVPR). IEEE, 2012, pp. 3642–3649.
[13] K. He, X. Zhang, S. Ren, and J. Sun,“Deep residual learning for image recognition,” in Proceedings of the IEEEconference on computer vision and pattern recognition, 2016, pp. 770–778.
[14] M. Abadi, A. Agarwal, P. Barham, E.Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al.,“Tensorflow: Largescale machine learning on heterogeneous distributed systems,”arXiv preprint arXiv:1603.04467, 2016.
[15] A. Garcia-Garcia, S. Orts-Escolano, S.Oprea, V. Villena-Martinez, and J. Garcia-Rodriguez, “A review on deep learningtechniques applied to semantic segmentation,” arXiv preprint arXiv:1704.06857,2017.
- 下一篇:电机驱动的NVH问题及介绍
- 上一篇:现代与autotalk合作开发V2X芯片组



编辑推荐




最新资讯
-
R171.01对DCAS的要求⑤
2025-04-20 10:58
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
