




 广告
广告





















































自动驾驶:交通标志识别算法
2018-08-30 11:10:10· 来源:九三智能控

交通标志是道路基础设施的重要组成部分,它们为司机提供关于路况的信息和合理的建议,同时也反过来促使司机调整驾驶行为,以确保他们遵守现行的任何道路法规。如果没有这些有用的标志,我们很可能会面临更多的事故,因为司机难以得知安全行驶速度、道路工程、急转弯或学校前面的交叉路口等关键的信息反馈。在我们的现代,每年约有130万人死于道路交通事故。如果没有我们的路标,这个数字会高得多。
交通标志是道路基础设施的重要组成部分,它们为司机提供关于路况的信息和合理的建议,同时也反过来促使司机调整驾驶行为,以确保他们遵守现行的任何道路法规。如果没有这些有用的标志,我们很可能会面临更多的事故,因为司机难以得知安全行驶速度、道路工程、急转弯或学校前面的交叉路口等关键的信息反馈。在我们的现代,每年约有130万人死于道路交通事故。如果没有我们的路标,这个数字会高得多。
对于自动驾驶汽车,必须可以识别和理解交通标志,从而确保其遵守道路法规。
在过去,通常使用经典的计算机视觉方法来检测和分类交通标志,但需要大量和费时的手工工作,来识标识作图像中的重要特征。本算法将深度学习技术应用到该问题上,我们创建了一个可靠地分类交通标志的模型,使汽车可以自主的识别出关键的交通标识。
数据概况
数据集被整合为训练、测试和验证集,具有以下特征:
图像为32(宽)x 32(高)x 3 (RGB彩色通道)
训练集由34799张图片组成
验证集由4410个图像组成
测试集由12630幅图像组成
有43个级别(例如限速20km/h、禁止进入、道路颠簸等)。
此外,我们将使用带有Tensorflow的Python 3.5来编写代码。
下面为来自数据集的图像示例,其标签显示在对应的图像之上。有些颜色很暗,所以我们稍后会改进对比度。

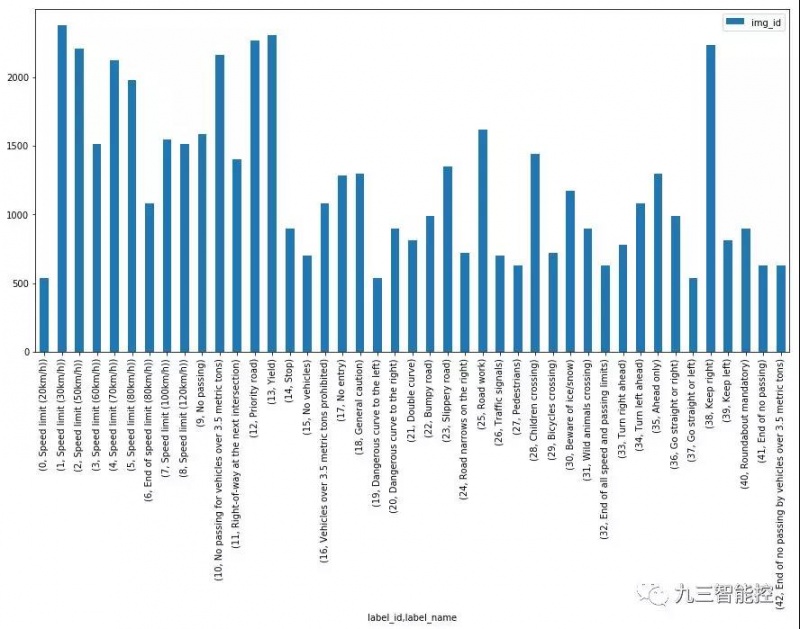
训练集中的各类别图像之间也存在显著的不平衡,如下面的直方图所示。有些类别的图片少于200张,而有些类别的图片则超过2000张。这意味着我们的模型可能偏向于过度表示的类别,特别是当它的预测不确定的时候。稍后我们将看到如何使用数据增强来减轻这种差异。
图像预处理
我们对原始图像应用了两个预处理步骤:
灰度处理
我们将三通道的彩色图像转换为单一通道的灰度图像。

图像归一化
我们将图像数据集的分布归一化,具体方法为:用数据集的均值减去每幅图像的值,然后除以其标准差。这有助于我们的模型均匀地处理图像。生成的图像如下所示:

模型结构
本算法的模型结构参考了Yann LeCun关于交通标志分类的论文。我们添加了一些调整,并创建了一个模块化代码库,它允许我们尝试不同的过滤尺寸、深度和卷积层的数量,以及完全连接层的尺寸。为了向LeCun致敬,我们称这种网络为EdLeNet。
我们重点尝试了5x5和3x3的卷积核尺寸,并从32的深度开始我们的第一个卷积层。EdLeNet的3x3架构如下图所示:
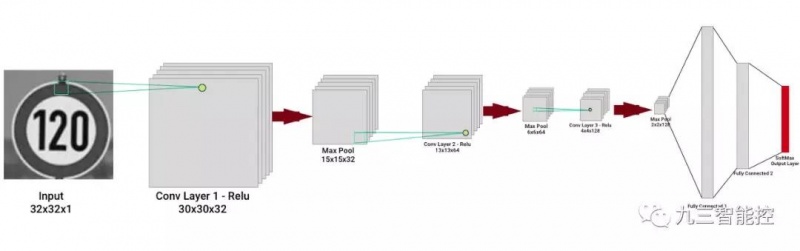
该网络由3个卷积层组成—卷积核大小为3x3,下一层深度加倍—使用ReLU作为激活函数,每一层都有2x2的最大池化操作。后面三层是全连接层,最后一层使用SoftMax激活函数计算得到43个结果(可能的标签总数)。利用Adam优化器对网络进行了小批量随机梯度下降训练。我们构建了一个高度模块化的编码结构,使我们能够动态地创建我们的模型,如下所示:
mc_3x3 = ModelConfig(EdLeNet, "EdLeNet_Norm_Grayscale_3x3_Dropout_0.50", [32, 32, 1], [3, 32, 3], [120, 84], n_classes, [0.75, 0.5])
mc_5x5 = ModelConfig(EdLeNet, "EdLeNet_Norm_Grayscale_5x5_Dropout_0.50", [32, 32, 1], [5, 32, 2], [120, 84], n_classes, [0.75, 0.5])
me_g_norm_drpt_0_50_3x3 = ModelExecutor(mc_3x3)
me_g_norm_drpt_0_50_5x5 = ModelExecutor(mc_5x5)
为了更好地隔离我们的模型,并确保它们不都处于同一个张量图下,我们进行了以下处理:
self.graph = tf.Graph()
with self.graph.as_default() as g:
with g.name_scope( self.model_config.name ) as scope:
...
with tf.Session(graph = self.graph) as sess:
通过这种方式,我们为每个模型创建单独的图表,确保没有混合变量、占位符等。这为我省去了很多麻烦。
我们最初尝试的卷积深度为16,但最终选择32时得到了更好的结果。我们还比较了彩色与灰度、原始图像和归一化图像的差别,发现灰度图像的表现优于采用图像。遗憾的是,我们在3x3或5x5模型上的测试集准确率只有93%,没有达到设定的要求。此外,我们观察到在一定的迭代周期后,验证集上存在一些不稳定的丢失行为,这实际上意味着模型在训练集上出现过拟合。
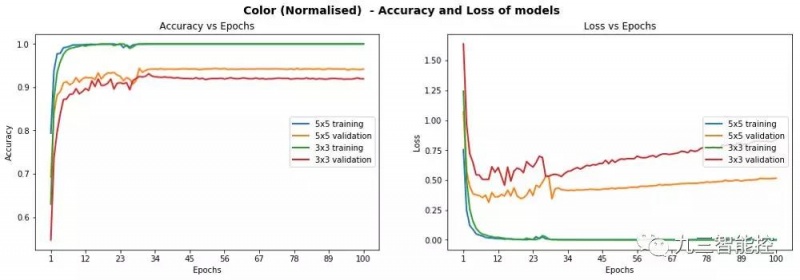
模型在彩色归一化图像上的表现
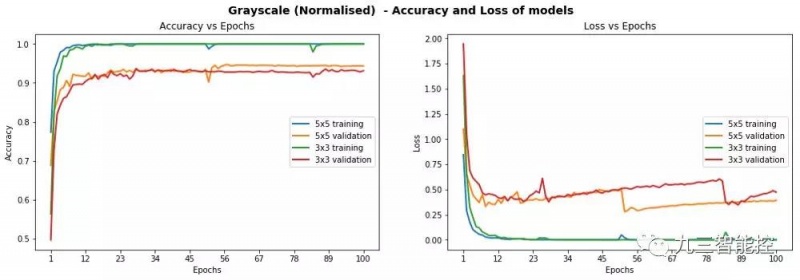
模型在灰度归一化图像上的表现
Dropout
为了提高模型的可靠性,我们转向了Dropout,它是一种正则化方法。该方法在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中剔除,这可以防止模型过度拟合。对于不同的层类型,可以应用不同程度的剔除率。因此我们决定在模型中加入两类Dropout,一类用于卷积层,另一层类用于全连接层。
p-conv: probability of keeping weight in convolutional layer
p-fc: probability of keeping weight in fully connected layer
随着网络深度的加深,可以逐渐采用了更激进(即更低)的Dropout值。此外,我们还进行了以下设置:
p-conv >= p-fc
也就是说,在卷积层中单元的剔除概率要大于或等于全连通层。我们可以将网络视为一个漏斗,因此希望在深入层的过程中逐渐收紧网络:避免一开始就丢弃太多信息,因为其中一些信息非常有价值。此外,当我们在卷积层中应用最大池化(MaxPooling)时,我们已经丢失了一些信息。
我们尝试了不同的参数,但最终确定了p-conv=0.75和p-fc=0.5,这使得我们用3x3模型对正态灰度图像的测试集准确率达到了97.55%。有趣的是,我们在验证集上的准确率超过98.3%:
Training EdLeNet_Norm_Grayscale_3x3_Dropout_0.50 [epochs=100, batch_size=512]...
[1] total=5.222s | train: time=3.139s, loss=3.4993, acc=0.1047 | val: time=2.083s, loss=3.5613, acc=0.1007
[10] total=5.190s | train: time=3.122s, loss=0.2589, acc=0.9360 | val: time=2.067s, loss=0.3260, acc=0.8973
...
[90] total=5.193s | train: time=3.120s, loss=0.0006, acc=0.9999 | val: time=2.074s, loss=0.0747, acc=0.9841
[100] total=5.191s | train: time=3.123s, loss=0.0004, acc=1.0000 | val: time=2.068s, loss=0.0849, acc=0.9832
Model ./models/EdLeNet_Norm_Grayscale_3x3_Dropout_0.50.chkpt saved
[EdLeNet_Norm_Grayscale_3x3_Dropout_0.50 - Test Set] time=0.686s, loss=0.1119, acc=0.9755
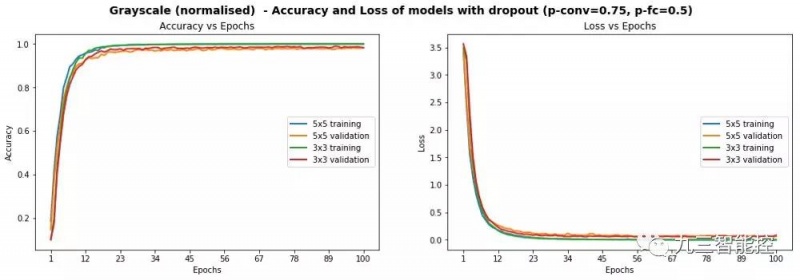
可以看到,引入Dropout后,模型的训练过程非常的平滑和稳定,并达到了测试集的准确率超过93%的目标。
但我们能做得更好吗?
我们注意到,有些图像是模糊的,并且每个类别的图像分布非常不均匀。下面我们将探讨处理以上两个问题的技术。
直方图均衡化
直方图均衡化(Histogram Equalization)是一种用于增加图像对比度的计算机视觉技术。由于我们的一些图像存在低对比度(模糊、暗),我们将通过应用OpenCV的对比度限制自适应直方图均衡化(CLAHE)函数来提高其可见性。
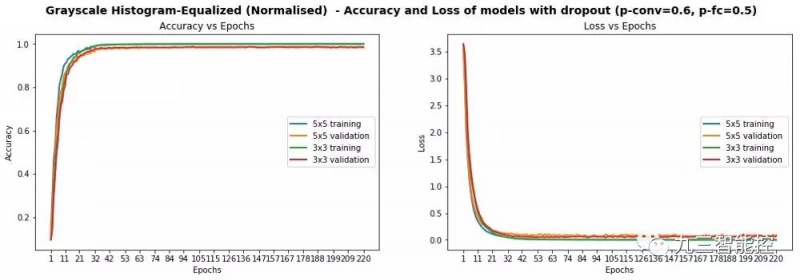
我们再次尝试各种模型结构,在3x3模型上,使用以下的Dropout值:p-conv=0.6, p-fc=0.5,得到最好的结果,测试准确率为97.75%。
Training EdLeNet_Grayscale_CLAHE_Norm_Take-2_3x3_Dropout_0.50 [epochs=500, batch_size=512]...
[1] total=5.194s | train: time=3.137s, loss=3.6254, acc=0.0662 | val: time=2.058s, loss=3.6405, acc=0.0655
[10] total=5.155s | train: time=3.115s, loss=0.8645, acc=0.7121 | val: time=2.040s, loss=0.9159, acc=0.6819
...
[480] total=5.149s | train: time=3.106s, loss=0.0009, acc=0.9998 | val: time=2.042s, loss=0.0355, acc=0.9884
[490] total=5.148s | train: time=3.106s, loss=0.0007, acc=0.9998 | val: time=2.042s, loss=0.0390, acc=0.9884
[500] total=5.148s | train: time=3.104s, loss=0.0006, acc=0.9999 | val: time=2.044s, loss=0.0420, acc=0.9862
Model ./models/EdLeNet_Grayscale_CLAHE_Norm_Take-2_3x3_Dropout_0.50.chkpt saved
[EdLeNet_Grayscale_CLAHE_Norm_Take-2_3x3_Dropout_0.50 - Test Set] time=0.675s, loss=0.0890, acc=0.9775
下面是我们测试5x5模型的前几次运行的图表,超过220次迭代。训练过程更加平滑,也意味着我们的模型更稳定。
我们标识了269个模型无法识别的图像,下面随机选择了10个,来判断模型无法准确识别的原因。

10个模型预测错误的图像
可以看到,一些图像非常模糊,采用直方图均衡化仍难以得到清晰的结果。而其他的一些图像则存在较大的扭曲。在我们的测试集中,可能没有足够的此类图像来改进模型的准确率。另外,虽然97.75%的测试精度非常高了,但是我们还有一个王牌可以用:数据增强。
数据增强
前面提到,数据集的43个类之间存在明显的不平衡。我们还注意到测试集中的一些图像是扭曲的。因此,我们将使用数据增强技术来尝试处理:
扩展数据集,设置不同的光线效果和图像方向,以提供额外的图片
提高模型的泛泛化能力
提高测试和验证的准确性,特别是对失真的图像
我们使用imgaug库来实现增强效果,要应用仿射变换来增强图像。代码如下:
def augment_imgs(imgs, p):
"""
Performs a set of augmentations with with a probability p
"""
augs = iaa.SomeOf((2, 4),
[
iaa.Crop(px=(0, 4)), # crop images from each side by 0 to 4px (randomly chosen)
iaa.Affine(scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}),
iaa.Affine(translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}),
iaa.Affine(rotate=(-45, 45)), # rotate by -45 to +45 degrees)
iaa.Affine(shear=(-10, 10)) # shear by -10 to +10 degrees
])
seq = iaa.Sequential([iaa.Sometimes(p, augs)])
return seq.augment_images(imgs)
虽然类别不平衡可能会在模型中引起一些偏差,但是我们决定在这个阶段不去处理它,因为这会导致我们的数据集显著膨胀并延长我们的训练时间。相反,我们决定将每个类增加10%,新数据集如下所示。

当然,图像的分布不会发生明显的变化,我们对图像集同样应用灰度处理、直方图均衡化和归一化预处理等技术。训练进行了2000次迭代, Dropout 参数为:p-conv=0.6, p-fc=0.5,测试集的准确率达到97.86%。
[EdLeNet] Building neural network [conv layers=3, conv filter size=3, conv start depth=32, fc layers=2]
Training EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50 [epochs=2000, batch_size=512]...
[1] total=5.824s | train: time=3.594s, loss=3.6283, acc=0.0797 | val: time=2.231s, loss=3.6463, acc=0.0687
...
[1970] total=5.627s | train: time=3.408s, loss=0.0525, acc=0.9870 | val: time=2.219s, loss=0.0315, acc=0.9914
[1980] total=5.627s | train: time=3.409s, loss=0.0530, acc=0.9862 | val: time=2.218s, loss=0.0309, acc=0.9902
[1990] total=5.628s | train: time=3.412s, loss=0.0521, acc=0.9869 | val: time=2.216s, loss=0.0302, acc=0.9900
[2000] total=5.632s | train: time=3.415s, loss=0.0521, acc=0.9869 | val: time=2.217s, loss=0.0311, acc=0.9902
Model ./models/EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50.chkpt saved
[EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50 - Test Set] time=0.678s, loss=0.0842, acc=0.9786
注意到,训练集上的损失指标为0.0521,说明我们还有一定的改进空间。未来可以尝试进行更多迭代次数的训练,以期取得更好的结果。
新图像验证
我们决定在新的图像上测试我们的模型,以确保它确实被推广到更多的交通标志识别上。因此,我们下载了5张新图片,并将它们提交给我们的模型进行预测。

预测结果如下:
['Speed limit (120km/h)',
'Priority road',
'No vehicles',
'Road work',
'Vehicles over 3.5 metric tons prohibited']
选择这些图片的原因如下:
代表了我们目前分类的不同交通标志
形状和颜色各不相同
在不同的光照条件下(第四个有阳光反射)
在不同的方向(第三个是倾斜的)
有不同的背景
最后一张图片实际上是一个设计,而不是一张真实的图片,我们想要根据它来测试模型
一些图像的表示信息不全
我们采取的第一步是对这些新图像应用相同的CLAHE,结果如下:

我们对新图像的精确度达到100%。在原始测试集上,我们达到了97.86%的准确率。我们可以探索模糊/扭曲我们的新图像或修改对比度,看看模型将会如何处理这些变化。
我们还展示了为每个图像计算出的前5个SoftMax,绿色的条带表示最终的识别结果。可以看到,模型预测的非常准确。在最坏的情况下(最后一张图片),第二种可能性的预测概率约为0.1%。事实上,模型在最后一张图片上挣扎得最厉害,这实际上是一个设计,不是一张真实的图片。总体来说,我们已经开发出了一个强大的模型!
激活图(Activation Maps)
接下来,我们将展示每个卷积层(在最大池化层之前)所生成的结果,主要包括3个激活图。
第1层网络

可以看到,第1层神经网络仅提取了卡车的圆形边缘,而对背景则未加以关注。
第2层网络

很难确定网络在第2层关注的是什么,但它似乎“激活”了圆圈的边缘和中间,也就是卡车出现的地方。
第3层网络

这个激活图也很难破译…但是看起来网络对边缘和中间的刺激又有反应。
结 论
本算法介绍了如何使用深度学习来对交通标志进行高精度分类,使用了各种预处理和正则化技术(如Dropout),并尝试了不同的模型架构。我们构建了高度可配置的代码,并开发了一种评估多个体系结构的灵活方法。我们的模型在测试集上的准确率接近98%,在验证集上的准确率达到99%。
对于自动驾驶汽车,必须可以识别和理解交通标志,从而确保其遵守道路法规。
在过去,通常使用经典的计算机视觉方法来检测和分类交通标志,但需要大量和费时的手工工作,来识标识作图像中的重要特征。本算法将深度学习技术应用到该问题上,我们创建了一个可靠地分类交通标志的模型,使汽车可以自主的识别出关键的交通标识。
数据概况
数据集被整合为训练、测试和验证集,具有以下特征:
图像为32(宽)x 32(高)x 3 (RGB彩色通道)
训练集由34799张图片组成
验证集由4410个图像组成
测试集由12630幅图像组成
有43个级别(例如限速20km/h、禁止进入、道路颠簸等)。
此外,我们将使用带有Tensorflow的Python 3.5来编写代码。
下面为来自数据集的图像示例,其标签显示在对应的图像之上。有些颜色很暗,所以我们稍后会改进对比度。
训练集中的各类别图像之间也存在显著的不平衡,如下面的直方图所示。有些类别的图片少于200张,而有些类别的图片则超过2000张。这意味着我们的模型可能偏向于过度表示的类别,特别是当它的预测不确定的时候。稍后我们将看到如何使用数据增强来减轻这种差异。
图像预处理
我们对原始图像应用了两个预处理步骤:
灰度处理
我们将三通道的彩色图像转换为单一通道的灰度图像。
图像归一化
我们将图像数据集的分布归一化,具体方法为:用数据集的均值减去每幅图像的值,然后除以其标准差。这有助于我们的模型均匀地处理图像。生成的图像如下所示:
模型结构
本算法的模型结构参考了Yann LeCun关于交通标志分类的论文。我们添加了一些调整,并创建了一个模块化代码库,它允许我们尝试不同的过滤尺寸、深度和卷积层的数量,以及完全连接层的尺寸。为了向LeCun致敬,我们称这种网络为EdLeNet。
我们重点尝试了5x5和3x3的卷积核尺寸,并从32的深度开始我们的第一个卷积层。EdLeNet的3x3架构如下图所示:
该网络由3个卷积层组成—卷积核大小为3x3,下一层深度加倍—使用ReLU作为激活函数,每一层都有2x2的最大池化操作。后面三层是全连接层,最后一层使用SoftMax激活函数计算得到43个结果(可能的标签总数)。利用Adam优化器对网络进行了小批量随机梯度下降训练。我们构建了一个高度模块化的编码结构,使我们能够动态地创建我们的模型,如下所示:
mc_3x3 = ModelConfig(EdLeNet, "EdLeNet_Norm_Grayscale_3x3_Dropout_0.50", [32, 32, 1], [3, 32, 3], [120, 84], n_classes, [0.75, 0.5])
mc_5x5 = ModelConfig(EdLeNet, "EdLeNet_Norm_Grayscale_5x5_Dropout_0.50", [32, 32, 1], [5, 32, 2], [120, 84], n_classes, [0.75, 0.5])
me_g_norm_drpt_0_50_3x3 = ModelExecutor(mc_3x3)
me_g_norm_drpt_0_50_5x5 = ModelExecutor(mc_5x5)
为了更好地隔离我们的模型,并确保它们不都处于同一个张量图下,我们进行了以下处理:
self.graph = tf.Graph()
with self.graph.as_default() as g:
with g.name_scope( self.model_config.name ) as scope:
...
with tf.Session(graph = self.graph) as sess:
通过这种方式,我们为每个模型创建单独的图表,确保没有混合变量、占位符等。这为我省去了很多麻烦。
我们最初尝试的卷积深度为16,但最终选择32时得到了更好的结果。我们还比较了彩色与灰度、原始图像和归一化图像的差别,发现灰度图像的表现优于采用图像。遗憾的是,我们在3x3或5x5模型上的测试集准确率只有93%,没有达到设定的要求。此外,我们观察到在一定的迭代周期后,验证集上存在一些不稳定的丢失行为,这实际上意味着模型在训练集上出现过拟合。
模型在彩色归一化图像上的表现
模型在灰度归一化图像上的表现
Dropout
为了提高模型的可靠性,我们转向了Dropout,它是一种正则化方法。该方法在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中剔除,这可以防止模型过度拟合。对于不同的层类型,可以应用不同程度的剔除率。因此我们决定在模型中加入两类Dropout,一类用于卷积层,另一层类用于全连接层。
p-conv: probability of keeping weight in convolutional layer
p-fc: probability of keeping weight in fully connected layer
随着网络深度的加深,可以逐渐采用了更激进(即更低)的Dropout值。此外,我们还进行了以下设置:
p-conv >= p-fc
也就是说,在卷积层中单元的剔除概率要大于或等于全连通层。我们可以将网络视为一个漏斗,因此希望在深入层的过程中逐渐收紧网络:避免一开始就丢弃太多信息,因为其中一些信息非常有价值。此外,当我们在卷积层中应用最大池化(MaxPooling)时,我们已经丢失了一些信息。
我们尝试了不同的参数,但最终确定了p-conv=0.75和p-fc=0.5,这使得我们用3x3模型对正态灰度图像的测试集准确率达到了97.55%。有趣的是,我们在验证集上的准确率超过98.3%:
Training EdLeNet_Norm_Grayscale_3x3_Dropout_0.50 [epochs=100, batch_size=512]...
[1] total=5.222s | train: time=3.139s, loss=3.4993, acc=0.1047 | val: time=2.083s, loss=3.5613, acc=0.1007
[10] total=5.190s | train: time=3.122s, loss=0.2589, acc=0.9360 | val: time=2.067s, loss=0.3260, acc=0.8973
...
[90] total=5.193s | train: time=3.120s, loss=0.0006, acc=0.9999 | val: time=2.074s, loss=0.0747, acc=0.9841
[100] total=5.191s | train: time=3.123s, loss=0.0004, acc=1.0000 | val: time=2.068s, loss=0.0849, acc=0.9832
Model ./models/EdLeNet_Norm_Grayscale_3x3_Dropout_0.50.chkpt saved
[EdLeNet_Norm_Grayscale_3x3_Dropout_0.50 - Test Set] time=0.686s, loss=0.1119, acc=0.9755
可以看到,引入Dropout后,模型的训练过程非常的平滑和稳定,并达到了测试集的准确率超过93%的目标。
但我们能做得更好吗?
我们注意到,有些图像是模糊的,并且每个类别的图像分布非常不均匀。下面我们将探讨处理以上两个问题的技术。
直方图均衡化
直方图均衡化(Histogram Equalization)是一种用于增加图像对比度的计算机视觉技术。由于我们的一些图像存在低对比度(模糊、暗),我们将通过应用OpenCV的对比度限制自适应直方图均衡化(CLAHE)函数来提高其可见性。
我们再次尝试各种模型结构,在3x3模型上,使用以下的Dropout值:p-conv=0.6, p-fc=0.5,得到最好的结果,测试准确率为97.75%。
Training EdLeNet_Grayscale_CLAHE_Norm_Take-2_3x3_Dropout_0.50 [epochs=500, batch_size=512]...
[1] total=5.194s | train: time=3.137s, loss=3.6254, acc=0.0662 | val: time=2.058s, loss=3.6405, acc=0.0655
[10] total=5.155s | train: time=3.115s, loss=0.8645, acc=0.7121 | val: time=2.040s, loss=0.9159, acc=0.6819
...
[480] total=5.149s | train: time=3.106s, loss=0.0009, acc=0.9998 | val: time=2.042s, loss=0.0355, acc=0.9884
[490] total=5.148s | train: time=3.106s, loss=0.0007, acc=0.9998 | val: time=2.042s, loss=0.0390, acc=0.9884
[500] total=5.148s | train: time=3.104s, loss=0.0006, acc=0.9999 | val: time=2.044s, loss=0.0420, acc=0.9862
Model ./models/EdLeNet_Grayscale_CLAHE_Norm_Take-2_3x3_Dropout_0.50.chkpt saved
[EdLeNet_Grayscale_CLAHE_Norm_Take-2_3x3_Dropout_0.50 - Test Set] time=0.675s, loss=0.0890, acc=0.9775
下面是我们测试5x5模型的前几次运行的图表,超过220次迭代。训练过程更加平滑,也意味着我们的模型更稳定。
我们标识了269个模型无法识别的图像,下面随机选择了10个,来判断模型无法准确识别的原因。
10个模型预测错误的图像
可以看到,一些图像非常模糊,采用直方图均衡化仍难以得到清晰的结果。而其他的一些图像则存在较大的扭曲。在我们的测试集中,可能没有足够的此类图像来改进模型的准确率。另外,虽然97.75%的测试精度非常高了,但是我们还有一个王牌可以用:数据增强。
数据增强
前面提到,数据集的43个类之间存在明显的不平衡。我们还注意到测试集中的一些图像是扭曲的。因此,我们将使用数据增强技术来尝试处理:
扩展数据集,设置不同的光线效果和图像方向,以提供额外的图片
提高模型的泛泛化能力
提高测试和验证的准确性,特别是对失真的图像
我们使用imgaug库来实现增强效果,要应用仿射变换来增强图像。代码如下:
def augment_imgs(imgs, p):
"""
Performs a set of augmentations with with a probability p
"""
augs = iaa.SomeOf((2, 4),
[
iaa.Crop(px=(0, 4)), # crop images from each side by 0 to 4px (randomly chosen)
iaa.Affine(scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}),
iaa.Affine(translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}),
iaa.Affine(rotate=(-45, 45)), # rotate by -45 to +45 degrees)
iaa.Affine(shear=(-10, 10)) # shear by -10 to +10 degrees
])
seq = iaa.Sequential([iaa.Sometimes(p, augs)])
return seq.augment_images(imgs)
虽然类别不平衡可能会在模型中引起一些偏差,但是我们决定在这个阶段不去处理它,因为这会导致我们的数据集显著膨胀并延长我们的训练时间。相反,我们决定将每个类增加10%,新数据集如下所示。
当然,图像的分布不会发生明显的变化,我们对图像集同样应用灰度处理、直方图均衡化和归一化预处理等技术。训练进行了2000次迭代, Dropout 参数为:p-conv=0.6, p-fc=0.5,测试集的准确率达到97.86%。
[EdLeNet] Building neural network [conv layers=3, conv filter size=3, conv start depth=32, fc layers=2]
Training EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50 [epochs=2000, batch_size=512]...
[1] total=5.824s | train: time=3.594s, loss=3.6283, acc=0.0797 | val: time=2.231s, loss=3.6463, acc=0.0687
...
[1970] total=5.627s | train: time=3.408s, loss=0.0525, acc=0.9870 | val: time=2.219s, loss=0.0315, acc=0.9914
[1980] total=5.627s | train: time=3.409s, loss=0.0530, acc=0.9862 | val: time=2.218s, loss=0.0309, acc=0.9902
[1990] total=5.628s | train: time=3.412s, loss=0.0521, acc=0.9869 | val: time=2.216s, loss=0.0302, acc=0.9900
[2000] total=5.632s | train: time=3.415s, loss=0.0521, acc=0.9869 | val: time=2.217s, loss=0.0311, acc=0.9902
Model ./models/EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50.chkpt saved
[EdLeNet_Augs_Grayscale_CLAHE_Norm_Take4_Bis_3x3_Dropout_0.50 - Test Set] time=0.678s, loss=0.0842, acc=0.9786
注意到,训练集上的损失指标为0.0521,说明我们还有一定的改进空间。未来可以尝试进行更多迭代次数的训练,以期取得更好的结果。
新图像验证
我们决定在新的图像上测试我们的模型,以确保它确实被推广到更多的交通标志识别上。因此,我们下载了5张新图片,并将它们提交给我们的模型进行预测。
预测结果如下:
['Speed limit (120km/h)',
'Priority road',
'No vehicles',
'Road work',
'Vehicles over 3.5 metric tons prohibited']
选择这些图片的原因如下:
代表了我们目前分类的不同交通标志
形状和颜色各不相同
在不同的光照条件下(第四个有阳光反射)
在不同的方向(第三个是倾斜的)
有不同的背景
最后一张图片实际上是一个设计,而不是一张真实的图片,我们想要根据它来测试模型
一些图像的表示信息不全
我们采取的第一步是对这些新图像应用相同的CLAHE,结果如下:
我们对新图像的精确度达到100%。在原始测试集上,我们达到了97.86%的准确率。我们可以探索模糊/扭曲我们的新图像或修改对比度,看看模型将会如何处理这些变化。
我们还展示了为每个图像计算出的前5个SoftMax,绿色的条带表示最终的识别结果。可以看到,模型预测的非常准确。在最坏的情况下(最后一张图片),第二种可能性的预测概率约为0.1%。事实上,模型在最后一张图片上挣扎得最厉害,这实际上是一个设计,不是一张真实的图片。总体来说,我们已经开发出了一个强大的模型!
激活图(Activation Maps)
接下来,我们将展示每个卷积层(在最大池化层之前)所生成的结果,主要包括3个激活图。
第1层网络
可以看到,第1层神经网络仅提取了卡车的圆形边缘,而对背景则未加以关注。
第2层网络
很难确定网络在第2层关注的是什么,但它似乎“激活”了圆圈的边缘和中间,也就是卡车出现的地方。
第3层网络
这个激活图也很难破译…但是看起来网络对边缘和中间的刺激又有反应。
结 论
本算法介绍了如何使用深度学习来对交通标志进行高精度分类,使用了各种预处理和正则化技术(如Dropout),并尝试了不同的模型架构。我们构建了高度可配置的代码,并开发了一种评估多个体系结构的灵活方法。我们的模型在测试集上的准确率接近98%,在验证集上的准确率达到99%。
- 下一篇:自动驾驶:车道线检测算法
- 上一篇:自动驾驶:汽车转向角控制算法






最新资讯
-
国家应急管理部就小米SU7事故发文:目前市
2025-04-06 20:36
-
余承东不再担任华为车BU董事长
2025-04-05 09:46
-
无稀土!里卡多开发铝电机
2025-04-05 09:46
-
康明斯宣布推出新的电池储能解决方案
2025-04-05 09:45
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
