




 广告
广告





















































MIT-AVT研究之—软件部分:数据管道和深度学习模型训练
2018-09-12 21:17:31· 来源:智车科技 作者:Lex Fridman等

在MIT - AVT研究中,最先进的嵌入式系统编程、软件工程、数据处理、分布式计算、计算机视觉和深度学习技术被应用于大规模自然驾驶数据的收集和分析,旨在为深入了解快速变化的交通系统中人类和自动驾驶车辆是如何进行相互作用的,从而开辟新的领域。这项研究提出了MIT-AVT研究背后的方法论,旨在定义和启发下一代自动驾驶研究。
在MIT - AVT研究中,最先进的嵌入式系统编程、软件工程、数据处理、分布式计算、计算机视觉和深度学习技术被应用于大规模自然驾驶数据的收集和分析,旨在为深入了解快速变化的交通系统中人类和自动驾驶车辆是如何进行相互作用的,从而开辟新的领域。这项研究提出了MIT-AVT研究背后的方法论,旨在定义和启发下一代自动驾驶研究。本篇介绍软件部分。
为了深入了解人类和自动驾驶车辆在快速变化的交通系统中的交互。
麻省理工学院进行了自动驾驶车辆技术的研究( MIT - AVT ):
( 1 )进行大规模的现实世界驾驶数据的收集,包括高清视频,以推动基于深度学习的内外感知系统;
( 2 )通过将视频数据与车辆状态数据、驾驶员特征、心理模型和自我报告的技术体验相结合,全面了解人类如何与车辆自动化技术进行互动;
( 3 )确定如何以挽救生命的方式改进与自动化使用有关的技术和其他因素。
为了以上研究先进的嵌入式系统编程、软件工程、数据处理、分布式计算、计算机视觉和深度学习技术被用于大规模自然驾驶数据的收集和分析。
&auto=0">
这项研究提出了MIT-AVT研究背后的方法论,旨在定义和启发下一代自然驾驶研究。本研究的设计原则是,除了先前成功的“自然驾驶研究”( NDS )方法之外,还利用计算机视觉和深度学习的力量自动提取人类与各种自主车辆技术水平相互作用的模式。(1)使用AI来分析大规模数据中的整体驾驶体验;(2)使用人类专业知识和定性分析深入挖掘数据以获得特定案例的理解。迄今为止,该数据集包括78名参与者,7,146天参与,275,589英里和35亿视频帧。 有关MITAVT数据集大小和范围的统计信息会定期更新为hcai.mit.edu/avt。
前文简单介绍了 MIT - AVT ,以及该研究的硬件部分,本文主要介绍该研究的软件部分。
软件部分:数据管道和深度学习模型训练
基于RIDER强大、可靠和灵活的硬件架构,这里的是软件框架也很庞大,它可以记录和处理原始传感数据,并通过数千个支持GPU的计算核心的许多步骤,获取关于自动驾驶车辆技术背景下人类行为的知识和见解。图8显示了从原始时间戳传感器数据到可操作知识的旅程。高级步骤是( 1 )数据清理和同步,( 2 )自动或半自动数据注释、上下文解释和知识提取,以及( 3 )聚合分析和可视化。
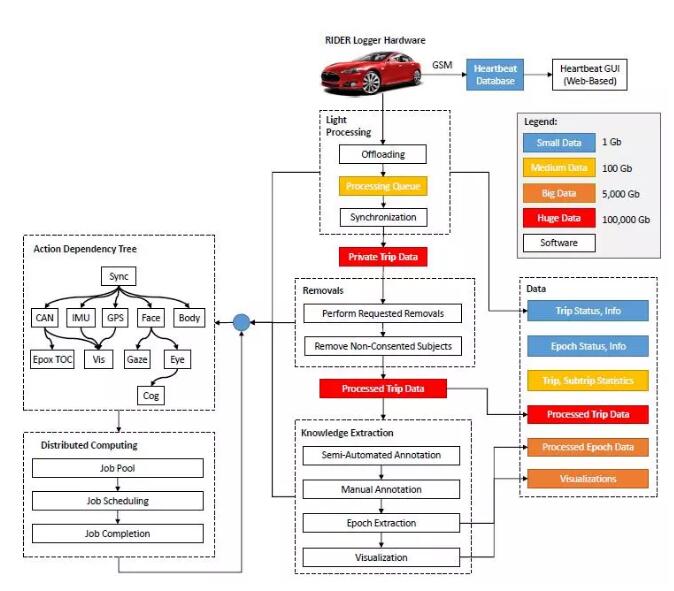
图8:MIT-AVT数据管道,展示了从数据中卸载、清理、同步和提取知识的过程。左边是依赖约束的异步分布式计算框架。中间是执行多个层次的知识提取的高级过程序列。右边是管道产生的广泛的数据类别,按大小进行组织。
本节将讨论数据管道(图8),其中包括在RIDER盒上实现的软件,可实现数据流和记录。此外,还将讨论用于在中央服务器上卸载和处理数据的软件。在RIDER盒上运行的软件的操作要求如下:
1 )每当车辆开启时,接通电源
2 )在外部固态驱动器上创建行程目录
3 )将所有数据流重新定向到带有时间戳的行程文件中
4 )实时记录元数据并将其传输到实验室
5 )车辆关闭后断电
A.微控制器
Knights of CANelot的微控制器运行一个小型C语言程序,负责为RIDER系统提供与车辆同步的动力。
默认情况下,该微控制器处于睡眠状态,等待特定的CAN消息。通过收听车辆的CAN总线,这个程序可以识别特定信号的CAN消息何时开始,这意味着汽车已经打开。如果观察到此信号,则C语言程序将车辆的电源连接到系统的其余部分,开始数据收集。当指定的消息结束时,意味着汽车关闭,微控制器向Banana Pi发送信号,关闭所有文件并正常关机。然后,它等待60秒钟,最终断开系统其余部分的电源,并进入其原始睡眠状态。
B.单板计算机
我们的单板计算机Banana Pi包含一个32GBsd卡,存储RIDER文件系统、软件和配置文件。Banana Pi使用定制内核模块和改进的Bannanian操作系统运行一个改进的Linux内核,并增强了性能和安全性。通过禁用不必要的内核模块和删除无关的Linux服务,性能得到了提高。安全性增强包括禁用所有CAN传输,从而禁止向车辆系统恶意或非故意传输致动消息。其他安全改进包括更改网络设置以防止任何远程连接登录。特定的MIT机器被设置为白名单,以允许通过物理连接更改配置文件,默认的系统服务也被修改,以便在系统启动时运行一系列本地安装的程序来管理数据收集。
C.启动脚本
每当系统启动时,Banana Pi都会运行一系列数据记录初始化bash启动脚本。首先,Pi上的板载时钟与保持高分辨率定时信息的实时时钟同步。然后加载用于设备通信的模块,如UART、I2C、SPI、UVC和CAN,以允许与输入数据流交互。。启动一个监控脚本,如果从 Knights of CANelot微控制器接收到指定的信号,该脚本会关闭系统,另外一个GSM监控脚本会在失去连接后帮助重新连接到蜂窝网络。最后的初始化步骤是启动python脚本Dacman和Lighthouse。
D. Dacman
Dacman表示管理所有数据流的中央数据处理程序脚本。 它使用名为trip_dacman.json的配置文件,该文件包含摄像机的唯一设备ID。此外,它还包含与存储在其中的RIDER盒相关联的唯一RIDER ID。该配置文件还包含与该驾驶员相关的主题、车辆和研究的唯一ID值。一旦启动,Dacman就会在外部固态驱动器上创建一个旅程目录,该目录根据使用唯一命名约定创建的日期命名:rider-id_date_timestamp(例如20_20160726_1469546998634990)。 此行程目录包含trip_dacman.json的副本,任何与数据相关的CSV文件,反映所包含的子系统,以及一个名为trip_specs.json的规范文件,其中包含表示每个子系统的起点和终点以及行程本身的微秒时间戳。
Dacman为每个子系统调用一个管理器python脚本(例如audio_manager.py或can_manager.py),这使得相关的系统调可用来记录数据。在当前车辆行程的整个过程中,所有数据都被写入CSV文件,每行包含时间戳信息。Dacman调用另外两个用C语言编写的程序来帮助生成这些文件:用于管理摄像机的cam2hd和用于创建CAN文件的dump_can。 音频或摄像机数据分别记录为RAW和H264格式,附带的CSV表示记录每帧的微秒时间戳。如果在Dacman运行时遇到任何错误,系统最多会重新启动两次以尝试解决它们,如果无法解决它们,则会关闭。
E. Cam2HD
Cam2hd是一个用C语言编写的程序,可以打开并记录所有摄像机数据。。它依赖于V4L ( Video4Linux ),这是一个开源项目,包含Linux中的摄像头驱动程序集。V4L通过将传入图像分辨率设置为720 p,允许访问连接到RIDER的摄像机,并允许写入原始H264帧。
F. DumpCAN
Dump _ CAN是用C语言编写的另一个程序,用于配置和接收来自all winner A20 CAN控制器的数据。这个程序使用CAN 4linux模块来产生一个CSV,包含从连接的CAN总线接收的所有CAN数据。此外,它提供CAN控制器的低水平操作。这允许Dump _ CAN在CAV控制器上设置仅监听模式,从而提高了安全性。通过消除在CAN网络上监听消息时发送确认的需要,可以最大限度地减少对CAN总线上现有系统的任何可能干扰。
G. Lighthouse
Lighthouse是一个python脚本,可以将有关每次行程的信息发送到Homebase。发送的信息包括行程时间信息、GPS数据、功耗、温度和可用的外部驱动空间。通信间隔在dacman配置文件中指定。所有通信都是以JSON格式发送的,并且由于其速度的原因,使用基于椭圆曲线25519的公钥加密。这意味着每个RIDER都使用服务器的公钥,以及唯一的公钥/私钥来加密和传输数据。Lighthouse是用Python编写的,依赖于libzmq/ libna。
H. Homebase
Homebase也是一个脚本,用于接收、解密和记录从Lighthouse接收到的所有信息,并将其存储在RIDER数据库中,这允许远程监控驱动器空间和系统运行状况良好。所有附加密钥管理都在这里完成,以便解密来自每个唯一盒子的消息。
I. Heartbeat
Heartbeat是一个面向工程师的界面,该界面显示RIDER系统状态信息,以验证成功的操作或了解潜在的系统故障。 Heartbeat使用从homease提交到数据库的信息来跟踪各种RIDER日志。这对于分析车辆的当前状态是有用的,并且有助于确定哪些仪表车辆需要驱动交换(由于硬盘驱动器空间不足)或系统维修。这也有助于验证任何修复是否成功。
J. RIDER Database
PostgreSQL数据库用于存储所有传入的行程信息,以及存储卸载到存储服务器的所有行程信息。经过额外处理后,可以将有关每次行程的有用信息添加到数据库中。然后,可以对查询进行结构化,以获得发生特定事件或条件的特定行程或时间。下列表格是行程处理管道的基本资料:
仪表:用于安装RIDER盒的日期和车辆ID
参与:独特的学科和研究IDs被结合起来,以识别主要和次要的驱动因素
车手:车手ID与笔记和IP地址配对
车辆:车辆信息与车辆ID配对如品牌和型号、制造日期、颜色和特定技术的可用性
行程:为每次集中卸载的旅行以及学习,车辆,主题和骑手ID提供唯一的ID。还提供有关同步状态、可用摄像机类型和子系统数据的信息。它还包含了关于旅行本身内容的元数据,例如太阳的存在、GPS频率以及某些技术应用或加速事件的存在。
epochs epoch-label:每个epoch类型的表都被标记并用于标识发生的行程和视频帧范围(例如,特斯拉中的autopilot使用的是epochs autopilot)
homebase日志:包含来自homebase脚本的流式日志信息,用于跟踪RIDER系统的运行状况和状态。
K. Cleaning
将原始行程数据卸载到存储服务器后,必须检查所有行程是否存在任何不一致。一些行程可能会有不一致的地方,可以修复,比如时间戳信息可以从多个文件中获得,或者行程中非必要的子系统出现故障(例如IMU或音频)。在不可恢复的情况下,例如在旅行期间拔出相机的事件,该行程数据将从数据集中删除。如果该行程满足某些过滤约束条件,例如当车辆开启但在再次关闭之前不移动,则也可以从数据集中移除具有有效数据文件的旅程数据。
L. Synchronization
在完成清洗和过滤后,有效的行程要经过一系列的同步步骤。首先,使用最新的摄像机开始时间戳和最早的摄像机结束时间戳,将从每个摄像机收集的每个帧的时间戳对齐在单个视频CSV文件中,每秒30帧。在低照明条件下,相机可能会以每秒15帧的速度降至录制状态。在这些情况下,可以重复一些帧以在同步的视频中实现每秒30帧。
在对齐所有原始视频之后,可以以每秒30帧的速度创建新的同步视频文件。然后通过创建一个CSV来解码CAN数据,其中所有相关的CAN消息都作为列,同步的帧ID作为行。然后,根据与每个解码后的CAN消息最近的时间戳,逐帧插入CAN消息值。然后可以生成一个最终的同步可视化,显示所有的视频流,并可以在同一个视频的单独面板中提供信息。然后,数据就可以由任何运行统计数据、检测任务或手动注释任务的算法进行处理。
【REFERENCES】
[1] A. Davies, “Oh look, more evidencehumans shouldn’t be driving,” May 2015. [Online]. Available:https://www.wired.com/2015/05/oh-look-evidence-humans-shouldnt-driving/
[2] T. Vanderbilt and B. Brenner, “Traffic:Why we drive the way we do(and what it says about us) , alfred a.knopf, new york, 2008; 978-0-307-26478-7,” 2009.
[3] W. H. Organization, Global statusreport on road safety 2015. World Health Organization, 2015.
[4] M. Buehler, K. Iagnemma, and S. Singh,The DARPA urban challenge:autonomous vehicles in city traffic.springer, 2009, vol. 56.
[5] V. V. Dixit, S. Chand, and D. J. Nair,“Autonomous vehicles: disengagements,accidents and reaction times,” PLoS one,vol. 11, no. 12, p.e0168054, 2016.
[6] F. M. Favar`o, N. Nader, S. O. Eurich,M. Tripp, and N. Varadaraju“Examining accident reports involving autonomousvehicles in california,”PLoS one, vol. 12, no. 9, p. e0184952,2017.
[7] R. Tedrake, “Underactuated robotics:Algorithms for walking, running, swimming, flying, and manipulation (coursenotes for mit 6.832),” 2016.
[8] M. R. Endsley and E. O. Kiris, “Theout-of-the-loop performance problem and level of control inautomation,” Human factors, vol. 37, no. 2, pp. 381–394, 1995.
[9] B. Reimer, “Driver assistance systemsand the transition to automated vehicles: A path to increase older adultsafety and mobility?” Public Policy & Aging Report, vol. 24, no. 1,pp. 27–31, 2014.
[10] K. Barry, “Too much safety could makedrivers less safe,” July 2011. [Online]. Available:https://www.wired.com/2011/07/ active-safety-systems-could-create-passive-drivers/
[11] V. L. Neale, T. A. Dingus, S. G.Klauer, J. Sudweeks, and M. Goodman, “An overview of the 100-car naturalistic study and findings,”National Highway Traffic Safety Administration,Paper, no. 05-0400, 2005.
[12] T. A. Dingus, S. G. Klauer, V. L.Neale, A. Petersen, S. E. Lee, J. Sudweeks, M. Perez, J. Hankey, D.Ramsey, S. Gupta et al., “The 100-car naturalistic driving study, phase ii-resultsof the 100-car field experiment,” Tech. Rep., 2006.
[13] S. G. Klauer, T. A. Dingus, V. L.Neale, J. D. Sudweeks, D. J. Ramsey et al., “The impact of driver inattentionon near-crash/crash risk: An analysis using the 100-car naturalisticdriving study data,” 2006.
[14] K. L. Campbell, “The shrp 2naturalistic driving study: Addressing driver performance and behavior in trafficsafety,” TR News, no. 282, 2012.
[15] T. Victor, M. Dozza, J. B¨argman,C.-N. Boda, J. Engstr¨om, C. Flannagan, J. D. Lee, and G. Markkula, “Analysis ofnaturalistic driving study data: Safer glances, driver inattention, andcrash risk,” Tech. Rep., 2015.
[16] M. Benmimoun, F. Fahrenkrog, A.Zlocki, and L. Eckstein, “Incident detection based on vehicle can-data withinthe large scale field operational test (eurofot),” in 22nd Enhanced Safety ofVehicles Conference (ESV 2011), Washington, DC/USA, 2011.
[17] L. Fridman, P. Langhans, J. Lee, andB. Reimer, “Driver gaze region estimation without use of eye movement,”IEEE Intelligent Systems, vol. 31, no. 3, pp. 49–56, 2016.
[18] L. Fridman, J. Lee, B. Reimer, and T.Victor, “Owl and lizard: patterns of head pose and eye pose in driver gazeclassification,” IET Computer Vision, vol. 10, no. 4, pp. 308–313, 2016.
[19] L. Fridman, “Cost of annotation inmachine learning, computer vision, and behavioral observation domains,” inProceedings of the 2018 CHI Conference on Human Factors in ComputingSystems, Under Review, 2018.
[20] B. C. Russell, A. Torralba, K. P. Murphy,and W. T. Freeman, “Labelme: a database and web-based tool for imageannotation,” International journal of computer vision, vol. 77, no. 1,pp. 157–173, 2008.
[21] M. Cordts, M. Omran, S. Ramos, T.Rehfeld, M. Enzweiler, R. Benenson,U. Franke, S. Roth, and B. Schiele, “Thecityscapes dataset for semantic urban scene understanding,” inProceedings of the IEEE Conference on Computer Vision and PatternRecognition, 2016, pp. 3213–3223.
[22] R. R. Knipling, “Naturalistic drivingevents: No harm, no foul, no validity,” in Driving Assessment 2015:International Symposium on Human Factors in Driver Assessment,Training, and Vehicle Design. Public Policy Center, University of IowaIowa City, 2015, pp. 196–202.
[23] ——, “Crash heterogeneity: implicationsfor naturalistic driving studies and for understanding crash risks,”Transportation Research Record: Journal of the Transportation ResearchBoard, no. 2663, pp. 117–125, 2017.
[24] L. Fridman, B. Jenik, and B. Reimer,“Arguing machines: Perceptioncontrol system redundancy and edge case discoveryin real-world autonomous driving,” arXiv preprintarXiv:1710.04459, 2017.
[25] V. Shankar, P. Jovanis, J.Aguero-Valverde, and F. Gross, “Analysis of naturalistic driving data: prospectiveview on methodological paradigms,” Transportation Research Record:Journal of the Transportation Research Board, no. 2061, pp. 1–8, 2008.
[26] N. Kalra and S. M. Paddock, “Drivingto safety: How many miles of driving would it take to demonstrateautonomous vehicle reliability?” Transportation Research Part A: Policy andPractice, vol. 94, pp. 182–193, 2016.
[27] I. Goodfellow, Y. Bengio, and A.Courville, Deep learning. MIT press, 2016.
[28] R. Hartley and A. Zisserman, Multipleview geometry in computer vision. Cambridge university press, 2003.
[29] J. Deng, W. Dong, R. Socher, L.-J. Li,K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,”in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEEConference on. IEEE, 2009, pp. 248–255.
[30] G. A. Miller, R. Beckwith, C.Fellbaum, D. Gross, and K. J. Miller, “Introduction to wordnet: An on-line lexical database,” International journal of lexicography, vol. 3, no. 4, pp.235–244, 1990.
[31] K. He, X. Zhang, S. Ren, and J. Sun,“Deep residual learning for image recognition,” in Proceedings of the IEEEconference on computer vision and pattern recognition, 2016, pp. 770–778.
[32] O. Russakovsky, J. Deng, H. Su, J.Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M.Bernstein et al., “Imagenet large scale visual recognition challenge,”International Journal of Computer
Vision, vol. 115, no. 3, pp. 211–252, 2015.
[33] T.-Y. Lin, M. Maire, S. Belongie, J.Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick, “Microsoftcoco: Common objects in context,” in European conference oncomputer vision. Springer, 2014, pp. 740–755.
[34] K. He, G. Gkioxari, P. Dollar, and R.Girshick, “Mask r-cnn,” in The IEEE International Conference on ComputerVision (ICCV), Oct 2017.
[35] J. Dai, H. Qi, Y. Xiong, Y. Li, G.Zhang, H. Hu, and Y.Wei, “Deformable convolutional networks,” in The IEEEInternational Conference on Computer Vision (ICCV), Oct 2017.
[36] A. Geiger, P. Lenz, C. Stiller, and R.Urtasun, “Vision meets robotics:The kitti dataset,” International Journalof Robotics Research (IJRR),2013.
[37] A. Geiger, P. Lenz, and R. Urtasun,“Are we ready for autonomous driving? the kitti vision benchmark suite,”in Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
[38] M. Menze and A. Geiger, “Object sceneflow for autonomous vehicles,” in Conference on Computer Vision andPattern Recognition (CVPR), 2015.
[39] M. Cordts, M. Omran, S. Ramos, T.Scharw¨achter, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele,“The cityscapes dataset,” 2015.
[40] H. Zhao, J. Shi, X. Qi, X. Wang, andJ. Jia, “Pyramid scene parsing network,” in The IEEE Conference onComputer Vision and Pattern Recognition (CVPR), July 2017.
[41] P. Wang, P. Chen, Y. Yuan, D. Liu, Z.Huang, X. Hou, and G. Cottrell,“Understanding convolution for semantic segmentation,” arXiv preprint arXiv:1702.08502, 2017.
[42] S. Liu, J. Jia, S. Fidler, and R.Urtasun, “Sgn: Sequential grouping networks for instance segmentation,” in The IEEEInternational Conference on Computer Vision (ICCV), Oct 2017.
[43] G. J. Brostow, J. Fauqueur, and R.Cipolla, “Semantic object classes in video: A high-definition ground truthdatabase,” Pattern Recognition Letters, vol. 30, no. 2, pp. 88–97, 2009.
[44] Y. Tian, P. Luo, X. Wang, and X. Tang,“Pedestrian detection aided by deep learning semantic tasks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015, pp. 5079–5087.
[45] V. Badrinarayanan, F. Galasso, and R.Cipolla, “Label propagation in video sequences,” in Computer Vision andPattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010, pp.3265–3272.
[46] P. Liu, S. Han, Z. Meng, and Y. Tong,“Facial expression recognition via a boosted deep belief network,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014, pp. 1805–1812.
[47] Z. Yu and C. Zhang, “Image basedstatic facial expression recognition with multiple deep network learning,” inProceedings of the 2015 ACM on International Conference on MultimodalInteraction. ACM, 2015, pp. 435–442.
[48] E. A. Hoffman and J. V. Haxby,“Distinct representations of eye gaze and identity in the distributed humanneural system for face perception,” Nature neuroscience, vol. 3, no. 1, pp.80–84, 2000.
[49] J. Wi´sniewska, M. Rezaei, and R.Klette, “Robust eye gaze estimation,” in International Conference on ComputerVision and Graphics.Springer, 2014, pp. 636–644.
[50] L. Fridman, H. Toyoda, S. Seaman, B.Seppelt, L. Angell, J. Lee, B. Mehler, and B. Reimer, “What can bepredicted from six seconds of driver glances?” in Proceedings of the 2017CHI Conference on Human Factors in Computing Systems. ACM, 2017,pp. 2805–2813.
[51] F. Vicente, Z. Huang, X. Xiong, F. Dela Torre, W. Zhang, and D. Levi,“Driver gaze tracking and eyes off the road detection system,” IEEE Transactions on Intelligent TransportationSystems, vol. 16, no. 4, pp. 2014–2027, 2015.
[52] H. Gao, A. Y¨uce, and J.-P. Thiran, “Detectingemotional stress from facial expressions for driving safety,” inImage Processing (ICIP), 2014 IEEE International Conference on. IEEE,2014, pp. 5961–5965.
[53] I. Abdic, L. Fridman, D. McDuff, E.Marchi, B. Reimer, and B. Schuller,“Driver frustration detection from audio and video in the wild,” inKI 2016: Advances in Artificial Intelligence:39th Annual German Conference on AI, Klagenfurt, Austria, September26-30, 2016, Proceedings, vol. 9904. Springer, 2016, p. 237.
[54] J. Shotton, T. Sharp, A. Kipman, A.Fitzgibbon, M. Finocchio, A. Blake,M. Cook, and R. Moore, “Real-time humanpose recognition in parts from single depth images,” Communicationsof the ACM, vol. 56, no. 1, pp. 116–124, 2013.
[55] A. Toshev and C. Szegedy, “Deeppose:Human pose estimation via deep neural networks,” in Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition, 2014, pp.1653–1660.
[56] J. J. Tompson, A. Jain, Y. LeCun, andC. Bregler, “Joint training of a convolutional network and a graphicalmodel for human pose estimation,” in Advances in neuralinformation processing systems, 2014, pp. 1799–1807.
[57] D. Sadigh, K. Driggs-Campbell, A.Puggelli, W. Li, V. Shia, R. Bajcsy, A. L. Sangiovanni-Vincentelli, S. S. Sastry,and S. A. Seshia, “Datadriven probabilistic modeling and verification ofhuman driver behavior,”
Formal Verification and Modeling inHuman-Machine Systems, 2014.
[58] R. O. Mbouna, S. G. Kong, and M.-G.Chun, “Visual analysis of eye state and head pose for driver alertnessmonitoring,” IEEE transactions on intelligent transportation systems, vol.14, no. 3, pp. 1462–1469, 2013.
[59] B. Zhou, A. Lapedriza, J. Xiao, A.Torralba, and A. Oliva, “Learning deep features for scene recognition usingplaces database,” in Advances in neural information processing systems,2014, pp. 487–495.
[60] H. Xu, Y. Gao, F. Yu, and T. Darrell,“End-to-end learning of driving models from large-scale video datasets,” inThe IEEE Conference on Computer Vision and Pattern Recognition(CVPR), July 2017.
[61] M. Bojarski, D. Del Testa, D.Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U.Muller, J. Zhang et al., “End to end learning for self-driving cars,”arXiv preprint arXiv:1604.07316,2016.
[62] “Advanced vehicle technologyconsortium (avt),” 2016. [Online]. Available: http://agelab.mit.edu/avt
[63] L. Fridman, D. E. Brown, W. Angell, I.Abdi´c, B. Reimer, and H. Y. Noh, “Automated synchronization of drivingdata using vibration and steering events,” Pattern RecognitionLetters, vol. 75, pp. 9–15, 2016.
[64] R. Li, C. Liu, and F. Luo, “A designfor automotive can bus monitoring system,” in Vehicle Power and PropulsionConference, 2008. VPPC’08. IEEE. IEEE, 2008, pp. 1–5.
 MIT-AVT研究之—软件部分:数据管道和深度学习模型训练.pdf
MIT-AVT研究之—软件部分:数据管道和深度学习模型训练.pdf
为了深入了解人类和自动驾驶车辆在快速变化的交通系统中的交互。
麻省理工学院进行了自动驾驶车辆技术的研究( MIT - AVT ):
( 1 )进行大规模的现实世界驾驶数据的收集,包括高清视频,以推动基于深度学习的内外感知系统;
( 2 )通过将视频数据与车辆状态数据、驾驶员特征、心理模型和自我报告的技术体验相结合,全面了解人类如何与车辆自动化技术进行互动;
( 3 )确定如何以挽救生命的方式改进与自动化使用有关的技术和其他因素。
为了以上研究先进的嵌入式系统编程、软件工程、数据处理、分布式计算、计算机视觉和深度学习技术被用于大规模自然驾驶数据的收集和分析。
&auto=0">
这项研究提出了MIT-AVT研究背后的方法论,旨在定义和启发下一代自然驾驶研究。本研究的设计原则是,除了先前成功的“自然驾驶研究”( NDS )方法之外,还利用计算机视觉和深度学习的力量自动提取人类与各种自主车辆技术水平相互作用的模式。(1)使用AI来分析大规模数据中的整体驾驶体验;(2)使用人类专业知识和定性分析深入挖掘数据以获得特定案例的理解。迄今为止,该数据集包括78名参与者,7,146天参与,275,589英里和35亿视频帧。 有关MITAVT数据集大小和范围的统计信息会定期更新为hcai.mit.edu/avt。
前文简单介绍了 MIT - AVT ,以及该研究的硬件部分,本文主要介绍该研究的软件部分。
软件部分:数据管道和深度学习模型训练
基于RIDER强大、可靠和灵活的硬件架构,这里的是软件框架也很庞大,它可以记录和处理原始传感数据,并通过数千个支持GPU的计算核心的许多步骤,获取关于自动驾驶车辆技术背景下人类行为的知识和见解。图8显示了从原始时间戳传感器数据到可操作知识的旅程。高级步骤是( 1 )数据清理和同步,( 2 )自动或半自动数据注释、上下文解释和知识提取,以及( 3 )聚合分析和可视化。
图8:MIT-AVT数据管道,展示了从数据中卸载、清理、同步和提取知识的过程。左边是依赖约束的异步分布式计算框架。中间是执行多个层次的知识提取的高级过程序列。右边是管道产生的广泛的数据类别,按大小进行组织。
本节将讨论数据管道(图8),其中包括在RIDER盒上实现的软件,可实现数据流和记录。此外,还将讨论用于在中央服务器上卸载和处理数据的软件。在RIDER盒上运行的软件的操作要求如下:
1 )每当车辆开启时,接通电源
2 )在外部固态驱动器上创建行程目录
3 )将所有数据流重新定向到带有时间戳的行程文件中
4 )实时记录元数据并将其传输到实验室
5 )车辆关闭后断电
A.微控制器
Knights of CANelot的微控制器运行一个小型C语言程序,负责为RIDER系统提供与车辆同步的动力。
默认情况下,该微控制器处于睡眠状态,等待特定的CAN消息。通过收听车辆的CAN总线,这个程序可以识别特定信号的CAN消息何时开始,这意味着汽车已经打开。如果观察到此信号,则C语言程序将车辆的电源连接到系统的其余部分,开始数据收集。当指定的消息结束时,意味着汽车关闭,微控制器向Banana Pi发送信号,关闭所有文件并正常关机。然后,它等待60秒钟,最终断开系统其余部分的电源,并进入其原始睡眠状态。
B.单板计算机
我们的单板计算机Banana Pi包含一个32GBsd卡,存储RIDER文件系统、软件和配置文件。Banana Pi使用定制内核模块和改进的Bannanian操作系统运行一个改进的Linux内核,并增强了性能和安全性。通过禁用不必要的内核模块和删除无关的Linux服务,性能得到了提高。安全性增强包括禁用所有CAN传输,从而禁止向车辆系统恶意或非故意传输致动消息。其他安全改进包括更改网络设置以防止任何远程连接登录。特定的MIT机器被设置为白名单,以允许通过物理连接更改配置文件,默认的系统服务也被修改,以便在系统启动时运行一系列本地安装的程序来管理数据收集。
C.启动脚本
每当系统启动时,Banana Pi都会运行一系列数据记录初始化bash启动脚本。首先,Pi上的板载时钟与保持高分辨率定时信息的实时时钟同步。然后加载用于设备通信的模块,如UART、I2C、SPI、UVC和CAN,以允许与输入数据流交互。。启动一个监控脚本,如果从 Knights of CANelot微控制器接收到指定的信号,该脚本会关闭系统,另外一个GSM监控脚本会在失去连接后帮助重新连接到蜂窝网络。最后的初始化步骤是启动python脚本Dacman和Lighthouse。
D. Dacman
Dacman表示管理所有数据流的中央数据处理程序脚本。 它使用名为trip_dacman.json的配置文件,该文件包含摄像机的唯一设备ID。此外,它还包含与存储在其中的RIDER盒相关联的唯一RIDER ID。该配置文件还包含与该驾驶员相关的主题、车辆和研究的唯一ID值。一旦启动,Dacman就会在外部固态驱动器上创建一个旅程目录,该目录根据使用唯一命名约定创建的日期命名:rider-id_date_timestamp(例如20_20160726_1469546998634990)。 此行程目录包含trip_dacman.json的副本,任何与数据相关的CSV文件,反映所包含的子系统,以及一个名为trip_specs.json的规范文件,其中包含表示每个子系统的起点和终点以及行程本身的微秒时间戳。
Dacman为每个子系统调用一个管理器python脚本(例如audio_manager.py或can_manager.py),这使得相关的系统调可用来记录数据。在当前车辆行程的整个过程中,所有数据都被写入CSV文件,每行包含时间戳信息。Dacman调用另外两个用C语言编写的程序来帮助生成这些文件:用于管理摄像机的cam2hd和用于创建CAN文件的dump_can。 音频或摄像机数据分别记录为RAW和H264格式,附带的CSV表示记录每帧的微秒时间戳。如果在Dacman运行时遇到任何错误,系统最多会重新启动两次以尝试解决它们,如果无法解决它们,则会关闭。
E. Cam2HD
Cam2hd是一个用C语言编写的程序,可以打开并记录所有摄像机数据。。它依赖于V4L ( Video4Linux ),这是一个开源项目,包含Linux中的摄像头驱动程序集。V4L通过将传入图像分辨率设置为720 p,允许访问连接到RIDER的摄像机,并允许写入原始H264帧。
F. DumpCAN
Dump _ CAN是用C语言编写的另一个程序,用于配置和接收来自all winner A20 CAN控制器的数据。这个程序使用CAN 4linux模块来产生一个CSV,包含从连接的CAN总线接收的所有CAN数据。此外,它提供CAN控制器的低水平操作。这允许Dump _ CAN在CAV控制器上设置仅监听模式,从而提高了安全性。通过消除在CAN网络上监听消息时发送确认的需要,可以最大限度地减少对CAN总线上现有系统的任何可能干扰。
G. Lighthouse
Lighthouse是一个python脚本,可以将有关每次行程的信息发送到Homebase。发送的信息包括行程时间信息、GPS数据、功耗、温度和可用的外部驱动空间。通信间隔在dacman配置文件中指定。所有通信都是以JSON格式发送的,并且由于其速度的原因,使用基于椭圆曲线25519的公钥加密。这意味着每个RIDER都使用服务器的公钥,以及唯一的公钥/私钥来加密和传输数据。Lighthouse是用Python编写的,依赖于libzmq/ libna。
H. Homebase
Homebase也是一个脚本,用于接收、解密和记录从Lighthouse接收到的所有信息,并将其存储在RIDER数据库中,这允许远程监控驱动器空间和系统运行状况良好。所有附加密钥管理都在这里完成,以便解密来自每个唯一盒子的消息。
I. Heartbeat
Heartbeat是一个面向工程师的界面,该界面显示RIDER系统状态信息,以验证成功的操作或了解潜在的系统故障。 Heartbeat使用从homease提交到数据库的信息来跟踪各种RIDER日志。这对于分析车辆的当前状态是有用的,并且有助于确定哪些仪表车辆需要驱动交换(由于硬盘驱动器空间不足)或系统维修。这也有助于验证任何修复是否成功。
J. RIDER Database
PostgreSQL数据库用于存储所有传入的行程信息,以及存储卸载到存储服务器的所有行程信息。经过额外处理后,可以将有关每次行程的有用信息添加到数据库中。然后,可以对查询进行结构化,以获得发生特定事件或条件的特定行程或时间。下列表格是行程处理管道的基本资料:
仪表:用于安装RIDER盒的日期和车辆ID
参与:独特的学科和研究IDs被结合起来,以识别主要和次要的驱动因素
车手:车手ID与笔记和IP地址配对
车辆:车辆信息与车辆ID配对如品牌和型号、制造日期、颜色和特定技术的可用性
行程:为每次集中卸载的旅行以及学习,车辆,主题和骑手ID提供唯一的ID。还提供有关同步状态、可用摄像机类型和子系统数据的信息。它还包含了关于旅行本身内容的元数据,例如太阳的存在、GPS频率以及某些技术应用或加速事件的存在。
epochs epoch-label:每个epoch类型的表都被标记并用于标识发生的行程和视频帧范围(例如,特斯拉中的autopilot使用的是epochs autopilot)
homebase日志:包含来自homebase脚本的流式日志信息,用于跟踪RIDER系统的运行状况和状态。
K. Cleaning
将原始行程数据卸载到存储服务器后,必须检查所有行程是否存在任何不一致。一些行程可能会有不一致的地方,可以修复,比如时间戳信息可以从多个文件中获得,或者行程中非必要的子系统出现故障(例如IMU或音频)。在不可恢复的情况下,例如在旅行期间拔出相机的事件,该行程数据将从数据集中删除。如果该行程满足某些过滤约束条件,例如当车辆开启但在再次关闭之前不移动,则也可以从数据集中移除具有有效数据文件的旅程数据。
L. Synchronization
在完成清洗和过滤后,有效的行程要经过一系列的同步步骤。首先,使用最新的摄像机开始时间戳和最早的摄像机结束时间戳,将从每个摄像机收集的每个帧的时间戳对齐在单个视频CSV文件中,每秒30帧。在低照明条件下,相机可能会以每秒15帧的速度降至录制状态。在这些情况下,可以重复一些帧以在同步的视频中实现每秒30帧。
在对齐所有原始视频之后,可以以每秒30帧的速度创建新的同步视频文件。然后通过创建一个CSV来解码CAN数据,其中所有相关的CAN消息都作为列,同步的帧ID作为行。然后,根据与每个解码后的CAN消息最近的时间戳,逐帧插入CAN消息值。然后可以生成一个最终的同步可视化,显示所有的视频流,并可以在同一个视频的单独面板中提供信息。然后,数据就可以由任何运行统计数据、检测任务或手动注释任务的算法进行处理。
【REFERENCES】
[1] A. Davies, “Oh look, more evidencehumans shouldn’t be driving,” May 2015. [Online]. Available:https://www.wired.com/2015/05/oh-look-evidence-humans-shouldnt-driving/
[2] T. Vanderbilt and B. Brenner, “Traffic:Why we drive the way we do(and what it says about us) , alfred a.knopf, new york, 2008; 978-0-307-26478-7,” 2009.
[3] W. H. Organization, Global statusreport on road safety 2015. World Health Organization, 2015.
[4] M. Buehler, K. Iagnemma, and S. Singh,The DARPA urban challenge:autonomous vehicles in city traffic.springer, 2009, vol. 56.
[5] V. V. Dixit, S. Chand, and D. J. Nair,“Autonomous vehicles: disengagements,accidents and reaction times,” PLoS one,vol. 11, no. 12, p.e0168054, 2016.
[6] F. M. Favar`o, N. Nader, S. O. Eurich,M. Tripp, and N. Varadaraju“Examining accident reports involving autonomousvehicles in california,”PLoS one, vol. 12, no. 9, p. e0184952,2017.
[7] R. Tedrake, “Underactuated robotics:Algorithms for walking, running, swimming, flying, and manipulation (coursenotes for mit 6.832),” 2016.
[8] M. R. Endsley and E. O. Kiris, “Theout-of-the-loop performance problem and level of control inautomation,” Human factors, vol. 37, no. 2, pp. 381–394, 1995.
[9] B. Reimer, “Driver assistance systemsand the transition to automated vehicles: A path to increase older adultsafety and mobility?” Public Policy & Aging Report, vol. 24, no. 1,pp. 27–31, 2014.
[10] K. Barry, “Too much safety could makedrivers less safe,” July 2011. [Online]. Available:https://www.wired.com/2011/07/ active-safety-systems-could-create-passive-drivers/
[11] V. L. Neale, T. A. Dingus, S. G.Klauer, J. Sudweeks, and M. Goodman, “An overview of the 100-car naturalistic study and findings,”National Highway Traffic Safety Administration,Paper, no. 05-0400, 2005.
[12] T. A. Dingus, S. G. Klauer, V. L.Neale, A. Petersen, S. E. Lee, J. Sudweeks, M. Perez, J. Hankey, D.Ramsey, S. Gupta et al., “The 100-car naturalistic driving study, phase ii-resultsof the 100-car field experiment,” Tech. Rep., 2006.
[13] S. G. Klauer, T. A. Dingus, V. L.Neale, J. D. Sudweeks, D. J. Ramsey et al., “The impact of driver inattentionon near-crash/crash risk: An analysis using the 100-car naturalisticdriving study data,” 2006.
[14] K. L. Campbell, “The shrp 2naturalistic driving study: Addressing driver performance and behavior in trafficsafety,” TR News, no. 282, 2012.
[15] T. Victor, M. Dozza, J. B¨argman,C.-N. Boda, J. Engstr¨om, C. Flannagan, J. D. Lee, and G. Markkula, “Analysis ofnaturalistic driving study data: Safer glances, driver inattention, andcrash risk,” Tech. Rep., 2015.
[16] M. Benmimoun, F. Fahrenkrog, A.Zlocki, and L. Eckstein, “Incident detection based on vehicle can-data withinthe large scale field operational test (eurofot),” in 22nd Enhanced Safety ofVehicles Conference (ESV 2011), Washington, DC/USA, 2011.
[17] L. Fridman, P. Langhans, J. Lee, andB. Reimer, “Driver gaze region estimation without use of eye movement,”IEEE Intelligent Systems, vol. 31, no. 3, pp. 49–56, 2016.
[18] L. Fridman, J. Lee, B. Reimer, and T.Victor, “Owl and lizard: patterns of head pose and eye pose in driver gazeclassification,” IET Computer Vision, vol. 10, no. 4, pp. 308–313, 2016.
[19] L. Fridman, “Cost of annotation inmachine learning, computer vision, and behavioral observation domains,” inProceedings of the 2018 CHI Conference on Human Factors in ComputingSystems, Under Review, 2018.
[20] B. C. Russell, A. Torralba, K. P. Murphy,and W. T. Freeman, “Labelme: a database and web-based tool for imageannotation,” International journal of computer vision, vol. 77, no. 1,pp. 157–173, 2008.
[21] M. Cordts, M. Omran, S. Ramos, T.Rehfeld, M. Enzweiler, R. Benenson,U. Franke, S. Roth, and B. Schiele, “Thecityscapes dataset for semantic urban scene understanding,” inProceedings of the IEEE Conference on Computer Vision and PatternRecognition, 2016, pp. 3213–3223.
[22] R. R. Knipling, “Naturalistic drivingevents: No harm, no foul, no validity,” in Driving Assessment 2015:International Symposium on Human Factors in Driver Assessment,Training, and Vehicle Design. Public Policy Center, University of IowaIowa City, 2015, pp. 196–202.
[23] ——, “Crash heterogeneity: implicationsfor naturalistic driving studies and for understanding crash risks,”Transportation Research Record: Journal of the Transportation ResearchBoard, no. 2663, pp. 117–125, 2017.
[24] L. Fridman, B. Jenik, and B. Reimer,“Arguing machines: Perceptioncontrol system redundancy and edge case discoveryin real-world autonomous driving,” arXiv preprintarXiv:1710.04459, 2017.
[25] V. Shankar, P. Jovanis, J.Aguero-Valverde, and F. Gross, “Analysis of naturalistic driving data: prospectiveview on methodological paradigms,” Transportation Research Record:Journal of the Transportation Research Board, no. 2061, pp. 1–8, 2008.
[26] N. Kalra and S. M. Paddock, “Drivingto safety: How many miles of driving would it take to demonstrateautonomous vehicle reliability?” Transportation Research Part A: Policy andPractice, vol. 94, pp. 182–193, 2016.
[27] I. Goodfellow, Y. Bengio, and A.Courville, Deep learning. MIT press, 2016.
[28] R. Hartley and A. Zisserman, Multipleview geometry in computer vision. Cambridge university press, 2003.
[29] J. Deng, W. Dong, R. Socher, L.-J. Li,K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,”in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEEConference on. IEEE, 2009, pp. 248–255.
[30] G. A. Miller, R. Beckwith, C.Fellbaum, D. Gross, and K. J. Miller, “Introduction to wordnet: An on-line lexical database,” International journal of lexicography, vol. 3, no. 4, pp.235–244, 1990.
[31] K. He, X. Zhang, S. Ren, and J. Sun,“Deep residual learning for image recognition,” in Proceedings of the IEEEconference on computer vision and pattern recognition, 2016, pp. 770–778.
[32] O. Russakovsky, J. Deng, H. Su, J.Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M.Bernstein et al., “Imagenet large scale visual recognition challenge,”International Journal of Computer
Vision, vol. 115, no. 3, pp. 211–252, 2015.
[33] T.-Y. Lin, M. Maire, S. Belongie, J.Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick, “Microsoftcoco: Common objects in context,” in European conference oncomputer vision. Springer, 2014, pp. 740–755.
[34] K. He, G. Gkioxari, P. Dollar, and R.Girshick, “Mask r-cnn,” in The IEEE International Conference on ComputerVision (ICCV), Oct 2017.
[35] J. Dai, H. Qi, Y. Xiong, Y. Li, G.Zhang, H. Hu, and Y.Wei, “Deformable convolutional networks,” in The IEEEInternational Conference on Computer Vision (ICCV), Oct 2017.
[36] A. Geiger, P. Lenz, C. Stiller, and R.Urtasun, “Vision meets robotics:The kitti dataset,” International Journalof Robotics Research (IJRR),2013.
[37] A. Geiger, P. Lenz, and R. Urtasun,“Are we ready for autonomous driving? the kitti vision benchmark suite,”in Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
[38] M. Menze and A. Geiger, “Object sceneflow for autonomous vehicles,” in Conference on Computer Vision andPattern Recognition (CVPR), 2015.
[39] M. Cordts, M. Omran, S. Ramos, T.Scharw¨achter, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele,“The cityscapes dataset,” 2015.
[40] H. Zhao, J. Shi, X. Qi, X. Wang, andJ. Jia, “Pyramid scene parsing network,” in The IEEE Conference onComputer Vision and Pattern Recognition (CVPR), July 2017.
[41] P. Wang, P. Chen, Y. Yuan, D. Liu, Z.Huang, X. Hou, and G. Cottrell,“Understanding convolution for semantic segmentation,” arXiv preprint arXiv:1702.08502, 2017.
[42] S. Liu, J. Jia, S. Fidler, and R.Urtasun, “Sgn: Sequential grouping networks for instance segmentation,” in The IEEEInternational Conference on Computer Vision (ICCV), Oct 2017.
[43] G. J. Brostow, J. Fauqueur, and R.Cipolla, “Semantic object classes in video: A high-definition ground truthdatabase,” Pattern Recognition Letters, vol. 30, no. 2, pp. 88–97, 2009.
[44] Y. Tian, P. Luo, X. Wang, and X. Tang,“Pedestrian detection aided by deep learning semantic tasks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015, pp. 5079–5087.
[45] V. Badrinarayanan, F. Galasso, and R.Cipolla, “Label propagation in video sequences,” in Computer Vision andPattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010, pp.3265–3272.
[46] P. Liu, S. Han, Z. Meng, and Y. Tong,“Facial expression recognition via a boosted deep belief network,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014, pp. 1805–1812.
[47] Z. Yu and C. Zhang, “Image basedstatic facial expression recognition with multiple deep network learning,” inProceedings of the 2015 ACM on International Conference on MultimodalInteraction. ACM, 2015, pp. 435–442.
[48] E. A. Hoffman and J. V. Haxby,“Distinct representations of eye gaze and identity in the distributed humanneural system for face perception,” Nature neuroscience, vol. 3, no. 1, pp.80–84, 2000.
[49] J. Wi´sniewska, M. Rezaei, and R.Klette, “Robust eye gaze estimation,” in International Conference on ComputerVision and Graphics.Springer, 2014, pp. 636–644.
[50] L. Fridman, H. Toyoda, S. Seaman, B.Seppelt, L. Angell, J. Lee, B. Mehler, and B. Reimer, “What can bepredicted from six seconds of driver glances?” in Proceedings of the 2017CHI Conference on Human Factors in Computing Systems. ACM, 2017,pp. 2805–2813.
[51] F. Vicente, Z. Huang, X. Xiong, F. Dela Torre, W. Zhang, and D. Levi,“Driver gaze tracking and eyes off the road detection system,” IEEE Transactions on Intelligent TransportationSystems, vol. 16, no. 4, pp. 2014–2027, 2015.
[52] H. Gao, A. Y¨uce, and J.-P. Thiran, “Detectingemotional stress from facial expressions for driving safety,” inImage Processing (ICIP), 2014 IEEE International Conference on. IEEE,2014, pp. 5961–5965.
[53] I. Abdic, L. Fridman, D. McDuff, E.Marchi, B. Reimer, and B. Schuller,“Driver frustration detection from audio and video in the wild,” inKI 2016: Advances in Artificial Intelligence:39th Annual German Conference on AI, Klagenfurt, Austria, September26-30, 2016, Proceedings, vol. 9904. Springer, 2016, p. 237.
[54] J. Shotton, T. Sharp, A. Kipman, A.Fitzgibbon, M. Finocchio, A. Blake,M. Cook, and R. Moore, “Real-time humanpose recognition in parts from single depth images,” Communicationsof the ACM, vol. 56, no. 1, pp. 116–124, 2013.
[55] A. Toshev and C. Szegedy, “Deeppose:Human pose estimation via deep neural networks,” in Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition, 2014, pp.1653–1660.
[56] J. J. Tompson, A. Jain, Y. LeCun, andC. Bregler, “Joint training of a convolutional network and a graphicalmodel for human pose estimation,” in Advances in neuralinformation processing systems, 2014, pp. 1799–1807.
[57] D. Sadigh, K. Driggs-Campbell, A.Puggelli, W. Li, V. Shia, R. Bajcsy, A. L. Sangiovanni-Vincentelli, S. S. Sastry,and S. A. Seshia, “Datadriven probabilistic modeling and verification ofhuman driver behavior,”
Formal Verification and Modeling inHuman-Machine Systems, 2014.
[58] R. O. Mbouna, S. G. Kong, and M.-G.Chun, “Visual analysis of eye state and head pose for driver alertnessmonitoring,” IEEE transactions on intelligent transportation systems, vol.14, no. 3, pp. 1462–1469, 2013.
[59] B. Zhou, A. Lapedriza, J. Xiao, A.Torralba, and A. Oliva, “Learning deep features for scene recognition usingplaces database,” in Advances in neural information processing systems,2014, pp. 487–495.
[60] H. Xu, Y. Gao, F. Yu, and T. Darrell,“End-to-end learning of driving models from large-scale video datasets,” inThe IEEE Conference on Computer Vision and Pattern Recognition(CVPR), July 2017.
[61] M. Bojarski, D. Del Testa, D.Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U.Muller, J. Zhang et al., “End to end learning for self-driving cars,”arXiv preprint arXiv:1604.07316,2016.
[62] “Advanced vehicle technologyconsortium (avt),” 2016. [Online]. Available: http://agelab.mit.edu/avt
[63] L. Fridman, D. E. Brown, W. Angell, I.Abdi´c, B. Reimer, and H. Y. Noh, “Automated synchronization of drivingdata using vibration and steering events,” Pattern RecognitionLetters, vol. 75, pp. 9–15, 2016.
[64] R. Li, C. Liu, and F. Luo, “A designfor automotive can bus monitoring system,” in Vehicle Power and PropulsionConference, 2008. VPPC’08. IEEE. IEEE, 2008, pp. 1–5.






最新资讯
-
沃尔沃汽车:创新驱动的豪华品牌
2025-04-24 18:16
-
飞书项目落地ASPICE解决方案,助力汽车软件
2025-04-24 09:59
-
驾驶员监控系统DMS合规认证的“中西结合”
2025-04-24 08:23
-
自动驾驶汽车测试关键行人场景生成
2025-04-23 17:12
-
R171.01对DCAS的要求⑧
2025-04-23 17:08
