




 广告
广告





















































基于改进的HMM方法预测驾驶员行为

预测过程的核心是通过HMM来实现的。使用给定的隐藏状态序列及其相应的观察序列,可以训练HMM。因此,输入到HMM的特征向量可以通过使用通用预滤波器来提取,这有助于确定最佳HMM并提高预测性能。出于这个原因,对于每个驱动器,可以生成具有个性化最佳预滤波器的HMM。
在图2中,示出了产生最佳预过滤器的过程。为了定义最佳预过滤参数,使用非支配排序遗传算法II ( NSGA - II )。NSGA - II源自NSGA,用于解决多目标优化问题( MOPs ) [ 16 ]。通过使用NSGA - II,使用不同的范围值重复训练HMM。考虑所有可能的范围值,每个范围从该参数的最小值变为最大值。确定每个观测参数的最佳阈值(最佳预滤波器)以最小化目标函数。
准确度( ACC )、检测率( DR )和虚警率( FAR )被广泛用于评估分类器[ 13 ] [ 14 ]。
它们是基于真阳性( TP )、假阳性( FP )、真阴性( TN )以及假阴性( FN )数来计算的。为了解释,举例说明了一个混淆矩阵(图3 )来描述向右改变车道的参数。真阳性( TP )表示

图3.混淆矩阵的说明[车道改为右]
它们的计算基于真阳性(TP),误报(FP),真阴性(TN)以及假阴性(FN)数。为了解释,示出了混淆矩阵(图3)作为示例来描述用于向右改变车道的参数。真阳性(TP)表示当估计的机动是正的时(向右改变车道)并且实际的也是正的事件的数量,对比度假阳性(FP)表示当估计的机动是正的时的事件的数量和实际值不相同,对于真假阴性(TN / FN)。 ACC,DR和FAR由[14]定义
如前所述,每个观察参数(预滤波器)的左/右阈值是确定HMM训练的观察序列的临界值,因此影响估计的状态。 TP,FP,TN和FN的值将由估计的状态定义,并最终影响ACC,DR和FAR值。在研究中,将针对前述ACC,DR和FAR参数的改进来选择最佳预滤波器。因此,目标函数定义为
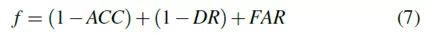
三种驾驶行为。
III.实验结果
本节介绍了基于HMM的变道机动预测的实验装置和获得的结果。使用所提出的模型,基于测量的变化和速度,预测了驾驶员的车道变换行为。为了提高预测性能,必须定义最佳预滤波器(特征参数)。
A.实验设计
应用如图4所示的专业驾驶模拟器SCANeRTMstudio来收集驾驶数据,该驾驶数据用于训练和测试所提出的方法。该模拟器配备五个监视器,180度视野,基座固定驾驶员座椅,方向盘和踏板。三个后视镜是决定改变车道所必需的,它们显示在显示器的相应位置上,驾驶模拟器的数据获取频率为20Hz。

图4.驾驶模拟器,椅子动力学和控制,U DuE
驾驶场景基于高速公路驾驶场景,具有四个车道的两个方向和模拟的交通环境。在驾驶期间,当前车缓慢行驶时,参与者可以执行超车操纵。超车后,参与者也可以回到最初的车道。从左到右改变车道的时间点由参与者决定。遵循德国的交通规则,只允许从左车道超车。共招募了9名年龄介乎25至38岁的参与者。他们都持有有效的驾驶执照。每位参与者进行了约25分钟的驾驶。
1)数据处理阶段:为了将数据标记为隐藏状态序列以及观察序列,需要对信号数据进行分类和处理。此贡献中的隐藏状态仅考虑更改车道。在驾驶模拟中,可以通过车辆中心点的位置确定当前车道i。因此,通过在不同时间比较车道i的值,可以确定车辆的车道变换。当当前车道的值与最后时刻it-1相同时,定义车道保持。当该值增加时定义向左变换的车道,并且当减小车道时向右变换车道。在实验中,驾驶员决定改变车道(转向灯)的时间已经在车道变换之前的2到3秒之间,平均值为2.5秒。因此,将考虑在行动之前2.5秒发生作为驾驶行为的车道变化。然而,如果自我车辆通过驾驶与白线重叠,则可能产生一些车道变换数据,并且这些数据不反映驾驶员的真实行为。因此,有必要去除这些干扰数据以获得准确的实验数据。表II给出了每种隐藏状态的符号及其具体描述。

观察载体可以通过预滤器分类并处理成序列。如第II部分所述,将使用最大ACC,最大DR以及最小FAR确定最佳预滤波器。因此,它应该用于改善驾驶行为预测的性能。为了证明这一点,使用两个不同的预滤器对观察向量进行分类。一个预过滤器正在使用这些最佳段。另一种是使用一组通用分段范围进行比较,通过比较实验数据给出,例如平均值,最小安全距离等。
2)训练阶段:在本实验中,每个实验数据集分为10个子集,这10个子集中的7个被认为是训练数据集,其他被认为是测试数据集。每个训练数据集的位置是不同的,并且不重复,例如,第一训练数据集从第一至第七子集中选择,第二训练数据集从第二至第八子集中选择,依此类推。每个训练和测试数据集必须包含不同的换道操作。训练数据集可用于估计HMM参数。利用该HMM参数,可以计算隐藏状态。在下一步骤中,将比较来自训练数据的隐藏状态序列和由HMM模型计算的隐藏状态序列,以检查对应关系并计算ACC,DR和FAR。然后,计算目标函数(7)。然后,通过关于上述目标函数的优化来定义预滤波器值。该预滤器及其相应的HMM模型将用于测试阶段。
3) 测试阶段:每个特定于驱动程序的测试数据集必须与在训练阶段使用的数据相关。 因此,已经在训练阶段计算了每个测试数据集的最佳预滤波器和相应的HMM模型。最可能的驾驶行为将通过使用相应的HMM来确定。通过计算和实际驾驶行为之间的比较,可以评估准确性。
B评估
为了评估所提出的方法,将通过使用相同的训练数据集和不同的预滤波器来学习HMM。在选择最佳预滤器之后,使用通用预滤器与最佳预滤器比较该方法。将比较计算的和实际的驾驶行为以评估相似性。数据集#5的测试阶段的结果如图5所示。这里隐藏状态(驾驶行为)作为模拟时间的函数给出。隐藏状态的符号如表II所示。绿色,蓝色和红色线分别表示使用一般预滤波器的原始状态,计算的隐藏状态,以及使用最佳预滤波器计算的隐藏状态。结果表明,优化的基于预过滤器的HMM预测的状态最适合原始状态。蓝线错误计算隐藏状态的数量多于红色。
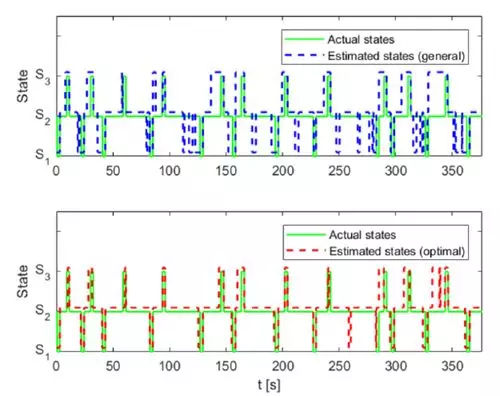
图5. HMM验证结果[测试数据集#5]
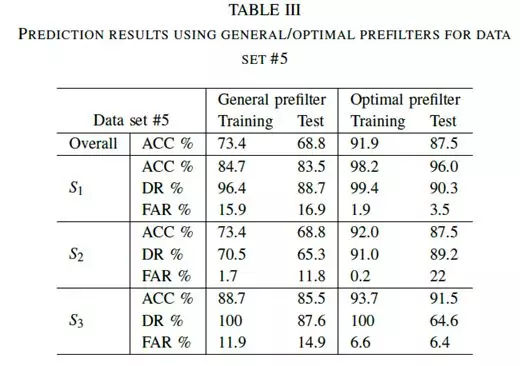
通过选择数据集#5的一般和最佳预滤波器的ACC,DR和FAR的百分比示于表III中。从得到的结果可以清楚地看出,使用最佳预滤器,总体ACC分别从73.4%(训练)和68.8%(测试)增加到91.9%和87.5%。类似地,使用最佳预滤器,DR高于使用通用预滤器。
在三种不同演习的FAR中,右侧车道变换的训练和测试阶段的FAR分别为15.9%和16.9%,优化后,FAR降至1.9%和3.5%。 FAR的值可以由等式(6)定义。可以看出,较高的FAR值是由图3中定义的较高的分子FP值(假阳性)产生的。对于向右变化的机动车道,FP是真实状态时的事件数,估计的状态是右边的车道变换。这些结果也可以从图5中检测到。这里S1定义了向右的车道变换。可以观察到,在若干情况下,估计的状态被错误地计算为S1。上述描述性问题更常出现在蓝线(使用一般预滤波器)而不是红线(使用最佳预滤波器)。可以得出结论,使用合适的预滤器可以改善预测结果。即使通过,在实验期间仍然可以找到一些例外,例如,车道保持(测试)的优化FAR值比预设值(大约高10%)更差。然而,考虑到所有情况的总体结果由于预滤器的优化而得到改善。







最新资讯
-
每秒采集100万个数据 | 下一代USB DAQ产品-
2025-04-07 14:12
-
重型商用车辆和客车的动力学——振动环境
2025-04-07 14:11
-
2025年10大隐形车衣品牌排行榜
2025-04-07 10:40
-
沃尔沃卡车与Greenlane合作推动商业电动化
2025-04-07 08:42
-
江铃晶马:美标转欧标充电结构专利
2025-04-07 08:39
